导读:由于大数据时代的发展,知识呈指数级增长,而知识图谱技术又在近年来逐步火热,因此诞生了利用知识图谱技术进行智能创作的新想法。本文将分享基于知识图谱的多模内容创作技术及应用。主要包括以下四大部分:
-
百度知识图谱概览
-
百度智能创作全景
-
多模内容创作技术
-
落地产品及应用案例
分享嘉宾|卞东海 百度 高级研发工程师
编辑整理|蒋郭鑫 河海大学
出品社区|DataFun
01/百度知识图谱概览
首先介绍一下百度知识图谱的概览。
1. 知识图谱的基本结构
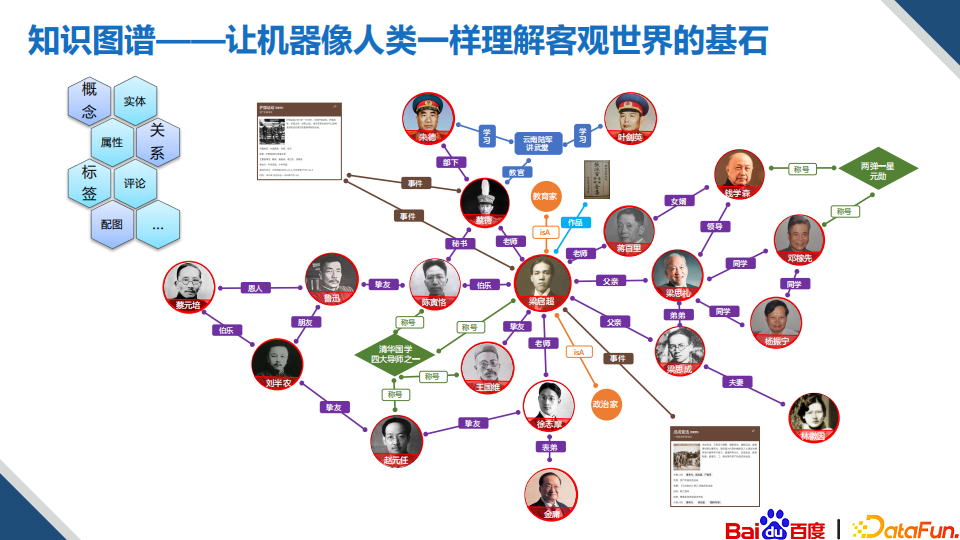
知识图谱以结构化的知识来描述客观世界的概念、实体及其属性和关系。从上图例子中我们可以看到,和梁启超相关的一些概念和关系,比如教育家和政治家是和梁启超相关的一些身份概念,而梁启超和梁思成是父子的关系。
2. 百度知识图谱的发展历程
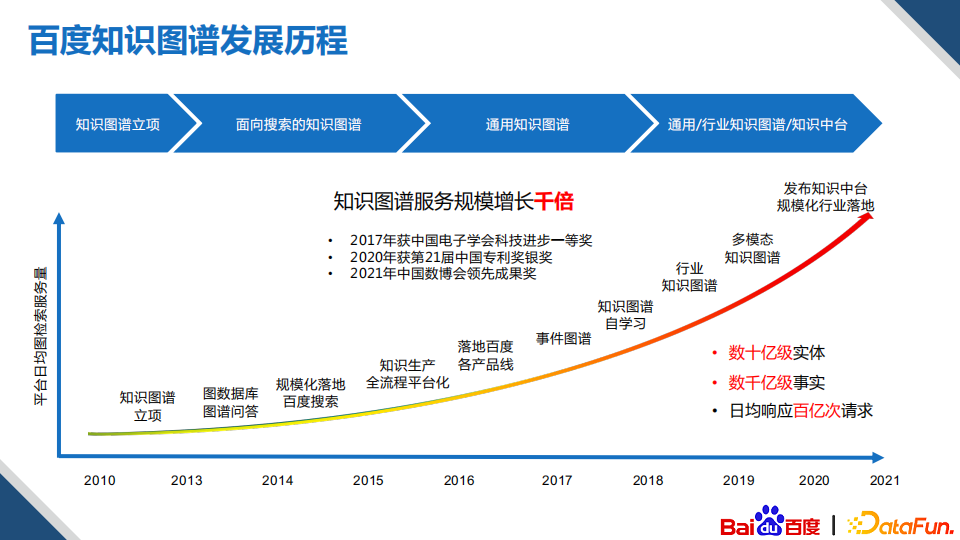
回顾百度知识图谱在过去十多年的主线工作和发展历程,主要经历了四个阶段:
-
第一个阶段在2013年以前的Pre-KG阶段,这也是学界和业界知识图谱发展的初级阶段,百度的知识图谱立项并开始运用于百度知识搜索的知心产品;
-
第二阶段在2014年至2015年,是知识图谱方法论和架构逐渐成型的阶段,我们建立了垂类的领域知识库,并规模化地应用于搜索的各类产品之中;
-
第三个阶段在2016年至2017年,逐渐地深入建设通用知识图谱相关的架构、算法和机制,开始全面应用于搜索、金融、客服、商业等各类产品线;
-
第四个阶段在2018年以后,这一阶段,技术建设的重点在于多元知识图谱的异构互联、图谱的主动输入和自学习、多媒体知识、复杂知识以及行业知识图谱的理解与构建等。
3. 百度知识图谱的技术视图
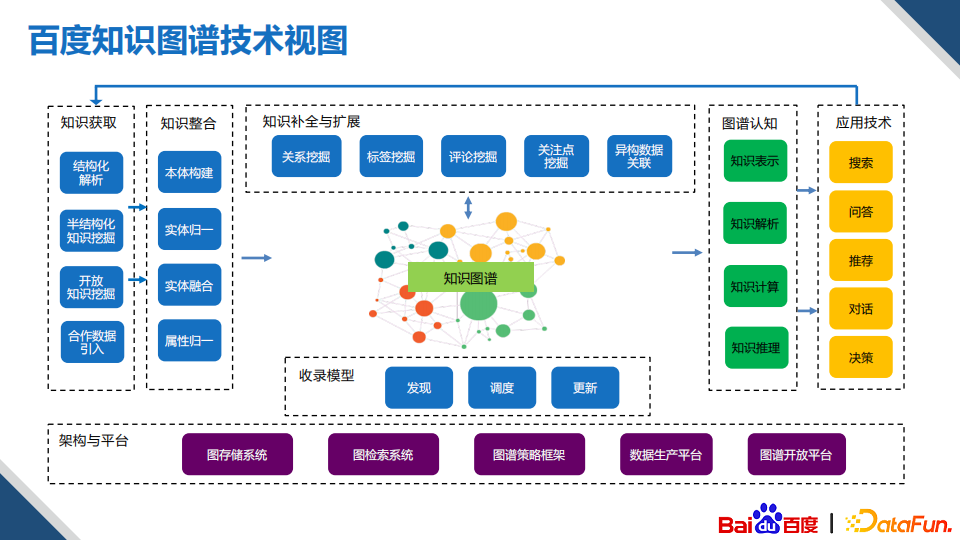
上图为百度知识图谱技术视图,首先是知识获取技术,即各种信息抽取的技术;接下来是知识整合技术,用于多元知识的融合;然后是知识补全和扩展的技术,用于不断地丰富知识图谱的内容;知识表示学习、知识推理与计算等认知技术主要运用在搜索、推荐问答等业务当中;最后,收录模型可以持续高效地更新知识。最下面是支撑上面所有知识发现、组织与获取应用能力的架构和平台。
4. 通用知识图谱应用
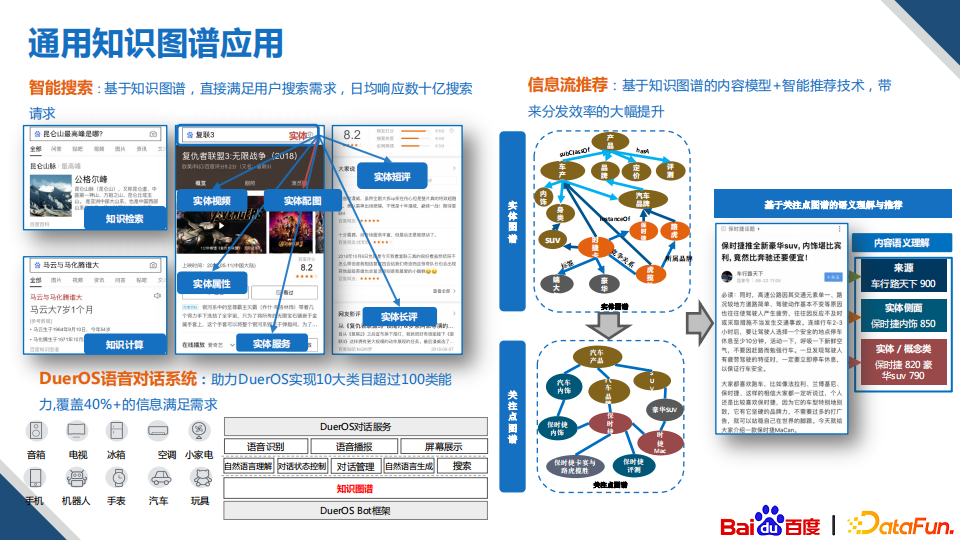
我们的通用知识图谱目前在百度的核心业务中广泛地应用,比如在搜索业务中支持了智能搜索,可以直接返回问题的答案。在信息流的推荐业务中,基于各类图谱去提升推荐的质量。在DuerOS等智能对话产品上,提供了大量优质的内容。
5. 行业知识图谱应用
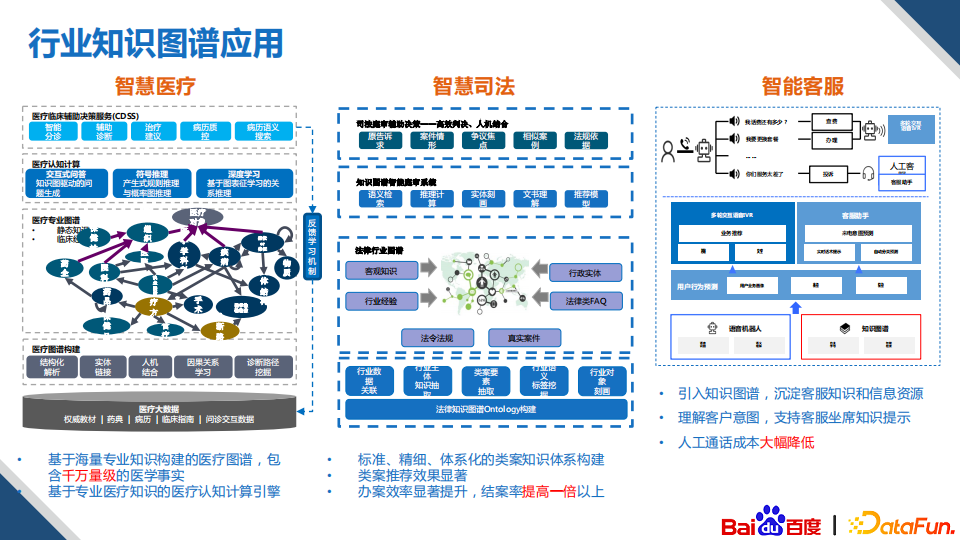
我们的行业知识图谱目前赋能了许多行业领域:
-
首先是基于海量专业知识构建的医疗知识图谱,其包含了千万级的医学事实,并开发了基于专业医疗知识的医疗计算认知引擎,在多家三甲医院上线使用;
-
其次是智慧司法,我们完成了标准、精细、体系化的类案知识体系的构建,类案推荐效果显著,在法案实际的使用当中,结案的效率提高了一倍以上;
-
最后是智能客服,我们引入知识图谱,沉淀客服知识和信息资源,通过理解客户的意图,支持客服坐席的知识提示,人工通话的接单量降低了70%。
02/百度智能创作全景
1. 内容创作挑战

创作,是对人类现有知识和素材的组织和再创造。在内容创作领域,像媒体、金融、政企都有大量的创作需求,比如新闻稿件、金融报告、公司公文等。在创作时一般都有以下四个痛点:
-
第一是如何从海量信息中获取到有价值的内容;
-
第二是时效性要足够高,像新闻稿件尤其是热门事件的新闻,肯定是越快越好;
-
第三是要把控内容的质量,避免出现错误;
-
第四是内容覆盖要广泛,包括长尾和冷门领域。
2. 百度大脑智能创作平台全景图
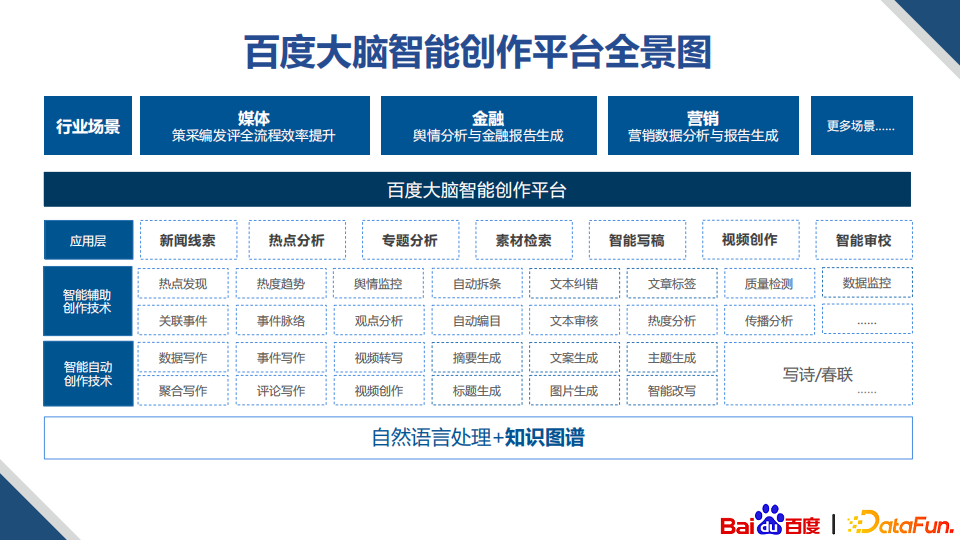
针对上述问题解决方案,可以简单总结为百度大脑智能创作平台全景图,基于NLP、知识图谱、视觉、语音的技术和数据,我们研发了智能自动创作和智能辅助创作的技术。在应用层提供包括新闻线索、热点分析、智能写稿、视频创作等核心的功能,可以满足各个行业创作的需求。下面会详细介绍每个功能的核心点:
(1)自动创作:让作者从重复工作中解放

首先是智能自动创作,通过数据加自动写作引擎的方式,实时大量地生成覆盖多个领域的资讯,让创作者从重复的工作中得到解放。像天气文章,每天都需要在规定的时间内高效地发布数千篇文章,单纯人工很难完成这些工作。
但其实机器并不能够完全取代人类作者,机器的优势在于它的高时效性、丰富的素材和大数据分析能力,而人工撰稿在内容的深度、精彩的程度、题材的多样上远胜于机器,所以我们的思路是让机器与创作者去分工协作。
(2)辅助创作:全流程智能辅助,全能赋能内容生产
于是,我们同样打造了智能辅助创造的能力,从创作前的素材的采集、理解,给作者提供热点的发现、热词分析的能力,到创作中的素材的推荐、编排,再到创作后的质量检测、提升,全流程的提供辅助创作的功能。自动和辅助的相结合,可以实现效率与质量的双收。
03/多模内容创作技术
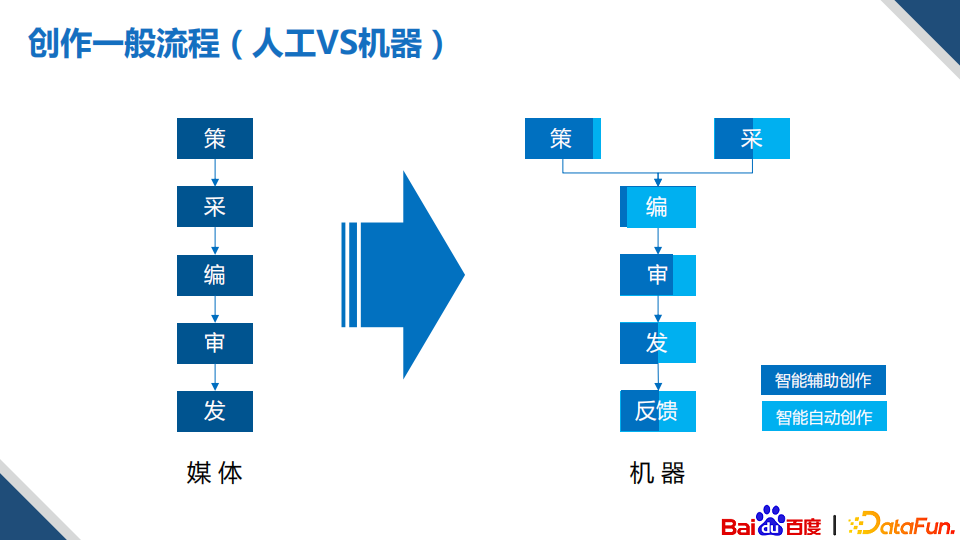
在介绍核心技术前,先看下机器创作和人工创作的区别,以媒体为例,创作过程一般有五个部分,分别是策、采、编、审、发。具体来讲,策是策划、要写什么,采是根据要写的主题去找相关的素材,编则是根据找到的素材写文章或制作视频,然后是审核和发布。机器创作分别扮演着不同的角色,比如自动创作这个线条,其主要侧重点是在于采和编辑;而辅助创作这个线条,侧重点就在于采集、策划和审。
1. 自动图文创作


从我们目前已发布的文章类型来划分,这里列出了六大类常见的自动创作出的文章:
-
第一类是计算/数值类,主要场景是天气、体育、股市等;
-
第二类是聚合类,是通过素材不同纬度的理解,将相关的素材组织成文;
-
第三类是浓缩类,就是将数千字的内容进行篇章级的摘要,同时要符合原内容的篇章逻辑;
-
第四类是事件类,主要是对同一个主题事件的不同阶段进行回顾;
-
第五类是分析类,主要是对同一个事件进行多维度分析其利弊,总结成文;
-
第六类是视频转写,它将视频内容进行总结,从而形成一篇文章。
那么机器到底是怎么创作的呢?一般来说要包括四步:写作触发、文章生产、质量控制和文章发布阶段。
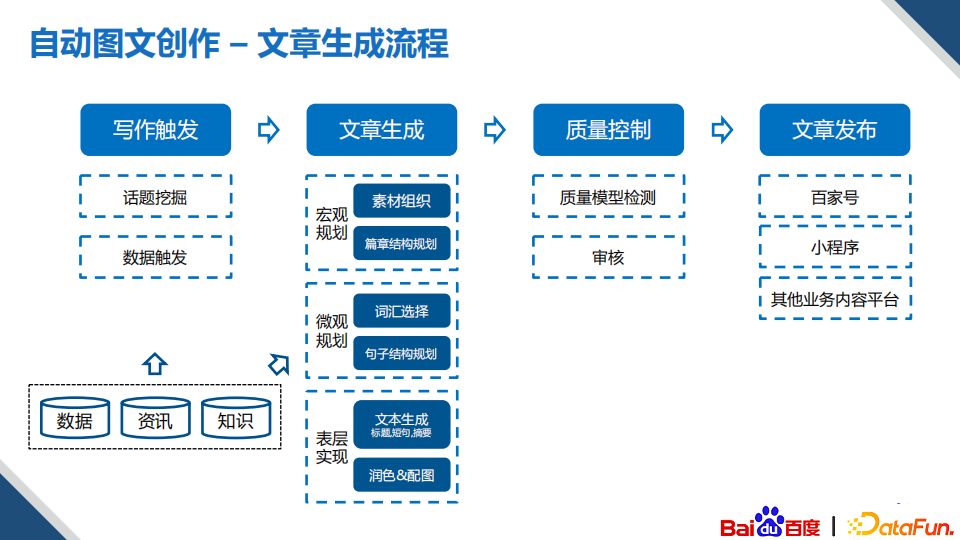
这里重点是写作触发和文章生成阶段,写作触发有两种方式,一种是主动的,比如话题挖掘,我们要找到话题之后才会写作;另外一种是被动的,比如我们每天都能看到的大量的天气、股市预警信息自动的更新。文章生成是自动创作的核心,机器的写作的时候其实和人的写作思路差不多,首先我们需要有一个宏观的规划,其次是每一段要写什么,要用什么样的方式、什么样的数据这些,进行微观的规划,最后表层实现就是要对上面规划后的类似写作模板一样的东西进行具体的实现。
下面来看一下图文创作实现这些能力的关键技术概览:
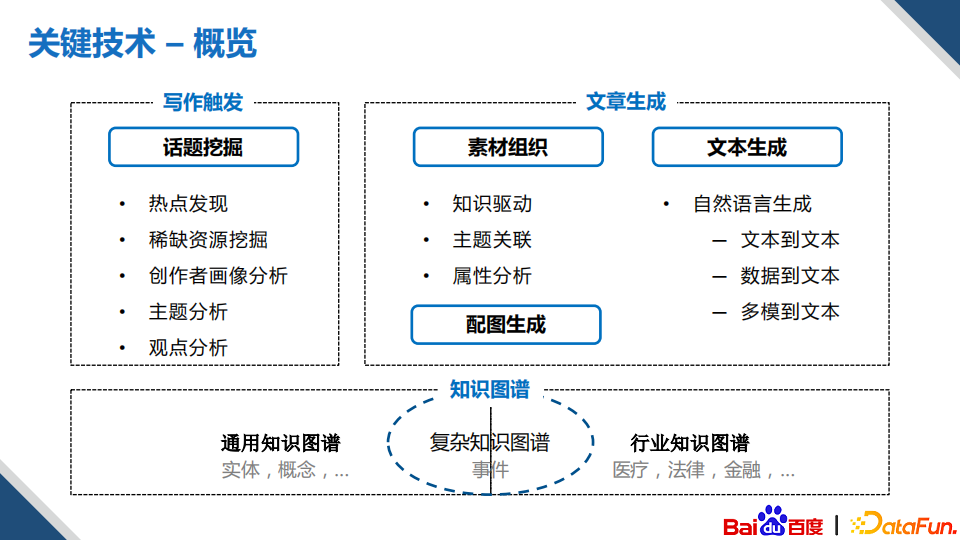
在技术概览当中,我们可以看到无论是写作触发,还是文章生成,底层都需要依赖于知识图谱作为输入,上层比较依赖于两个重要的技术方向,一个是理解,另外一个是生成。
下面分别介绍具体关键技术:
(1)通用知识图谱
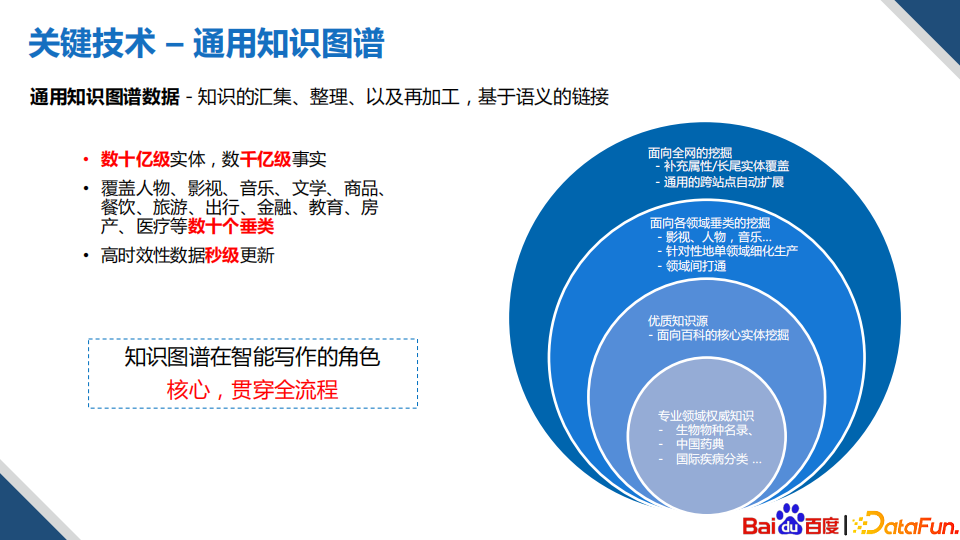
第一个比较关键技术就是通用知识图谱,通用知识图谱里面有非常多的有价值的信息。以生成明星CP类的文章为例,我们需要从图谱中去获取明星之前的关系作为文章内容的切入点。比如,邓超和孙俪,通过图谱机器可以知道他们是夫妻的关系;如果想在文章的正文当中插入一些关于邓超的介绍,可以直接在图谱中获取邓超相关的个人公开的信息。所以知识图谱在智能创作中扮演着核心的角色,贯穿全流程。
(2)事件图谱

我们的世界无时无刻不发生着事件、新闻资讯,绝大部分也都会包含事件。人的一些属性或者关系可能会随着时间发生变化,比如美国总统是谁这个问题,在2021年1月20号之前是特朗普,之后则变为了拜登。如果只是使用通用知识图谱,并不能得到这些动态变化的信息,而事件图谱可以很好地补充这一缺陷。
(3)话题挖掘
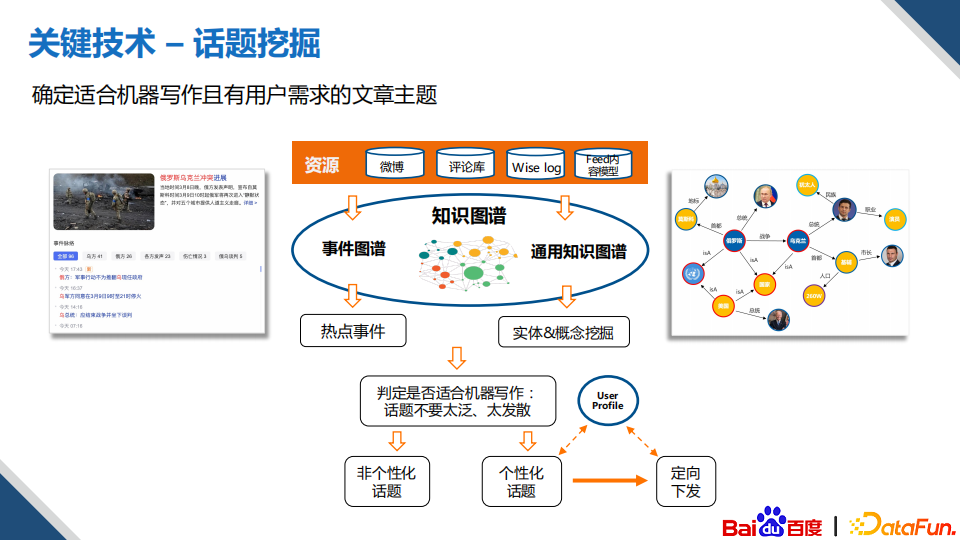
有了图谱作为基础,接下来就可以从全网域的数据中获取一些相关的咨询信息;然后我们从通用的知识图谱当中获取到对应的资讯中的实体概念,从事件图谱当中获取与资讯对应的的热门事件;接着再对这些概念和资讯进行进一步的分析和理解;最后依据写作类型,分别确定哪些话题可用,就可以得到我们的写作话题。图上的例子中,像“乌克兰”就是一个比较泛的话题,而“乌克兰局势”相对就属于比较好的话题。
(4)素材组织
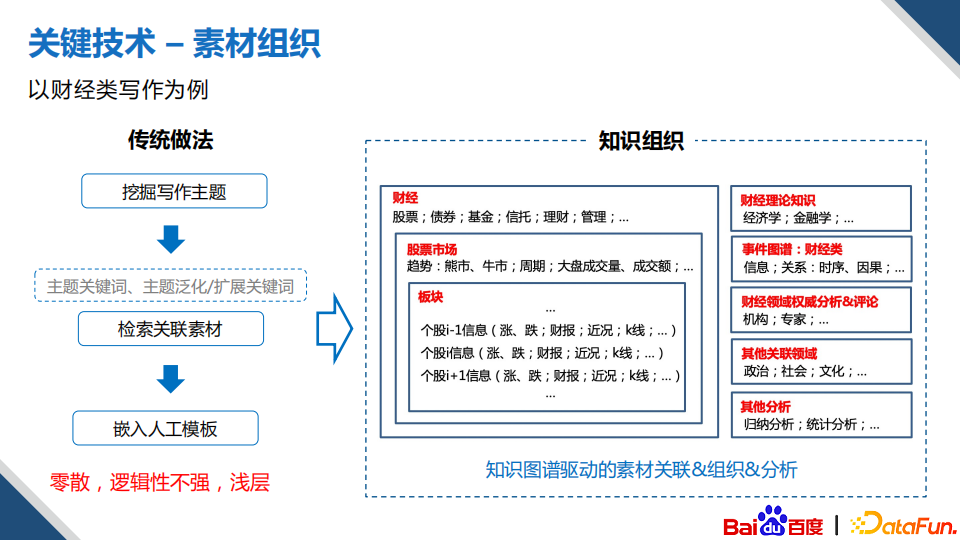
有了话题,接下来就是如何去组织文章的素材,在传统的做法当中,当挖掘出写作的主题之后,一般是直接检索关联的素材,嵌入模板就结束了,这种方案是比较浅层的,整体的文章逻辑非常零散。在我们的做法中,首先对素材包含的知识进行分析整合,形成一个体系化的知识信息,在生成文章时,将该知识信息结合图谱中其他的相关联的知识同时作为输入,这样生成的文章内容上会更加丰富,文章的整体性逻辑会更强。
(5)文本生成
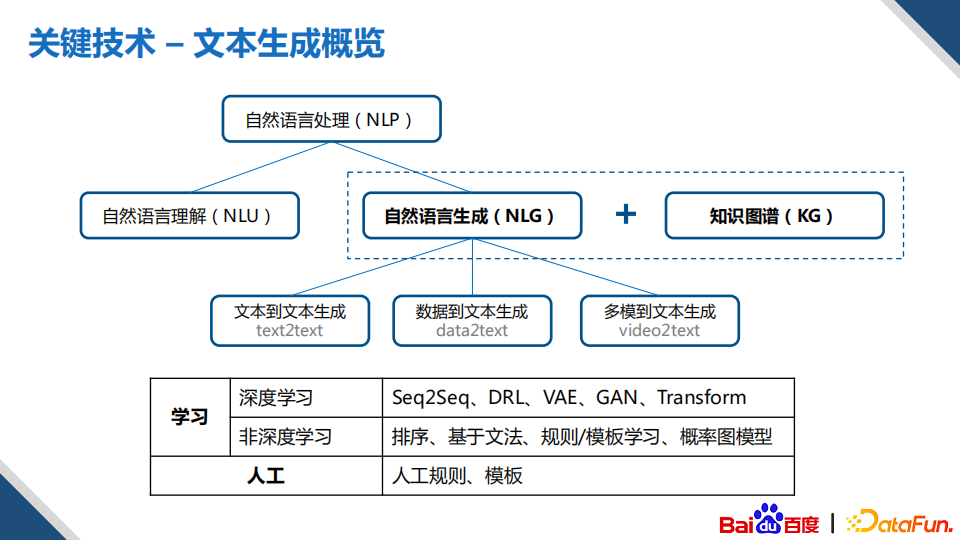
文本生成是自然语言生成下面的一个子任务,有很多种类型,从单模态到多模态,这里我们常用的有三大类,分别是文本到文本生成、数据到文本生成、多模到文本生成。针对不同的场景会使用不同的技术方案,包括模型、规则、模板等。
下面看不同的生成任务具体是如何实现的。
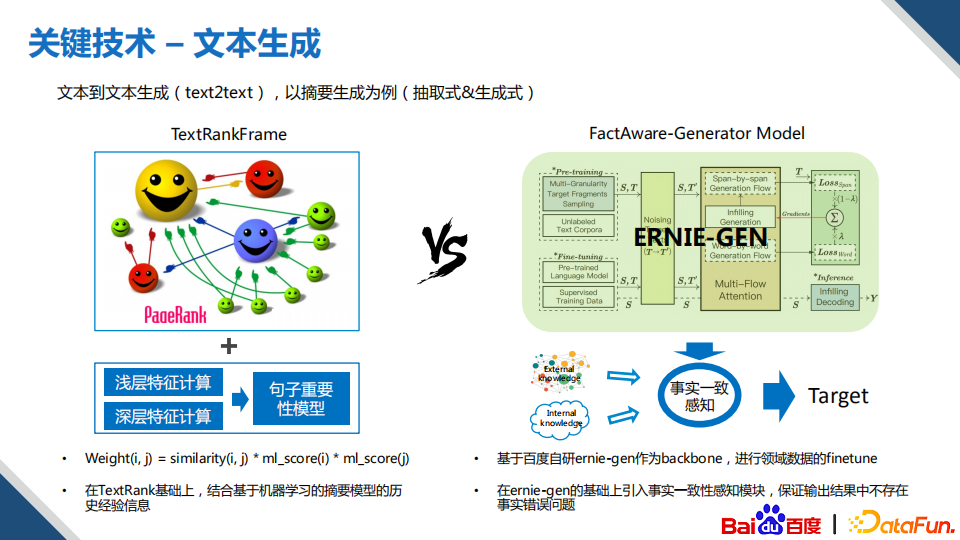
文本到文本生成,以摘要为例,摘要生成一般有两种方案,一种是抽取式,另外一种是生成式。在真实场景中,我们主要还是使用抽取式的方法。
除了算法本身,其实还要辅助很多的规则,比如说摘要开头的句子不太合适,在这种情况我们会使用词典来进行过滤。
另外,在一些场景下比如聚类的文章,考虑到生成文章的多样性,我们也会同时使用生成式的方法。
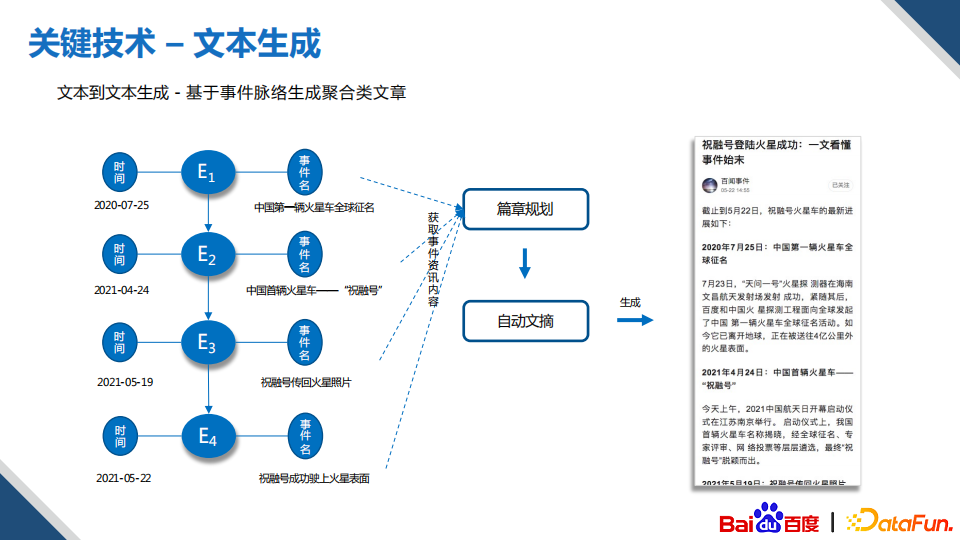
有了图谱信息和摘要生成技术,就可以做很多类型的文章了,比如上图的文章,它是一个事件脉络追溯的文章,把中国的第一辆火星车“祝融号”的来龙去脉进行了一个非常详细的盘点。
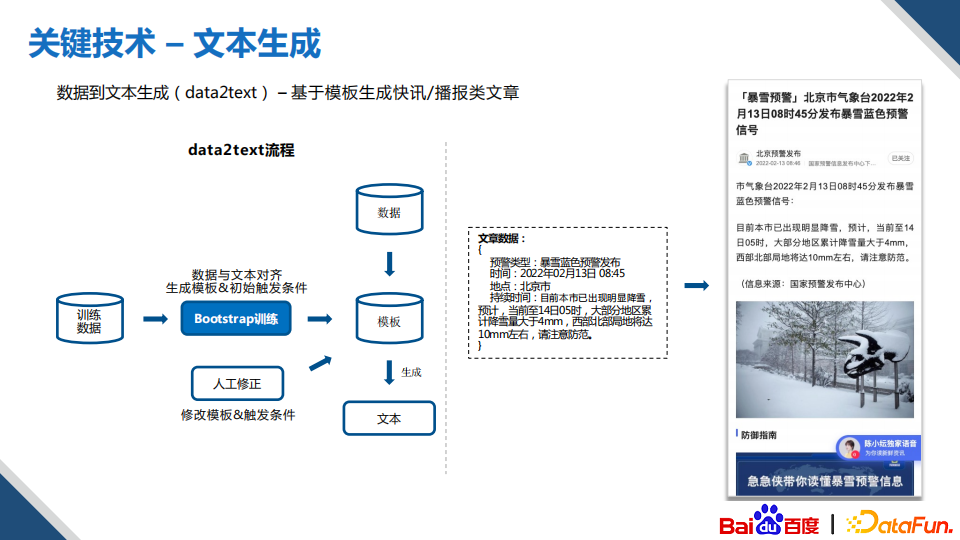
数据到文本生成,主要用在计算数值类的快讯文章,核心问题是如何去构建文章的模板。一般有三种方法:第一种是人工去构建初始的模板;第二种是从网上找到大量训练的数据,从中挖掘出对应的KV对信息,然后通过bootstrap的方式去训练;第三种是根据输入的KV对去直接生成,这种方案在短文案生成上的效果较好,但是在文章级的长文本生成上,目前还有很多问题。所以我们还是主要使用前两种方式去生成文章。
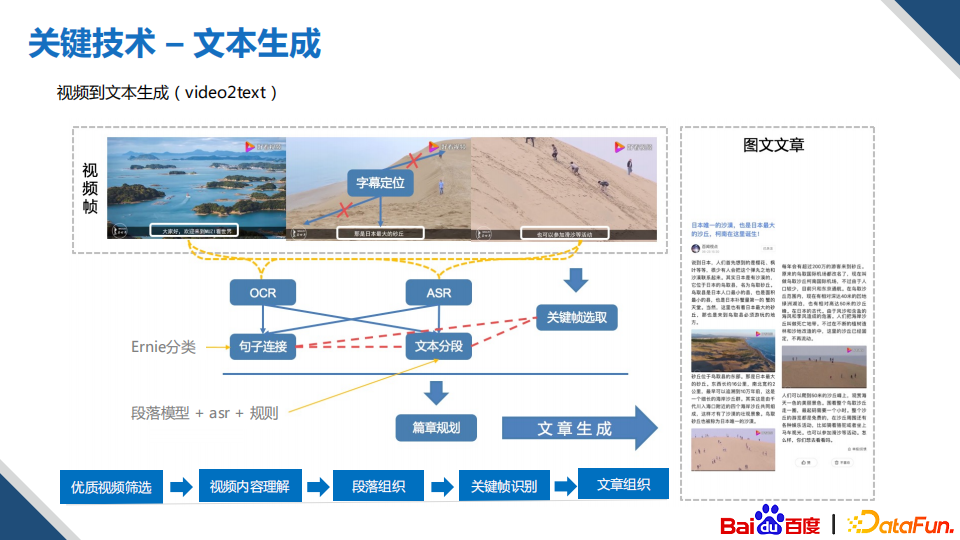
视频到文本的生成方式,应用场景有很多,比如大家比较熟悉的视频会议记录,就是一种,当然了它们是不同的研究范畴。对于视频转图文,我们的主要目标是希望生成的文章能够很好地表达视频的内容。
我们目前的方法当中会同时使用模型和规则。首先是做视频的理解,得到视频的一些感知数据,像ocr、asr相关的信息,为了确保文章的准确率,我们会使用ocr和asr做一个双向的校验,对输出的字幕会使用Ernie进行分类,最后结合每一段去选择对应的关键帧作为图片。有了文本和对应的关键帧作为配图,就可以按照这种时间的逻辑顺序生成一篇视频转写的文章。
(6)配图生成
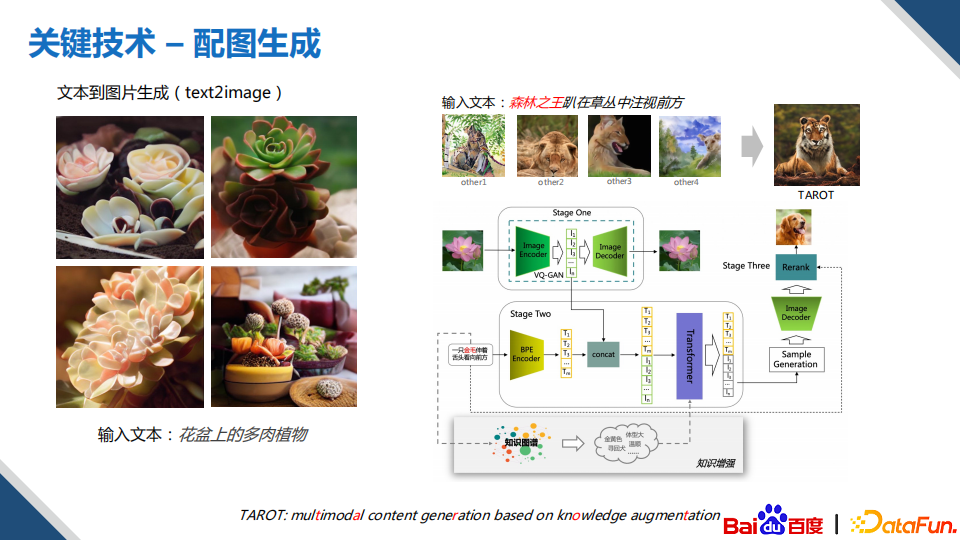
除了文本生成,我们还探索了文本到图片生成,这是一个非常有应用价值的技术,它除了可以生成各种类型的图片,还能够帮助公司去避免图片版权相关的一些问题。对这方面技术了解的同学,应该都看过DALL·E的生成效果,可以说是非常惊艳的,但仍存在一些问题,比如图片分辨率较小,图片质量不是特别高,所以是不可以直接落地使用的。另外,在真实的场景下,作者检索图片时,输入的往往都是概念,而DALL·E更偏向于对确定性实体进行细节性描述。所以我们的做法是,首先使用VQ-GAN代替了DALL·E的VQ-VAE,并且提高了图片生成的分辨率。上图多肉植物图片,可以看到,质量是非常高的;然后结合知识图谱让模型学习到更多的和抽象概念相关的知识,保证模型能够理解人类常识性的概念,在右上角这个示例中,可以看到,当输入的是“森林之王”时,模型依然可以很好地生成对应的实体,而且质量上相对也更好。
2. 自动视频创作
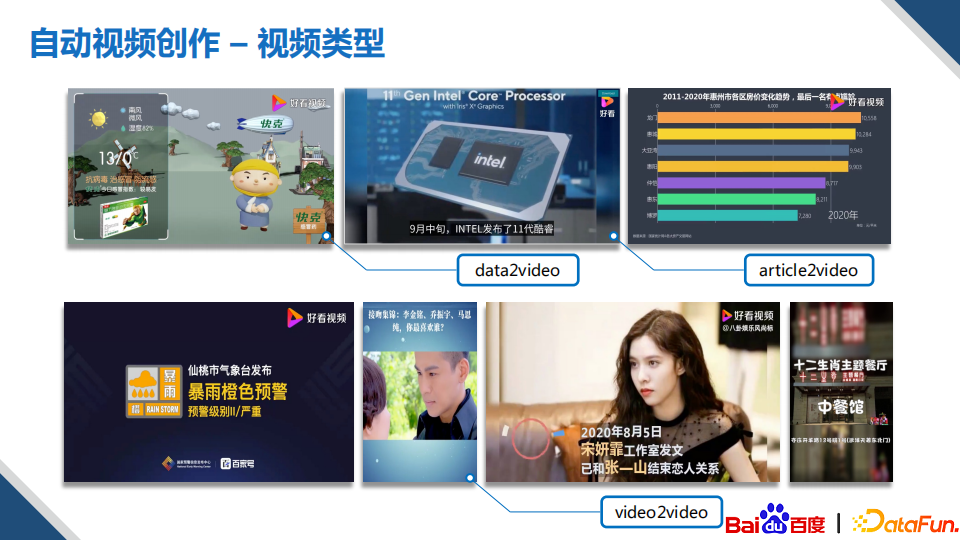
除了图文创作,我们在视频创作上也进行了非常多的工作,在公司内部和外部的合作当中也落地了很多的应用。对于视频的类型,我们一般从输入数据的类型来进行划分,可以分为三大类,分别是:视频到视频、文章到视频和数据到视频。
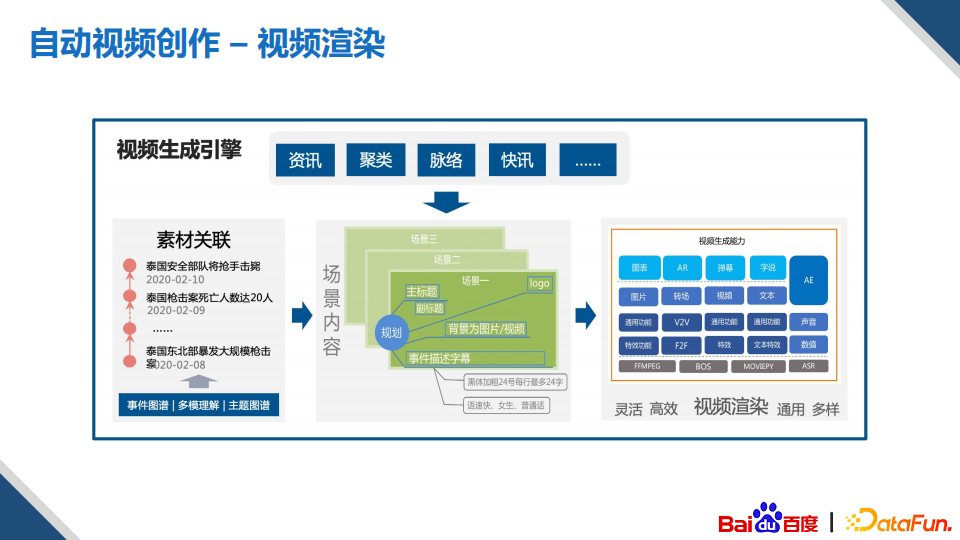
视频跟图文创作相比,最不一样的地方就是多了一个视频渲染的流程,视频渲染是非常繁琐耗时的事情,尤其是后台自动化的渲染;所以我们针对创作的场景构建了我们自己的视频生成引擎,它的底层主要是基于FFMPEG。我们把常用的一些操作都封装为渲染函数,然后根据输入和模板进行视频的高效生产。
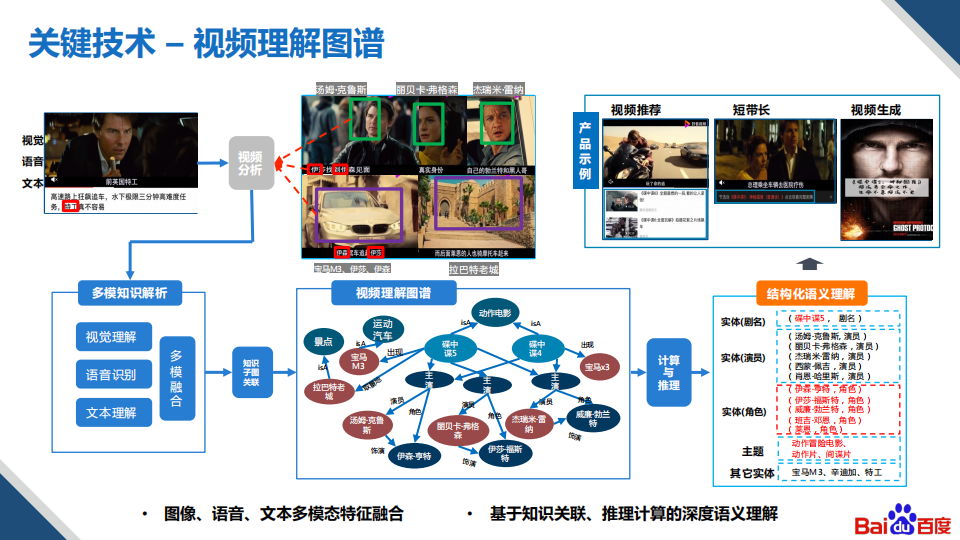
视频创作的一个关键技术是“视频理解图谱”,在以视频作为输入的场景下(也就是video2video),对视频素材的理解是进行后续生成的第一步。比如上图左上角给出的视频,如果从标题看,我们几乎得不到任何有关该视频的具体信息,但是我们通过对视频内容的感知,可以知道里面出现的演员有哪些,出现了哪些实体、地点;然后通过和知识子图进行关联就可以得到对应的影视剧的子图,对子图再进行实体地点的计算推理,就可以得到其对应的影视剧信息,后续使用视频素材就会非常容易。
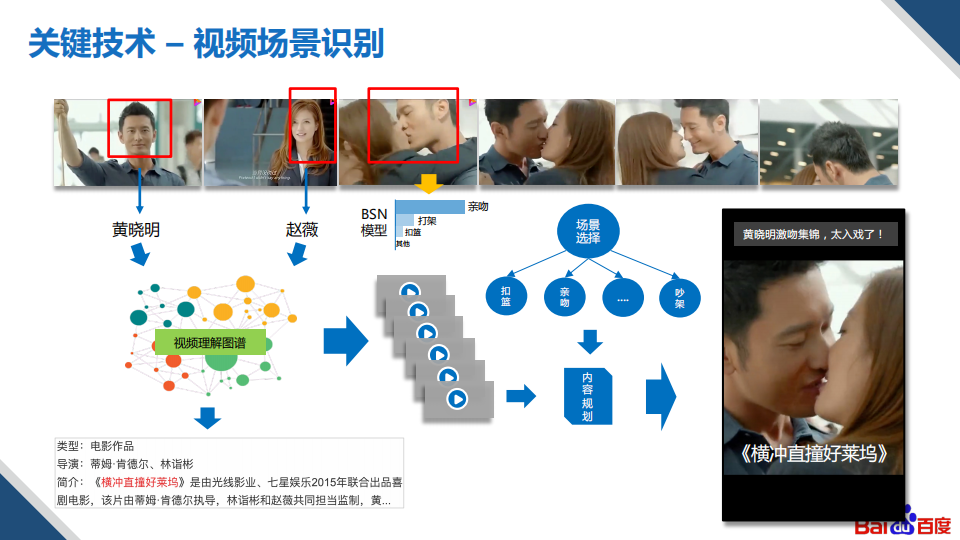
另外一个关键技术是视频场景识别,其在学界的研究对象主要是“时序动作提名”。在自动创作的时候,我们会从挖掘的信息中获取用户最喜欢观看的一些视频场景,然后对这些场景进行抽象。比如我们发现像亲吻、扣篮、打斗等场景都是用户喜欢的类型。因此,我们就基于时序动作提名的算法来进行包含该动作场景的一些识别和检测。当识别出这些场景之后,结合视频理解图谱,就会得到当前视频片段所属的影视剧是哪一个,这样就相当于对每个视频进行时序上打标签。有了这些标签之后,可以把需要的视频片段进行整合,通过一定的构建策略,生产精彩集锦类的视频。
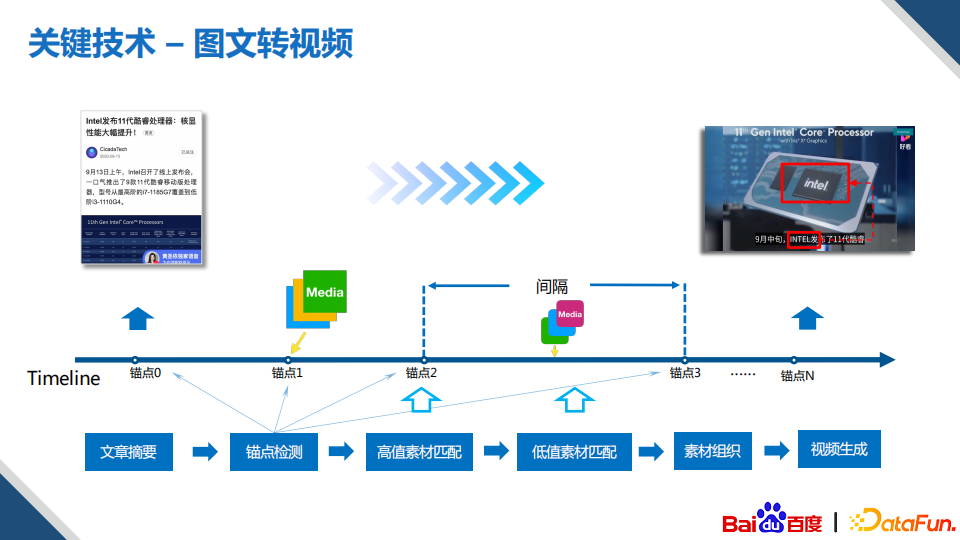
另外一个比较常见的视频类型是图文转视频,创作者只需要进行一次的稿件撰写,就可以实现多种模态的发布,可以大大节省人力。对于生成的资讯视频一般要求要足够的简洁,视频的内容要和语音有对应关系。
图文转视频的过程大概可以分为以下步骤:
-
首先生成文章摘要,文章一般来说都是包含数百上千字的内容,但是资讯类的视频长度可能在30秒到100秒左右,因此我们需要进行摘要;
-
其次需要对摘要后的文本进行锚点选择,锚点就是摘要后的一些比较关键的信息片段,比如上图例子中“英特尔”就是一个比较关键的锚点,这样做主要的原因是生成视频的素材输入大部分情况下都很少,比如可能就2-3张图,我们要把最相关的素材给到用户关注度最高的时间点上;
-
对于这些关键信息出现的时间点,需要有对应的高相关的素材进行展示,比如上述例子中的,当语音说到“intel”的时候,视频展示的是文章里面的包含intel的配图,如果文章中无对应的高相关性的图片视频素材,那就通过检索关联,从知识图谱中获取对应的信息;
-
对于非锚点的时间区间,可以使用文章中的其他低值素材作为填充,同样地,如果无素材,则从知识图谱中获取相关素材;
-
最后,使用视频生成引擎进行视频的渲染。
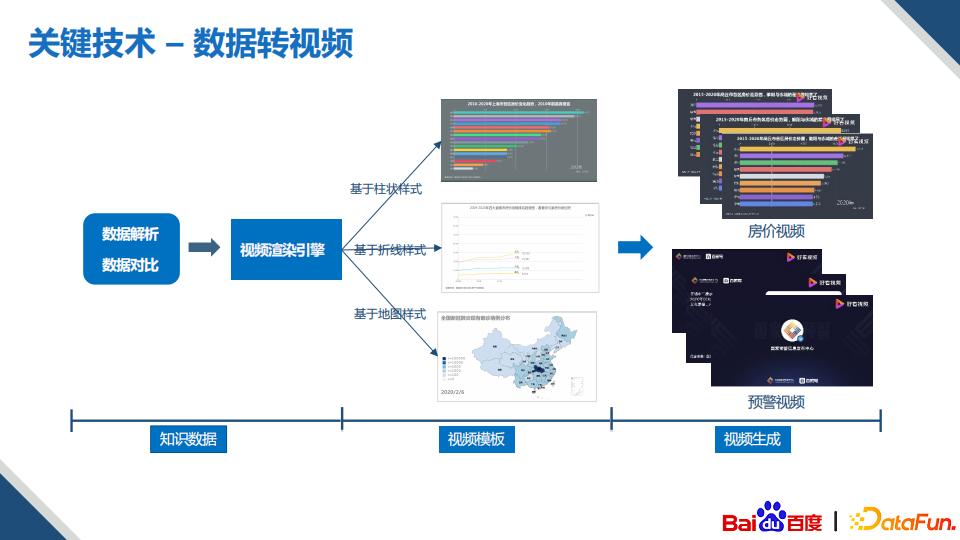
最后是数据转视频,像前面介绍的数据到文本的生成,理论上来说都可以通过视频化的方式展示。在我们的应用中,也发现视频方式展示的内容比图文更加受用户的喜爱,因此我们构建了非常多的通用的视频模板。比如上图中深圳房价动态的视频,我们可以定期获取动态更新的数据,再结合知识图谱中已有数据,就可以生成房价波动视频,从而满足用户观看的需求。
3. 辅助创作

辅助创作核心的价值是可以告诉用户有什么可以写,我们有跟媒体编辑聊过,他们认为整个创作流程当中第一步的策划其实是最难的,即如何找到有价值的创作点,而辅助创作刚好可以做到这一点。以帮助用户进行选题策划为例,我们可以将各类资讯的各个纬度进行理解和展示,激发用户的创作灵感。

辅助创作最关键的技术就是主题图谱,它是支撑创作选题和选材的核心。
上图左边的这张图中,大的节点代表一个主题,蓝色的是实体主题,红色的是事件主题,每个主题都有相应的素材、热度、稀缺度、行业和地域等属性,主题之间的边关系包括了实体的spo关系、事件的从属关系以及更为抽象发散的隐式的关系。上图右边的这张图是主题图谱的构建过程,首先我们是以实体、事件图谱、query、新闻等作为基础数据,然后进行主题、属性和边关系的挖掘,最后为用户提供按照热度、稀缺度进行主题素材的推荐和检索,另外还能够基于边关系进行主题的扩展。
下面具体看一下主题图谱具体是如何构建的:

主题分为实体主题和事件主题,他们的挖掘方式各有不同。
-
实体主题:我们以百度的核心集为基础,通过实体概念标注,从各种资讯中挖掘出实体概念主题,并抽取和计算每个主题的属性。
-
事件主题:我们通过对客观世界发生的事件,通过对篇章进行阅读理解、问答的方式来抽取出事件主题。事件抽取策略通过百度ERNIE—基于知识增强的语义理解模型进行多轮问答技术来实现的。
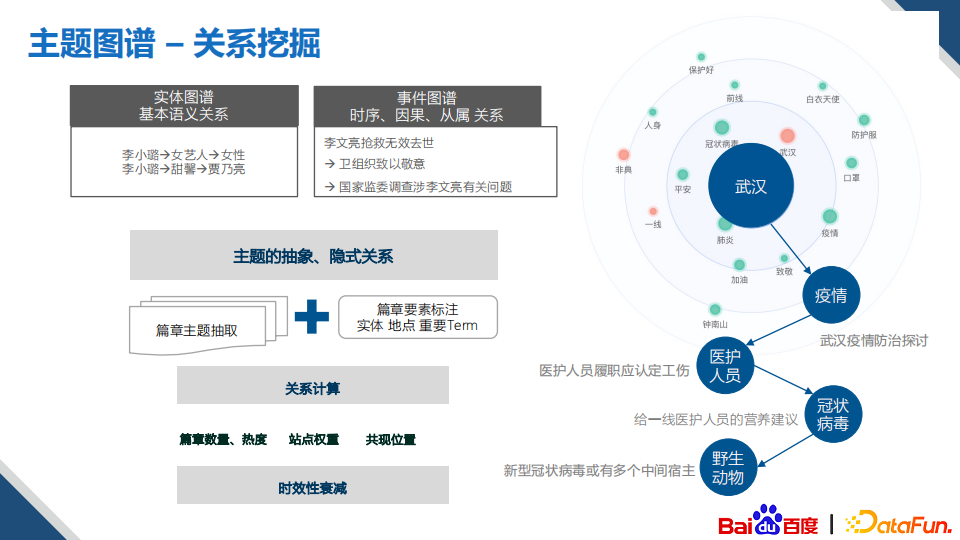
对于边关系的挖掘,我们划定了三类边关系,第一种是KG实体中的spo关系,第二种是事件之间的关系,但以上这两种关系都受限于严谨的语义关系,而创作者在选题的时候往往会需要一些比较发散的、抽象性的思考。因此我们采用隐式关系来满足这种需求,具体的做法是:首先从篇章中抽取出主题,然后对篇章的要素进行标注,比如实体、地点、以及重要的term,接下来分别从篇章数量热度、站点权重和共现位置计算这些term与主题的关系强度,再计算时效性的衰减,最后得到隐式关系的强度。
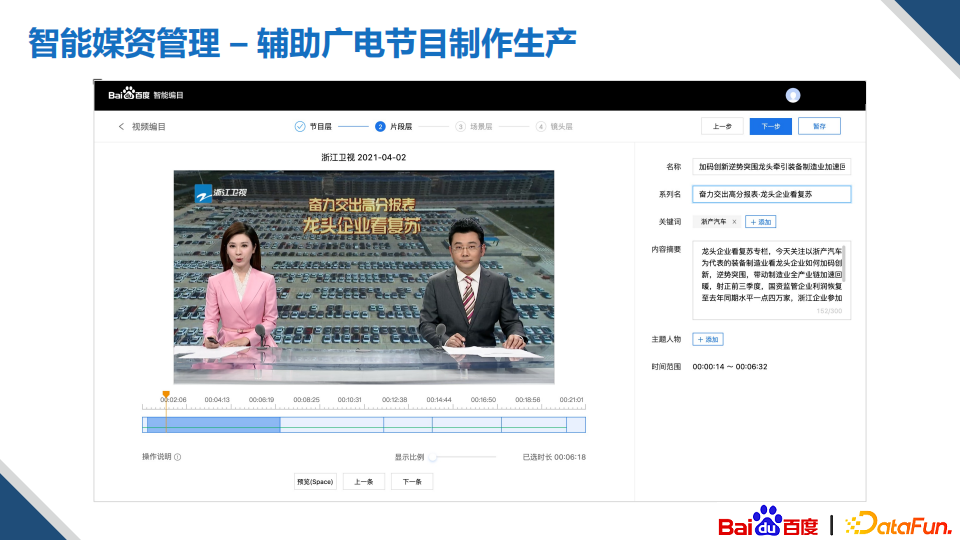
辅助创作的另外一个比较有价值的应用是媒资智能管理,简单来说就是帮助各个媒体进行视频的拆条、编目、标注的能力。拆条就是对一个完整的视频进行分割,像新闻联播,它可以分为很多的独立的片段,拆条的力度可以是片段级、场景级、镜头级;编目就是对拆条后的视频进行总结的描述。
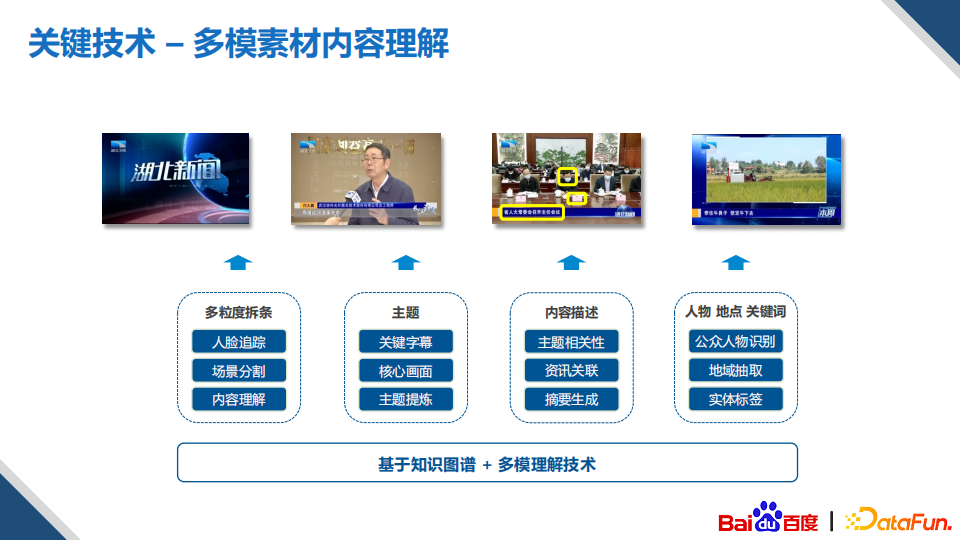
针对媒资智能管理应用场景,我们构建了多模素材理解技术。通过获取视频中的感知数据信息,然后对关键信息进行整合输出。比如跨场景的人脸追踪,可以帮助我们对视频进行多粒度的拆条,通过对这种实时资讯的抓取、理解以及检索和视频asr的解析,可以帮助我们生成编目的解析。目前,我们的方案在拆条、编目的效率上比纯人工提升了3-4倍。
04/落地场景及应用案例
1. 自动创作应用落地

自动创作方面,我们在百度百家号落地了数十类的图文文章,借助视频创作引擎,我们在好看视频也落地了多种类型的视频作品,CTR达到了与人工创作持平,同时在百度地图落地了商家推广的视频产品。
2. 辅助创作应用落地
辅助方面,在公司内部,我们支持了百家号APP的多项创作能力,例如热点分析、热门推荐、主题趋势等。
3. 行业赋能
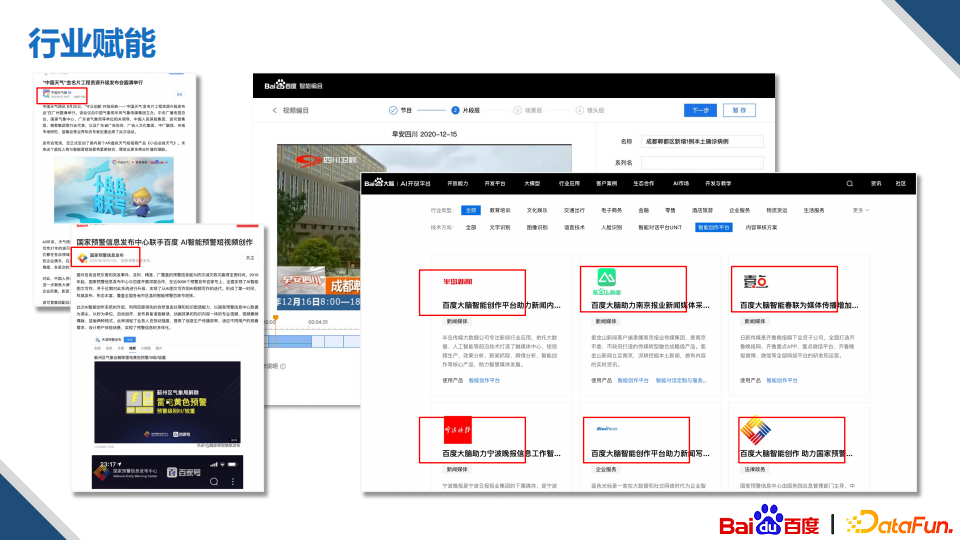
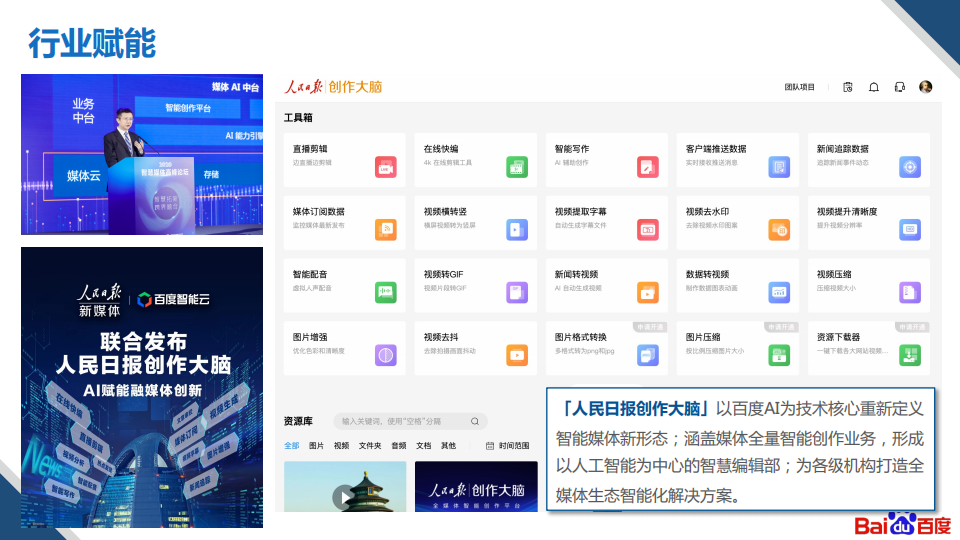
在行业赋能方面,自动创作上,我们和国家预警中心,中国天气网等部门进行了深度的合作;辅助创作上,我们支持了四川观察新闻视频的拆条和主题抽取的应用,以及多家省级媒体的辅助能力的落地。此外,在去年初我们还和人民日报达成了持续的合作,输出了多项创作的核心能力。
今天的分享就到这里,谢谢大家。
分享嘉宾: