✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab仿真内容点击👇
智能优化算法 神经网络预测 雷达通信 无线传感器
信号处理 图像处理 路径规划 元胞自动机 无人机 电力系统
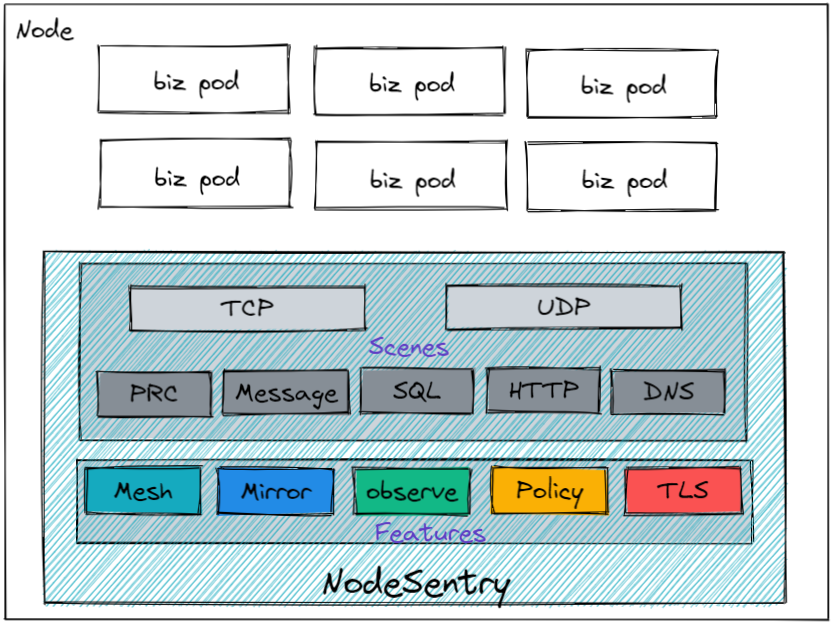
⛄ 内容介绍
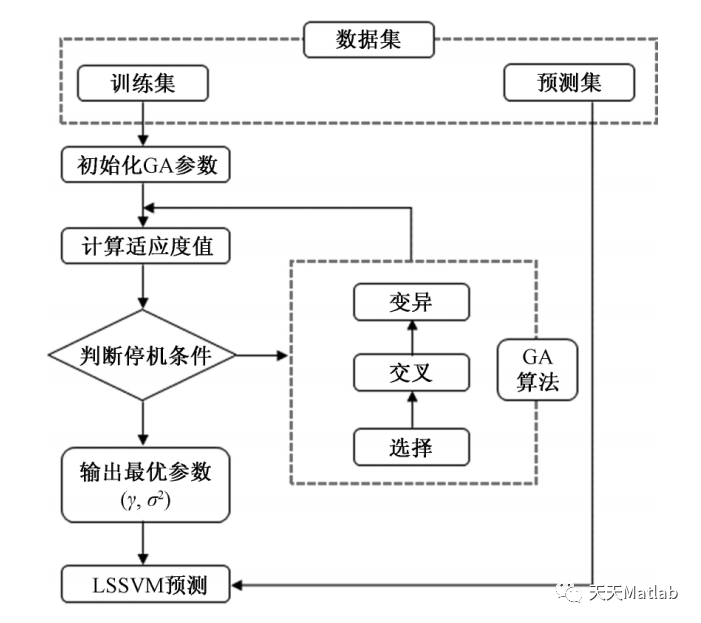
本文提出一种基于最小二乘支持向量机的数据预测方法。LSSVM 是一种新型机器学习算法,其在传统支持向量机 SVM 基础上,将二次规划问题中的不等式约束改为等式约束,极大地方便了求解过程,克服了数据集粗糙、数据集波动性大等问题造成的异常回归,能有效避免 BP 神经网络等方法中出现的局部最优等问题。GA 算法是由美国密歇根大学的 Holland 于 1975 年提出的一种模拟生物进化论的自然选择和生物遗传的优化技术,是一种高度并行、自适应和全局性的概率搜索算法。GA 求解问题的核心过程包括: 编码( 二进制) 、遗传操作( 选择、交叉、变异) 、适应度函数。首先对优化参数进行二进制编码,将解空间转换成染色体空间; 设定进化代数、个体长度、种群大小等初始群体参数; 确定合适的适应度函数,计算群体中个体的适应度; 然后对种群进行遗传算子操作,如选择、交叉和变异,经过迭代计算,使种群不断向最优方向进化,从 而 得 到 最 优解。由于 LSSVM 模型需要优化的参数有两个( 惩罚因子 γ,核参数 σ2) ,所以种群维数为 2。
算法流程如下:
步骤1,采集时间序列的样本数据;
步骤2,建立基于遗传算法优化参数的LSSVM数据预测模型;
步骤3,应用预测模型对训练样本进行预测,得到训练样本的相对误差和预测值;步骤4,预测模型对训练样本的相对误差进行预测,从而得到相对误差的预测值;步骤5,对相对误差的预测值进行校正,从而得到预测速率;解决了由于最小二乘支持向量机核函数参数和惩罚参数的经验性赋值而导致的预测精度不足的问题.
⛄ 部分代码
function [A,B,C,D,E] = bay_lssvm(model,level,type, nb, bay)
% Compute the posterior cost for the 3 levels in Bayesian inference
%
% >> cost = bay_lssvm({X,Y,type,gam,sig2}, level, type)
% >> cost = bay_lssvm(model , level, type)
%
% Description
% Estimate the posterior probabilities of model (hyper-) parameters
% on the different inference levels:
% - First level: In the first level one optimizes the support values alpha 's and the bias b.
% - Second level: In the second level one optimizes the regularization parameter gam.
% - Third level: In the third level one optimizes the kernel
% parameter. In the case of the common 'RBF_kernel' the kernel
% parameter is the bandwidth sig2.
%
% By taking the negative logarithm of the posterior and neglecting all constants, one
% obtains the corresponding cost. Computation is only feasible for
% one dimensional output regression and binary classification
% problems. Each level has its different in- and output syntax.
%
%
% Full syntax
%
% 1. Outputs on the first level
%
% >> [costL1,Ed,Ew,bay] = bay_lssvm({X,Y,type,gam,sig2,kernel,preprocess}, 1)
% >> [costL1,Ed,Ew,bay] = bay_lssvm(model, 1)
%
% costL1 : Cost proportional to the posterior
% Ed(*) : Cost of the fitting error term
% Ew(*) : Cost of the regularization parameter
% bay(*) : Object oriented representation of the results of the Bayesian inference
%
% 2. Outputs on the second level
%
% >> [costL2,DcostL2, optimal_cost, bay] = bay_lssvm({X,Y,type,gam,sig2,kernel,preprocess}, 2)
% >> [costL2,DcostL2, optimal_cost, bay] = bay_lssvm(model, 2)
%
% costL2 : Cost proportional to the posterior on the second level
% DcostL2(*) : Derivative of the cost
% optimal_cost(*) : Optimality of the regularization parameter (optimal = 0)
% bay(*) : Object oriented representation of the results of the Bayesian inference
%
% 3. Outputs on the third level
%
% >> [costL3,bay] = bay_lssvm({X,Y,type,gam,sig2,kernel,preprocess}, 3)
% >> [costL3,bay] = bay_lssvm(model, 3)
%
% costL3 : Cost proportional to the posterior on the third level
% bay(*) : Object oriented representation of the results of the Bayesian inference
%
% 4. Inputs using the functional interface
%
% >> bay_lssvm({X,Y,type,gam,sig2,kernel,preprocess}, level)
% >> bay_lssvm({X,Y,type,gam,sig2,kernel,preprocess}, level, type)
% >> bay_lssvm({X,Y,type,gam,sig2,kernel,preprocess}, level, type, nb)
%
% X : N x d matrix with the inputs of the training data
% Y : N x 1 vector with the outputs of the training data
% type : 'function estimation' ('f') or 'classifier' ('c')
% gam : Regularization parameter
% sig2 : Kernel parameter (bandwidth in the case of the 'RBF_kernel')
% kernel(*) : Kernel type (by default 'RBF_kernel')
% preprocess(*) : 'preprocess'(*) or 'original'
% level : 1, 2, 3
% type(*) : 'svd'(*), 'eig', 'eigs', 'eign'
% initiate and ev. preprocess
%
if ~isstruct(model), model = initlssvm(model{:}); end
model = prelssvm(model);
if model.y_dim>1,
error(['Bayesian framework restricted to 1 dimensional regression' ...
' and binary classification tasks']);
end
%
% train with the matlab routines
%model = adaptlssvm(model,'implementation','MATLAB');
eval('nb;','nb=ceil(sqrt(model.nb_data));');
if ~(level==1 | level==2 | level==3),
error('level must be 1, 2 or 3.');
end
%
% delegate functions
%
if level==1,
eval('type;','type=''train'';');
%[cost, ED, EW, bay, model] = lssvm_bayL1(model, type);
eval('[A,B,C,D,E] = lssvm_bayL1(model,type,nb,bay);','[A,B,C,D,E] = lssvm_bayL1(model,type,nb);');
elseif level==2,
% default type
eval('type;','type=''svd'';');
%[costL2, DcostL2, optimal, bay, model] = lssvm_bayL2(model, type);
eval('[A,B,C,D,E] = lssvm_bayL2(model,type,nb,bay);',...
'[A,B,C,D,E] = lssvm_bayL2(model,type,nb);')
elseif level==3,
% default type
eval('type;','type=''svd'';');
%[cost, bay, model] = lssvm_bayL3(model, bay);
[A,B,C] = lssvm_bayL3(model,type,nb);
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% FIRST LEVEL %
% %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%
function [cost, Ed, Ew, bay, model] = lssvm_bayL1(model, type, nb, bay)
%
% [Ed, Ew, cost,model] = lssvm_bayL1(model)
% [bay,model] = lssvm_bayL1(model)
%
% type = 'retrain', 'train', 'svd'
if ~(strcmpi(type,'train') | strcmpi(type,'retrain') | strcmpi(type,'eig') | strcmpi(type,'eigs')| strcmpi(type,'svd')| strcmpi(type,'eign')),
error('type should be ''train'', ''retrain'', ''svd'', ''eigs'' or ''eign''.');
end
%type(1)=='t'
%type(1)=='n'
N = model.nb_data;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% compute Ed, Ew en costL1 based on training solution %
% TvG, Financial Timeseries Prediction using LS-SVM, 27-28 %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
if (type(1)=='t'), % train
% find solution of ls-svm
model = trainlssvm(model);
% prior %
if model.type(1) == 'f',
Ew = .5*sum(model.alpha.* (model.ytrain(1:model.nb_data,:) - model.alpha./model.gam - model.b));
elseif model.type(1) == 'c',
Ew = .5*sum(model.alpha.*model.ytrain(1:model.nb_data,:).* ...
((1-model.alpha./model.gam)./model.ytrain(1:model.nb_data,:) - model.b));
end
% likelihood
Ed = .5.*sum((model.alpha./model.gam).^2);
% posterior
cost = Ew+model.gam*Ed
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% compute Ed, Ew en costL1 based on SVD or nystrom %
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
else
if nargin<4,
[bay.eigvals, bay.scores, ~, omega_r] = kpca(model.xtrain(model.selector,1:model.x_dim), ...
model.kernel_type, model.kernel_pars, [],type,nb,'original');
bay.eigvals = bay.eigvals.*(N-1);
bay.tol = 1000*eps;
bay.Peff = find(bay.eigvals>bay.tol);
bay.Neff = length(bay.Peff);
bay.eigvals = bay.eigvals(bay.Peff);
bay.scores = bay.scores(:,bay.Peff);
%Zc = eye(N)-ones(model.nb_data)/model.nb_data;
%disp('rescaling the scores');
for i=1:bay.Neff,
bay.Rscores(:,i) = bay.scores(:,i)./sqrt(bay.scores(:,i)'*bay.eigvals(i)*bay.scores(:,i));
end
end
Y = model.ytrain(model.selector,1:model.y_dim);
%%% Ew %%%%
% (TvG: 4.75 - 5.73))
YTM = (Y'-mean(Y))*bay.scores;
Ew = .5*(YTM*diag(bay.eigvals)*diag((bay.eigvals+1./model.gam).^-2))*YTM';
%%% cost %%%
YTM = (Y'-mean(Y));
%if model.type(1) == 'c', % 'classification' (TvG: 5.74)
% cost = .5*YTM*[diag(bay.eigvals); zeros(model.nb_data-bay.Neff,bay.Neff)]*diag((bay.eigvals+1./model.gam).^-1)*bay.scores'*YTM';
%elseif model.type(1) == 'f', % 'function estimation' % (TvG: 4.76)
% + correctie of zero eignwaardes
cost = .5*(YTM*model.gam*YTM')-.5*YTM*bay.scores*diag((1+1./(model.gam.*bay.eigvals)).^-1*model.gam)*bay.scores'*YTM';
%end
%%% Ed %%%
Ed = (cost-Ew)/model.gam;
end
bay.costL1 = cost;
bay.Ew = Ew;
bay.Ed = Ed;
bay.mu = (N-1)/(2*bay.costL1);
bay.zeta = model.gam*bay.mu;
% SECOND LEVEL
%
%
function [costL2, DcostL2, optimal, bay, model] = lssvm_bayL2(model,type,nb,bay)
%
%
%
if ~(strcmpi(type,'eig') | strcmpi(type,'eigs')| strcmpi(type,'svd')| strcmpi(type,'eign')),
error('The used type needs to be ''svd'', ''eigs'' or ''eign''.')
end
N = model.nb_data;
% bayesian interference level 1
eval('[cost, Ed, Ew, bay, model] = bay_lssvm(model,1,type,nb,bay); ',...
'[cost, Ed, Ew, bay, model] = bay_lssvm(model,1,type,nb);');
all_eigvals = zeros(N,1); all_eigvals(bay.Peff) = bay.eigvals;
% Number of effective parameters
bay.Geff = 1 + sum(model.gam.*all_eigvals ./(1+model.gam.*all_eigvals));
bay.mu = .5*(bay.Geff-1)/(bay.Ew);
bay.zeta = .5*(N-bay.Geff)/bay.Ed;
% ideally: bay.zeta = model.gam*bay.mu;
% log posterior (TvG: 4.73 - 5.71)
costL2 = sum(log(all_eigvals+1./model.gam)) + (N-1).*log(bay.Ew+model.gam*bay.Ed);
% gradient (TvG: 4.74 - 5.72)
DcostL2 = -sum(1./(all_eigvals.*(model.gam.^2)+model.gam)) ...
+ (N-1)*(bay.Ed/(bay.Ew+model.gam*bay.Ed));
% endcondition fullfilled if optimal == 0;
optimal = model.gam - (N-bay.Geff)/(bay.Geff-1) * bay.Ew/bay.Ed;
% update structure bay
bay.optimal = optimal;
bay.costL2 = costL2;
bay.DcostL2 = DcostL2;
% THIRD LEVEL
%
%
function [costL3, bay, model] = lssvm_bayL3(model,type,nb)
%
% costL3 = lssvm_bayL3(model, type)
%
if ~(strcmpi(type,'svd') | strcmpi(type,'eigs') | strcmpi(type,'eign')),
error('The used type needs to be ''svd'', ''eigs'' or ''eign''.')
end
% lower inference levels;
[model,~, bay] = bay_optimize(model,2,type,nb);
% test Neff << N
N = model.nb_data;
if sqrt(N)>bay.Neff,
%model.kernel_pars
%model.gam
warning on;
warning(['Number of degrees of freedom not tiny with respect to' ...
' the number of datapoints. The approximation is not very good.']);
warning off
end
% construct all eigenvalues
all_eigvals = zeros(N,1);
all_eigvals(bay.Peff) = bay.eigvals;
% L3 cost function
%costL3 = sqrt(bay.mu^bay.Neff*bay.zeta^(N-1)./((bay.Geff-1)*(N-bay.Geff)*prod(bay.mu+bay.zeta.*all_eigvals)));
%costL3 = .5*bay.costL2 - log(sqrt(2/(bay.Geff-1))) - log(sqrt(2/(N-bay.Geff)))
costL3 = -(bay.Neff*log(bay.mu) + (N-1)*log(bay.zeta)...
- log(bay.Geff-1) -log(N-bay.Geff) - sum(log(bay.mu+bay.zeta.*all_eigvals)));
bay.costL3 = costL3;
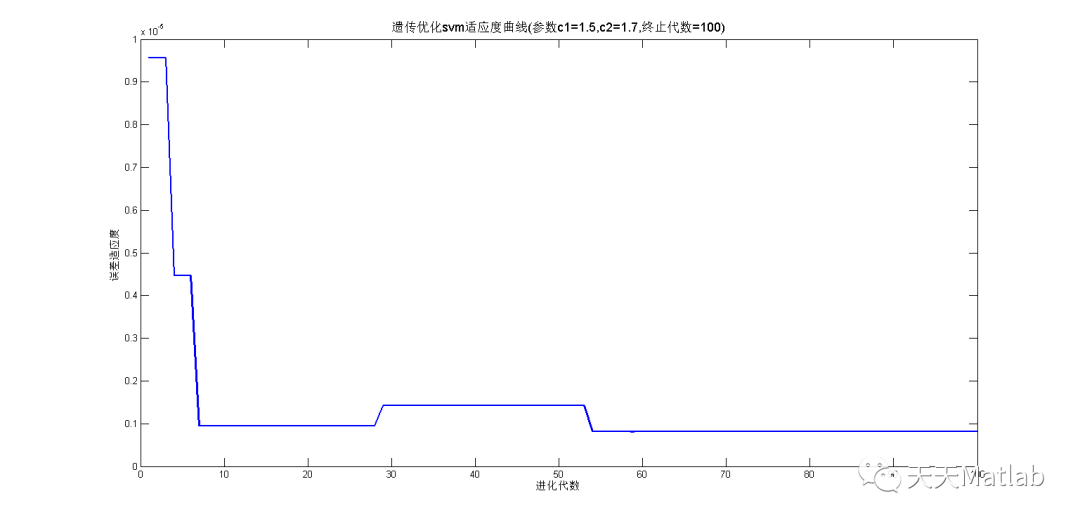
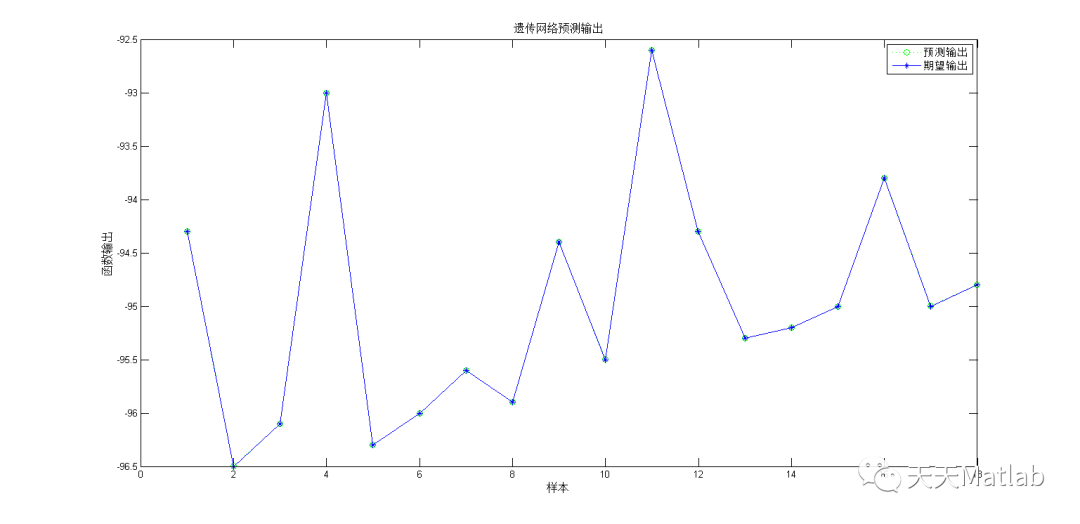
⛄ 运行结果
⛄ 参考文献
[1]聂敬云, 李春青, 李威威, & 王韬. (2015). 关于遗传算法优化的最小二乘支持向量机在mbr仿真预测中的研究. 软件(5), 6.
⛄ Matlab代码关注
❤️部分理论引用网络文献,若有侵权联系博主删除
❤️ 关注我领取海量matlab电子书和数学建模资料