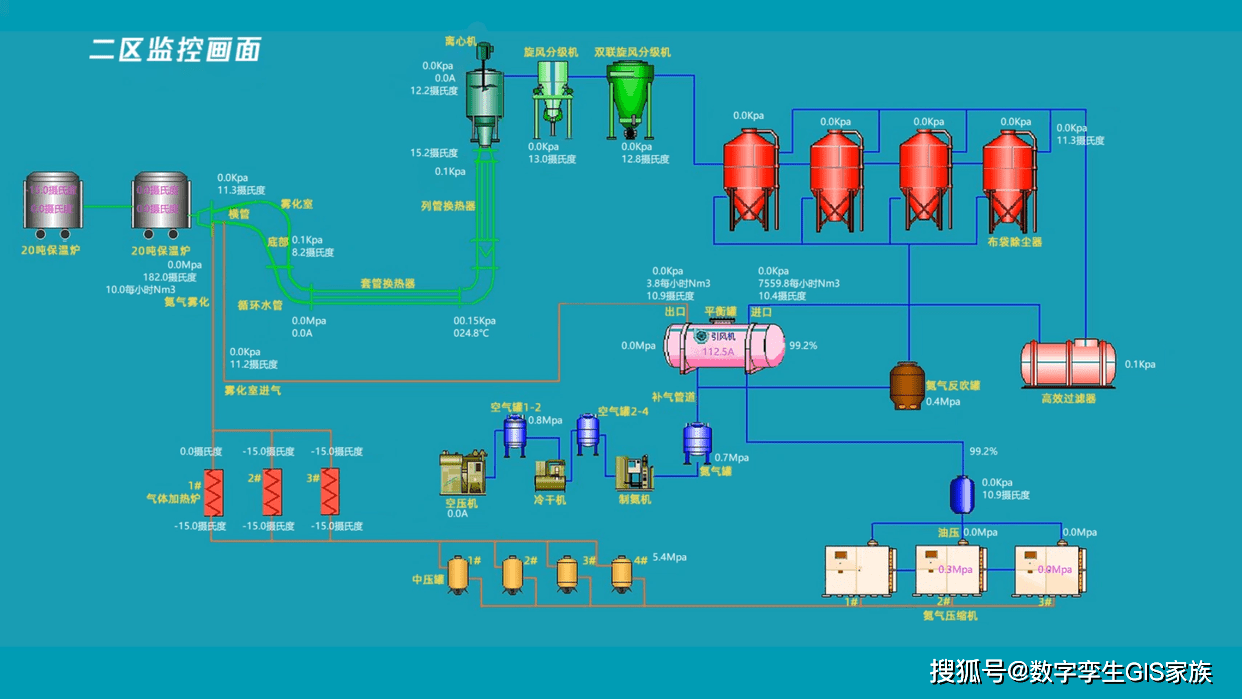
目录
深度学习硬件:CPU和GPU
深度学习硬件:TPU
深度学习硬件:CPU和GPU
1.提升CPU的利用率Ⅰ:提升空间和时间的内存本地性
①在计算a+b之前,需要准备数据
主内存->L3->L2->L1->寄存器
L1:访问延时 0.5ns
L2:访问延时 7 ns(14 * L1)
主内存访问延时: 100ns(200 * L1),内存访问太慢了
② 提升空间和时间的内存本地性
时间:重用数据使得保持他们在缓存里(寄存器)
空间:按序读写数据使得可以预读取(数据相邻)
【例】
如果一个矩阵是按行存储的,访问一行比访问一列要快(按行的地址是连续的,读取快)
CPU一次读取64字节(缓存线)
CPU会“聪明的”提前读取下一个(缓存线)
2.提升CPU利用率 Ⅱ,尽量使用多核并行计算
①高端CPU有几十个核
②并行来利用所有核
超线程不一定提升性能,因为它们共享寄存器
3.提升GPU利用率
①并行,使用数千个线程
②内存本地性,缓存更小,架构更简单(GPU为了节省面积将缓存做得比较小,这样做的好处是内存的带宽会更高一点)
③少用控制语句,支持有限,同步开销大。
4.GPU和CPU的对比 一般/高端

①GPU核数量远多于CPU,导致GPU每秒计算高于CPU
②每一次计算需要从内存读取数据,所以内存带宽很重要,达不到计算峰值是内存带宽的限制
③核心数量和内存带宽使GPU比CPU运算快,但GPU内存小,控制流弱。CPU做通用计算,控制流强。
4.CPU和GPU之间的带宽不是很高,多个GPU还要共享带宽,所以不要频繁在CPU和GPU之间传数据:带宽限制,同步开销。
总结:
①CPU:可以处理通用计算。性能优化考虑数据的读写效率和多线程
②GPU:使用更多的小核和更好的内存带宽,适合能大规模并行的计算任务
深度学习硬件:TPU
1.DSP:数字信号处理
①为数字信号处理算法设计:点积,卷积,FFT
②低功耗,高性能
③一条指令计算上百次乘累加
缺点:编程和调试困难,编译器良莠不齐
2.可编程陈列(FPGA)
①有大量的可以编程逻辑单元和可配置的连接
②可以配置成计算复杂函数
③通常比通用硬件更高效
缺点:工具链质量良莠不齐,一次编译需要数小时
3.Google TPU芯片
①跟英伟达GPU性能媲美
②Google内部部署,核心是systolic array
4.systolic array
①计算单元(PE)阵列
②适合做矩阵乘法
③设计和制造相对简单

【总结】

单机多卡并行
1.
①一台机器可以装多个GPU(1-16)
②在训练和预测时,将一个小批量计算切分到多个GPU上来加速
③常用的切分方案:数据并行,模型并行,通道并行(数据+模型并行)
2.数据并行VS模型并行
①数据并行:将小批量分成n块,每个GPU拿到完整参数计算一块数据的梯度
通常性能更好
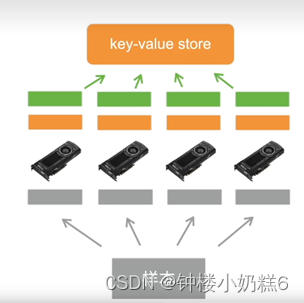
步骤:Ⅰ读一个数据块 Ⅱ拿回参数 Ⅲ计算梯度 Ⅳ发出梯度
②模型并行:将模型分成n块,每个GPU拿到一块模型计算它的前向和反向的结果
通常用于模型大到单GPU放不下
【总结】
①当一个模型能用单卡计算时,通常使用数据并行扩展到多卡上
②模型并行用到大模型上