🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
什么是词向量/词嵌入
词向量的理解 TODO
Word2Vec
基于层次 SoftMax 的 CBOW 模型
层次 SoftMax 的正向传播
层次 Softmax 的反向传播 TODO
基于层次 Softmax 的 Skip-gram 模型
---
基于负采样的 CBOW 和 Skip-gram
负采样算法
Word2Vec 中的做法
一些源码细节
σ(x) 的近似计算
低频词的处理
高频词的处理
自适应学习率
参数初始化
GloVe
共现矩阵
构架共现矩阵的细节
GloVe 的基本思想
GloVe 的目标函数
GloVe 目标函数的推导过程
GloVe 与 Word2Vec 的区别
FastText
gensim.models.FastText 使用示例
获取单个词的 ngrams 表示
计算一个未登录词的词向量
WordRank TODO
CharCNN 字向量
其他实践
一般 embedding 维度的选择
什么是词向量/词嵌入
- 词向量(word embedding)是一个固定长度的实值向量
- 词向量是神经语言模型的副产品。
- 词向量是针对“词”提出的。事实上,也可以针对更细或更粗的粒度来进行推广——比如字向量、句向量、文档向量等
词向量的理解 TODO
word2vec 中的数学原理详解(三)背景知识 - CSDN博客
- 在 NLP 任务中,因为机器无法直接理解自然语言,所以首先要做的就是将语言数学化——词向量就是一种将自然语言数学化的方法。
One-hot 表示
- TODO
分布式表示 (distributed representation)
- 分布式假设
- TODO
- 常见的分布式表示方法
- 潜在语义分析 (Latent Semantic Analysis, LSA)
- SVD 分解
- 隐含狄利克雷分布 (Latent Dirichlet Allocation, LDA),主题模型
- 神经网络、深度学习
- 潜在语义分析 (Latent Semantic Analysis, LSA)
Word2Vec
-
Word2Vec 本质上也是一个神经语言模型,但是它的目标并不是语言模型本身,而是词向量;因此,其所作的一系列优化,都是为了更快更好的得到词向量
-
Word2Vec 提供了两套模型:CBOW 和 Skip-Gram(SG)
- CBOW 在已知
context(w)的情况下,预测w - SG 在已知
w的情况下预测context(w)
- CBOW 在已知
-
从训练集的构建方式可以更好的理解和区别 CBOW 和 SG 模型
-
每个训练样本为一个二元组
(x, y),其中x为特征,y为标签假设上下文窗口的大小
context_window =5,即
或者说
skip_window = 2,有context_window = skip_window*2 + 1 -
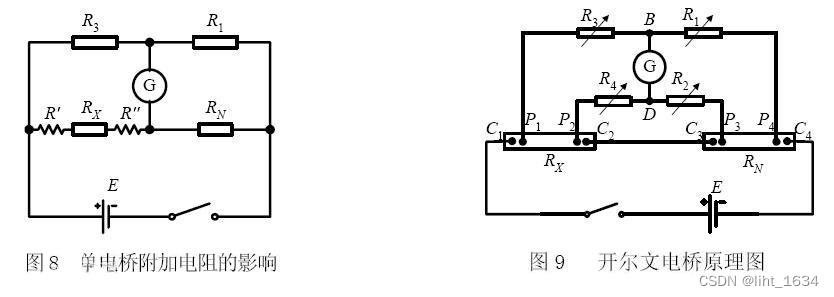
CBOW 的训练样本为:
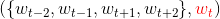
-
SG 的训练样本为:

-
一般来说,
skip_window <= 10
-
-
除了两套模型,Word2Vec 还提供了两套优化方案,分别基于 Hierarchical Softmax (层次SoftMax) 和 Negative Sampling (负采样)
基于层次 SoftMax 的 CBOW 模型
-
【输入层】将
context(w)中的词映射为m维词向量,共2c个 -
【投影层】将输入层的
2c个词向量累加求和,得到新的m维词向量 -
【输出层】输出层对应一棵哈夫曼树,以词表中词作为叶子节点,各词的出现频率作为权重——共
N个叶子节点,N-1个非叶子节点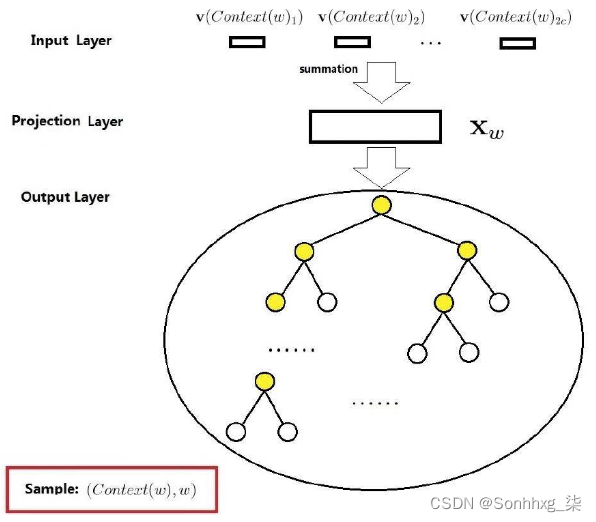
-
对比 N-gram 神经语言模型的网络结构
- 【输入层】前者使用的是
w的前n-1个词,后者使用w两边的词这是后者词向量的性能优于前者的主要原因
- 【投影层】前者通过拼接,后者通过累加求和
- 【隐藏层】后者无隐藏层
- 【输出层】前者为线性结构,后者为树形结构
- 【输入层】前者使用的是
-
模型改进
- 从对比中可以看出,CBOW 模型的主要改进都是为了减少计算量——取消隐藏层、使用层Softmax代替基本Softmax
层次 SoftMax 的正向传播
-
层 Softmax 实际上是把一个超大的多分类问题转化成一系列二分类问题
-
示例:求
P("足球"|context("足球"))
-
从根节点到“足球”所在的叶子节点,需要经过 4 个分支,每次分支相当于一次二分类(逻辑斯蒂回归,二元Softmax)

这里遵从原文,将 0 作为正类,1 作为负类
-
而
P("足球"|context("足球"))就是每次分类正确的概率之积,即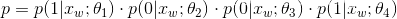
这里每个非叶子都对应一个参数
θ_i
-
为什么层次 SoftMax 能加速
- Softmax 大部分的计算量在于分母部分,它需要求出所有分量的和
- 而层次 SoftMax 每次只需要计算两个分量,因此极大的提升了速度
层次 Softmax 的反向传播 TODO
word2vec 中的数学原理详解(四)基于 Hierarchical Softmax 的模型 - CSDN博客
基于层次 Softmax 的 Skip-gram 模型
-
这里保留了【投影层】,但实际上只是一个恒等变换
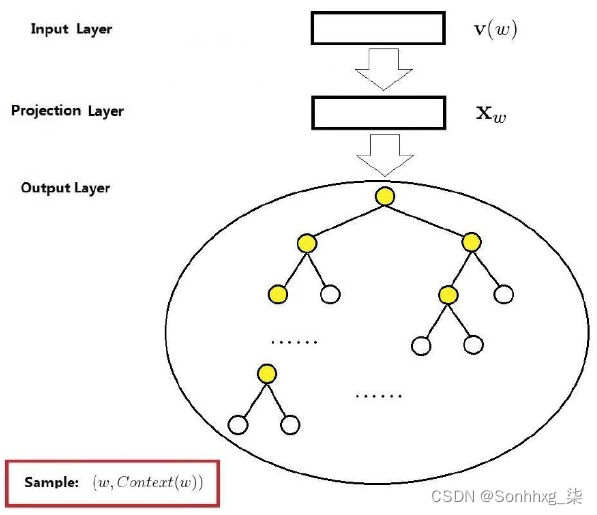
-
从模型的角度看:CBOW 与 SG 模型的区别仅在于
x_w的构造方式不同,前者是context(w)的词向量累加;后者就是w的词向量 -
虽然 SG 模型用中心词做特征,上下文词做类标,但实际上两者的地位是等价的
---
基于负采样的 CBOW 和 Skip-gram
- 层次 Softmax 还不够简单,于是提出了基于负采样的方法进一步提升性能
- 负采样(Negative Sampling)是 NCE(Noise Contrastive Estimation) 的简化版本
噪音对比估计(NCE) - CSDN博客
- CBOW 的训练样本是一个
(context(w), w)二元对;对于给定的context(w),w就是它的正样本,而其他所有词都是负样本。 - 如果不使用负采样,即 N-gram 神经语言模型中的做法,就是对整个词表 Softmax 和交叉熵
- 负采样相当于选取所有负例中的一部分作为负样本,从而减少计算量
- Skip-gram 模型同理
负采样算法
- 负采样算法,即对给定的
w,生成相应负样本的方法 - 最简单的方法是随机采样,但这会产生一点问题,词表中的词出现频率并不相同
- 如果不是从词表中采样,而是从语料中采样;显然,那些高频词被选为负样本的概率要大于低频词
- 在词表中采样时也应该遵循这个
- 因此,负采样算法实际上就是一个带权采样过程

Word2Vec 中的做法
-
记
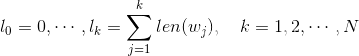
-
以这
N+1个点对区间[0,1]做非等距切分 -
引入的一个在区间
[0,1]上的M等距切分,其中M >> N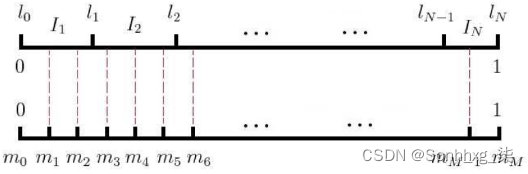
源码中取
M = 10^8 -
然后对两个切分做投影,得到映射关系
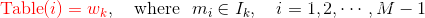
-
采样时,每次生成一个
[1, M-1]之间的整数i,则Table(i)就对应一个样本;当采样到正例时,跳过(拒绝采样)。 -
特别的,Word2Vec 在计算
len(w)时做了一些改动——为count(·)加了一个指数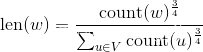
一些源码细节
σ(x) 的近似计算
-
类似带权采样的策略,用查表来代替计算

-
具体计算公式如下

因为
σ(x)函数的饱和性,当x < -6 || x > 6时,函数值基本不变了
低频词的处理
- 对于低频词,会设置阈值(默认 5),对于出现频次低于该阈值的词会直接舍弃,同时训练集中也会被删除
高频词的处理
- 高频词提供的信息相对较少,为了提高低频词的词向量质量,有必要对高频词进行限制
- 高频词对应的词向量在训练时,不会发生明显的变化,因此在训练是可以减少对这些词的训练,从而提升速度
Sub-sampling 技巧
- 源码中使用 Sub-sampling 技巧来解决高频词的问题,能带来 2~10 倍的训练速度提升,同时提高低频词的词向量精度
- 给定一个词频阈值
t,将w以p(w)的概率舍弃,p(w)的计算如下
Word2Vec 中的Sub-sampling
- 显然,Sub-Sampling 只会针对 出现频次大于
t的词 - 特别的,Word2Vec 使用如下公式计算
p(w),效果是类似的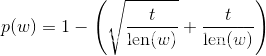
自适应学习率
-
预先设置一个初始的学习率
η_0(默认 0.025),每处理完M(默认 10000)个词,就根据以下公式调整学习率
-
随着训练的进行,学习率会主键减小,并趋向于 0
-
为了方式学习率过小,Word2Vec 设置了一个阈值
η_min(默认0.0001 * η_0);当学习率小于η_min,则固定为η_min。
参数初始化
- 词向量服从均匀分布
[-0.5/m, 0.5/m],其中m为词向量的维度 - 所有网络参数初始化为
0
GloVe
CS224d - L2&3-词向量
共现矩阵
- 共现矩阵的实现方式
-
基于文档 - LSA 模型(SVD分解)
-
基于窗口 - 类似 skip-gram 模型中的方法
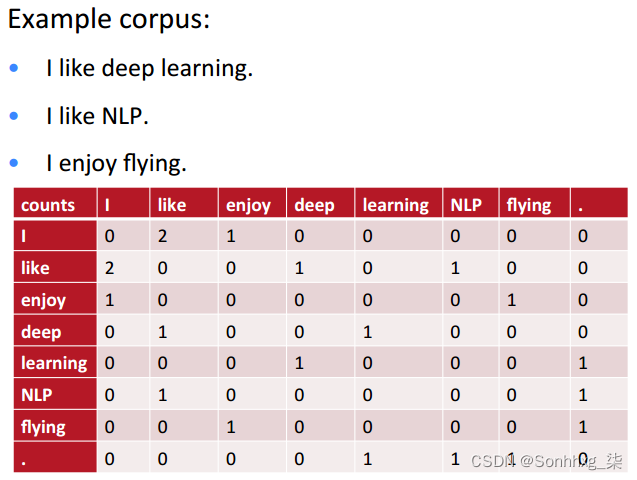
skip_window = 1的共现矩阵
-
构架共现矩阵的细节
- 功能词的处理
- 功能词:如 "the", "he", "has", ...
- 法1)直接忽略
- 在一些分类问题上可以这么做;如果目标是词向量,则不建议使用这种方法
- 法2)设置阈值
min(x, t)- 其中
x为功能词语其他词的共现次数,t为设置的阈值
- 其中
- 可以尝试使用一些方法代替单纯的计数,如皮尔逊相关系数,负数记为 0
但是似乎没有人这么做
GloVe 的基本思想
-
GloVe 模型的是基于共现矩阵构建的
-
GloVe 认为共现矩阵可以通过一些统计信息得到词之间的关系,这些关系可以一定程度上表达词的含义
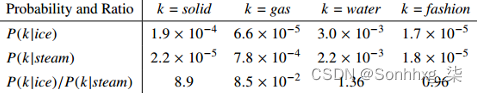
- solid related to ice but not steam
- gas related to stream but not ice
- water related to both
- fashion relate not to both
说明 TODO
-
GloVe 的基本思想:
- 假设词向量已知,如果这些词向量通过某个函数(目标函数)可以拟合共现矩阵中的统计信息,那么可以认为这些词向量也拥有了共现矩阵中蕴含的语义
- 模型的训练过程就是拟合词向量的过程
GloVe 的目标函数
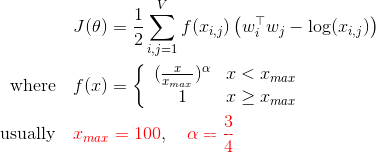
其中
-
w_i和w_j为词向量 -
x_ij为w_i和w_j的共现次数 -
f(x)是一个权重函数,为了限制高频词和防止x_ij = 0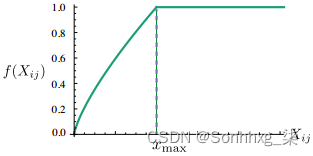
- 当
x_ij = 0时,有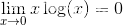
- 当
GloVe 目标函数的推导过程
以前整理在 OneNote 上的,有时间在整理
-
目标函数





-
w_i的权重函数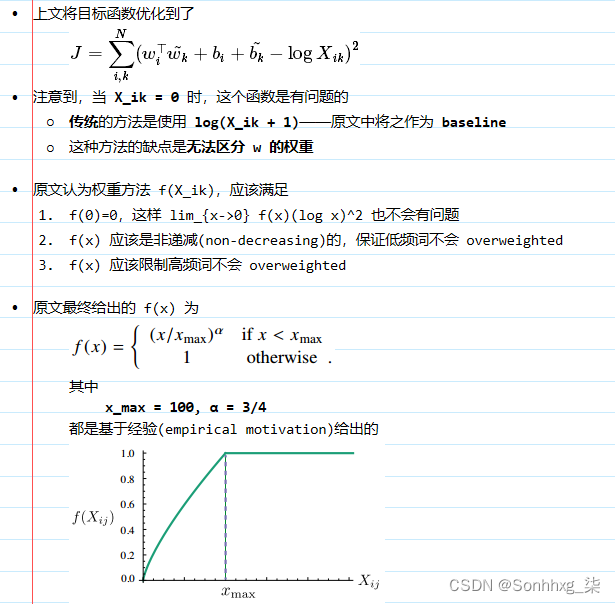
GloVe 与 Word2Vec 的区别
- Word2Vec 本质上是一个神经网络;
Glove 也利用了反向传播来更新词向量,但是结构要更简单,所以 GloVe 的速度更快 - Glove 认为 Word2Vec 对高频词的处理还不够,导致速度慢;GloVe 认为共现矩阵可以解决这个问题
实际 Word2Vec 已结有了一些对高频词的措施 > 高频词的处理
- 从效果上看,虽然 GloVe 的训练速度更快,但是词向量的性能在通用性上要弱一些:
在一些任务上表现优于 Word2Vec,但是在更多的任务上要比 Word2Vec 差
FastText
-
FastText 是从 Word2Vec 的 CBOW 模型演化而来的;
从网络的角度来看,两者的模型基本一致;区别仅在于两者的输入和目标函数不同;
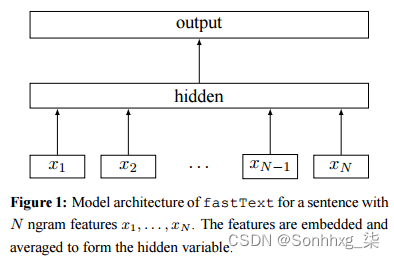
基于层次 SoftMax 的 CBOW 模型
-
FastText 与 CBOW 的相同点:
- 包含三层:输入层、隐含层、输出层(Hierarchical Softmax)
- 输入都是多个单词的词向量
- 隐藏层(投影层)都是对多个词向量的叠加平均
- 输出都是一个特定的 target
- 从网络的角度看,两者基本一致
-
不同点:
- CBOW 的输入是中心词两侧
skip_window内的上下文词;FastText 除了上下文词外,还包括这些词的字符级 N-gram 特征
- CBOW 的输入是中心词两侧
-
注意,字符级 N-gram 只限制在单个词内,以英文为例
// 源码中计算 n-grams 的声明,只计算单个词的字符级 n-gram compute_ngrams(word, unsigned int min_n, unsigned int max_n);# > https://github.com/vrasneur/pyfasttext#get-the-subwords >>> model.args.get('minn'), model.args.get('maxn') (2, 4) # 调用源码的 Python 接口,源码上也会添加 '<' 和 '>' >>> model.get_all_subwords('hello') # word + subwords from 2 to 4 characters ['hello', '<h', '<he', '<hel', 'he', 'hel', 'hell', 'el', 'ell', 'ello', 'll', 'llo', 'llo>', 'lo', 'lo>', 'o>'] >>> # model.get_all_subwords('hello world') # warning -
值得一提的是,因为 FastText 使用了字符级的 N-gram 向量作为额外的特征,使其能够对未登录词也能输出相应的词向量;
具体来说,未登录词的词向量等于其 N-gram 向量的叠加
gensim.models.FastText 使用示例
../codes/FastText
- 构建 FastText 以及获取词向量
# gensim 示例 import gensim import numpy as np from gensim.test.utils import common_texts from gensim.models.keyedvectors import FastTextKeyedVectors from gensim.models._utils_any2vec import compute_ngrams, ft_hash from gensim.models import FastText # 构建 FastText 模型 sentences = [["Hello", "World", "!"], ["I", "am", "huay", "."]] min_ngrams, max_ngrams = 2, 4 # ngrams 范围 model = FastText(sentences, size=5, min_count=1, min_n=min_ngrams, max_n=max_ngrams) # 可以通过相同的方式获取每个单词以及任一个 n-gram 的向量 print(model.wv['hello']) print(model.wv['<h']) """ [-0.03481839 0.00606661 0.02581969 0.00188777 0.0325358 ] [ 0.04481247 -0.1784363 -0.03192253 0.07162753 0.16744071] """ print() # 词向量和 n-gram 向量是分开存储的 print(len(model.wv.vectors)) # 7 print(len(model.wv.vectors_ngrams)) # 57 # gensim 好像没有提供直接获取所有 ngrams tokens 的方法 print(model.wv.vocab.keys()) """ ['Hello', 'World', '!', 'I', 'am', 'huay', '.'] """ print()
获取单个词的 ngrams 表示
- 利用源码中
compute_ngrams方法,gensim 提供了该方法的 Python 接口sum_ngrams = 0 for s in sentences: for w in s: w = w.lower() # from gensim.models._utils_any2vec import compute_ngrams ret = compute_ngrams(w, min_ngrams, max_ngrams) print(ret) sum_ngrams += len(ret) """ ['<h', 'he', 'el', 'll', 'lo', 'o>', '<he', 'hel', 'ell', 'llo', 'lo>', '<hel', 'hell', 'ello', 'llo>'] ['<w', 'wo', 'or', 'rl', 'ld', 'd>', '<wo', 'wor', 'orl', 'rld', 'ld>', '<wor', 'worl', 'orld', 'rld>'] ['<!', '!>', '<!>'] ['<i', 'i>', '<i>'] ['<a', 'am', 'm>', '<am', 'am>', '<am>'] ['<h', 'hu', 'ua', 'ay', 'y>', '<hu', 'hua', 'uay', 'ay>', '<hua', 'huay', 'uay>'] ['<.', '.>', '<.>'] """ assert sum_ngrams == len(model.wv.vectors_ngrams) print(sum_ngrams) # 57 print()
计算一个未登录词的词向量
-
未登录词实际上是已知 n-grams 向量的叠加平均
# 因为 "a", "aa", "aaa" 中都只含有 "<a" ,所以它们实际上都是 "<a" print(model.wv["a"]) print(model.wv["aa"]) print(model.wv["aaa"]) print(model.wv["<a"]) """ [ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ] [ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ] [ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ] [ 0.00226487 -0.19139008 0.17918809 0.13084619 -0.1939924 ] """ print() -
只要未登录词能被已知的 n-grams 组合,就能得到该词的词向量
gensim.models.keyedvectors.FastTextKeyedVectors.word_vec(token)的内部实现word_unk = "aam" ngrams = compute_ngrams(word_unk, min_ngrams, max_ngrams) # min_ngrams, max_ngrams = 2, 4 word_vec = np.zeros(model.vector_size, dtype=np.float32) ngrams_found = 0 for ngram in ngrams: ngram_hash = ft_hash(ngram) % model.bucket if ngram_hash in model.wv.hash2index: word_vec += model.wv.vectors_ngrams[model.wv.hash2index[ngram_hash]] ngrams_found += 1 if word_vec.any(): # word_vec = word_vec / max(1, ngrams_found) else: # 如果一个 ngram 都没找到,gensim 会报错;个人认为把 0 向量传出来也可以 raise KeyError('all ngrams for word %s absent from model' % word_unk) print(word_vec) print(model.wv["aam"]) """ [ 0.02210762 -0.10488641 0.05512805 0.09150169 0.00725085] [ 0.02210762 -0.10488641 0.05512805 0.09150169 0.00725085] """ # 如果一个 ngram 都没找到,gensim 会报错 # 其实可以返回一个 0 向量的,它内部实际上是从一个 0 向量开始累加的; # 但返回时做了一个判断——如果依然是 0 向量,则报错 # print(model.wv['z']) """ Traceback (most recent call last): File "D:/OneDrive/workspace/github/DL-Notes-for-Interview/code/工具库 /gensim/FastText.py", line 53, in <module> print(model.wv['z']) File "D:\program\work\Python\Anaconda3\envs\tf\lib\site-packages\gensim\models \keyedvectors.py", line 336, in __getitem__ return self.get_vector(entities) File "D:\program\work\Python\Anaconda3\envs\tf\lib\site-packages\gensim\models \keyedvectors.py", line 454, in get_vector return self.word_vec(word) File "D:\program\work\Python\Anaconda3\envs\tf\lib\site-packages\gensim\models \keyedvectors.py", line 1989, in word_vec raise KeyError('all ngrams for word %s absent from model' % word) KeyError: 'all ngrams for word z absent from model' """
WordRank TODO
CharCNN 字向量
- CharCNN 的思想是通过字符向量得到词向量
[1509] Character-level Convolutional Networks for Text Classification
其他实践
一般 embedding 维度的选择
Feature Columns | TensorFlow
- 经验公式
embedding_size = n_categories ** 0.25 - 在大型语料上训练的词向量维度通常会设置的更大一些,比如
100~300如果根据经验公式,是不需要这么大的,比如 200W 词表的词向量维度只需要
200W ** 0.25 ≈ 37












![[SpringBoot] YAML基础语法](https://img-blog.csdnimg.cn/036a59853e7a4ad89c2b4d775759999d.png)