1、概述
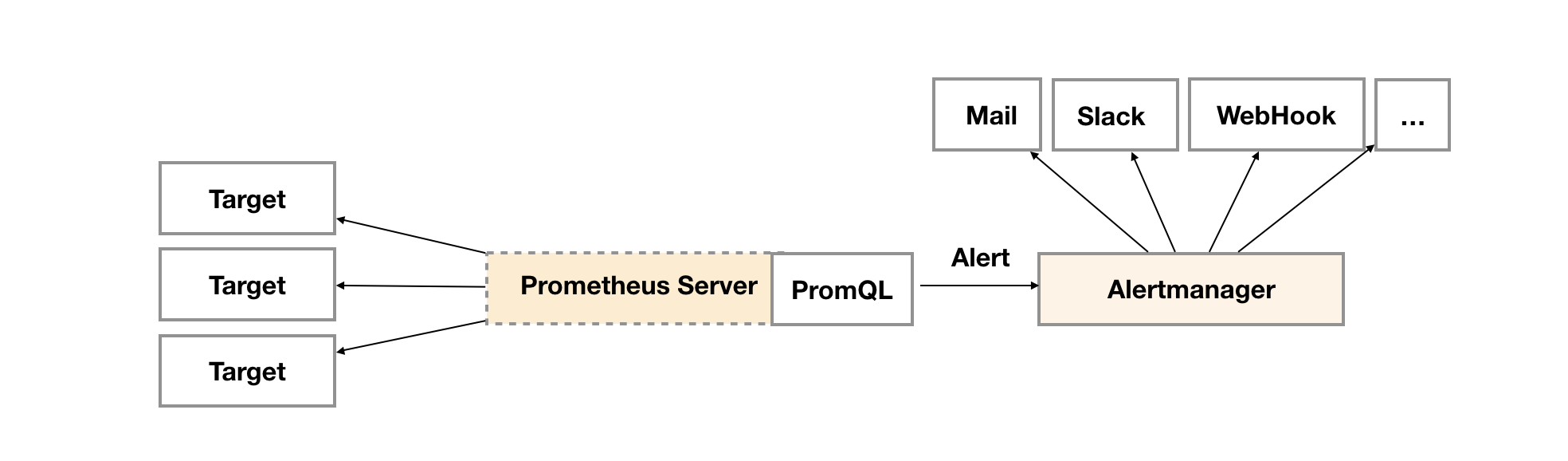
在Prometheus的架构中告警被划分为两个部分,在Prometheus Server中定义告警规则以及产生告警,Alertmanager组件则用于处理这些由Prometheus产生的告警。本文主要讲解Prometheus发送告警机制也就是在Prometheus Server中定义告警规则和产生告警部分,不过多介绍Alertmanager组件。

2、在Prometheus Server中定义告警规则
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
在Prometheus中,还可以通过Group(告警组)对一组相关的告警进行统一定义。当然这些定义都是通过YAML文件来统一管理的。
2.1 定义告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当满足触发条件后则会触发告警通知。默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态。当Promthues与Alertmanager关联之后,可以将告警发送到外部服务如Alertmanager中并通过Alertmanager可以对这些告警进行进一步的处理。
一条典型的告警规则如下所示:
| 1 2 3 4 5 6 7 8 9 10 11 |
|
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
- alert:告警规则的名称。
- expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。
为了能够让Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
| 1 2 |
|
默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期:
| 1 2 |
|
2.2 模板化
一般来说,在告警规则文件的annotations中使用summary描述告警的概要信息,description用于描述告警的详细信息。同时Alertmanager的UI也会根据这两个标签值,显示告警信息。为了让告警信息具有更好的可读性,Prometheus支持模板化label和annotations的中标签的值。
通过$labels.<labelname>变量可以访问当前告警实例中指定标签的值。$value则可以获取当前PromQL表达式计算的样本值。
| 1 2 3 4 |
|
例如,可以通过模板化优化summary以及description的内容的可读性:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
2.3 查看告警状态
如下所示,用户可以通过Prometheus WEB界面中的Alerts菜单查看当前Prometheus下的所有告警规则,以及其当前所处的活动状态。

同时对于已经pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中。
可以通过表达式,查询告警实例:
| 1 |
|
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时,样本值则为0。
3、Prometheus发送告警机制
在第二章节介绍了如何在Prometheus Server中定义告警规则,现在来讲一下定义的告警规则触发后,如何产生告警到目标接收器。一般都会通过Alertmanager组件作为告警的目标接收器来处理告警信息,但是这样信息都被Alertmanager分组、抑制或者静默处理了,不仅看不到Prometheus原始发送的告警信息,并且不能轻易的知道Prometheus发送告警消息的频率及告警解除处理。
在这里,我们自己写一个目标接收器来接收Prometheus发送的告警,并将告警打印出来。以此来研究告警信息,发送频率以及告警解除处理。
3.1 构建并在Kubernetes集群中部署告警目标接收器
1)alertmanager-imitate.go:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
2)构建告警目标接收器(Golang 应用一般可以使用如下形式的 Dockerfile):
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
3)构建应用容器镜像,并将镜像传到镜像仓库中,此步骤比较简单,本文不再赘余。
4)定义Deployment:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
5)同时需要 Kubernetes Service 做服务发现和负载均衡:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
3.2 关联Prometheus与告警目标接收器
在Kubernetes集群中,一直通过Prometheus Operator部署和管理Prometheus Server,所以只需修改当前Kubernetes集中的prometheuses.monitoring.coreos.com资源对象即可轻易关联Prometheus与告警目标接收器。
| 1 2 3 4 5 6 7 8 9 |
|
注意:如果对Prometheus Operator不熟的话,可以先看《容器云平台监控告警体系(三)—— 使用Prometheus Operator部署并管理Prometheus Server 》这篇博文。
3.3 通过自定义告警规则验证Prometheus发送告警机制
这里测试的告警规则很简单,Prometheus每隔15秒会对告警规则进行计算(evaluationInterval: 15s),如果nginx-alter-test-v1这个工作负载实例数持续2分钟>=2则触发告警,并发送告警消息给告警目标接收器。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
由于新创建的告警规则组(replicas.rules)底下的告警规则没没触发,当前告警组的状态为inactives,由于replicas.rules告警规则组下的告警规则HignReplicas当前并没触发,所以是0活跃。

将工作负载nginx-alter-test-v1实例数改为4。 Prometheus首次检测到满足触发条件后,将当前告警状态为PENDING,如下图所示:

注意 1: Active Since是首次检测到满足告警触发条件的时间。
注意 2:如果当前告警规则下有多个监控目标满足此告警规则,那么active值等于满足监控目标数。

如果2分钟后告警条件持续满足,则会实际触发告警并且告警状态为FIRING,如下图所示:

3.4 Prometheus发送的原始告警信息及发送告警消息频率
下面我们通过alertmanager-imitate Pod日志来分析Prometheus发送告警消息频率。
| 1 2 3 4 5 6 7 8 9 10 |
|
着重看一下Prometheus发送过来的第一条告警消息,可以看到第一次发送告警消息时间是告警Firing时间,也就是 Active Since 时间 + for时间(持续检测时间)。
| 1 |
|
下面分析下Prometheus原始发送的告警信息。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
注意1 : endsAt 为什么是 4 分钟的问题,这是因为 Prometheus 中的告警默认有一个 4 分钟的“静默期”(silence period)。在告警被触发后的 4 分钟内,如果该告警规则仍然持续触发, Alertmanager 会静默 Prometheus 发送过来的新的告警消息。如果告警解除,那么 endsAt 将设置为告警解除的时间。您可以通过调整 Prometheus 的配置文件来更改这个默认的“静默期”时间。
注意 2:如果一个告警规则下有多个监控目标满足此告警规则,则会将这多个监控目标产生的告警信息合并到一个数组中一起发送给告警目标接收器,如下示例,一个告警规则中有4个监控目标满足此告警规则,那么产生的这一条告警消息中包含这4个监控目标产生的告警信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
[{
"annotations": {
"description": "10.233.65.207:15020 job istio-system/envoy-stats-monitor 已经宕机1分钟以上!",
"summary": "主机 10.233.65.207:15020 停止工作"
},
"endsAt": "2023-04-23T23:42:15.994Z",
"startsAt": "2023-04-23T23:38:15.994Z",
"generatorURL": "http://prometheus-k8s-0:9090/graph?g0.expr=up+%3D%3D+0\u0026g0.tab=1",
"labels": {
"alertname": "主机宕机",
"container": "istio-proxy",
"instance": "10.233.65.207:15020",
"job": "istio-system/envoy-stats-monitor",
"namespace": "controls-system",
"pod": "router-ceshi07-58d5bc476c-4xj5s",
"pod_name": "router-ceshi07-58d5bc476c-4xj5s",
"prometheus": "monitoring-system/k8s",
"serverity": "error"
}
}, {
"annotations": {
"description": "10.233.65.210:15020 job istio-system/envoy-stats-monitor 已经宕机1分钟以上!",
"summary": "主机 10.233.65.210:15020 停止工作"
},
"endsAt": "2023-04-23T23:42:15.994Z",
"startsAt": "2023-04-23T23:38:15.994Z",
"generatorURL": "http://prometheus-k8s-0:9090/graph?g0.expr=up+%3D%3D+0\u0026g0.tab=1",
"labels": {
"alertname": "主机宕机",
"container": "istio-proxy",
"instance": "10.233.65.210:15020",
"job": "istio-system/envoy-stats-monitor",
"namespace": "controls-system",
"pod": "router-ceshi13-5ff5b8f949-htmbr",
"pod_name": "router-ceshi13-5ff5b8f949-htmbr",
"prometheus": "monitoring-system/k8s",
"serverity": "error"
}
}, {
"annotations": {
"description": "10.233.64.233:15090 job envoy-stats 已经宕机1分钟以上!",
"summary": "主机 10.233.64.233:15090 停止工作"
},
"endsAt": "2023-04-23T23:42:15.994Z",
"startsAt": "2023-04-23T23:38:15.994Z",
"generatorURL": "http://prometheus-k8s-0:9090/graph?g0.expr=up+%3D%3D+0\u0026g0.tab=1",
"labels": {
"alertname": "主机宕机",
"instance": "10.233.64.233:15090",
"job": "envoy-stats",
"namespace": "efr",
"pod_name": "nginx-v1-5d654cdf88-k689w",
"prometheus": "monitoring-system/k8s",
"serverity": "error"
}
}, {
"annotations": {
"description": "10.233.65.207:15090 job envoy-stats 已经宕机1分钟以上!",
"summary": "主机 10.233.65.207:15090 停止工作"
},
"endsAt": "2023-04-23T23:42:15.994Z",
"startsAt": "2023-04-23T23:38:15.994Z",
"generatorURL": "http://prometheus-k8s-0:9090/graph?g0.expr=up+%3D%3D+0\u0026g0.tab=1",
"labels": {
"alertname": "主机宕机",
"instance": "10.233.65.207:15090",
"job": "envoy-stats",
"namespace": "controls-system",
"pod_name": "router-ceshi07-58d5bc476c-4xj5s",
"prometheus": "monitoring-system/k8s",
"serverity": "error"
}注意 3:如果同一个告警组底下有多个告警规则,并且他们的for配置一样,Prometheus会周期性的检查这个告警组下的所有告警规则,如果被检查时,有多个告警规则满足触发条件,那么这多个告警规则对应的监控目标的Active Since是时间应该是一致的,示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
groups:
- name: replicas.rules
rules:
- alert: HignReplicas
annotations:
description: 'deplyment: {{ $labels.deployment }} 当前实例数为: {{ $value }}'
summary: nginx-alter-test-v1实例数过高
expr: kube_deployment_spec_replicas{deployment="nginx-alter-test-v1"} >= 2
for: 2m
labels:
serverity: error
- alert: 主机宕机
expr: up == 0
for: 2m
labels:
serverity: error
annotations:
summary: "主机 {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} job {{ $labels.job }} 已经宕机1分钟以上!"
但是发送告警消息时,不同的告警规则单独发送一条告警消息。
1
2
3
4
5
023-04-24 00:06:47.076024777 +0000 UTC m=+696.078198008
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 当前实例数为: 4","summary":"nginx-alter-test-v1实例数过高"},"endsAt":"2023-04-24T00:10:47.073Z","startsAt":"2023-04-23T23:56:47.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"-monitoring-system/k8s","serverity":"error"}}]
2023-04-24 00:06:47.07869065 +0000 UTC m=+696.080863891
[{"annotations":{"description":"10.233.65.209:15020 job istio-system/envoy-stats-monitor 已经宕机1分钟以上!","summary":"主机 10.233.65.209:15020 停止工作"},"endsAt":"2023-04-24T00:10:47.073Z","startsAt":"2023-04-23T23:56:47.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=up+%3D%3D+0\u0026g0.tab=1","labels":{"alertname":"主机宕机","container":"istio-proxy","instance":"10.233.65.209:15020","job":"istio-system/envoy-stats-monitor","namespace":"-controls-system","pod":"-router-ceshi14-694765968c-rqjvl","pod_name":"-router-ceshi14-694765968c-rqjvl","prometheus":"-monitoring-system/k8s","serverity":"error"}},{"annotations":{"description":"10.233.64.228:15090 job envoy-stats 已经宕机1分钟以上!","summary":"主机 10.233.64.228:15090 停止工作"},"endsAt":"2023-04-24T00:10:47.073Z","sta......

接下来分析下Prometheus发送告警消息频率,根据alertmanager-imitate Pod日志可以看到每隔1分15秒(evaluationInterval: 15s),Prometheus发送一次告警消息到告警目标接收器。
接下来修改Prometheus告警计算周期的值,将其改成25秒。
| 1 2 3 4 5 6 7 8 |
|
过10分钟再观察alertmanager-imitate Pod日志,Prometheus发送告警消息频率变成了1分25秒,暂时可以得出如下结论,Prometheus发送告警消息频率:
| 1 |
|
注意:测试完后,再把时间间隔改成15秒。
3.5 告警解除处理
将工作负载nginx-alter-test-v1实例数改为1,解除告警。

这时再观察alertmanager-imitate Pod日志,着重看下解除告警后的第一条日志,结束时间不再是当前时间加4分钟,而是Prometheus检查到告警解除的时间。
| 1 2 3 4 5 6 7 8 9 10 |
|
再继续分析 alertmanager-imitate Pod日志,解除告警后Prometheus不是立马停止向告警目标接收器发送告警消息,而是会持续发送15分钟的告警消息到目标接收器,而这15分钟发送的告警消息的结束时间都是相同的值,即Prometheus检测到告警解除的时间。
注意:Prometheus定义的告警规则解除告警后为什么还会再发15分钟通知?
在 Prometheus 中,当一个告警规则被触发后,它会保持持续状态,直到被解除。为了确保管理员能够在告警解除后仍然得到通知,以便了解问题是否已经解决,Prometheus 提供了“告警静默”(Silence)的功能。
当一个告警规则被静默后,该告警规则在被解除之前,不会再次触发告警。但是,在告警规则解除之后的15分钟内,Prometheus 仍然会定期向管理员发送通知,以提醒管理员该告警规则已经解除。
这种重复通知的作用在于,确保管理员能够及时了解到告警规则的解除状态,以便在需要的情况下采取进一步的行动。例如,如果告警规则的解除状态发生了变化,管理员可能需要采取进一步的措施来确保问题已经解决。
需要注意的是,Prometheus 的告警规则可以配置告警静默的时间长度。如果管理员希望在解除告警规则之后立即停止重复通知,可以将告警静默时间设置为0。
总之,Prometheus 的重复通知功能可以帮助管理员了解告警规则的解除状态,以便在需要的情况下采取进一步的行动,从而更好地保障系统的稳定性和可靠性。
4、总结:
在Prometheus的架构中告警被划分为两个部分,在Prometheus Server中定义告警规则以及产生告警,Alertmanager组件则用于处理这些由Prometheus产生的告警。
- Prometheus会以evaluation_interval的间隔评估是否应该发送告警,当满足告警条件时Prometheus会以1min + evaluation_interval 的频率发送告警,第一次发送告警消息时间是告警Firing时间,也就是 Active Since 时间 + for时间(持续检测时间)。
- Prometheus会以evaluation_interval的间隔评估是否应该解除告警,当满足解除告警条件时Prometheus会以1min + evaluation_interval 的频率发送解除告警消息,持续发送15分钟,endsAt不再是当前时间加4分钟,而是Prometheus检查到告警解除的时间。
- 如果一个告警规则下有多个监控目标满足此告警规则,则会将这多个监控目标产生的告警信息合并到一个数组中一起发送给告警目标接收器。
- 如果同一个告警组底下有多个告警规则,并且他们的for配置一样,Prometheus会周期性的检查这个告警组下的所有告警规则,如果被检查时,有多个告警规则满足触发条件,那么这多个告警规则对应的监控目标的Active Since是时间应该是一致的,但是发送告警消息时,不同的告警规则单独发送一条告警消息。