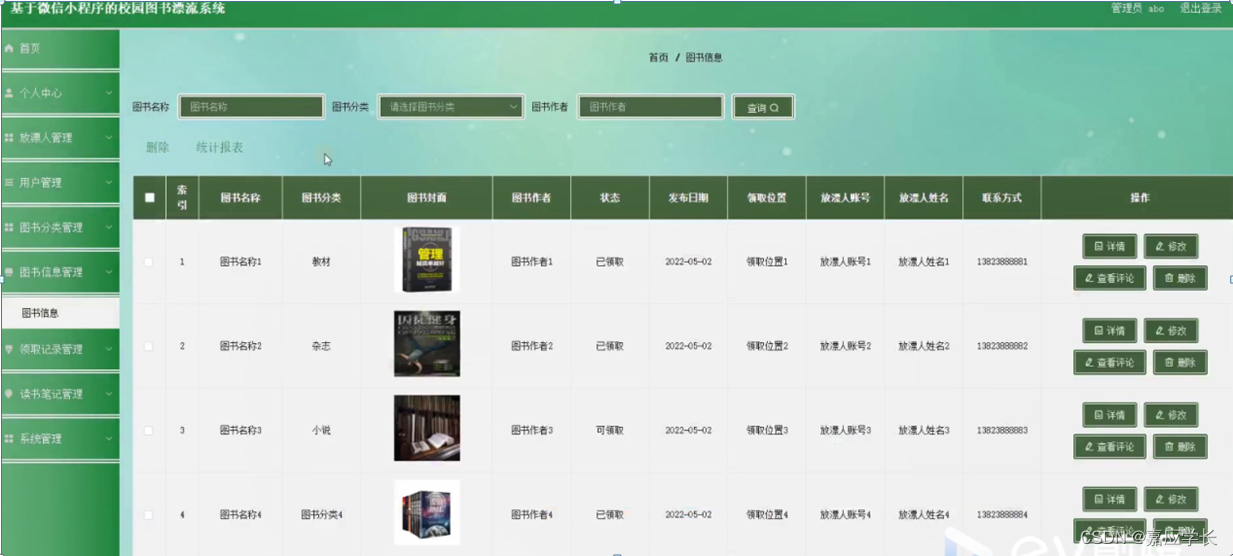
此脚本用于下载apache文件服务器中制定某个文件夹下所有文件与文件夹。
包含下载单个文件的方法、拼接url递归下载的方法、参数解析。
1 下载文件
功能点:
- 文件下载
以追加写的方式打开一个新文件,按照块大小写入文件
with open(filepath, 'wb') as file: # 显示进度条
for data in response.iter_content(chunk_size=1024):
file.write(data)
- 文件大小
content_size = int(response.headers['content-length'])
- 下载计时
这个简单,不做概述。 - 下载进度
转义符\r代表回车,也就是打印头归位,(光标)回到当前行的开头。
那么打印进度时,在前面加上该转义符,进度条则会覆盖住当前打印行,即可实现进度条刷新
print('\r'+"进度条:>>>")
print('\r'+"进度条:>>>>>")
print('\r'+"进度条:>>>")

2 下载链接
功能点:正则获取html中文件链接、拼接各级路径
由于apache文件服务器页面以html输出,且各文件、文件夹链接地址为相对地址,所以在解析html文件后,仍需对链接进行拼接。
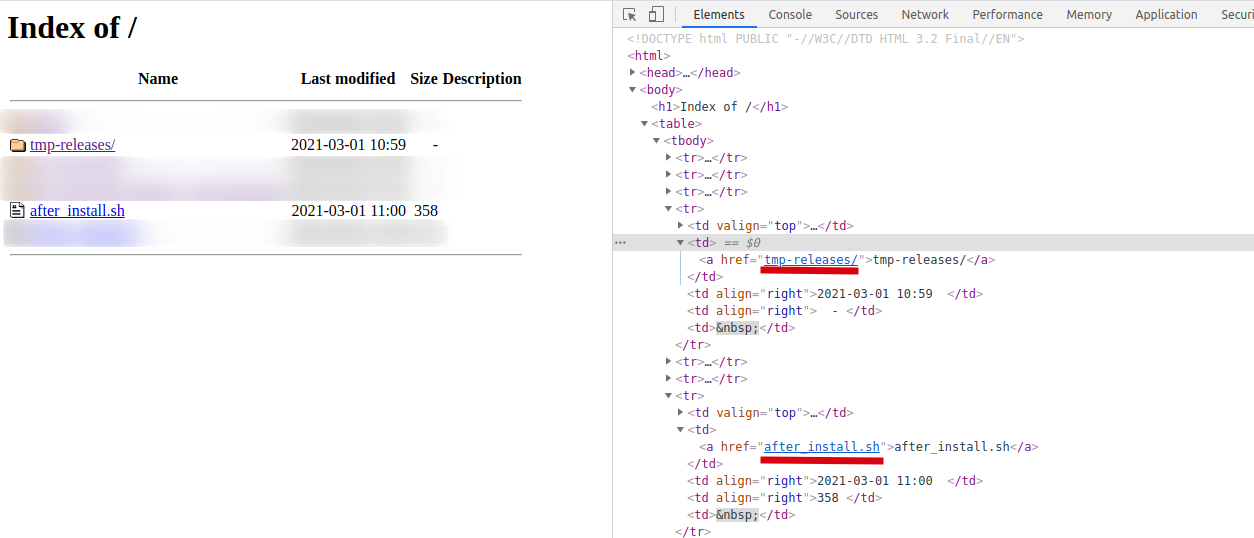
根据网页结构,目录的链接以/结束,则可以此为判断依据。
- 获取链接
response = requests.get(root_url).text
urls = re.findall(r'<td><a href="(.*?)">', response, re.S | re.M)
- 拼接
# 判断链接不是目录,是文件则调用下载方法,root_url是当前请求路径,url是文件名
if not url.endswith('/'):
tm += download_file(root_url+url, download_dir+url)
continue # 跳过当前循环
# 至此,url只能是目录
# root_url拼接下一级目录url,递归调用当前获取url的方法
3 参数读取
模仿终端中大部分命令的执行方式,以--参数名=参数值的方法进行参数的传递。
思路: 构建参数字典,将参数以等号分割,去除左边的短横,根据参数名调用字典key,将参数值赋值到value。
查看完整代码
import requests, re, time, os, sys
def download_file(url, filepath):
start = time.time() # 下载开始时间
response = requests.get(url, stream=True) # stream=True必须写上
size = 0 # 初始化已下载大小
chunk_size = 1024 # 每次下载的数据大小
content_size = int(response.headers['content-length']) # 下载文件总大小
try:
if response.status_code == 200: # 判断是否响应成功
print('Downloading {file}, [File size]:{size:.2f} MB'.format(
file=filepath,
size=content_size / chunk_size / 1024)) # 开始下载,显示下载文件大小
with open(filepath, 'wb') as file: # 显示进度条
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
st = '>' * int(size * 50 / content_size)
if size == 0:
st = '>' * 50
print('\r' + '[下载进度]:%s%.2f%%' % (
st.ljust(50, " "),
float(size / content_size * 100)), end=' ')
end = time.time() # 下载结束时间
print('\tCompleted!,times: %.2f秒' % (end - start)) # 输出下载用时时间
return end - start
except:
print("error")
def download_url(root_url, download_dir="downloads/"):
if not download_dir.endswith('/'):
download_dir += '/'
response = requests.get(root_url).text
urls = re.findall(r'<td><a href="(.*?)">', response, re.S | re.M)
os.makedirs(download_dir, exist_ok=True)
tm = float(0)
for url in urls:
if url == '/':
continue
if not url.endswith('/'):
tm += download_file(root_url+url, download_dir+url)
continue
tm += download_url(root_url+url, download_dir=download_dir+url)
return tm
if __name__ == '__main__':
sys_args = sys.argv[1:]
user_args_key = {0: 'url', 1: 'dir'}
user_args = {'url': '', 'dir': ''}
if len(sys_args) == 2:
for i in range(len(sys_args)):
if '=' in sys_args[i]:
k, v = sys_args[i].rsplit('=', maxsplit=1)
if k.lstrip('-').rstrip('=') not in user_args:
print('error1')
exit(1)
user_args[k.lstrip('-').rstrip('=')] = v
else:
user_args[user_args_key[i]] = sys_args[i]
elif len(sys_args) == 0:
user_args['url'] = "http://172.20.188.160:8080/"
user_args['dir'] = 'iso'
else:
print('error2')
exit(1)
print("Files will be save to %s." % user_args['dir'])
tm = download_url(user_args['url'], user_args['dir'])
print('Total Completed!,times: %.2f秒' % tm)
![[附源码]Python计算机毕业设计SSM基于JAVA语言的宠物寄养管理(程序+LW)](https://img-blog.csdnimg.cn/b106f4b83f3141ec938f60d3336b7295.png)

![[附源码]Python计算机毕业设计SSM基于web的社团管理系统(程序+LW)](https://img-blog.csdnimg.cn/8ad3feb0d56b4a108c6490c7be94721b.png)

![[附源码]计算机毕业设计的小说阅读系统Springboot程序](https://img-blog.csdnimg.cn/73d5602892d74fe2828e44483b16f316.png)


![[附源码]Nodejs计算机毕业设计基于Web课堂签到管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/cb6e87ab6c944157a47ea5c78c6b1d4a.png)