我们来彻底搞懂 Batch Normalization(BN) 在训练和测试阶段的区别,以及 测试时怎么用。
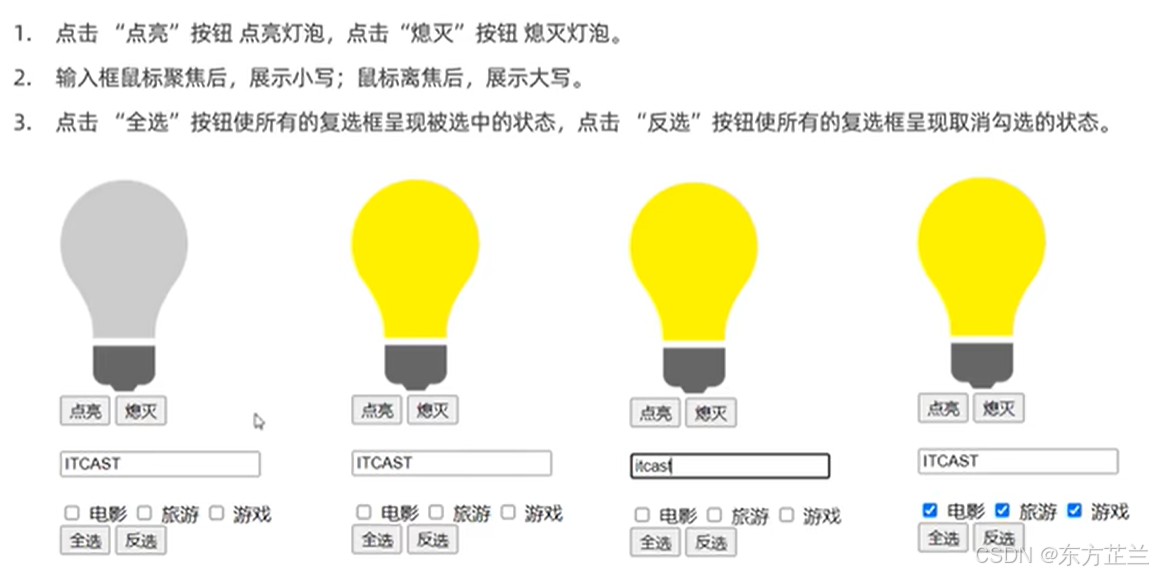
🧠 一句话总结:
训练时:使用 当前 mini-batch 的均值和方差
测试时:使用 整个训练集估计的“滑动平均均值和方差”
🧪 训练阶段的 BN(model.train()):
1. 对每个 mini-batch:
• 计算该 batch 的均值 μ 和方差 σ²
• 进行标准化:
• 然后进行缩放和平移:
2. 同时更新全局滑动均值和滑动方差(moving mean/var)用于测试。
✅ 测试阶段的 BN(model.eval()):
1. 不再用当前 batch 的统计量(因为测试数据可能 batch 很小,甚至 batch=1,统计不稳定)
2. 使用训练时保存下来的滑动均值和方差来做归一化:
🔁 在 PyTorch 中怎么做?
训练时:
model.train() # 启用 dropout、BN 用 batch 统计测试/验证时:
model.eval() # 关闭 dropout,BN 用全局 moving 均值/方差你想实际测试一个 BN 层,可以这样
import torch
import torch.nn as nn
bn = nn.BatchNorm2d(3)
x = torch.randn(4, 3, 8, 8)
# 训练时
bn.train()
out_train = bn(x)
# 测试时
bn.eval()
out_test = bn(x)📌 小结表格
| 模式 | 统计方式 | 是否更新均值/方差 | 适用场景 |
|---|---|---|---|
| train() | 当前 mini-batch | ✅ 是 | 训练 |
| eval() | 滑动平均值 | ❌ 否 | 推理、验证 |
全局滑动均值和滑动方差是什么
全局滑动均值(moving mean)和滑动方差(moving variance)是 Batch Normalization(BN) 在训练过程中用于统计数据分布的全局估计值。它们通过 指数加权移动平均 的方式进行更新,并在 测试阶段 使用。具体而言,它们用于避免测试时每次计算时都依赖小批量数据(mini-batch)的统计信息。
🧠 具体解释:
1. 滑动均值(Moving Mean):
• 训练时,BN层 会不断计算当前 batch 的均值(mean)和方差(variance)。
• 但是,为了让测试时能够使用更稳定的均值和方差,BN会 维护一个滑动均值。
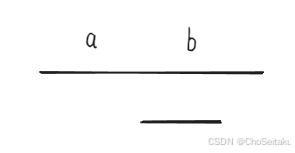
• 这个均值是通过以下公式更新的:
其中,α 是一个常数(通常接近1,比如 0.9 或 0.99),用于控制历史统计对当前的影响。
2. 滑动方差(Moving Variance):
• 类似于滑动均值,BN层也会维护一个 滑动方差,它是通过以下公式更新的:
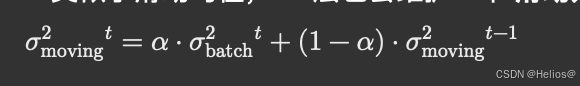
• 这里的σ² 是当前 batch 的方差。
3. 为什么要使用滑动均值和滑动方差?
• 稳定性:在测试时,数据通常是一次性输入模型,batch size 可能为 1 或者非常小,这会导致当前 batch 的统计量(均值和方差)非常不稳定。如果每次测试时都重新计算均值和方差,可能会导致不稳定的推理结果。
• 全局统计:滑动均值和方差通过结合历史数据的统计量,提供了一个更为稳定的全局估计,这有助于在整个训练过程中产生更一致的推理结果。
🚀 总结:
• 训练阶段:每个 mini-batch 计算新的均值和方差,并且更新滑动均值和滑动方差。
• 测试阶段:使用训练中计算得到的滑动均值和滑动方差,而不再使用当前 batch 的均值和方差。
小结表格:
| 阶段 | 使用的均值/方差 | 更新均值/方差 |
|---|---|---|
| 训练 | 当前 batch 的均值和方差 | ✅ 更新滑动均值/方差 |
| 测试 | 滑动均值和滑动方差 | ❌ 不更新 |