22-spark-核心编程-RDD概念:
分布式计算基础测试: big-data-study\Spark-demo\src\main\java\spark\core\com\zh\test02
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VFqQS2tw-1670771635691)(png/image-20210923204137911.png)]](https://img-blog.csdnimg.cn/bca16376805344b6b34c94469a0c82e4.png)
Spark 核心编程
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
➢ RDD : 弹性分布式数据集
➢ 累加器:分布式共享只写变量
➢ 广播变量:分布式共享只读变量
java-io读写基本了解RDD
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CxQ5cvGi-1670771635693)(png/image-20210923210629235.png)]](https://img-blog.csdnimg.cn/918eef3def6d4428ab96ac2cc31a3a59.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DgPG95kG-1670771635693)(png/image-20210923210741863.png)]](https://img-blog.csdnimg.cn/98e75491c1754c8583ea8a5560144bb6.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wcL9y4VS-1670771635694)(png/image-20210923224728454.png)]](https://img-blog.csdnimg.cn/7b2000edda3f400896ec7d87c6e9a311.png)
Spark-RDD和IO之间的关系(将最小单元通过组合形成一个)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D93Akmc0-1670771635694)(png/image-20210926193355883.png)]](https://img-blog.csdnimg.cn/200dcdba82394d08a3dcc6fafdcd7d57.png)
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合
➢ 弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片(类似hadoop中的分区)。
➢ 分布式:数据存储在大数据集群不同节点上
➢数据集:RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象:RDD 是一个抽象类,需要子类具体实现
➢ 不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SB54v60a-1670771635695)(png/image-20210924102705832.png)]](https://img-blog.csdnimg.cn/0c3efd2abc99442da4bab4e2de14fd00.png)
核心五大属性
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions 分区列表:RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
protected def getPartitions: Array[Partition]
* - A function for computing each split 分区计算函数:Spark 在计算时,是使用分区函数对每一个分区进行计算
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
* - A list of dependencies on other RDDs RDD 之间的依赖关系:RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
protected def getDependencies: Seq[Dependency[_]] = deps
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) 分区器:当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
@transient val partitioner: Option[Partitioner] = None
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file) 首选位置:计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
执行原理
数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
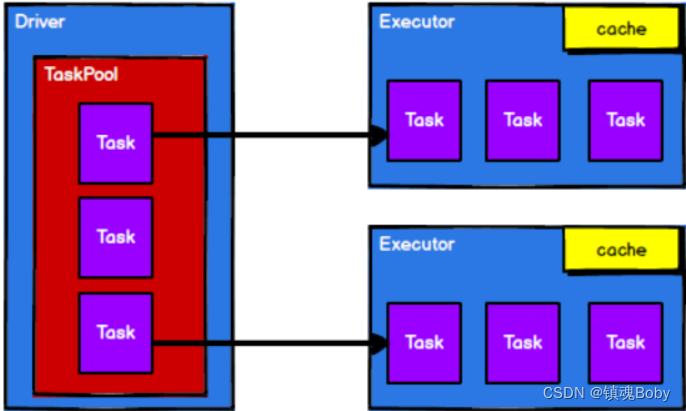
RDD 是 Spark 框架中用于数据处理的核心模型,接下来我们看看,在 Yarn 环境中,RDD的工作原理:
- 启动 Yarn 集群环境
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LQ9u7Fxe-1670771635695)(png/image-20210924135700961.png)]](https://img-blog.csdnimg.cn/4d35a457bbb54d91a873dd97fe5ae04d.png)
2、Spark 通过申请资源创建调度节点和计算节点
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I9QEYWzH-1670771635696)(png/image-20210924135727191.png)]](https://img-blog.csdnimg.cn/8dd62424eba94638b51377e33b31320e.png)
3、Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5u0oC2Um-1670771635696)(png/image-20210924135750302.png)]](https://img-blog.csdnimg.cn/5aca29689f6a41988081caf1377bf21a.png)
- 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
学习路径:https://space.bilibili.com/302417610/,如有侵权,请联系q进行删除:3623472230