一、字符串
Lua 使用 八个比特位来存储 字符。(一个字节 = 八个比特位)
Lua 最好使用 UTF-8 编码。
字符串是不可变值,和 java 和 kotlin 相似,修改其中某一个字符,都是创建一个新的字符串。
Lua 对字符串会进行自动内存管理,会自动进行字符串的分配和释放。
二、函数
1、获取字符串长度
使用 # 获取字符串所占字节数,编码不同可能会有不同结果
a = "Jiang 澎涌"
print(a .. " size: " .. #a) --> Jiang 澎涌 size: 12
2、字符串拼接
使用 .. 字符串拼接,如果操作数中存在数值,则会先将数值转为字符串
3、转义字符
C 风格转义字符:
| 符号 | 描述 |
|---|---|
| \a | 响铃 |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ | 反斜杠 |
| " | 双引号 |
| ’ | 单引号 |
转义序列
\ddd(d 是十进制数) 、 \xhh(h 是十六进制数)
使用的是 ASCII 编码
--- 两种写法一样的表示 (A == '0x41' ,\n == '\0' ,1 == '\049')
print("ALO\n123\"") --> ALO 换行 123"
print('\x41LO\10\04923"') --> AL0 换行 123"
Lua 5.3 开始,可以使用转义序列 \u{h....h} 来声明 UTF-8 字符。 h 代表十六进制
print("\u{3b1} \u{3b2} \u{3b3}") -->α β γ
转义的使用
在某些系统下,‘\r\n’ 会被归一化为 ‘\n’ , 这个时候可以使用十进制数值或十六进制数值来表示。
可以借助一些网上工具进行获取相应编码,https://tool.chinaz.com/tools/unicode.aspx
三、多行字符串
多行字符串更多用于文本,内容中的转义序列不会被转义,并且第一个字符是换行符的话,则会被忽略。
multiLines = [[
Hello world.
Jiang Pengyong.
]]
print(multiLines)

为了应对文本中可能含有 [[ 或 ]] 字符,所以可以使用 [===[ 在两个 [ 中夹杂 0-n 个等号,相对应的终止也要同样多的等号夹杂在 ] 中。
superMultiLines = [=====[
Hello world
Jiang Pengyong
--[[
]]
]=====]
print(superMultiLines)

可以通过 \z 去除字符串中的空白字符,直到下一个非空白字符串
data = "123\z
456"
print(data) --> 123456
四、强制类型转换
1、字符串转数值
字符串运算操作
所有针对字符串的算数操作都会尝试将字符串转为数值
print("10" + "1") --> 11
print("10" + 1) --> 11
print(10 + "1") --> 11
print(10 + 1) --> 11
print("10.0" + "1") --> 11.0
print("\"10\" + 1 ===>>", "10" + 1, math.type("10" + 1)) --> "10" + 1 ===>> 11 integer
值得注意的是比较操作,字符串不会进行转换成数值
- 不能将数值和字符串进行比较,否则异常
attempt to compare number with string - 字符串之间比较的是字符
print("10" == 10) --> false
print("10" < 11) -- attempt to compare string with number
print(10 < "11") -- attempt to compare string with number
print("10" < "11") --> true
print(10 < 11) --> true
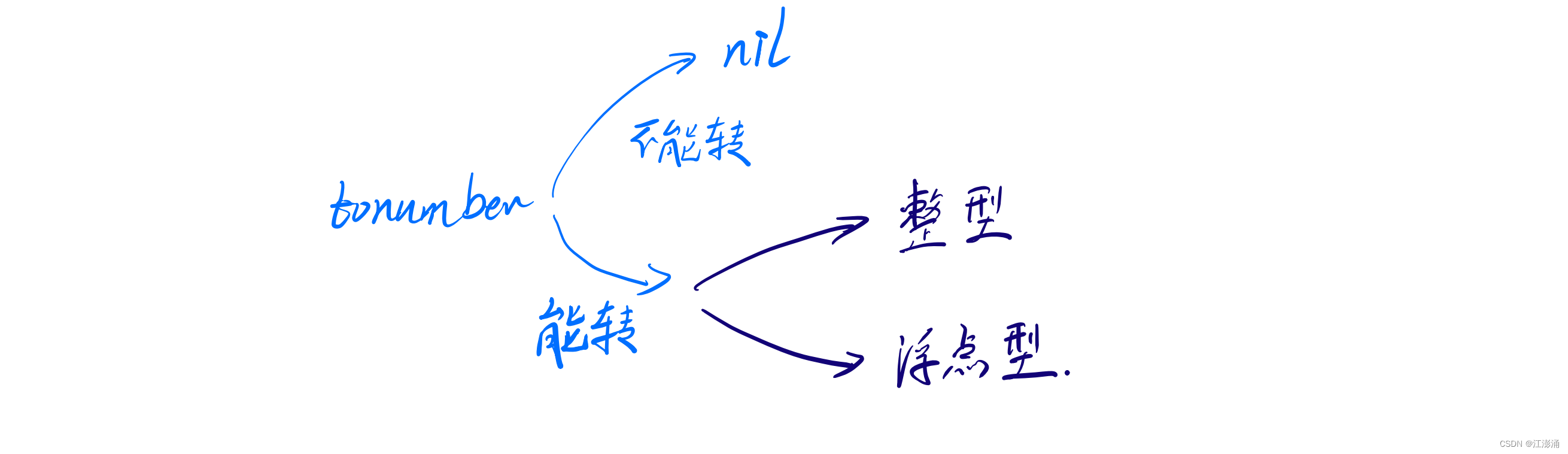
tonumber 转换
可以使用 tonumber 函数,将字符串转为数值,Lua 扫描器会判定最终是整型值还是浮点类型值
转换符合 “数值类型” 中的通用规则
print(tonumber(" -3 ")) --> -3
print(tonumber(" 10e2 ")) --> 1000.0
print(tonumber(" 10e ")) --> nil
print(tonumber(" 0x1.3p-4 ")) --> 0.07421875
tonumber 还可以选择想转的进制,可选 [2,36] 进制,默认为十进制
print(tonumber("100101", 2)) --> 37
print(tonumber("fff", 16)) --> 4095
print(tonumber("-ZZ", 36)) --> -1295
print(tonumber("987", 8)) --> nil
如果转不成功,则返回 nil
2、数值转字符串 tostring
将数值转连接使用 .. 要记得数值和连接符隔开,否则会被当成小数点
print(10 .. 1) --> 101
可以使用 tostring 将数值转为字符串
print(tostring(10) == "10") --> true
五、字符串标准库
| 函数 | 描述 |
|---|---|
| string.len(s) | 获取字符串 s 的长度 |
| string.rep(s, n) | 将字符串 s 重复 n 次 |
| string.reverse(s) | 字符串翻转 |
| string.lower(s) | 将所有的大写字母转为小写字母 |
| string.upper(s) | 将所有的小写字母转为大写字母 |
| string.sub(s, i, j) | 从字符串 s 中提取第 i 个到第 j 个字符,包含 i 和 j ,就是 [i, j] |
| string.char(i …) | 可以传入零个或多个整数,返回每个整数转换成对应的字符,最后连接为字符串 |
| string.byte(s, i = 0) | 返回字符串 s 中第 i 个字符的数值 |
| string.byte(s, i, j) | 返回字符串 s 中 i 到 j之间( [i, j] )的字符数值 |
| string.format(s, …) | 进行字符串格式化和将数值输出为字符串 |
| string.find(s, s1) | 在字符串 s 中,寻找字符串 s1 的下标,会有两个返回值,一个是起始下标一个是终止下标, 查询不到则返回 nil |
| string.gsub(s, s1, replace) | 在字符串 s 中,寻找到字符串 s1 ,并用 replace 字符串进行替换,会返回两个值,一个值替换完的字符串,一个是替换的次数(即使没替换成功,也会有两个返回值) |
string.sub(s, i, j)的 i 和 j 可以为负数,则从后面开始计算,-1 代表最后一位
name = "Jiang Pengyong"
-- string.len(name) 等同于 #name , 等同于 name:len()
print(string.len(name)) --> 14
print(#name) --> 14
print(name:len()) --> 14
print(string.rep("jiang", 5)) --> jiangjiangjiangjiangjiang
print(string.reverse(name)) --> gnoygneP gnaiJ
print(string.upper(name)) --> JIANG PENGYONG
print(string.lower(name)) --> jiang pengyong
-- 字符串的索引是从 1 开始,裁剪的包括两个下标 [i, j]
print(string.sub(name, 1, 5)) --> Jiang
-- 负数表示从后往前计算,-1 表示最后一个字符
print(string.sub(name, 1, -2)) --> Jiang Pengyon
print(string.sub(name, 11, -1)) --> yong
print(string.char(97)) --> a
print(string.char(97, 98, 99)) --> abc
-- byte 如果没有填第二个参数,则直接使用第一个字符
-- 索引也是从 1 开始
print(string.byte("abc")) --> 97
print(string.byte("abc", 2)) --> 98
print(string.byte("abc", -1)) --> 99
print(string.byte("abc", 1, -1)) --> 97 98 99
-- 创建一个包含所有字符的表 [1, -1] ,只是要控制好大小,不能超过 1 M
local t = { string.byte(name, 1, -1) }
print("table: " .. #t)
for i = 1, #t do
print(i .. "-->" .. t[i])
end
--> table: 14
--> 1-->74
--> 2-->105
--> 3-->97
--> 4-->110
--> 5-->103
--> 6-->32
--> 7-->80
--> 8-->101
--> 9-->110
--> 10-->103
--> 11-->121
--> 12-->111
--> 13-->110
--> 14-->103
-- find 查询到会返回两个数 开始位置 结束位置, 如果找不到则返回 nil
print(string.find(name, "Jiang")) --> 1 5
print(string.find(name, "jiang")) --> nil
-- 进行替换字符,会返回两个 替换的字符 和 替换的个数
print(string.gsub(name, "j", ".")) --> Jiang Pengyong 0 (未查询到)
print(string.gsub(name, "ong", ".")) --> Jiang Pengy. 1 (查询到一次)
print(string.gsub(name, "g", ".")) --> Jian. Pen.yon. 3 (查询到多次)
string.format
因为 Lua 是通过调用 C 语言标准库来完成实际工作,所以格式化和 C 一样,可以使用和 C 一样的操作。
- d 代表十进制整数
- x 代表十六进制整数 (a-f 小写)
- X 代表十六进制整数 (a-f 大写)
- f 代表浮点数
- s 代表字符串
可以在 % 和 字母间增加数字,当格式化的内容长度不够数字是,会用“ ”(空格)补足,如果增加 0 则会用 0 补足空间。
print(string.format("pi = %.4f", math.pi)) --> pi = 3.1416
-- 如果不使用 0 ,则默认使用空格
print(string.format("%02d/%02d/%04d", 4, 5, 2022)) --> 04/05/2022
print(string.format("%2d/%2d/%4d", 4, 5, 2022)) --> 4/ 5/2022
print(string.format("%x", 15)) --> f
print(string.format("%X", 15)) --> F
print(string.format("%15s", "jiang")) --> jiang
六、Unicode 编码
5.3 引入了用于操作 UTF8 的 Unicode 字符串标准库。
UTF8 使用变长的多个字节来编码一个 Unicode 字符。
string 函数对 utf8 的使用
string 的有些函数并不适合处理 utf8 ,例如这些:reverse , upper , lower , byte , char
chineseName = "江澎涌"
print(string.reverse(chineseName)) --> ��掾柱�
print(string.upper(chineseName)) --> 江澎涌
print(string.lower(chineseName)) --> 江澎涌
print(string.byte(chineseName)) --> 230
print(string.char(chineseName)) -- bad argument #1 to 'char' (number expected, got string)
format , rep , len , sub 适用 utf8 的字符串
format中不能继续使用%c来进行展示字符串
值得注意: len 和 sub 的索引是以字节为单位,不是以字符为单位。例如这里的 “江” 是 3 个字节,所以 len 会返回 9 ,sub 的截取其实下标为 2 时,则出现乱码。
print(string.format("名字: %s", chineseName)) --> 名字: 江澎涌
print(string.rep(chineseName, 5)) --> 江澎涌江澎涌江澎涌江澎涌江澎涌
print(string.len(chineseName)) --> 9
print(string.sub(chineseName, 2, -1)) --> ��澎涌
urf8 标准库
| 函数 | 描述 |
|---|---|
| utf8.len(s) | 返回指定字符串中 UTF8 字符的个数。如果该函数发现字符串中包含有无效的字符序列,则会返回两个值,第一个值为 false,第二个值为第一个无效字节的位置 |
| utf8.char(int …) | 在 utf8 环境下,等价于 string.char |
| utf8.codepoint(s, i, j) | 在 utf8 环境下,等价于 string.byte ( i 和 j 是字节,不是字符) |
| utf8.offset(s, i) | 获取 s 字符串中,第 i 个字符的以字节索引 |
| utf8.codes(s) | 用于遍历 utf8 字符串中的每一个字符,每次遍历都会返回两个值,一个是字节索引,一个是编码 |
utf8 库中索引大多是字节为单位,而非字符。可以用 offset 把字符位置转为字节位置
utf8 库的索引一样可以使用负数,一样是从后往前的意思
chineseName = "江澎涌"
print("utf8.len: ", utf8.len(chineseName), "string.len", string.len(chineseName)) --> utf8.len: 3 string.len 9
print(utf8.len("ab\x93")) --> nil 3
print("codepoint:", utf8.codepoint("澎")) --> codepoint: 28558
print("char", utf8.char(28558)) --> char 澎
print(utf8.offset(chineseName, 2)) --> 4
print(string.sub(chineseName, utf8.offset(chineseName, 2))) --> 澎涌
-- codes 遍历 utf8 字符串中的每一个字符
for i, j in utf8.codes(chineseName) do
print(i .. "-->" .. j .. "-->" .. utf8.char(j))
end
--> 1-->27743-->江
--> 4-->28558-->澎
--> 7-->28044-->涌
七、写在最后
Lua 项目地址:Github传送门 (如果对你有所帮助或喜欢的话,赏个star吧,码字不易,请多多支持)
公众号搜索 “江澎涌” 可以第一时间获取到后续文章