大型纪录片:学习若依源码(前后端分离版)之 “ 用户管理根据不同角色、部门显示数据范围”
- 前端部分
- 后端部分
- “ /list " 方法
- " /treeselect " 方法
- 结语
起因是我想做一个根据不同角色以及其所在的部门展示其相应的信息,只能展示自己部门的信息。后面发现若伊竟然自带了这个功能,不得不说真的强大。它自带了用户管理菜单,里面有角色、部门、用户的模块,其中每个模块又互相有着关系。
用户可以绑定角色,也可以绑定到部门,角色绑定了哪些部门,就决定着隶属于该角色的用户能对哪些部门数据进行操作。
前端部分
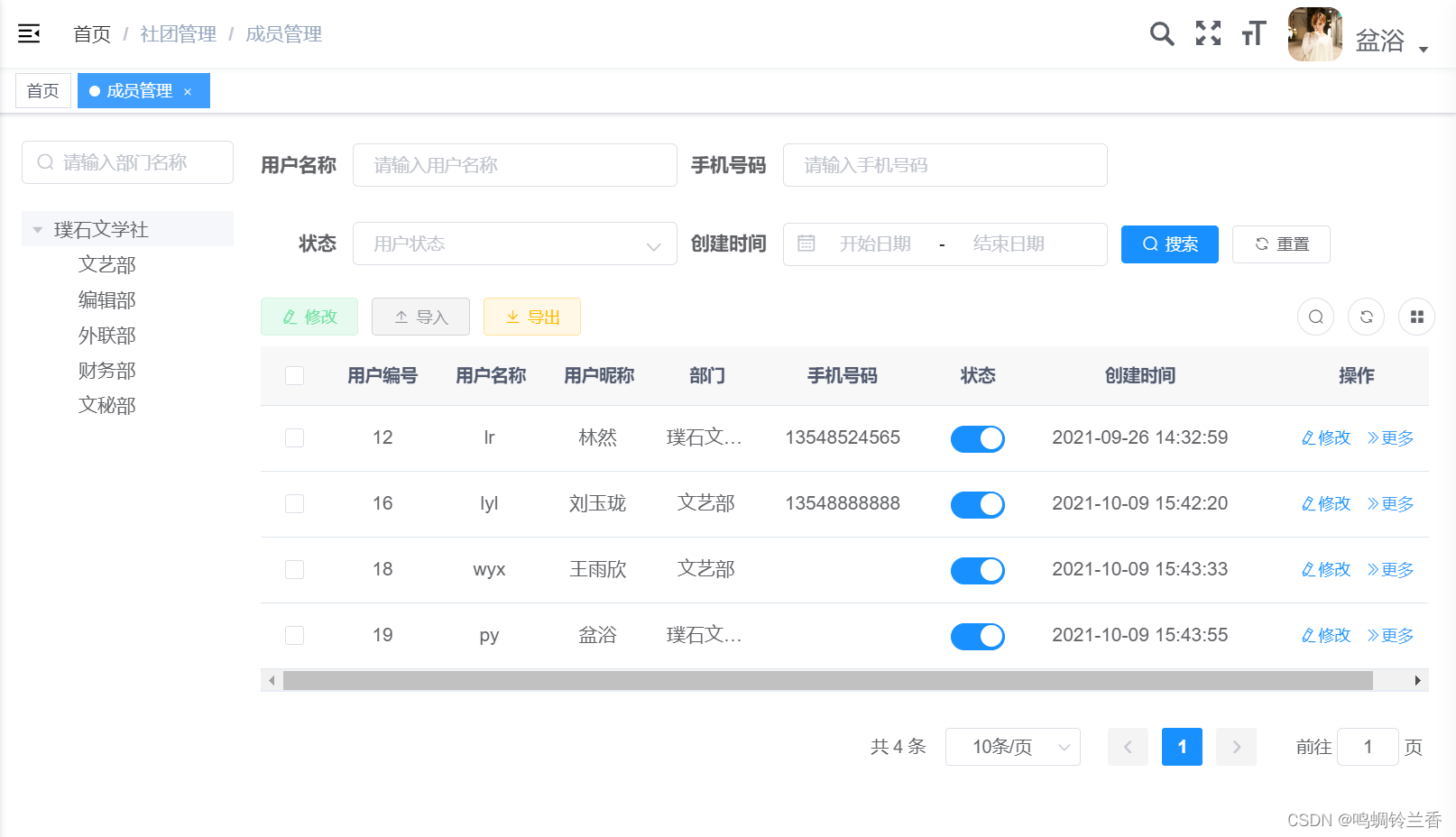

那么,怎么实现让用户只能遵循其绑定角色所指定的部门,来进行数据范围控制呢?
具体操作流程如下:
第一步:打开角色管理,选择该角色可以显示的数据有哪些
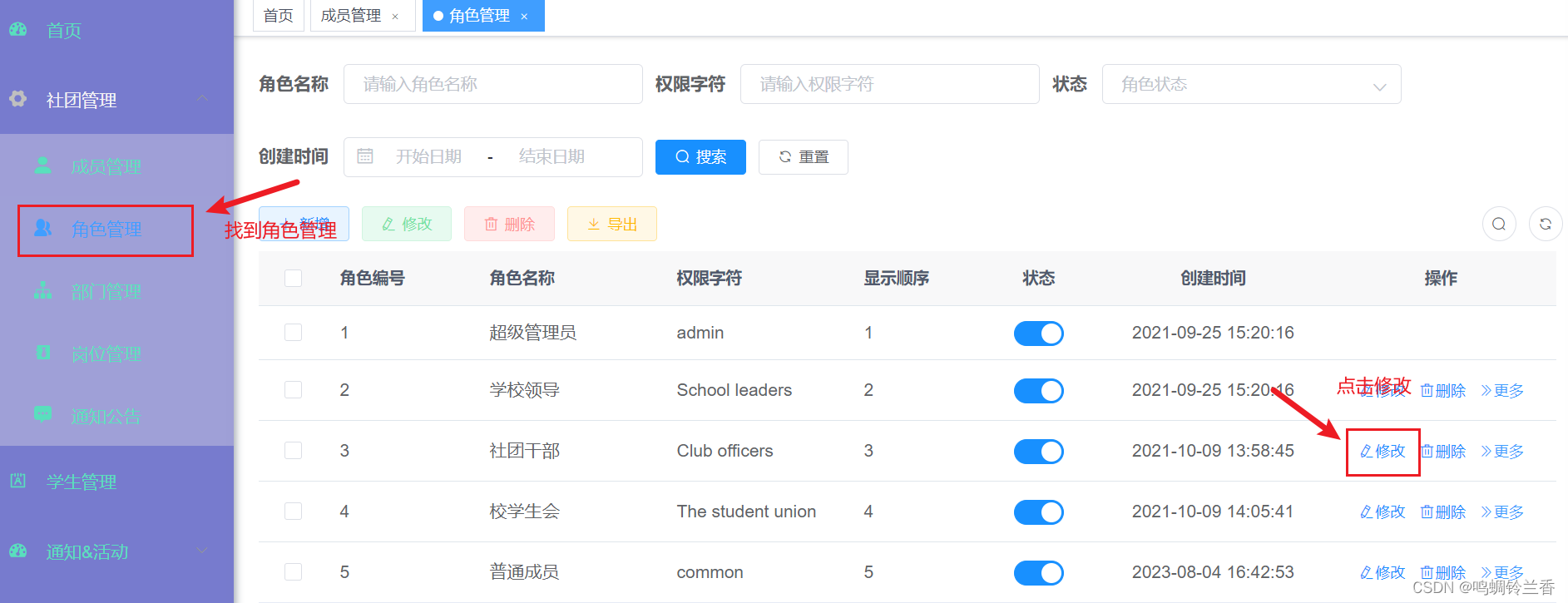
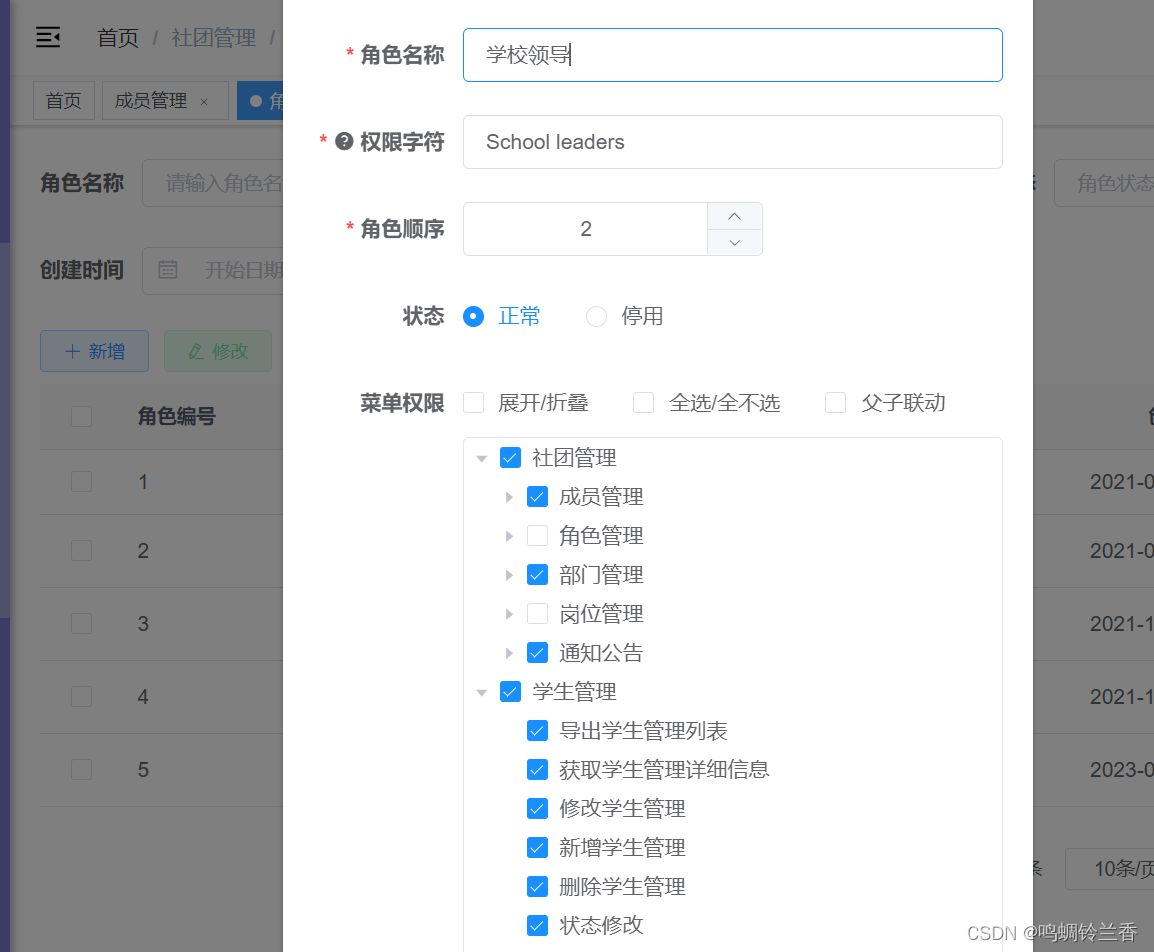
通过这个操作我们可以实现该角色能看到哪些菜单,能对哪些数据进行操作。那么如果业务进一步需要在角色信息中只显示本部门的数据呢?
第二步:点击 “更多” —》选择 “数据权限”,就可以看到若伊提供的五种权限范围了,这五种权限范围也基本满足我们的业务需求了。

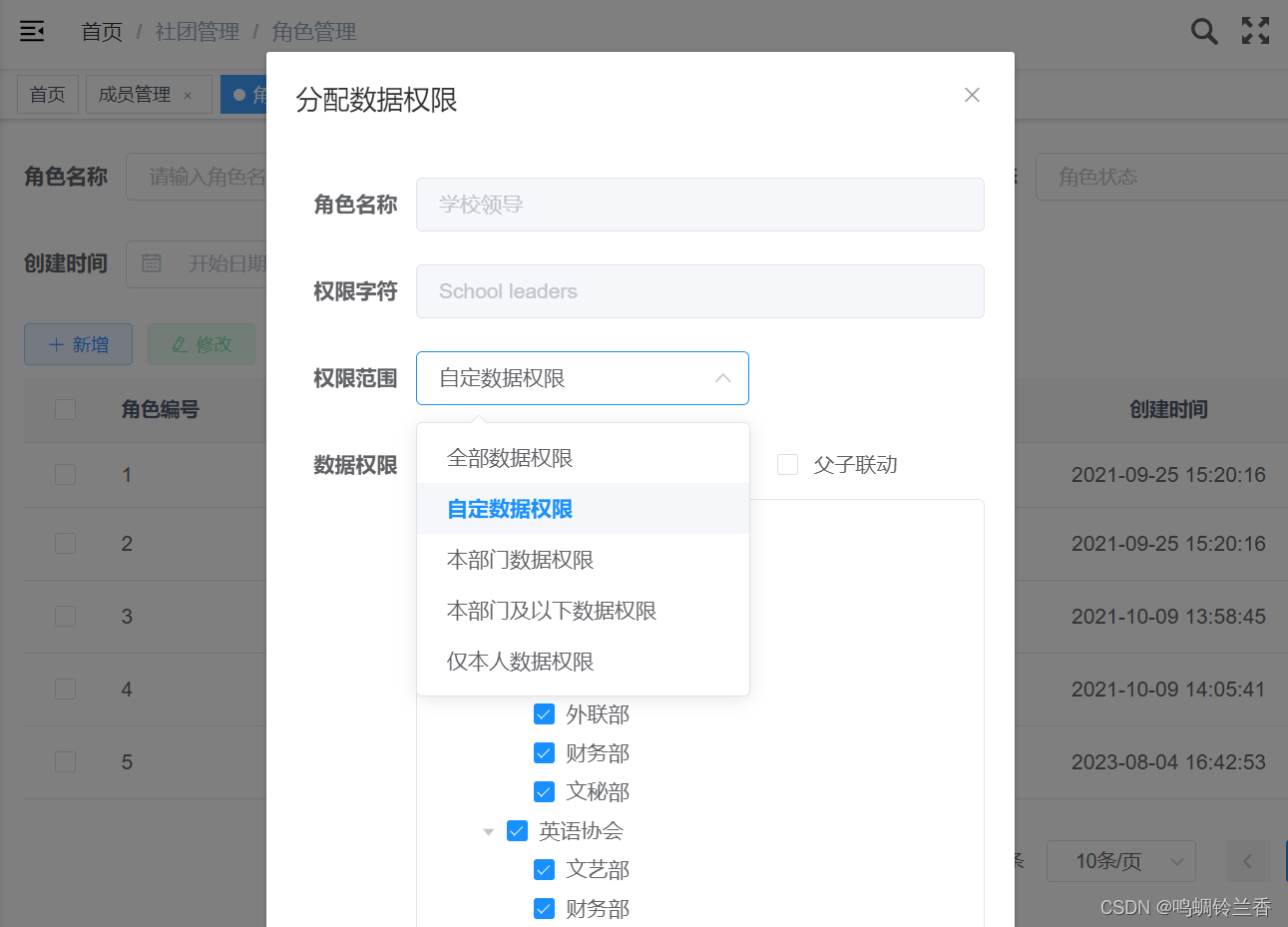
看到这里,相信你就已经会使用若伊用角色和部门进行权限的自定义了。
但是我们的学习还没有结束,这个功能是怎么实现的呢?我们一起来研究一下。首先依旧老一套,我们找到前端的请求代码。
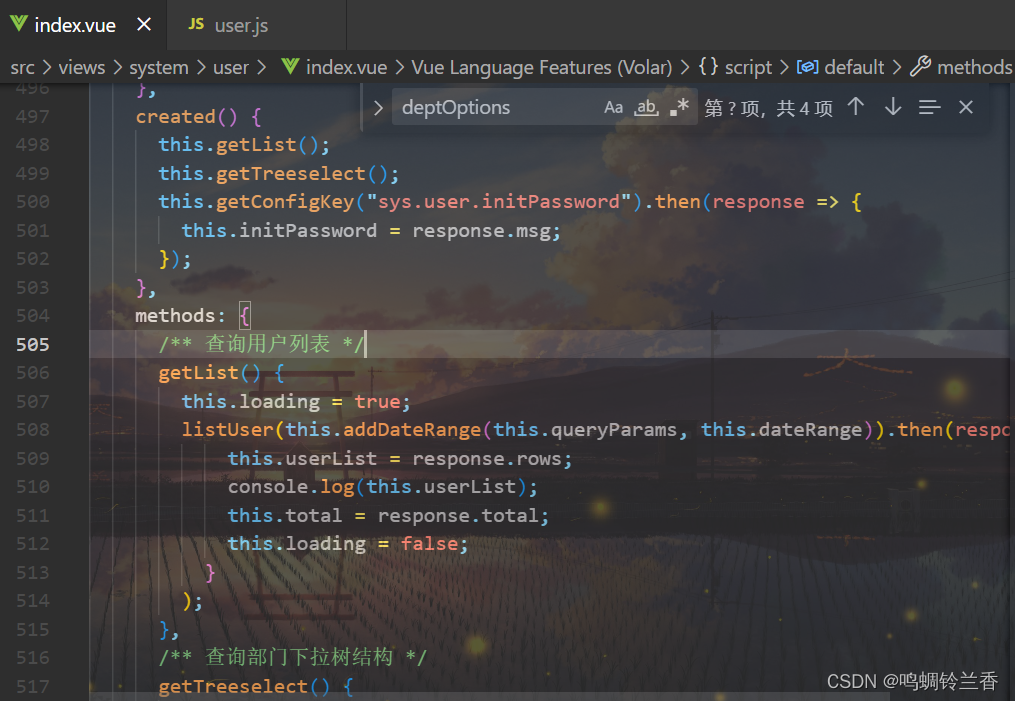
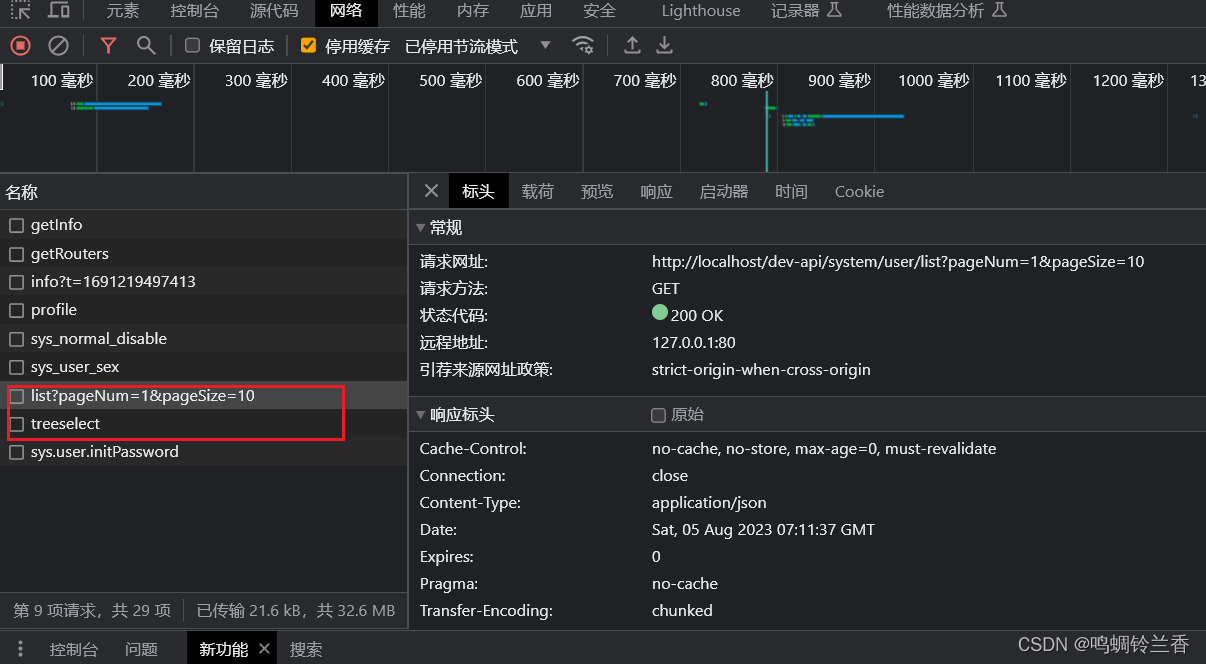
可以看到,在页面加载的时候,就调用了两个方法。 “getList()” 也是老面孔了,前面讲到分页的时候就已经提起过它。那么我们接着看后端。
后端部分
“ /list " 方法
找到代码接收请求的部分,打上断点,进入debug。
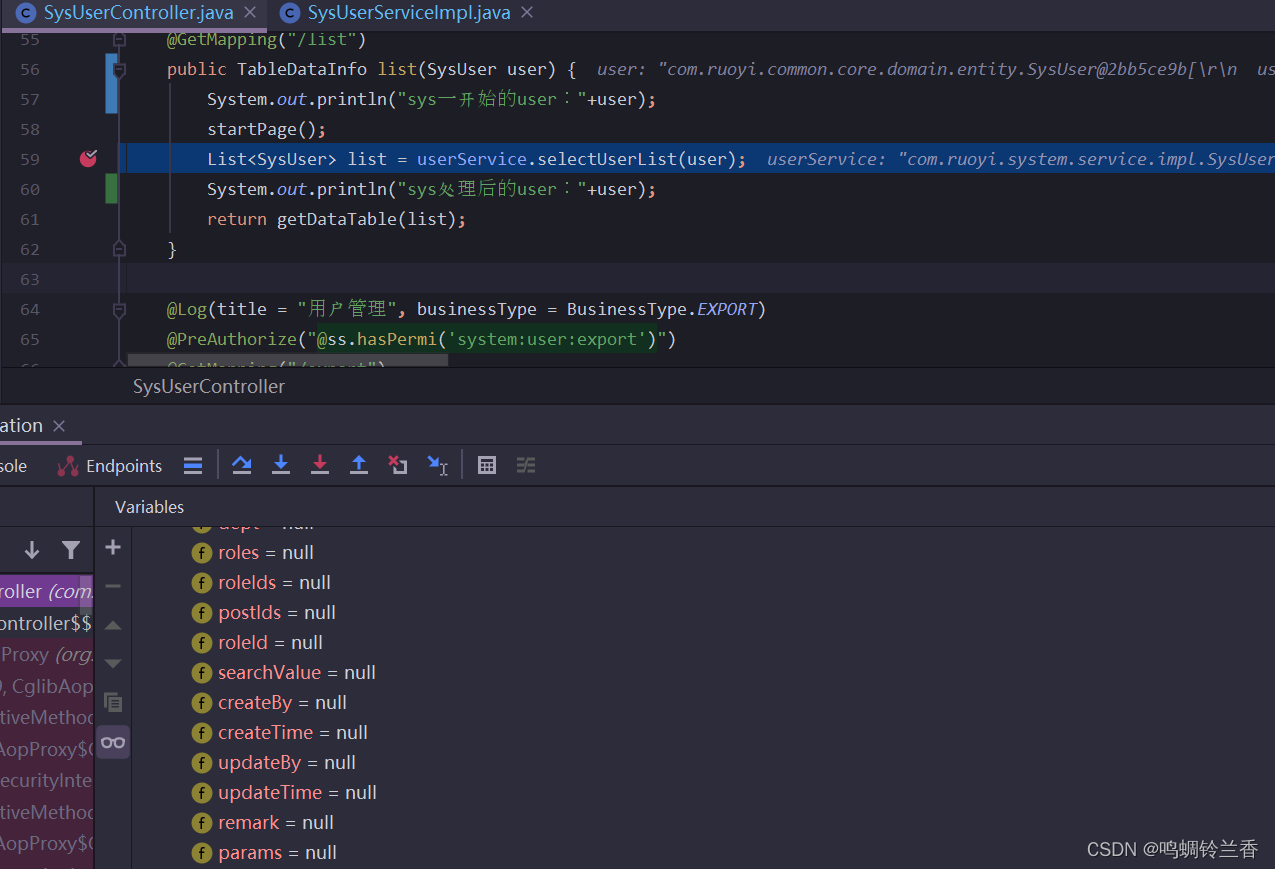
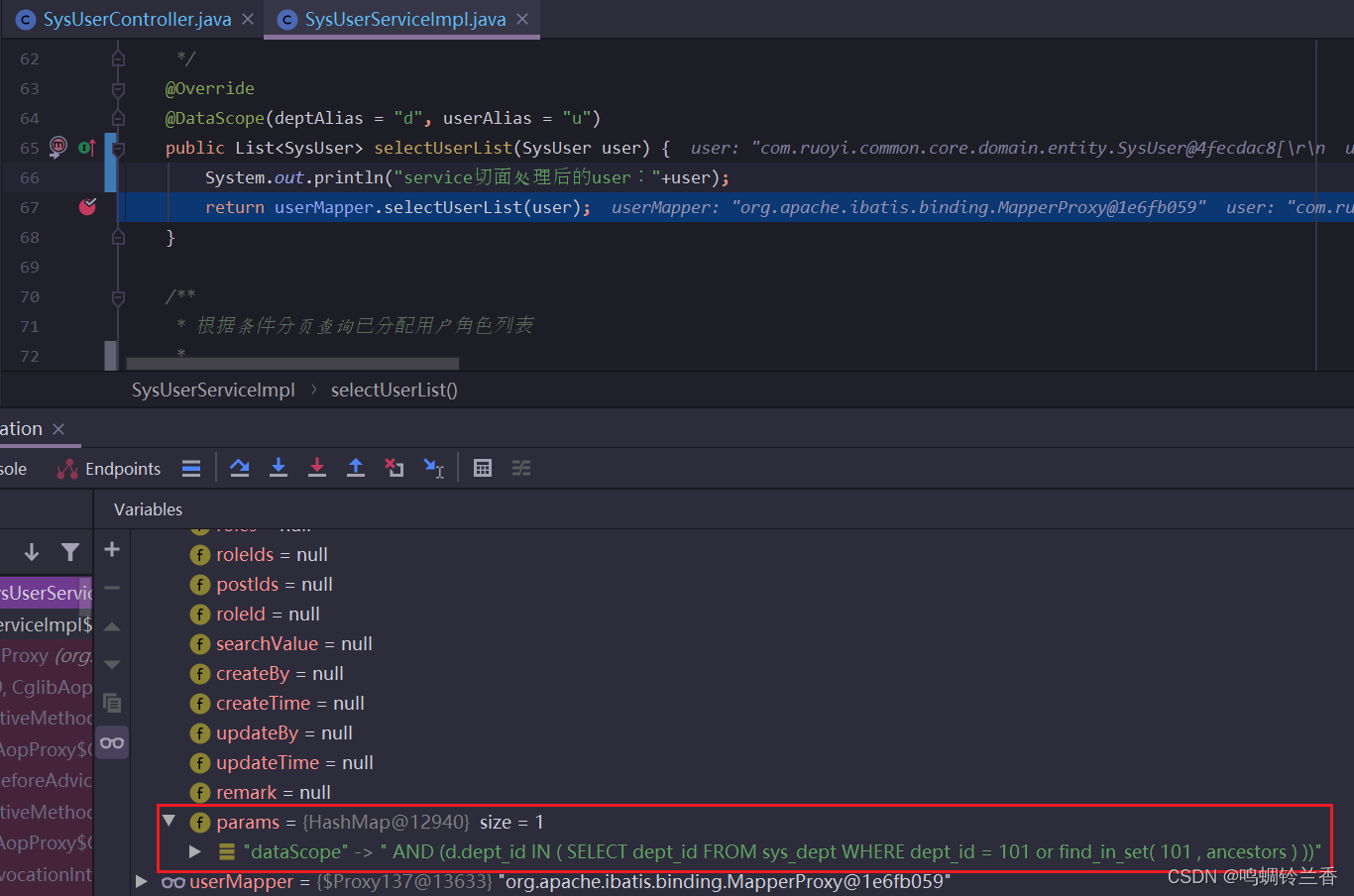
家人们,有没有好奇怎么突然多出一条数据??!哪来的??不用慌,我带大家来好好捋一下。
在我们自己做项目的时候怎么实现让用户只能遵循其绑定角色所指定的部门,来进行数据范围控制呢?
一般情况下,假如我们对一张表要进行查询或更新的话,需要在sql语句中,where条件语法后面 加上判断来进行过滤, 例如下面的sql语句:
select * from sys_user
where dept_id = {currentUserDeptId}
但是,在若依框架中,我们只需要在Service层的方法上加入@DataScope注解, 并分别通过deptAlias和userAlias属性,指定出部门表和用户表在sql语句中的别名是什么的话, 就可以灵活地在sql语句后面加上过滤条件了。
下面,我们通过演示,来介绍如何使用@DataScope注解(这里部分参考了网上的回答)。
1.首先,我们有一个部门表的实体类,叫SysDept。并且,它还必须继承了BaseEntity这个类。
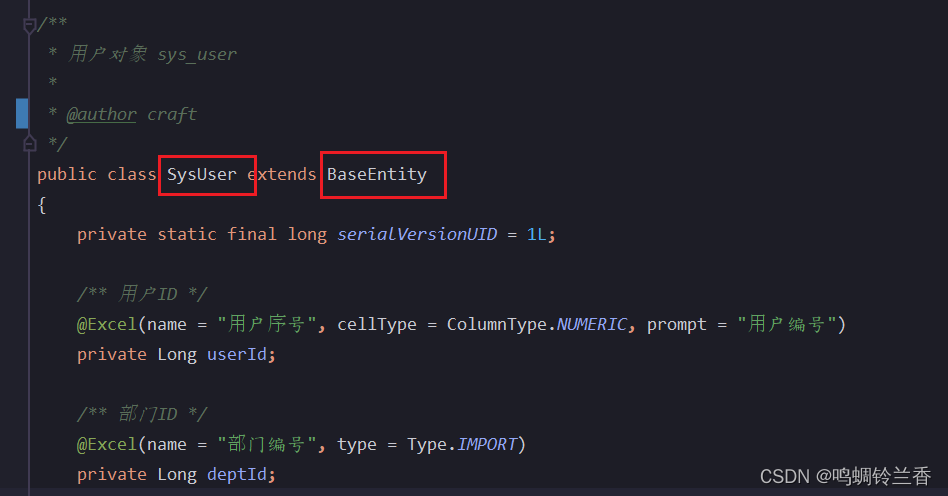
而BaseEntity实体类中,有一个类型为map,名称为params的属性。

2.在对应的mapper.xml文件中,对应sql语句的末尾,我们引用SysUser所继承的BaseEntity父类中的’params’属性 ${params.dataScope}

3.在Service层方法上,加入@DataScope注解,并指定sql语句中用户表和部门表的别名。
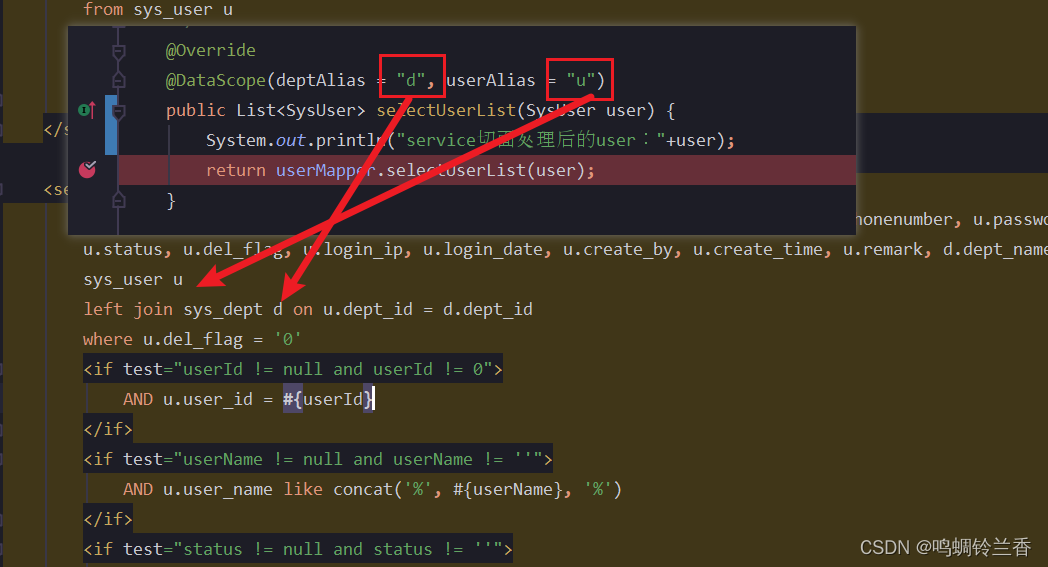
总结一下 @DataScope(deptAlias = “d”, userAlias = “u”) 这个注解,它是若依框架自定义的一个注解,用于标记需要进行数据范围过滤的方法。运行原理是:
- 当你在Service层的方法上使用了 @DataScope 注解时,若依框架会通过一个叫做DataScopeAspect的切面类来拦截你的请求,根据你的角色和数据范围权限,动态生成SQL语句,添加数据过滤条件。
- 这个SQL语句会被赋值给你的实体类所继承的BaseEntity类的params属性,这个属性是一个Map类型,用于存储请求参数。
- 在Mapper层的XML文件中,你可以通过
${params.dataScope}来引用这个SQL语句,作为查询条件的一部分。 - 这样,就可以实现根据不同的用户角色和数据范围权限,返回不同的数据结果。
现在我们知道了,既然使用了@DataScope后,就会根据前端用户的相关权限参数,自动来生成sql语句用以过滤。 也许你还是会好奇——这个sql语句是在哪儿生成的? 前端用户的权限,肯定也是需要通过响应的判断,来生成的吧,那么在哪儿判断的? 假如它当前自动生成的sql语句,不符合我的现在业务的需求,我怎么去改?
我们打开上面说的DataScopeAspect类来一探究竟。
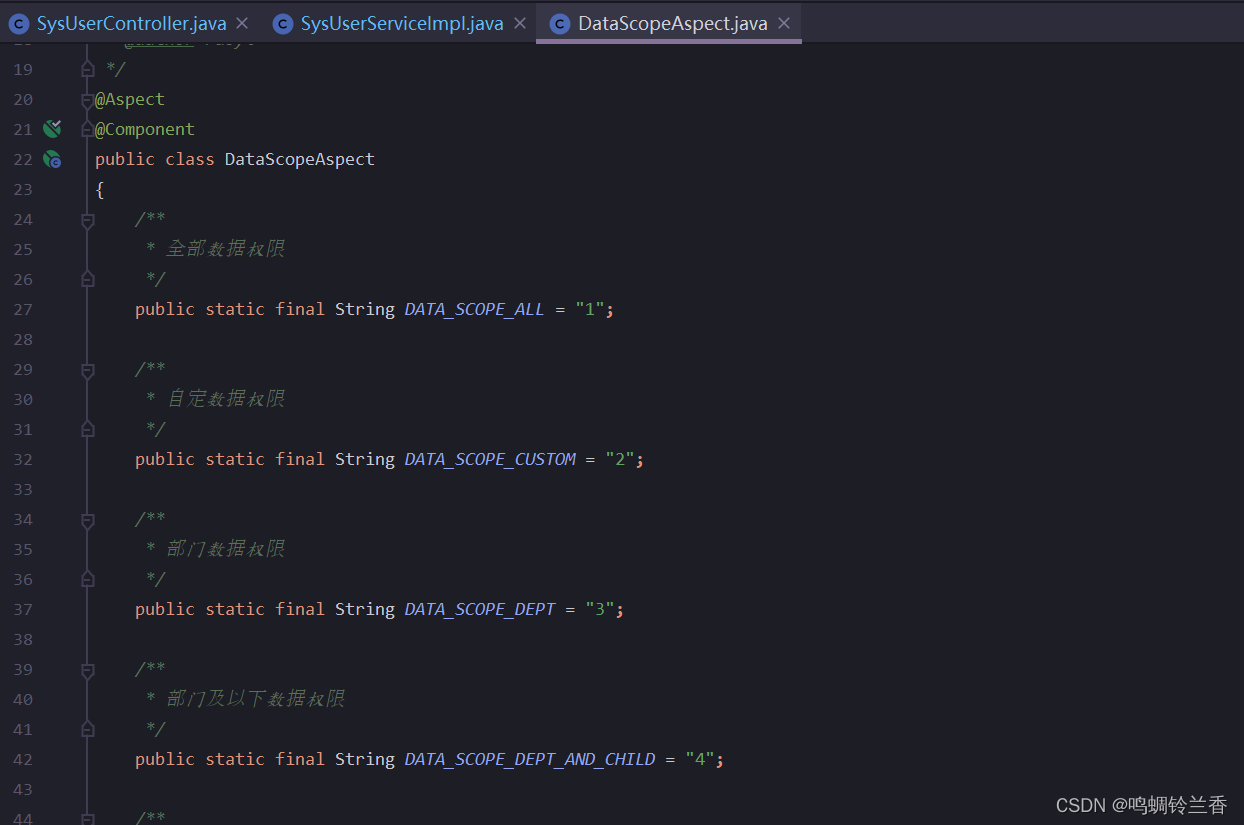
还记得之前在前端看到的吗?若伊给数据范围分了五类,原来在这里都有一一对应的。
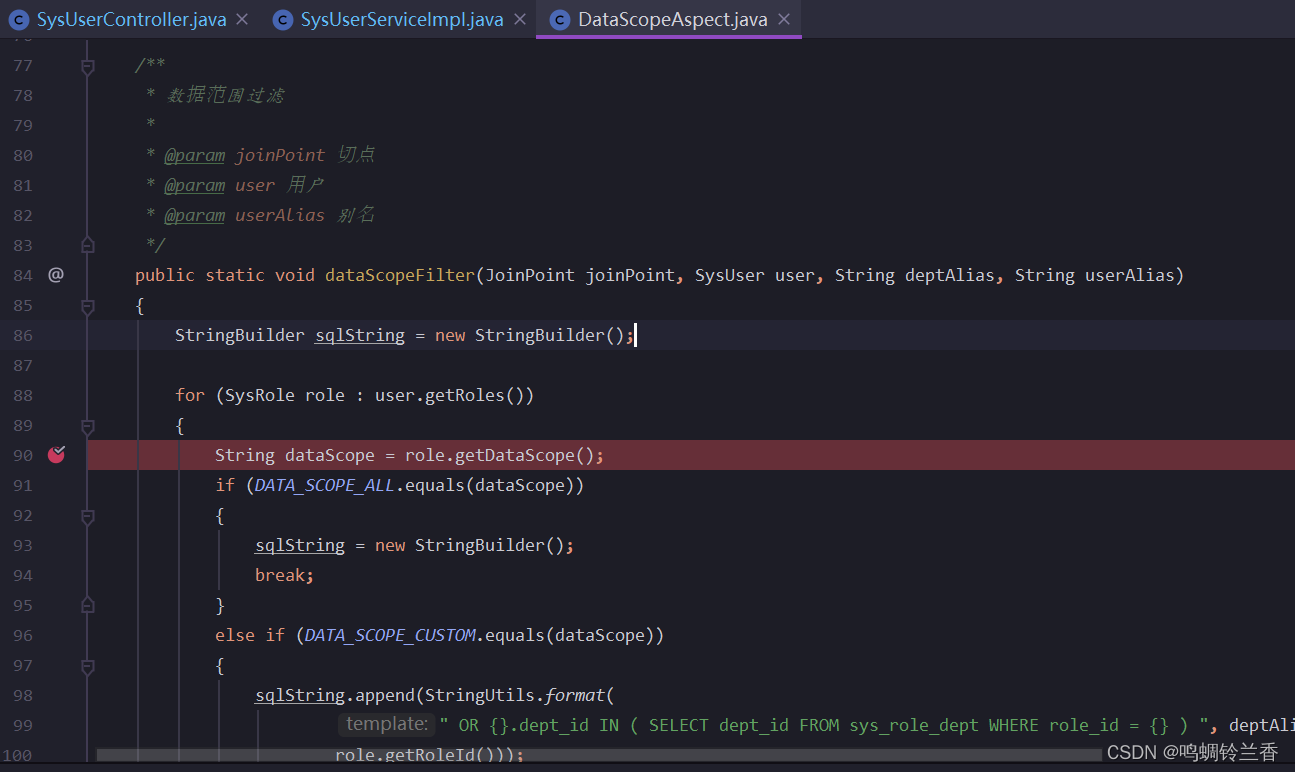
打个断点继续测试
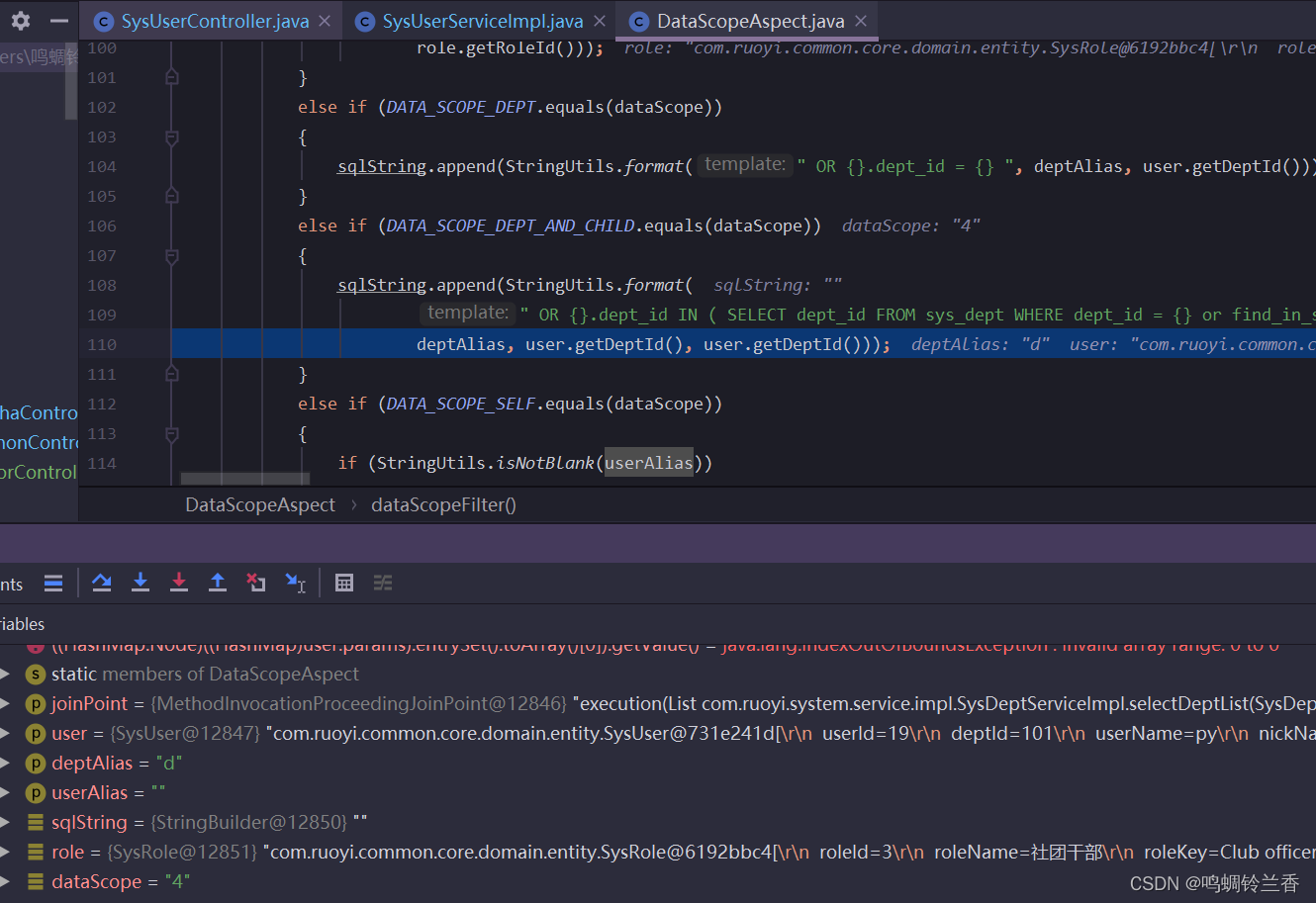
现在我们思路就很清晰了,它会循环判断该用户的角色,然后再获取这个角色的数据显示范围,进行判断找到对应的那个SQL,进行拼接。
你以为到这里就完了吗??哈哈,我们接着往下看,发现又进入了一个判断。
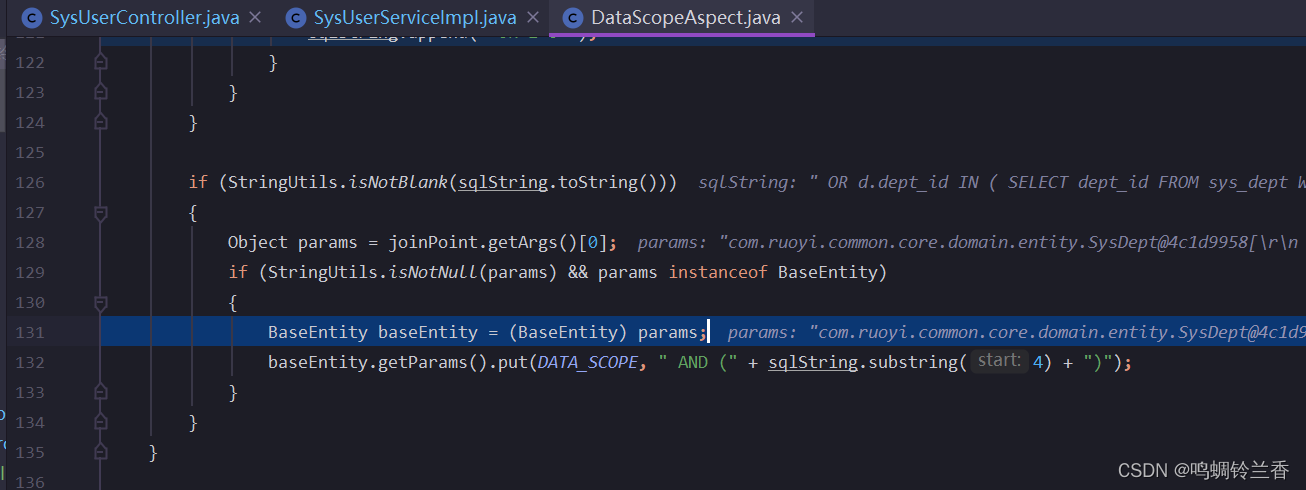
简单概括一下这个判断有什么作用:
- 首先,判断sqlString是否为空,sqlString是一个StringBuilder类型的对象,用于存储SQL语句的条件部分。
- 如果sqlString不为空,那么获取切点的第一个参数,赋值给params对象。切点是指被
@DataScope注解标记的方法。 - 如果params不为空,并且是BaseEntity类型的对象,那么将params强制转换为BaseEntity类型的对象,赋值给baseEntity对象。BaseEntity是若依框架中所有实体类的父类,用于封装公共属性。
- 从baseEntity对象中获取params属性,这个属性是一个Map类型,用于存储请求参数。然后将sqlString去掉前面的" AND "字符串,并用括号括起来,作为一个键值对,放入params属性中。键是
DATA_SCOPE,值是sqlString。 - 这样,就可以在Mapper层的XML文件中,通过
${params.dataScope}来引用这个SQL语句,作为查询条件的一部分。
" /treeselect " 方法
那么前端发出的第二个请求/treeselect做了哪些事呢,来看源码
/**
* 获取部门下拉树列表
*/
@GetMapping("/treeselect")
public AjaxResult treeselect(SysDept dept) {
List<SysDept> depts = deptService.selectDeptList(dept);
return AjaxResult.success(deptService.buildDeptTreeSelect(depts));
}
我们发现它跟上一个请求不一样的是,它还多调用了一个方法
先看第一个方法:
/**
* 查询部门管理数据
*
* @param dept 部门信息
* @return 部门信息集合
*/
@Override
@DataScope(deptAlias = "d")
public List<SysDept> selectDeptList(SysDept dept) {
return deptMapper.selectDeptList(dept);
}
这里其实就跟我们上面讲的那个方法差不多。
再看第二个方法:
/**
* 构建前端所需要下拉树结构
*
* @param depts 部门列表
* @return 下拉树结构列表
*/
@Override
public List<TreeSelect> buildDeptTreeSelect(List<SysDept> depts) {
List<SysDept> deptTrees = buildDeptTree(depts);
return deptTrees.stream().map(TreeSelect::new).collect(Collectors.toList());
}
解释一下后面这个stream流
- 首先,调用
deptTrees.stream()方法,将部门树结构 deptTrees 转换为一个流,这个流中的元素是 SysDept 类型的对象,表示部门节点。 - 然后,调用
stream().map(TreeSelect::new)方法,对流中的每个元素进行一个映射操作,将每个 SysDept 对象转换为一个 TreeSelect 对象,并返回一个新的流,这个流中的元素是 TreeSelect 类型的对象,表示下拉树结构中的选项。 - 最后,调用
stream().collect(Collectors.toList())方法,对流进行一个收集操作,将流中的所有元素收集到一个列表中,并返回这个列表。
使用stream流有几个好处:
- stream 流可以让我们用一种声明式的方式来处理集合或数组中的数据,而不需要写很多繁琐的循环和判断。stream 流可以让我们专注于数据的变化和操作,而不是数据的存储和遍历。
- stream 流可以提供一些高级的功能,如并行处理、延迟执行、短路求值等,这些功能可以提高代码的性能和效率。
- stream 流可以提高代码的可读性和可维护性,因为它使用了一些函数式编程的概念和方法,如 lambda 表达式、方法引用、函数接口等,这些概念和方法可以让代码更简洁和清晰。
问:那他们两个类字段也不一样啊,怎么对上的?
答:它是通过调用 TreeSelect 的构造方法来实现的。在TreeSelect 的构造方法有一段这样的定义:
public TreeSelect(SysDept dept) {
this.id = dept.getDeptId();
this.label = dept.getDeptName();
this.children = dept.getChildren().stream().map(TreeSelect::new).collect(Collectors.toList());
}
再看这个buildDeptTree(depts);方法,相信大家都不陌生了,前面讲动态路由树的时候详细讲过,这里就把相关的一小节代码贴出来,总体递归思路和前面那个生成动态路由树基本一致。
/**
* 构建前端所需要树结构
*
* @param depts 部门列表
* @return 树结构列表
*/
@Override
public List<SysDept> buildDeptTree(List<SysDept> depts) {
List<SysDept> returnList = new ArrayList<SysDept>();
List<Long> tempList = new ArrayList<Long>();
//把所有部门的id取出来,方便后面进行父节点比较
for (SysDept dept : depts) {
tempList.add(dept.getDeptId());
}
for (Iterator<SysDept> iterator = depts.iterator(); iterator.hasNext(); ) {
SysDept dept = (SysDept) iterator.next();
// 如果是顶级节点, 遍历该父节点的所有子节点
if (!tempList.contains(dept.getParentId())) {
recursionFn(depts, dept);
returnList.add(dept);
}
}
if (returnList.isEmpty()) {
returnList = depts;
}
return returnList;
}
结语
好了,解释完这个切面我们也就懂了他是怎么实现根据不同角色的不同职位做不同的数据范围了。希望你能从文章中学到、了解一下东西。欢迎留言评论一起交流心得。
今天的篇幅有点长,那么以上就是唐某的一些理解。这次的分享就到这里了。记得一键三连~( •̀ ω •́ )✧