StarRocks 自4月底发布3.0版本,拥抱云原生,开启极速统一的湖仓新范式;8月7日,StarRocks 正式发布全新3.1版本,全面提升云原生存算分离构架、极速数据湖分析、物化视图等重量级特性,让用户更简单的实现极速统一的湖仓分析。
StarRocks 3.1版本湖仓一体分析功能更完善、更易用:
- 存算分离架构功能对齐存算一体,支持业界广泛应用的主键表模型及相关功能,让存算分离更好地支持实时分析场景;性能上,查询和导入性能也基本与存算一体架构持平。
- 极速数据湖分析性能进一步提升,比 Trino/Presto 快3-6倍, 并实现常用 Trino 语法的完全兼容;增加 Apache Iceberg的读写支持、对流式数据湖 Apache Paimon 的分析支持,让数据湖分析更加实时、简单、高效。
- 异步物化视图上,进一步提升物化视图构建、刷新的稳定性,并提供更多灵活易用的创建和刷新参数、增加更多场景的 SQL 智能改写。
- StarRocks 3.1 提供了随机分桶、表达式分区、FILES 表函数等更多新功能、新模式,进一步提升建表/分区/导入中的易用性。
毫无疑问,无论是功能、性能还是易用性,StarRocks 都将持续迈向新的台阶,打造 Lakehouse 的新范式,为用户提供极速统一的数据分析体验!
开始体验 StarRocks 3.1:
※完整中文 release note:https://docs.mirrorship.cn/zh-cn/main/release_notes/release-3.1
※GitHub 地址:https://github.com/StarRocks/starrocks
※二进制包下载:https://www.mirrorship.cn/zh-CN/download/community
新增核心功能介绍
1、存算分离架构
3.1版本,StarRocks 进一步完善对齐存算一体架构下的功能,包括新增支持主键模型表(包括支持部分列更新,但暂不支持持久化索引)、自增列属性 AUTO_INCREMENT、时间函数表达式分区及导入时自动创建分区。并且,进一步优化了数据缓存功能,可以指定热数据的缓存范围以防止冷数据过多占用缓存、影响热数据查询速度。在打开 Data cache 的情况下,存算分离架构与存算一体架构在查询性能、导入性能上都已基本持平。存算分离架构可以帮助用户在不损失查询性能的前提下,极大的降低存储成本。
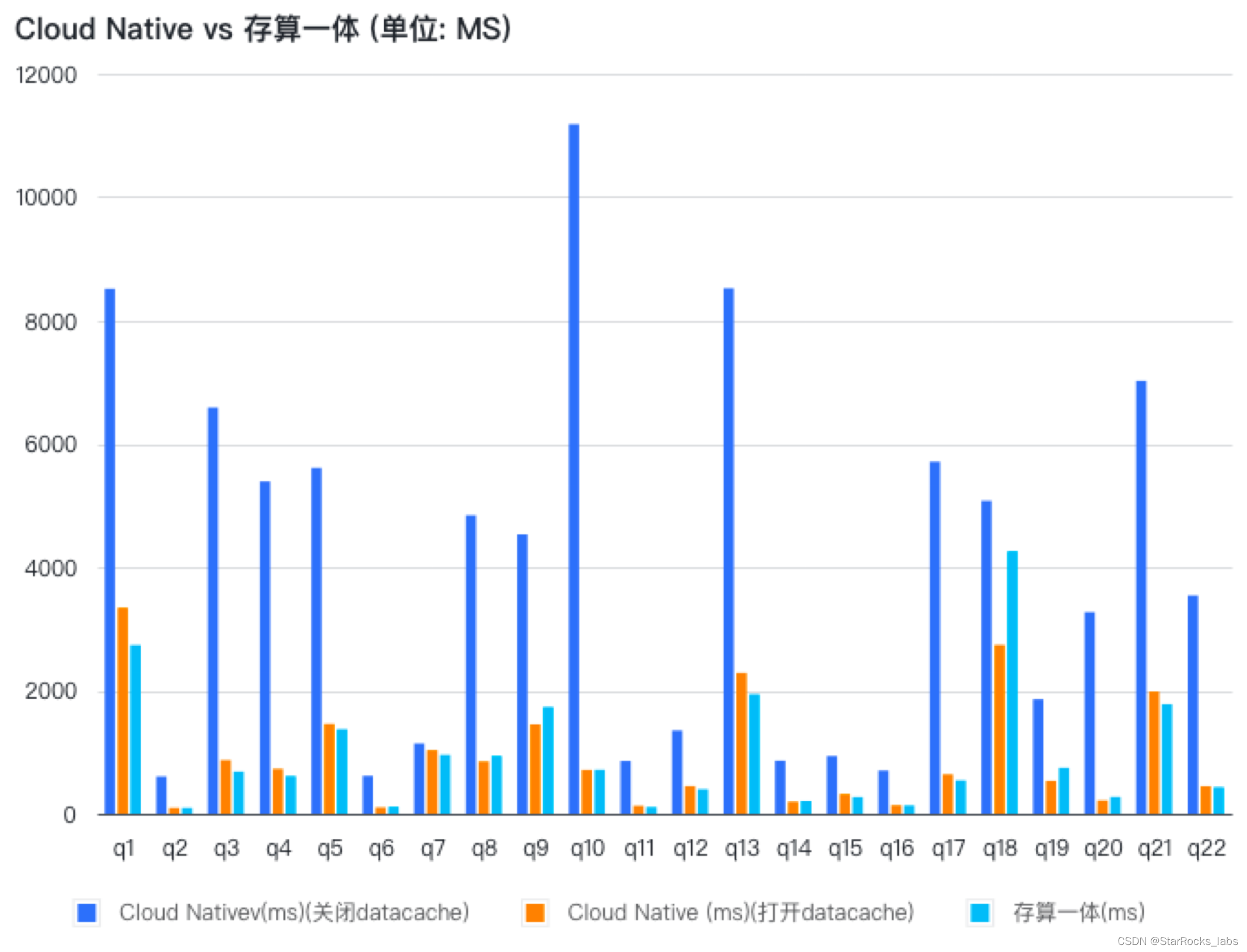
查询性能:在打开 Data Cache 时与存算一体基本持平
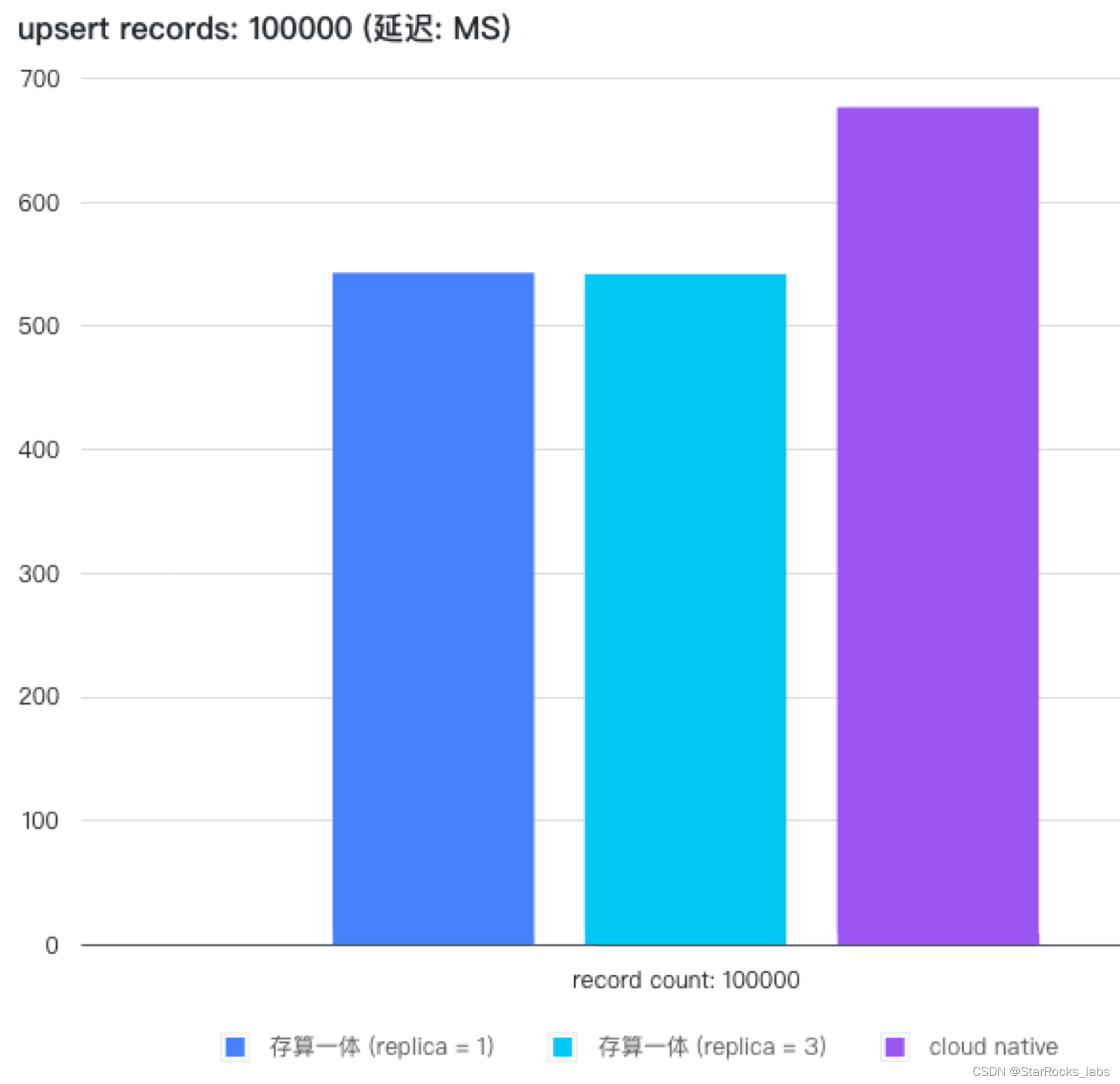
写入性能:与算一体基本持平
2、数据湖分析
3.1 版本对 Iceberg Catalog 进行了完善与增强:
- 在查询能力上,新增支持了对 Parquet 格式的 Icerberg v2 MOR 表的访问。
- 在查询性能上,新增支持了对 Iceberg 元数据的内存+磁盘的两级缓存,在元数据文件较大的情况下显著提升查询性能。
- 在写入能力上,新增支持了在 Icerberg 内创建数据库、表,并通过 INSERT INTO/OVERWRITE 写入 Parquet 格式数据。方便用户将 StarRocks 处理好的数据通过开放格式提供给生态内的其他组件。
同时,3.1版本新增支持了[Elasticsearch catalog]、[Paimon catalog],并进一步增强 Trino 语法兼容性,持续扩大生态打通和提升产品易用性。
3、物化视图
自从2.4版本支持异步物化视图以来,这一功能就已经被大量的用户应用在查询加速、数仓建模等场景中。3.1版本在异步物化视图的创建管理、查询智能改写、使用易用性上继续做了大量的优化工作。
对于同步物化视图,StarRocks 也在3.1版本中扩展了它的能力边界,拓宽更多应用场景。
异步物化视图
StarRocks 致力于让异步物化视图拥有与内表相同的加速和管理能力,在3.1版本中:
- 支持通过
ORDER BY指定排序键,支持设置colocate_group,进一步利用 StarRocks 原生存储的优化来加速物化视图的查询性能。 - 支持配置存储介质和降冷时间(
storage_medium、cooldown_time),方便数据的生命周期管理。 - 支持不指定分桶,默认采用随机分桶,提升创建物化视图的易用性。
并且为了使异步物化视图更加灵活,在 3.1 版本中:
- 支持为物化视图的刷新配置会话变量 (Session Variable),用户可以方便地为物化视图配置单独的执行策略,如查询超时时间、并行度、内存限制、是否开启算子落盘等。让物化视图的刷新不受集群整体变量的限制。
- 支持基于视图(View)创建物化视图,分层建模选择更加灵活。
- 支持通过
SWAP原子替换物化视图,从而实现物化视图的 Schema Change 而不影响嵌套的血缘关系。 - 支持手动激活失效的物化视图,从而在基表重建后仍旧复用历史物化视图。
在查询改写上,StarRocks 致力于让更多场景能够被智能改写,更多发挥物化视图的加速效果。在 3.1 版本中:
- 新增支持 Join 派生改写、Count Distinct、time_slice 函数等场景的改写,并优化了 Union 改写能力。
- 新增支持 Stale Rewrite,即在一定时间内允许改写至还未刷新的物化视图上。从而在允许一定数据延迟的实时场景下,通过物化视图提高查询并发。
- 新增支持 View Delta Join,提升如指标平台、面向主题的宽表场景下的改写能力,降低物化视图的维护成本。
在刷新能力上,在3.1版本中:
- 支持全新同步物化视图刷新接口,同步获取刷新结果。
- 基于 Hive Catalog 创建的外表异步物化视图可以感知分区变动,按分区增量刷新,加速刷新的同时降低成本。
同步物化视图
同步物化视图因其同步更新、增量计算的能力受到广大用户的喜爱。在历史版本中,由于其支持的算子较少,应用场景较为受限。在 3.1 版本中,StarRocks 对同步物化视图能力边界进行拓展。在计算能力上,支持了CASE-WHEN、CAST、数学运算等表达式;支持在单个物化视图内设置多个聚合列;并且支持使用 HINT 来对同步物化视图进行直接查询。
CREATE MATERIALIZED VIEW v1 AS
SELECT b, sum(a + 1) as sum_a1, min(cast (a as bigint)) as min_a
FROM base_table
GROUP BY b;在未来,StarRocks 也将持续完善和挖掘同步和异步物化视图的能力,让物化视图功能成为数据湖查询的一大利器。
4、优化查询性能和稳定性
卓越的查询性能是 StarRocks 一直以来引以为傲的优势。3.1版本中,新增了[生成列 (Generated Column)功能,StarRocks 会根据生成列表达式自动计算表达式的值并在导入时即存储,在查询时会自动判断并进行改写,在无需增加查询复杂性的情况下,再一步提升查询性能,尤其适用对 JSON、Array、Map、Struct 等半结构数据的查询加速和对复杂表达式的计算加速。并且,如果生成列的类型是简单类型,还能利用上 zonemap 等索引,会更进一步加速查询性能。
- 如下所示,newcol1、newcol2 是两个分别是对 data_array、data_json 列做了一些函数操作的生成列。
CREATE TABLE t (
id INT NOT NULL,
data_array ARRAY < int > NOT NULL,
data_json JSON NOT NULL,
newcol1 DOUBLE AS array_avg(data_array),
newcol2 STRING AS get_json_string(json_string(data_json), '$.a')
);- 插入数据时正常插入即可(不用关心生成列),newcol1、newcol2 会自动计算并存储。
INSERT INTO t VALUES (1, [1,2], parse_json('{"a" : 1, "b" : 2}')),
(2, [3,5], parse_json('{"a" : 8, "b" : 3}'))- 查询时也正常查询即可,StarRocks 会自动改写 Query,变成对 newcol1、newcol2 的使用。
SELECT max(get_json_string(json_string(data_json),”$.a”)) AS a,
min(array_avg(data_array)) AS b
FROM t;同时,StarRocks 优化了主键模型的部分列更新功能,执行 UPDATE 语句时会开启列模式(column mode),在更新少部分列但是有大量行的场景下,可提升十倍性能。

- 在原来的「行模式」下,部分列更新时,StarRocks 会需要重写整行数据。
- 在新的「列模式」下,只需要重写更新的列数据即可。
还有,StarRocks 支持了基数保持 JOIN 表(Cardinality-preserving Joins)的裁剪,优化了点查查询性能、统计信息收集、并行 merge 算法、优化内部锁使用的逻辑等等,进一步提升各类细分场景下的查询性能。其中「基数保持 JOIN 表的裁剪」功能在较多表的星型模型(比如 SSB)和雪花模型(TPC-H)中会有用武之地,当 JOIN 的表存在主键或者外键约束,且可以满足基数保持 JOIN 表裁剪的条件,一些经过裁剪后的 JOIN 的性能能加速 10X 倍以上。在风控领域进行多种组合的特征选择时,往往采用直接查询由较多表 JOIN 后的 View,此时的裁剪就会起到不错的效果。

⚠SELECT view 时,view 中不需要用到的 Table-C 被自动裁剪掉了。使用中需要额外设置一些约束。
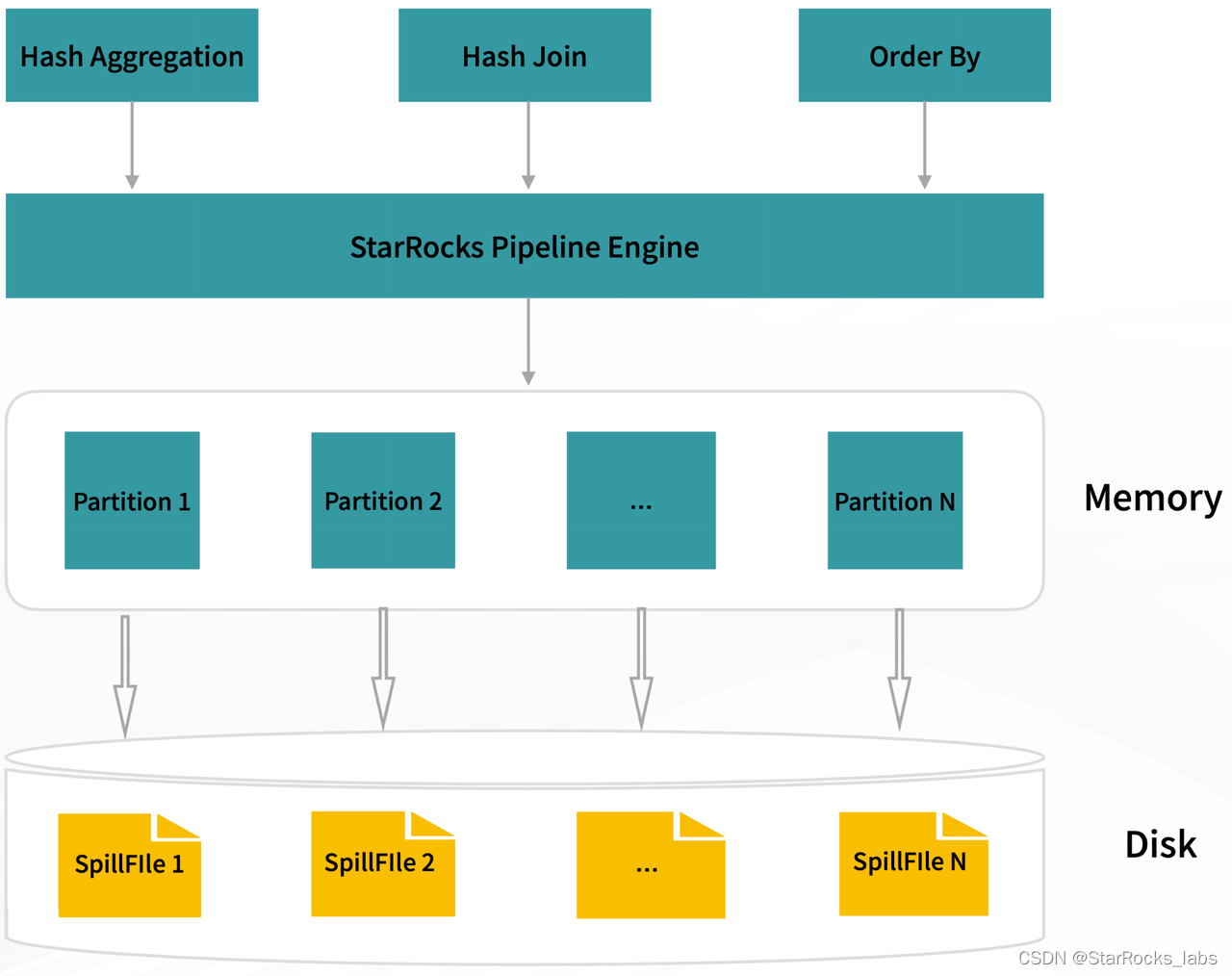
Spill To Disk 加强
除了卓越的查询性能,在大规模的数据集上查询时的稳定性也是很重要的一个方面。3.1 版本中,StarRocks 正式支持了部分阻塞算子的 Spill(中间数据落盘)能力,当查询中包括聚合、排序或者连接算子时,开启 Spill 功能将允许相关的算子将计算的中间结果缓存到磁盘上,从而降低内存占用,尽量避免查询因内存不足而失败,在物化视图构建、数据 ETL 处理等内存密集型的场景中,开启 Spill 会极大地提升查询的稳定性。在单个 BE、16core/内存限制20G 的测试环境中,开启 Spill 功能后,StarRocks 能完整地跑完 TPCH-1TB 和 TPCDS-1TB 测试集。
5、提升建表与导入的易用性
在不断优化查询性能的同时,StarRocks 持续在建表和导入方面提升产品易用性、提供更多实用功能。在建表时,用户可以配置[随机分桶 (Random Bucketing)]方式(默认),不再需要设置分桶键,StarRocks 会将导入数据随机分发到各个分桶中,同时配合使用2.5.7版本起支持的自动设置分桶数量功能(默认),用户可以不再需要关心分桶配置。
CREATE TABLE site_access(
event_day DATE,
site_id INT DEFAULT '10',
...
) DUPLICATE KEY(event_day, site_id)
PARTITION BY date_trunc('day', event_day)
DISTRIBUTED BY HASH(event_day,site_id) BUCKETS 10; -- 可以不再需要指定在导入数据时,如果数据是存储在 AWS S3/HDFS 上的 Parquet/ORC 格式文件,用户可以很简单地直接采用 [INSERT]+ [FILES()]表函数来导入数据,FILES 表函数会自动进行 table schema 推断,做到数据拿来即可 SELECT,用户甚至还可以使用 CTAS + FILES 一键式导入数据,在前期测试数据导入阶段尤其适用。
CREATE TABLE insert_wiki_edit AS
SELECT * FROM FILES(
'path' = 's3://inserttest/parquet/insert_wiki_edit_append.parquet',
'format' = 'parquet');同时,关于建表时的分区设置,一般直接设置日期时间字段作为分区列即可,如果用户想要根据自己的数据更灵活地配置,也可以使用 StarRocks 新支持的[表达式分区]和[LIST 分区方式],其中配置表达式分区后,StarRocks 会根据数据和分区表达式的定义规则自动创建分区。
并且,继 3.0 版本中湖分析支持查询[Map]、[Struct]类型数据后,3.1 版本中导入数据时也支持导入 Parquet/ORC 格式数据中的 Map、Struct 字段类型,为导入提供了更多选项。
StarRocks 在简化建表、简化导入方面将持续地进行端到端的优化,不断提升产品易用性和功能的完善性。
6、增强半结构化分析能力
3.1 版本中,StarRocks 正式原生支持了 Map 和 Struct 数据类型。除了基于湖上的半结构化数据分析,也支持建表、导入、创建物化视图。同时也补充了 Map 和 Struct 的更多函数,包括标量、聚合以及更多的 Map 高阶函数。
Array 数据类型支持了 Fast Decimal,并且 Array 函数支持了嵌套结构类型 Map、Struct 和 Array。让用户的查询分析体验更加灵活。
并且结合生成列的能力,可以进一步加速对复杂数据类型的计算与查询。例如对 JSON 内的对象的查询、大 ARRAY 的聚合计算等场景,均可以通过生成列在导入时预先完成计算,并在后续查询中通过自动改写完成查询加速。
可以认为,不论是从导入到查询的功能上、还是用生成列来优化性能上,StarRocks 基本完整地支持了 Array、JSON、Map、Struct 这类半结构化数据的能力。
最后,如你希望更加了解 StarRocks 3.1 版本,欢迎观看视频解说:
https://starrocks.feishu.cn/docx/AjsWdc28ZoAygixhZd9cdubAnBd#G8dEdRt0hozBIAxPcc6c1J5TnML
StarRocks Feature Groups:
StarRocks 社区为了让用户在使用新 features 时能更加得心应手,设立了包含”物化视图“、”湖仓分析“和”存算分离“等的用户群,欢迎小伙伴们入群对特定 feature 进行深入交流!
下方扫码添加小助手,回复关键字存算分离/湖仓分析/物化视图 即可加入对应的用户小组! <br/>https://wx.focussend.com/weComLink/mobileQrCodeLink/33412/0bfe8
在这个版本中,117 位贡献者 一共提交了 2785 个 Commits,感谢他们:
stdpain, Astralidea, mofeiatwork, yandongxiao, kevincai, Seaven, hellolilyliuyi, EsoragotoSpirit, Youngwb, andyziye, packy92, sduzh, meegoo, zaorangyang, caneGuy, silverbullet233, chaoyli, LiShuMing, trueeyu, srlch, liuyehcf, ABingHuang, luohaha, amber-create, miomiocat, sevev, letian-jiang, stephen-shelby, zombee0, nshangyiming, satanson, fzhedu, Smith-Cruise, gengjun-git, decster, TszKitLo40, starrocks-xupeng, evelynzhaojie, ZiheLiu, zhenxiao, wyb, rickif, HangyuanLiu, liuzhongjun89, dirtysalt, abc982627271, wanpengfei-git, SilvaXiang, hongli-my, kangkaisen, liuyufei9527, ggKe, xuzifu666, ucasfl, GavinMar, jkim650, JackeyLee007, tracymacding, huzhichengdd, Moonm3n, silly-carbon, imay, szza, you06, leoyy0316, Johnsonginati, smartlxh, xiangguangyxg, vendanner, QingdongZeng3, zhangruchubaba, wxl24life, banmoy, matchyc, predator4ann, huangfeng1993, dengliu, choury, bowenliang123, sebpop, RamaMalladiAWS, dustinlineweber, jiacheng-celonis, chen9t, blanklin030, wangsimo0, howrocks, qmengss, alberttwong, before-Sunrise, chenjian2664, wangruin, kobebryantlin0, wangxiaobaidu11, creatstar, kateshaowanjou, huandzh, mlimwxxnn, goldenbean, Jay-ju, ss892714028, mchades, cbcbq, shileifu, xiaoyong-z, sfwang218, uncleGen, r-sniper, blackstar-baba, ldsink, gddezero, fieldsfarmer, even986025158, idomic, yangrong688, padmejin, zuyu