前言:本篇博客主要记录Python进程的创建、进程间的通信、进程池的使用、线程的创建、多线程的执行、同步和互斥、协程的创建和应用。
目录
思维导图
基本概念
进程
进程的创建
进程间的通信
进程池
线程
线程的创建
子线程的执行顺序
同步&互斥
互斥锁
死锁
生产者消费者模式
协程
协程的创建
进程线程协程的对比
总结
思维导图

基本概念
首先来了解几个基本概念,什么是进程?什么是线程?
进程:资源分配的最小工具(管理:一个进程下包含线程)
线程:操作系统调度执行的最小单位(执行)
协程:比线程更轻量级的微线程
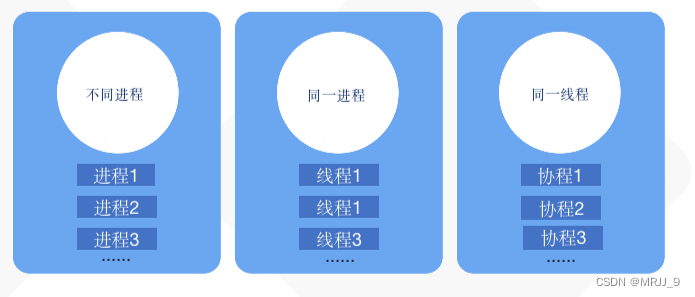
三者的关系,如图,同一进程可以有多个线程,同一线程内可以有多个协程
下面的这篇文件介绍得更为详细,推荐阅读。
干货 | 进程、线程、协程 10 张图讲明白了! - 知乎 (zhihu.com)
什么是并行?什么是并发?
并行:同一时间点,任务同时地运行,比如一台电脑,有8个CPU,每个CPU的每个核心都可以独立地执行一个任务,在同一时间点,可同时执行8个任务,这时任务是同时执行,并行地运行任务。
并发:同一时间点,只能去执行一个任务,只不过任务之间快速切换,使得看上去像是多个任务在同时运行,但实际并非如此。
进程
进程的创建
创建一个进程,其中multiprocessing 模块就是跨平台版本的多进程模块,它提供了一个 Process 类来代表一个进程对象,可以执行另外的任务,创建子进程时,只需要传入一个执行函数和函数的参数,创建一个 Process 实例,用 start()方法启动。
import time
from multiprocessing import Process
def test1():
while True:
print("--------------test1----------------")
time.sleep(10)
def test2():
while True:
print("--------------test2----------------")
time.sleep(10)
p1 = Process(target=test1())
p2 = Process(target=test2())
p1.start()
p2.start()multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={})
参数说明:
group:指定进程组
target:指定函数,执行指定的函数
name:给进程设定一个名字,可以不设定
args:给 target 指定的函数传递的参数,以元组的方式传递
kwargs:给 target 指定的函数传递命名参数
启动子进程实例 strat()
判断进程子进程是否还存在 is_alive()
关闭子进程 terminate()
等待子进程执行结束 join()
举例:执行传递参数的函数
from multiprocessing import Process
def runProc(*args, **kwargs):
print(args, kwargs)
if __name__ == '__main__':
P = Process(target=runProc, args=('test', 123), kwargs={"name": "test1","age":35})
P.start()
P.join()
print("over!")开启一个子进程,实例代码:
from multiprocessing import Process
import time
import os
class Process_Class(Process):
def __init__(self, interval):
Process.__init__(self)
self.interval = interval
def run(self):
print("子进程(%s) 开始执行,父进程为(%s)" % (os.getpid(), os.getppid()))
t_start = time.time()
time.sleep(self.interval)
t_stop = time.time()
print("(%s)执行结束,耗时%0.2f秒" % (os.getpid(), t_stop - t_start))
if __name__ == "__main__":
t_start = time.time()
print("当前程序进程(%s)" % os.getpid())
p1 = Process_Class(2)
p1.start()
p1.join()
t_stop = time.time()
print("(%s)执行结束,耗时%0.2f" % (os.getpid(), t_stop - t_start))
进程间的通信
上面我们学习了如何去创建进程,那不同进程间是如何通信的?
可以使用 multiprocessing 模块的 Queue ,实现多进程之间的数据传递,Queue 本身是一个消息 列队程序,这是操作系统开辟的一个空间,各个子程序可以把信息放进去,也可以取走,一个进程可以放多条消息到Queue中。
import multiprocessing
q = multiprocessing.Queue(3)
q.put("test1")
q.put("test2")
print(q.full())
q.put("test3")
print(q.full())
try:
q.put("test4",True,2)
except:
print("消息队列已满,现有消息数量%s"%q.qsize())
try:
q.put_nowait("test4")
except:
print("消息队列已满,现有消息数量%s" % q.qsize())
if not q.full():
q.put_nowait("test4")
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
看一下这段代码的知识点:
初始化 Queue()对象时(例如:q = Queue()),若括号中没有指定最大可接收的消息数量, 或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头)
返回当前队列包含的消息数量 Queue.qsize()
判断队列是否为空 Queue.empty()
判断队列是否满了 Queue.full()
put、get的用法:
Queue.put(item,block, timeout)
Queue.put_nowait(item),相当于 Queue.put(item, False)
将 item 消息写入队列,block 默认值为 True 如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止, 如果设置了 timeout,则会等待 timeout 秒,若还没空间,则抛出"Queue.Full"异常,如果 block 值为 False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full" 异常。
get用法与put用法,参数一样,不再赘述。
进程池
结合上面的进程间的通信,写两个函数,一个是将消息依次放入队列里,一个是从队列里依次取出消息,具体代码如下:
import multiprocessing
import time
import random
def write(q):
for value in ['a', 'b', 'c']:
print("put %s to queue" % (value))
q.put(value)
time.sleep(random.random())
def read(q):
while True:
if not q.empty():
value = q.get(True)
print("get %s from queue" % (value))
time.sleep(random.random())
else:
break
if __name__ == '__main__':
q = multiprocessing.Queue()
pw = multiprocessing.Process(target=write, args=(q,))
pr = multiprocessing.Process(target=read, args=(q,))
pw.start()
pw.join()
pr.start()
pr.join()
print("")
print("over")
下面用进程池去实现:
这段代码对比了顺序执行和并行执行耗费的时间,代码执行后的结果可以看到,并行的耗费的时间要小于顺序执行的时间。
import time
from multiprocessing import Pool
def run(f):
time.sleep(1)
return f * f
if __name__ == '__main__':
test = [1, 2, 3, 4, 5, 6]
print("顺序执行")
s = time.time()
for f in test:
run(f)
e1 = time.time()
print("顺序执行耗费时间:", int(e1 - s))
print("创建多个线程")
pool = Pool(5)
r1 = pool.map(run, test)
pool.close()
pool.join()
e2 = time.time()
print("并行执行耗费时间:", int(e2 - e1))
print(r1)
下面的代码展示了进程池中进程间是如何通信的,
其中:apply_async(func,args,kwds),使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func 的参数列表,kwds为传递给 func 的关键字参数列表。
import multiprocessing
import time, os, random
from multiprocessing import Pool
def reader(q):
print("read启动(%s),父进程为%s" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("Queue 从队列中获取到消息%s" % q.get(True))
def writer(q):
print("writer启动(%s),父进程为%s" % (os.getpid(), os.getppid()))
for i in "test001":
q.put(i)
if __name__ == '__main__':
print("(%s) start" % os.getpid())
q = multiprocessing.Manager().Queue()
po = multiprocessing.Pool()
po.apply_async(writer, (q,))
time.sleep(1)
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) end" % os.getpid())
线程
线程的创建
创建一个单线程
import time
def test():
print("test")
time.sleep(1)
if __name__ == '__main__':
StartTime = time.time()
for i in range(5):
test()
EndTime = time.time()
print("耗时%s" % (EndTime - StartTime))创建一个多线程,threading.Thread(target=test),用.start()方法启动线程。
import time,threading
def test():
print("test")
time.sleep(1)
if __name__ == '__main__':
StartTime = time.time()
for i in range(5):
t = threading.Thread(target=test)
t.start()
EndTime = time.time()
print("\n耗时%s" % (EndTime - StartTime))从执行结果上,可以明显看到多线程并发耗时要比单线程少很多。
子线程的执行顺序
可以看到下面的这段程序,子线程执行顺序是不确定的。
import time, threading
def test1():
for i in range(5):
print("---test1---")
time.sleep(1)
def test2():
for i in range(5):
print("---test2---")
time.sleep(1)
if __name__ == '__main__':
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
print("线程启动前,线程数是:", len(threading.enumerate()))
t1.start()
t2.start()
print("线程启动后,线程数是:", len(threading.enumerate()))
整个线程的生命周期:
1、new新建,初始化后,进入Runnable状态
2、Running运行:Runnable就绪,等待线程调度,调度后进入运行状态
4、Blocked阻塞,暂停运行,可能的情况有:sleep、locked、处理业务上的数据
5、Dead消亡。线程方法执行完毕返回或者异常终止
多线程之间全局变量是可以共享的,但不同线程对全局变量的修改可能带来数据混乱的问题,即线程非安全。代码示例如下:
import time, threading
num_test = 0
def test1(num):
global num_test
for i in range(num):
num_test += 1
print("test1中num_test的值是:%s"%(num_test))
def test2(num):
global num_test
for i in range(num):
num_test += 1
print("test2中num_test的值是:%s"%(num_test))
if __name__ == '__main__':
t1 = threading.Thread(target=test1,args=(1000000,))
t2 = threading.Thread(target=test2,args=(1000000,))
t1.start()
t2.start()
time.sleep(10)
print("num_test的值是:",num_test)结果如下,可以看到输出的结果出错了。 那如何处理呢?引出互斥,锁的概念。

同步&互斥
什么是同步?什么是互斥?
同步:程序必须按规定的某种顺序执行,程序A的运行依赖程序B运行产生的数据
互斥:同一公共资源,在同一时间点,只能由一个进程或线程使用
互斥锁
上面的例子中,当多个线程需要同时去修改公共数据时,就需要加入同步控制,安全访问资源的有效方式是引入互斥锁,其状态有锁定、非锁定。当某个线程需要改共享数据时,先锁定,这样,其他线程就不能更改数据,直到该线程释放资源,资源状态变成非锁定状态,其他线程才能再次锁定,然后修改,互斥锁的机制保证了每次写入操作只有一个线程,在多线程的情况下,保护了数据的正确性
threading 模块中定义了 Lock 类, 创建锁:mutex = threading.Lock(),加锁:mutex.acquire(),释放锁:mutex.release()
import multiprocessing
import time, threading
num_test = 0
def test1(num):
global num_test
for i in range(num):
mutex.acquire()
num_test += 1
mutex.release()
print("test1中num_test的值是:%s"%(num_test))
def test2(num):
global num_test
for i in range(num):
mutex.acquire()
num_test += 1
mutex.release()
print("test2中num_test的值是:%s"%(num_test))
if __name__ == '__main__':
mutex = threading.Lock()
t1 = threading.Thread(target=test1,args=(1000000,))
t2 = threading.Thread(target=test2,args=(1000000,))
t1.start()
t2.start()
time.sleep(10)
print("num_test的值是:",num_test)可以看到,这次最终计算结果是正确的。

死锁
下面我们来看一下,加锁时出现死锁的特殊情况,所谓死锁,就是多个进程一直在互相等待,程序中应该尽量避免死锁的出现
下面的这篇博客举出的死锁例子很好,可以了解一下
python—多线程之死锁_python 死锁_敲代码敲到头发茂密的博客-CSDN博客
生产者消费者模式
什么是生产者消费者模式?
生产者和消费者通过阻塞队列来进行通讯,解决生产者和消费者的强耦合问题,在生产者生产完数据之后不用等待消费者处理,消费者也不找生产者要数据,而是通过一个阻塞队列来放数据取数据。
实现代码示例:
import random
import threading
import time
from queue import Queue
class Producer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.data = queue
def run(self):
for i in range(5):
print("%s正在生产%d" % (self.getName(), i))
self.data.put(i)
time.sleep(random.randint(1, 3))
print("%s生产结束!" % (self.getName()))
class Consumer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.data = queue
def run(self):
for i in range(5):
value = self.data.get()
print("%s正在消费%d" % (self.getName(), value))
time.sleep(random.randint(1, 3))
print("%s消费结束!" % (self.getName()))
if __name__ == '__main__':
queue = Queue()
producer = Producer('Producer', queue)
consumer = Consumer('Consumer', queue)
producer.start()
consumer.start()
producer.join()
consumer.join()
print("over")
协程
协程的创建
用yeild实现一个简单的协程,代码如下:
import time
def test1():
while True:
print("test1")
yield
time.sleep(1)
def test2():
while True:
print("test2")
yield
time.sleep(1)
def main():
t1 = test1()
t2 = test2()
while True:
next(t1)
next(t2)
if __name__ == '__main__':
main()用greenlet创建协程,代码如下:
import time
import greenlet
def test1():
while True:
print("test1")
g2.switch()
time.sleep(1)
def test2():
while True:
print("test2")
g1.switch()
time.sleep(1)
g1=greenlet.greenlet(test1)
g2=greenlet.greenlet(test2)
g1.switch()
g2.switch()用gevent实现协程,代码如下:
import gevent
def f(n):
for i in range(n):
print(gevent.getcurrent(),i)
gevent.sleep(1)
g1 = gevent.spawn(f,5)
g2 = gevent.spawn(f,5)
g3 = gevent.spawn(f,5)
g1.join()
g2.join()
g3.join()
或者给程序打补丁
import time
import gevent
from gevent import monkey
monkey.patch_all()
def f(n):
for i in range(n):
print(gevent.getcurrent(),i)
time.sleep(1)
g1 = gevent.spawn(f,5)
g2 = gevent.spawn(f,5)
g3 = gevent.spawn(f,5)
g1.join()
g2.join()
g3.join()
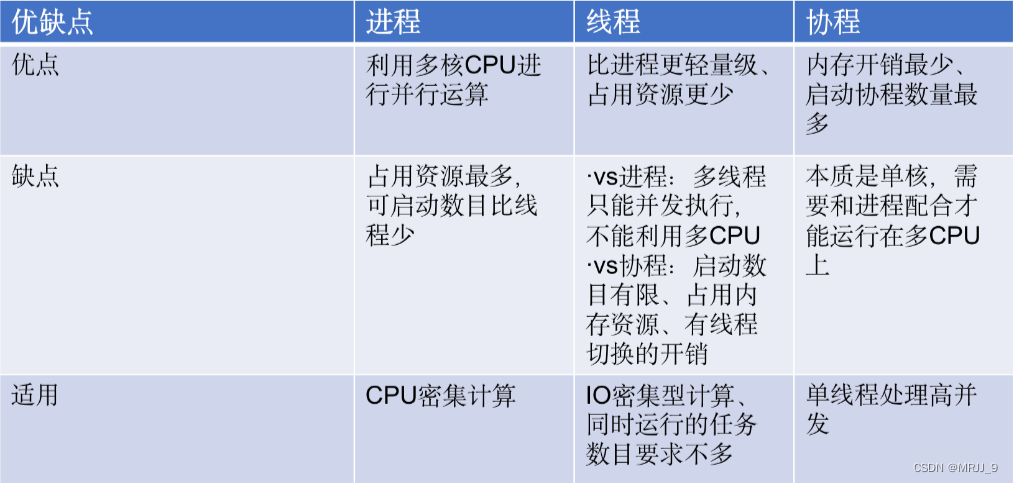
进程线程协程的对比
总结
本篇博客学习了Python中的进程、线程、协程的使用,还要多加练习,多在实际中应用感受多线程编程以及协程的使用,这部分是比较抽象,也是比较重要的一部分,python进阶的两篇学习博客暂告一段落,还是要多敲代码。