一、Spark RDD
Spark是一个高性能的内存分布式计算框架,具备可扩展性,任务容错等特性,每个Spark应用都是由一个driver program 构成,该程序运行用户的 main函数 。
Spark提供的一个主要抽象就是 RDD(Resilient Distributed Datasets),这 是一个分布在集群中多节点上的数据集合,利用内存和磁盘作为存储介质。其中内存为主要数据存储对象,支持对该数据集合的并发操作,用户可以使用HDFS中的一个文件来创建一个RDD,可以控制RDD存放于内存中还是存储与磁盘。
RDD的设计目标是针对迭代式机器学习,每个RDD是只读的、不可更改的
创建RDD
有两种方式创建一个 RDD
在driver program 中并行化一个当前的数据集合
利用一个外部存储系统中的数据集合创建
二、Spark与MapReduce对比
Spark 作为新一代的大数据计算框架,针对的是迭代式计算、实时数据处理,要求处理的时间更少,与MapReduce对比整体反映如下
1: 在中间计算结果方面 - Spark基本把数据存放在内存中,只有在内存资源不够的时候才写到磁盘等存储介质中; 而 MapReduce计算过程中 Map任务产生的 计算结果存放到本地磁盘中
2:在计算模型方面 - Spark采用 DAG 图描述计算任务,Spark拥有更丰富的功能;MapReduce则只采用 Map和 Reduce两个函数,计算功能比较简单
3:在计算速度方面 - Spark 的计算速度更快
4:在容错方面 - Spark采用了和 MapReduce类似的方式,针对丢失和无法引用的RDD,Spark采用利用记录的transform,采取重新做已做过的 transform
5:在计算成本方面 - Spark是把RDD主要存放在内存存储介质中,则需要提供高容量的内存;而 MapReduce是面向磁盘的分布式计算框架,因此在成本考虑方面,Spark的计算成本高于 MapReduce计算框架
6:在简单易管理方面 - 目前Spark也在同一个集群上运行流处理 、批处理和机器学习,同时Spark也可以管理不同类型的负载。这些都是 MapReduce做不到的
三、Spark工作机制
开始深入探讨Spark的内部工作原理,具体包括Spark运行的DAG图、Partition、容错机制、缓存管理以及数据持久化
1:DAG工作图
DAG是有向无环图
当用户运行action操作的时候, Spark调度器检查RDD的lineage图,生成一个DAG图
为了Spark更加高效的调度和计算,RDD DAG中还包括宽依赖和窄依赖
窄依赖是父节点 RDD 中的分区最多只被子节点 RDD 中的一个分区使用
宽依赖是父节点RDD中的分区被子节点 RDD 中的多个子分区使用

采用DAG方式描述运行逻辑,可以描述更加复杂的运算功能,也有利于Spark调度器调度
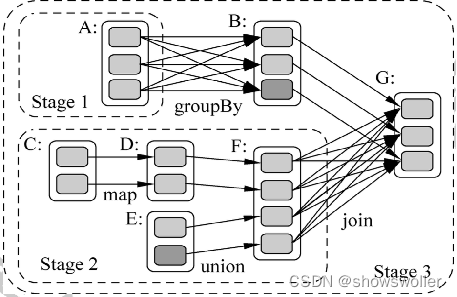
2:分区Partition
Spark 执行每次操作transformation都会产生一个新的RDD,每个RDD是Partition分区的集合
在Spark中 ,操作的粒度是Partition分区
当前支持的分区方式有hash分区和范围(range)分区
3:Linedge容错方法
在容错方面有多种方式,包括数据复制以及记录修改日志
RDD本身是一个不可更改的数据集,Spark根据transformation和action构建它的操作图DAG
当执行任务的 Worker失败时完全可以通过操作图 DAG 获得之前执行的操作,进行重新计算
针对RDD的wide dependency,最有效的容错方式同样是采用checkpoint机制 ,但是当前,Spark并没有引入auto checkpointing机制
4:内存管理
旧版本Spark的内存空间分成了3块独立的区域,每块区域的内存容量是按照JVM堆大小的固定比例进行分配的
1:Execution - 在执行shuffle、join、sort和aggregation时,Execution用于缓存中间数据 默认为0.2
2:Storage - Storage主要用于缓存数据块以提高性能,同时也用于连续不断地广播或发送大的任务结果 默认为0.6
3:Other - 这部分内存用于存储运行系统本身需要加载的代码与元数据 默认为0.2
无论是哪个区域的内存,只要内存的使用量达到了上限,则内存中存储的数据就会被放入到硬盘中,从而清理出足够的内存空间,
5:数据读取
Spark最重要的一个功能是它可以通过各种操作 (operations)持久化(或者缓存 )一 个集合到内存中
这个能力使后续的动作速度更快(通常快10倍以上)。 对应迭代算法和快速的交互使用来说,缓存是一个关键的工具
用户可以利用不同的存储级别存储每一个被持久化的RDD
四、数据读取
Spark支持多种外部数据源来创建 RDD,Hadoop支持的所有格式Spark都支持
包括HDFS Amazon S3 HBase等等
创作不易 觉得有帮助请点赞关注收藏~~~