需要全部代码请点赞关注收藏后评论区留言私信~~~
下面通过WordCount,WordMean等几个例子讲解MapReduce的实际应用,编程环境都是以Hadoop MapReduce为基础
一、WordCount
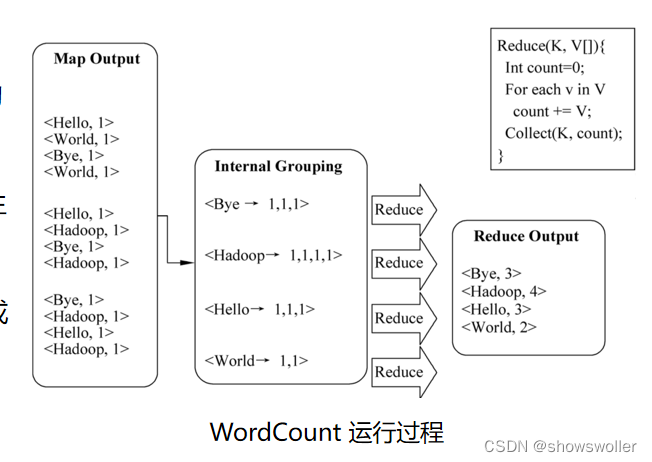
WordCount用于计算文件中每个单词出现的次数,非常适合采用MapReduce进行处理,处理单词计数问题的思路很简单,在 Map阶段处理每个文本split中的数据,产生<word,1> 这样的键-值对,在Reduce阶段对相同的关键字求和,最后生成所有的单词计数 。
运行示意图如下
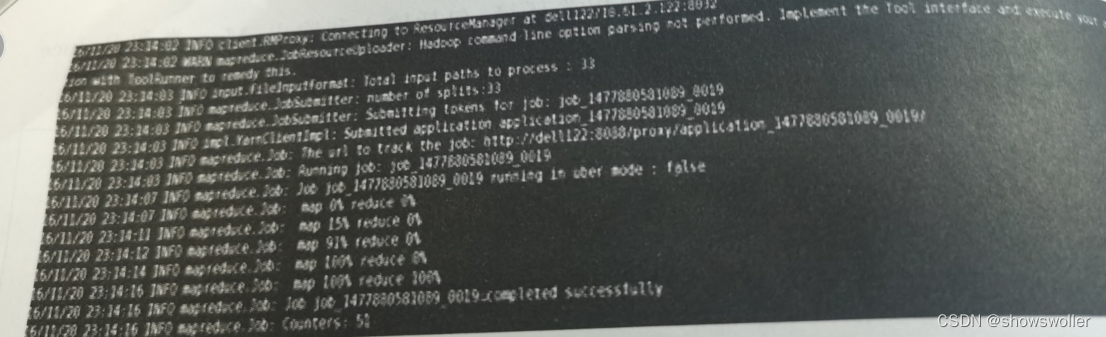
运行结果如下
二、WordMean
对上面例子的代码稍作修改,改成计算所有文件中单词的平均长度,单词长度的定义是单词的字符个数,现在HDFS集群中有大量的文件,需要统计所有文件中所出现单词的平均长度。
三、Grep
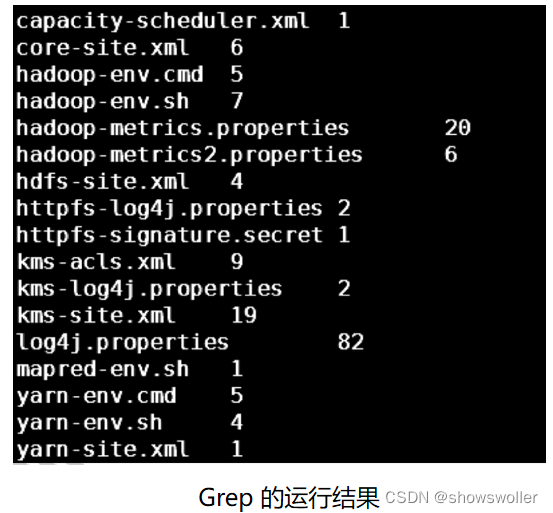
还是进行大规模文本中单词的相关操作,现在希望提供类似Linux系统中的Grep命令的功能,找出匹配目标串的所有文件,并统计出每个文件中出现目标字符串的个数。
在 Map阶段根据提供的文件split信息、给定的每个字符串输出 <filename,1> 这样 的键-值对信息
在 Reduce阶段根据filename对 Map阶段产生的结果进行合并
运行效果如下
四、代码
部分代码如下 全部代码请点赞关注收藏后评论区留言私信~
package alibook.odps;
import java.io.IOException;
import java.util.Iterator;
import com.aliyun.odps.data.Record;
import com.aliyun.odps.data.TableInfo;
import com.aliyun.odps.mapred.JobClient;
import com.aliyun.odps.mapred.MapperBase;
import com.aliyun.odps.mapred.ReducerBase;
import com.aliyun.odps.mapred.conf.JobConf;
import com.aliyun.odps.mapred.utils.InputUtils;
import com.aliyun.odps.mapred.utils.OutputUtils;
import com.aliyun.odps.mapred.utils.SchemaUtils;
public class wordcount {
public static class TokenizerMapper extends MapperBase {
private Record word;
private Record one;
@Override
public void setup(TaskContext context) throws IOException {
word = context.createMapOutputKeyRecord();
one = context.createMapOutputValueRecord();
one.set(new Object[] { 1L });
System.out.println("TaskID:" + context.getTaskID().toString());
}
@Override
public void map(long recordNum, Record record, TaskContext context)
throws IOException {
for (int i = 0; i < record.getColumnCount(); i++) {
word.set(new Object[] { record.get(i).toString() });
context.write(word, one);
}
}
}
/**
* A combiner class that combines map output by sum them.
**/
public static class SumCombiner extends ReducerBase {
private Record count;
@Override
public void setup(TaskContext context) throws IOException {
count = context.createMapOutputValueRecord();
}
@Override
public void reduce(Record key, Iterator<Record> values, TaskContext context)
throws IOException {
long c = 0;
while (values.hasNext()) {
Record val = values.next();
c += (Long) val.get(0);
}
count.set(0, c);
context.write(key, count);
}
}
/**
* A reducer class that just emits the sum of the input values.
**/
public static class SumReducer extends ReducerBase {
private Record result = null;
@Override
public void setup(TaskContext context) throws IOException {
result = context.createOutputRecord();
}
@Override
public void reduce(Record key, Iterator<Record> values, TaskContext context)
throws IOException {
long count = 0;
while (values.hasNext()) {
Record val = values.next();
count += (Long) val.get(0);
}
result.set(0, key.get(0));
result.set(1, count);
context.write(result);
}
}
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: WordCount <in_table> <out_table>");
System.exit(2);
}
JobConf job = new JobConf();
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(SumCombiner.class);
job.setReducerClass(SumReducer.class);
job.setMapOutputKeySchema(SchemaUtils.fromString("word:string"));
job.setMapOutputValueSchema(SchemaUtils.fromString("count:bigint"));
InputUtils.addTable(TableInfo.builder().tableName(args[0]).build(), job);
OutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(), job);
JobClient.runJob(job);
}
}pom.xml文件代码如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>alibook</groupId>
<artifactId>odps</artifactId>
<version>0.0.1</version>
<packaging>jar</packaging>
<name>odps</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-core</artifactId>
<version>0.23.3-public</version>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-commons</artifactId>
<version>0.23.3-public</version>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-mapred</artifactId>
<version>0.23.3-public</version>
</dependency>
</dependencies>
</project>
创作不易 觉得有帮助请点赞关注收藏~~~




![新兴新能源设施[1]--盐穴压缩空气储能相关配套设施](https://img-blog.csdnimg.cn/43b3bf44cf064095a74616ae0bf7ed5a.png)