🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
识别服装项目
数据:时尚 MNIST
视觉神经元
设计神经网络
完整代码
训练神经网络
探索模型输出
更长时间的训练——发现过度拟合
停止训练
概括
这上一章介绍了机器学习工作原理的基础知识。您了解了如何开始使用神经网络进行编程以将数据与标签匹配,以及如何从那里推断可用于区分项目的规则。合乎逻辑的下一步是将这些概念应用于计算机视觉,我们将让模型学习如何识别图片中的内容,以便它可以“看到”图片中的内容。在本章中,您将使用一个流行的服装项目数据集并构建一个可以区分它们的模型,从而“看到”不同类型服装之间的差异。
识别服装项目
为了我们的第一个例子,让我们考虑一下如何识别图像中的衣服。例如,考虑图 2-1中的项目。

图 2-1。服装示例
这里有许多不同的服装项目,您可以认出它们。你明白什么是衬衫、外套或裙子。但是,您如何向从未见过服装的人解释这一点?鞋子怎么样?这张图片中有两只鞋,但你会如何向别人描述呢?这是我们在第 1 章中谈到的基于规则的编程可能失败的另一个领域。有时用规则来描述一些东西是不可行的。
当然,计算机视觉也不例外。但是想想你是如何学会识别所有这些项目的——通过看很多不同的例子,并获得如何使用它们的经验。我们可以用电脑做同样的事情吗?答案是肯定的,但有局限性。让我们看一下第一个示例,该示例使用名为 Fashion MNIST 的著名数据集教计算机识别衣服。
数据:时尚 MNIST
一 用于学习和基准测试算法的基础数据集的一部分是由 Yann LeCun、Corinna Cortes 和 Christopher Burges 修改后的美国国家标准与技术研究院 (MNIST) 数据库。该数据集由 0 到 9 的 70,000 个手写数字的图像组成。图像为 28 × 28 灰度。
时尚 MNIST是旨在直接替代 MNIST,它具有相同的记录数、相同的图像维度和相同的类数——因此,Fashion MNIST 包含 10 种不同类型的图像,而不是数字 0 到 9 的图像衣物。您可以在图 2-2中看到数据集内容的示例。在这里,三行专用于每种服装项目类型。

图 2-2。探索时尚 MNIST 数据集
它有各种各样的服装,包括衬衫、裤子、连衣裙和许多类型的鞋子。您可能会注意到,它是单色的,因此每张图片都由一定数量的像素组成,像素值介于 0 到 255 之间。这使得数据集更易于管理。
您可以在图 2-3中看到数据集中特定图像的特写。

图 2-3。Fashion MNIST 数据集中图像的特写
与任何图像一样,它是一个矩形像素网格。在这种情况下,网格大小为 28 × 28,每个像素只是 0 到 255 之间的一个值,如前所述。现在让我们看看如何将这些像素值与我们之前看到的函数一起使用。
视觉神经元
在第一章,你看到一个非常简单的场景,机器被赋予了一组 X 和 Y 值,它了解到这些之间的关系是 Y = 2X – 1。这是使用一个非常简单的神经网络完成的,只有一层和一个神经元。
如果您要直观地绘制它,它可能看起来像图 2-4。
我们的每张图像都是 0 到 255 之间的一组 784 个值(28 × 28)。它们可以是我们的 X。我们知道我们的数据集中有 10 种不同类型的图像,所以让我们将它们视为我们的 Y。现在我们想了解 Y 是 X 的函数时的函数是什么样的。
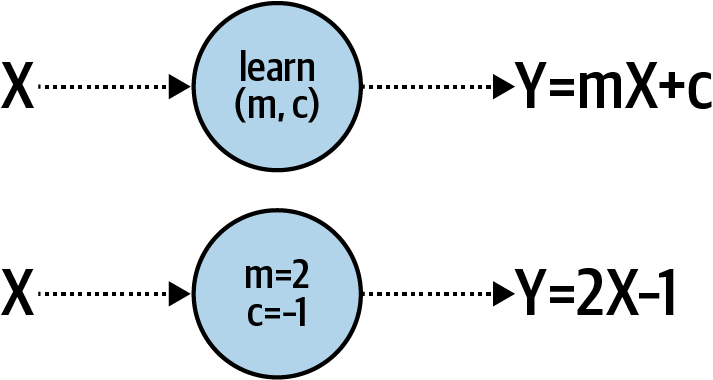
图 2-4。学习线性关系的单个神经元
鉴于我们每张图像有 784 个 X 值,并且我们的 Y 将介于 0 和 9 之间,很明显我们不能像之前那样做 Y = mX + c。
但我们能做的就是让几个神经元一起工作。其中每一个都将学习参数,当我们拥有所有这些参数的组合函数时,我们可以看看我们是否可以将该模式与我们想要的答案相匹配(图 2-5)。
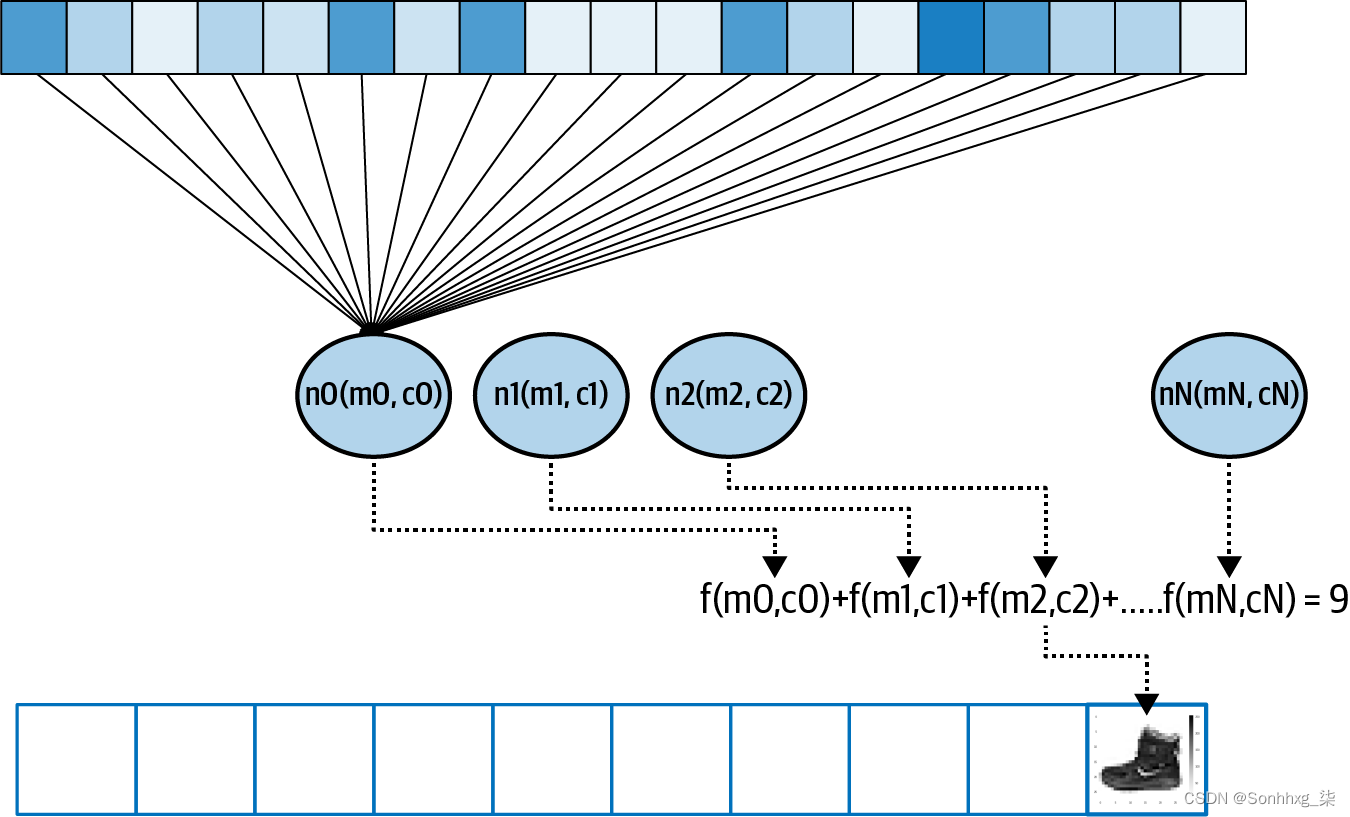
图 2-5。扩展我们的模式以获得更复杂的示例
该图顶部的框可以被认为是图像中的像素,或者我们的 X 值。当我们训练神经网络时,我们将它们加载到一层神经元中——图 2-5显示它们只是被加载到第一个神经元中,但值被加载到每个神经元中。考虑随机初始化每个神经元的权重和偏差(m 和 c)。然后,当我们将每个神经元的输出值相加时,我们将得到一个值。这将对输出层中的每个神经元完成,因此神经元 0 将包含像素加起来为标签 0 的概率值,神经元 1 为标签 1,等等。
随着时间的推移,我们希望将该值与所需的输出相匹配——对于此图像,我们可以看到数字 9,即图 2-3中所示的踝靴标签。因此,换句话说,这个神经元应该具有所有输出神经元中的最大值。
鉴于有 10 个标签,随机初始化应该在大约 10% 的时间内得到正确答案。由此,损失函数和优化器可以一个时期一个时期地完成他们的工作,调整每个神经元的内部参数,以提高那 10%。因此,随着时间的推移,计算机将学会“看”什么使鞋子成为鞋子或使裙子成为连衣裙。
设计神经网络
让我们现在探索它在代码中的样子。首先,我们来看看图 2-5中所示的神经网络的设计:
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])如果您还记得,在第 1 章中,我们有一个Sequential模型来指定我们有很多层。它只有一层,但在这种情况下,我们有多层。
这首先,Flatten不是神经元层,而是输入层规范。我们的输入是 28 × 28 的图像,但我们希望将它们视为一系列数值,如图2-5顶部的灰色框。Flatten获取那个“正方形”值(一个二维数组)并将它变成一条线(一个一维数组)。
这下一个,Dense,是一层神经元,我们指定我们需要 128 个神经元。这就是图 2-5中所示的中间层。你会经常听到这样的层被描述为 隐藏层。调用者看不到输入和输出之间的层,因此使用术语“隐藏”来描述它们。我们要求 128 个神经元随机初始化其内部参数。通常这时候我会被问到的问题是“为什么是 128?” 这完全是任意的——对于要使用的神经元数量没有固定的规则。在设计层时,您希望选择适当数量的值以使您的模型能够实际学习。更多的神经元意味着它会运行得更慢,因为它必须学习更多的参数。更多的神经元还可能导致一个网络非常擅长识别训练数据,但不擅长识别它以前没有见过的数据(这被称为过度拟合,我们将在本章后面讨论)。另一方面,更少的神经元意味着模型可能没有足够的参数来学习。
它随着时间的推移需要进行一些实验才能选择正确的值。此过程通常称为超参数调整。在机器学习中,超参数是用于控制训练的值,与被训练/学习的神经元的内部值相反,后者被称为参数。
你可能会注意到该层中还指定了一个激活函数。激活函数是将在层中的每个神经元上执行的代码。TensorFlow 支持其中的一些,但在中间层是relu,代表整流线性单元。if-then这是一个简单的函数,如果它大于 0,它只返回一个值。在这种情况下,我们不希望将负值传递到下一层以潜在地影响求和函数,因此我们可以不用编写大量代码,而是可以只需激活图层即可relu。
最后,有还有Dense一层,就是输出层。这有 10 个神经元,因为我们有 10 个类。这些神经元中的每一个最终都会有输入像素匹配该类别的概率,因此我们的工作是确定哪个具有最高值。我们可以遍历它们来选择那个值,但是softmax激活函数会为我们做这些。
所以现在当我们训练我们的神经网络时,目标是我们可以输入一个 28 × 28 像素的数组,中间层的神经元将具有权重和偏差(m 和 c 值),当它们组合在一起时会将这些像素匹配到10 个输出值之一。
完整代码
现在我们已经探索了神经网络的架构,让我们看一下使用 Fashion MNIST 数据训练神经网络的完整代码:
import tensorflow as tf
data = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = data.load_data()
training_images = training_images / 255.0
test_images = test_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)让我们一块一块地过一遍。首先是访问数据的便捷快捷方式:
data = tf.keras.datasets.fashion_mnist难的有许多内置数据集,您可以像这样使用一行代码访问这些数据集。在这种情况下,您不必处理 70,000 张图像的下载——将它们分成训练集和测试集,等等——只需要一行代码。这种方法在使用称为TensorFlow Datasets的 API 后得到了改进,但是为了这些早期章节的目的,为了减少您需要学习的新概念的数量,我们将只使用 tf.keras.datasets.
我们load_data可以像这样调用它的方法来返回我们的训练和测试集:
(training_images, training_labels),
(test_images, test_labels) = data.load_data()Fashion MNIST 旨在拥有 60,000 张训练图像和 10,000 张测试图像。因此, from 的返回值data.load_data将为您提供一个包含 60,000 个 28 × 28 像素数组的数组,称为training_images,以及一个包含 60,000 个值 (0–9) 的数组,称为training_labels。同样,该test_images数组将包含 10,000 个 28 × 28 像素的数组,该test_labels数组将包含 10,000 个介于 0 和 9 之间的值。
我们的工作将是将训练图像与训练标签相匹配,其方式与我们在第 1 章中将 Y 与 X 相匹配的方式类似。
我们将阻止测试图像和测试标签,以便网络在训练时看不到它们。这些可用于测试具有迄今为止未见数据的网络的功效。
接下来的代码行可能看起来有点不寻常:
training_images = training_images / 255.0
test_images = test_images / 255.0Python允许您使用此表示法对整个数组执行操作。回想一下,我们图像中的所有像素都是灰度的,值介于 0 和 255 之间。因此,除以 255 可确保每个像素都由 0 到 1 之间的数字表示。这个过程称为 规范化图像。
为什么归一化数据更适合训练神经网络的数学原理超出了本书的范围,但在 TensorFlow 中训练神经网络时请记住,归一化会提高性能。在处理非规范化数据时,您的网络通常不会学习并且会出现大量错误。第 1 章中的 Y = 2X – 1 示例不需要对数据进行归一化,因为它非常简单,但为了好玩,尝试使用不同的 X 和 Y 值对其进行训练,其中 X 大得多,您很快就会看到它失败!
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])什么时候我们编译我们的模型,我们像以前一样指定损失函数和优化器:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])这这种情况下的损失函数称为稀疏分类交叉熵,它是 TensorFlow 中内置的损失函数库之一。再次,选择哪个使用损失函数本身就是一门艺术,随着时间的推移,您将了解哪些最适合在哪些场景中使用。该模型与我们在第 1 章中创建的模型之间的一个主要区别在于,我们不是试图预测单个数字,而是选择一个类别。我们的衣服属于 10 种衣服中的一种,因此使用分类损失函数是可行的方法。稀疏分类交叉熵是一个不错的选择。
这这同样适用于选择优化器。这 adamsgd优化器是我们在第 1 章中使用的随机梯度下降 ( ) 优化器的演变,它已被证明更快、更有效。由于我们正在处理 60,000 张训练图像,我们可以获得的任何性能改进都会有所帮助,因此这里选择一个。
接下来,我们将通过在五个时期内将训练图像拟合到训练标签来训练网络:
model.fit(training_images, training_labels, epochs=5)最后,我们可以做一些新的事情——评估模型,使用一行代码。我们有一组 10,000 张图像和标签用于测试,我们可以将它们传递给经过训练的模型,让它预测它认为每张图像是什么,将其与实际标签进行比较,然后总结结果:
model.evaluate(test_images, test_labels)训练神经网络
执行代码,你会看到一个时代一个时代的网络训练。运行训练后,您会在最后看到如下所示的内容:
58016/60000 [=====>.] - ETA: 0s - loss: 0.2941 - accuracy: 0.8907
59552/60000 [=====>.] - ETA: 0s - loss: 0.2943 - accuracy: 0.8906
60000/60000 [] - 2s 34us/sample - loss: 0.2940 - accuracy: 0.8906请注意,它现在正在报告准确性。因此,在这种情况下,使用训练数据,我们的模型仅在五个 epoch 后就达到了大约 89% 的准确率。
但是测试数据呢?这我们的测试数据的结果model.evaluate将如下所示:
10000/1 [====] - 0s 30us/sample - loss: 0.2521 - accuracy: 0.8736在这种情况下,模型的准确率为 87.36%,考虑到我们只训练了五个 epoch,这还不错。
例如,如果您从小到大只看到运动鞋,而这就是您眼中的鞋子,那么当您第一次看到高跟鞋时,您可能会有些困惑。根据你的经验,它可能是一只鞋,但你不确定。这是一个类似的概念。
探索模型输出
现在该模型已经过训练,并且我们可以使用测试集对其准确性进行很好的衡量,让我们稍微探索一下:
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])我们将通过将测试图像传递给 来获得一组分类model.predict。然后让我们看看如果我们打印出第一个分类并将其与测试标签进行比较会得到什么:
[1.9177722e-05 1.9856788e-07 6.3756357e-07 7.1702580e-08 5.5287035e-07
1.2249852e-02 6.0708484e-05 7.3229447e-02 8.3050705e-05 9.1435629e-01]
9您会注意到分类返回了一组值。这些是 10 个输出神经元的值。在本例中,标签是衣服的实际标签9。仔细查看数组 — 您会发现一些值非常小,而最后一个(数组索引 9)是迄今为止最大的。这些是图像在该特定索引处与标签匹配的概率。因此,神经网络报告的是索引 0 处的衣服有 91.4% 的可能性是标签 9。我们知道它是标签 9,所以它是正确的。
为自己尝试几个不同的值,看看是否可以找到模型出错的地方。
更长时间的训练——发现过度拟合
尝试更新它以训练 50 个时期而不是 5 个时期。在我的例子中,我在训练集上得到了这些准确度数据:
58112/60000 [==>.] - ETA: 0s - loss: 0.0983 - accuracy: 0.9627
59520/60000 [==>.] - ETA: 0s - loss: 0.0987 - accuracy: 0.9627
60000/60000 [====] - 2s 35us/sample - loss: 0.0986 - accuracy: 0.9627这特别令人兴奋,因为我们做得更好:96.27% 的准确率。对于测试集,我们达到了 88.6%:
[====] - 0s 30us/sample - loss: 0.3870 - accuracy: 0.8860因此,我们在训练集上得到了很大的改进,而在测试集上得到了较小的改进。这可能表明,对我们的网络进行更长时间的训练会导致更好的结果——但情况并非总是如此。网络在训练数据上做得更好,但它不一定是更好的模型。事实上,准确率数字的差异表明它已经对训练数据过度专业化,这个过程通常称为过度拟合。当你构建更多的神经网络时,这是需要注意的事情,并且当你阅读本书时,你将学到一些避免它的技术。
停止训练
最简单的方法是使用 训练回调。让我们看一下使用回调的更新代码:
import tensorflow as tf
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('accuracy')>0.95):
print("\nReached 95% accuracy so cancelling training!")
self.model.stop_training = True
callbacks = myCallback()
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels),
(test_images, test_labels) = mnist.load_data()
training_images=training_images/255.0
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=50,
callbacks=[callbacks])让我们看看我们在这里做了什么改变。首先,我们创建了一个名为myCallback. 这需要一个tf.keras.callbacks.Callback作为参数。在其中,我们定义了on_epoch_end函数,它将为我们提供有关该时期日志的详细信息。在这些日志中有一个精度值,因此我们要做的就是查看它是否大于 0.95(或 95%);如果是,我们可以通过说停止训练self.model.stop_training = True。
一旦我们指定了这个,我们就创建一个callbacks对象作为myCallback函数的一个实例。
现在检查model.fit声明。您会看到我已将其更新为训练 50 个时期,然后添加了一个callbacks参数。为此,我传递了callbacks对象。
训练时,在每个 epoch 结束时,都会调用回调函数。所以在每个 epoch 结束时你会检查,在大约 34 个 epoch 之后你会看到你的训练将结束,因为训练已经达到 95% 的准确率(你的数字可能因为初始随机初始化而略有不同,但是它可能非常接近 34):
56896/60000 [====>..] - ETA: 0s - loss: 0.1309 - accuracy: 0.9500
58144/60000 [====>.] - ETA: 0s - loss: 0.1308 - accuracy: 0.9502
59424/60000 [====>.] - ETA: 0s - loss: 0.1308 - accuracy: 0.9502
Reached 95% accuracy so cancelling training!概括
在第 1 章中,您了解了机器学习如何基于通过神经网络的复杂模式匹配将特征拟合到标签。在本章中,您将其提升到了一个新的水平,超越了单个神经元,并学习了如何创建您的第一个(非常基础的)计算机视觉神经网络。由于数据的原因,它有些受限。所有图像均为 28 × 28 灰度,衣服位于画面中央。这是一个好的开始,但这是一个非常受控的场景。为了在视觉上做得更好,我们可能需要计算机学习图像的特征,而不仅仅是原始像素。
我们可以通过称为卷积的过程来做到这一点。在下一章中,您将学习如何定义卷积神经网络以理解图像的内容。