在日常生活中,大家经常会遇到图像关键信息自动抽取的场景,比如身份证拍照上传自动识别、发票拍照上传自动报销等。
在这个领域,现有的AI技术方案已经能解决一部分需求,但是依然存在一些痛点,比如发票的种类样式极其繁多,基于OCR文字识别+规则后处理的方案无法有效覆盖全部样式,即泛化性很差。如果要强行覆盖全部样式,成本又太高。
针对这样的问题,飞桨团队隆重推出基于文心大模型的全新解决方案——PP-ChatOCR!
PP-ChatOCR将LLM(Large Language Model)与经典的PP-OCR模型结合,达到了通用场景下的图片关键信息抽取效果,支持身份证、银行卡、户口本、火车票等多种场景的关键信息提取。
您只需要指明自己所关注的字段,PP-ChatOCR就能帮您从图片中提取出这些字段的信息!
下面来看看效果~




左右滑动查看更多内容
要知道,这后面仅仅是一套OCR模型和针对LLM的Prompt模板哦!这强大的泛化能力,不可谓不香了~
小伙伴们是不是等不及要亲自体验了?来,上链接!https://aistudio.baidu.com/aistudio/projectdetail/6488689

在飞桨AI套件中使用PP-ChatOCR
PP-ChatOCR今天正式上线飞桨AI套件PaddleX!源码全部开放!您可以在AI Studio云端或者PaddleX本地端尽情探索!一方面可以发挥您的想象力修改Prompt,另一方面您也可以在PaddleX中对PP-OCRv4做训练微调。同时PaddleX还支持PP-ChatOCR的高性能部署,赶快尝试与真实业务场景结合,体验LLM带来的生产力变革吧!
PP-ChatOCR链接:https://aistudio.baidu.com/aistudio/modelsdetail?modelId=332
PaddleX是一站式、全流程、高效率的飞桨AI套件,具备飞桨生态优质模型和产业方案。PaddleX的使命是助力AI技术快速落地,愿景是使人人成为AI Developer。
PaddleX支持10+任务能力,包括图像分类、目标检测、图像分割、3D、OCR和时序预测等;内置36 种飞桨生态特色模型,包括PP-ChatOCR、PP-OCRv4、RP-DETR、PP-YOLOE、PP-ShiTu、PP-LiteSeg、PP-TS等。
PaddleX提供“工具箱”和“开发者”两种开发模式,同时支持云端和本地端。工具箱模式可以无代码调优关键超参,开发者模式可以低代码进行单模型训压推和多模型串联推理。
PaddleX未来还将支持联创开发,收益共享!欢迎广大个人开发者和企业开发者参与进来,共创繁荣的AI技术生态!
目前PaddleX正在快速迭代,欢迎大家试用和指正!比心~
PaddleX本地端即将开放内部测试,扫码进群优先体验PaddleX本地端!

微信扫描二维码添加运营同学,并回复【PaddleX】,运营同学会邀请您加入官方交流群,先人一步体验PaddleX本地端,获得更高效的问题答疑!

PP-ChatOCR核心思想
PP-ChatOCR为什么能做到通用的图像关键信息抽取?这样的能力带来了怎样的价值?让我们从PP-ChatOCR的设计核心思想来一探究竟。

传统OCR+规则的信息抽取:规则复杂,泛化能力差
在传统的图像关键信息抽取技术方案中,主要思路是先经过OCR文字识别,然后根据业务需求,设计一整套规则来提取若干关键信息。这样的做法有一些明显的缺点:
(1)泛化能力差。图像中文字编排略有调整,可能就需要修改提取规则。
(2)扩展能力差。新增规则复杂,关键信息字段与规则数量成正比,成本较高。


PP-ChatOCR:扩展能力强,泛化能力强,开发成本降低
图像关键信息提取的关键点在于对OCR识别结果的规则化处理。如上所述,传统的技术方案采用人工编写规则的“硬编码”方式,不够优雅,泛化能力很差。那么,既然OCR识别结果都是文字,把规则化处理的工作交给号称具备了AGI雏形能力的LLM来做会不会有很好的效果呢?答案是肯定的。把不经任何处理加工的OCR识别结果直接喂给LLM,编写好Prompt提示词,就能非常准确、稳定地获得我们所关注的关键信息了。
PP-ChatOCR的泛化能力极强,只要OCR能顺利识别出来关键文字,PP-ChatOCR理论上就能提取出关键信息,甚至少量的文字识别错误也能被LLM自动纠正!
PP-ChatOCR的扩展能力也很强,如果业务中需要额外提取新的字段信息,只需要修改一下Prompt,就搞定了全部工作!
这样一来,搭建一套通用图像关键信息抽取系统的成本就大大下降了,而这就是大模型技术变革带来的生产力提升!


PP-ChatOCR要点解读
PP-ChatOCR整体的技术框架如下图所示。

整体来说,PP-ChatOCR的技术流程还是比较简单的,一共分为以下若干步骤:
OCR推理。使用OCR模型对输入图像进行文字检测识别处理,这里PP-ChatOCR默认使用了PP-OCR系列的最高精度模型--PP-OCRv4_server,保证在速度不敏感的服务器端提供最准确的OCR识别结果。
场景判别。直接将OCR识别的结果送入LLM,并询问LLM“根据当前的OCR识别结果,当前图像的场景属于以下场景列表的哪一种:【火车票】、【身份证】、【驾照】、【营业执照】、【学位证书】...文心大模型基本可以做到100%的场景判别准确率。
Prompt构造。在Prompt构造环节,由于我们要使用few-shot learning 或者所谓的in-context learning的技巧,需要知道当前图像所属于的场景,所以正好用上第二步场景判别的结果。除了few-shot learning之外,通用的PP-ChatOCR暂时没有使用其它特别的技巧,仅仅是将任务要求描述清楚,让大模型输出json格式的结果,方便我们解析。
后处理。理想情况下大模型的输出结果应当是符合预期的json,但是众所周知LLM是一个黑盒子,总会有一些意外存在,为了能够在业务系统中稳定运行,就必须妥善处理这些意外。PP-ChatOCR目前实现了json格式检查等后处理操作,在真实业务场景下,可以设置更多的后处理规则,以保证系统的可靠性。
值得注意的是,如果您在一个明确的场景中使用PP-ChatOCR,上述第二步场景判别过程是可以省略的,第三步的few-shot learning直接提供该场景下的例子即可。
整体看下来,不知道大家有没有发现,虽然PP-ChatOCR名字里面带了Chat一词,但是在使用上并没有显式的Chat过程。这里稍微解释一下,PP-ChatOCR面向的是真实业务场景的落地,是需要集成到业务系统中自动化运行的。要做到这一点,就必须要求其输出格式化的结果,不能有废话(这个其实很关键),而且整体精度要足够高。在真实的图像关键信息提取的场景中,几乎没有人会拿一张火车票或者证件去跟LLM“聊天”,所以即使在AI Studio的应用中心,PP-ChatOCR也没有要求大家像使用ChatBot一样聊天。而之所以带上Chat一词,归根到底还是跟LLM产生了对话,而且现在跟LLM相关的项目,动辄就要带上Chat,我们也不能例外。
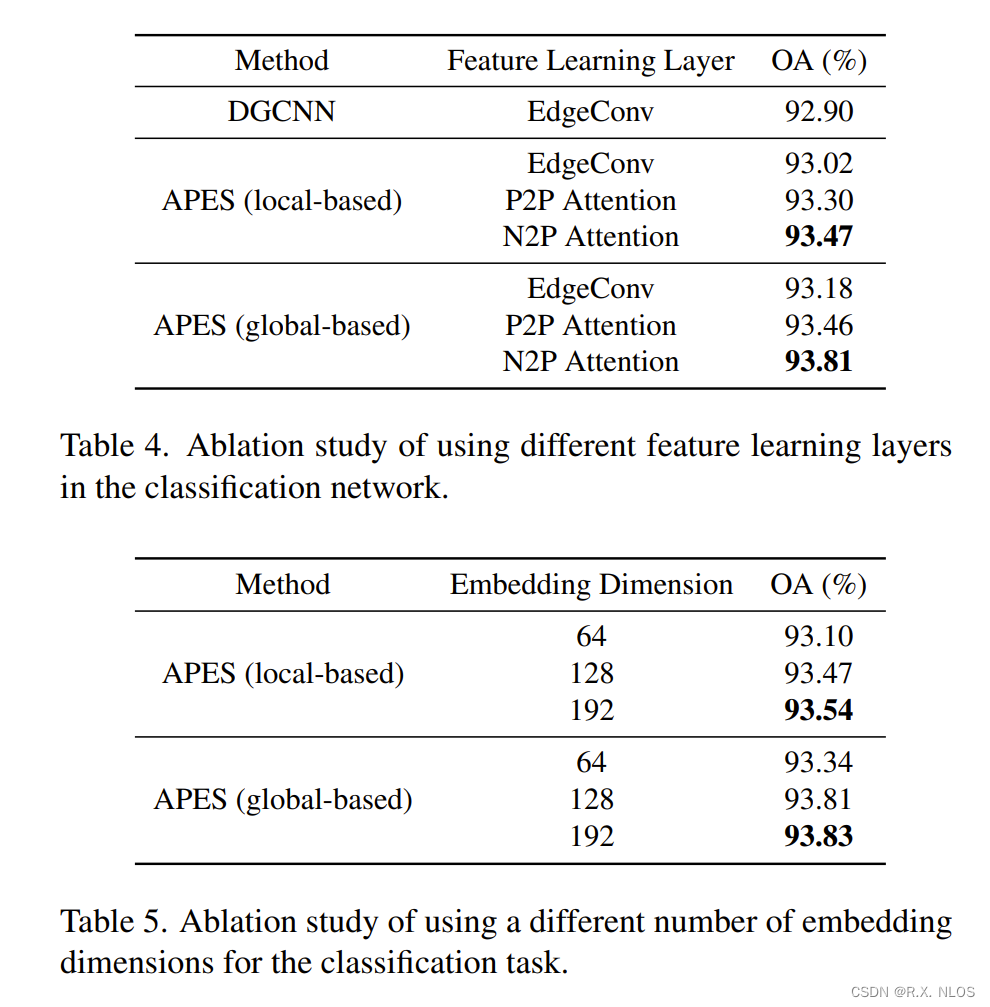
就这一套通用场景下的PP-ChatOCR技术方案,基于一个通用的PP-OCRv4模型、一套共用的Prompt模板,没有增加复杂的前后处理逻辑,目前在12种图像场景中,已经达到了平均80%以上的精度。在一些相对简单的场景(例如身份证)中,精度可达97%。
在此基础之上,大家可以充分发挥想象力,进行垂类场景中PP-ChatOCR能力的定制优化,比如说可以使用更强大的OCR模型、使用更多的Prompt工程技巧、添加更多的前后处理规则等。在下面一小节,我们就来聊一聊如何打造个性化的PP-ChatOCR。

如何打造个性化的PP-ChatOCR
在真实业务中,一般不建议直接使用通用版的PP-ChatOCR,而是需要针对业务场景中的图像类型进行专门的优化适配,以实现足够高的精度和稳定性,满足真实业务需求。那么,如何打造个性化的PP-ChatOCR呢?下面让我们一一道来。
 获取文心大模型调用能力
获取文心大模型调用能力
首先,我们需要有方法调用文心大模型的能力。AI Studio SDK 中集成了文心大模型服务调用能力,所以没有申请到API的同学也可以在AI Studio直接调用文心大模型了!具体使用方式请扫描文章底部的二维码进群了解~

创建PP-ChatOCR模型产线
飞桨AI套件PaddleX已上线AI Studio平台,目前的入口在模型库,大家可以在这里找到PP-ChatOCR,阅读其介绍文档,并最终创建属于你自己的PP-ChatOCR模型产线。
AI Studio模型库链接如下:https://aistudio.baidu.com/aistudio/modelsoverview?supportPaddlex=true&sortBy=weight

准备评估数据与效果验证
为了客观地评价PP-ChatOCR的效果,建议大家从业务场景中准备一定量的评估数据进行定量的综合评价。例如,可以准备50张火车票图像,根据业务需求标注所关注的字段及其真值。
在对通用的PP-ChatOCR效果进行评估之后,其结果可以作为baseline指导后续针对业务场景的优化工作。

针对业务场景的优化
终于来到了关键的环节,在这里,我们讨论如何针对具体的垂类业务场景进行PP-ChatOCR的优化。
PP-ChatOCR由传统的OCR模型和文心大模型两部分组成,所以优化大致可以分为两个方面:一是训练微调OCR模型,使之在垂类场景中的精度进一步提高;二是“调教”文心大模型,通过Prompt工程和适当的后处理工作使大模型能够输出我们想要的结果,甚至可以考虑对LLM进行微调。
微调OCR模型方面,推荐大家使用飞桨最新推出的PP-OCRv4模型。PP-OCRv4 是实用的超轻量通用OCR模型。在实现前沿算法的基础上,考虑精度与速度的平衡,进行了模型瘦身和深度优化。在飞桨AI套件中即可体验和训练微调PP-OCRv4,大大提高开发效率。
链接如下:https://aistudio.baidu.com/aistudio/modelsoverview?category=%E5%9F%BA%E7%A1%80%E6%A8%A1%E5%9E%8B&supportPaddlex=1&sortBy=weight&task=%E6%96%87%E5%AD%97%E8%AF%86%E5%88%AB
“调教”文心大模型方面,大家就有非常广阔的发挥空间了。Prompt方面,大家可以基于PP-ChatOCR提供的基础Prompt进行优化。比如最常见实用的in-context learning技巧,给LLM几个例子,效果通常就会有明显的提高。再比如给大模型一些场景相关的信息,让大模型充分理解上下文语境,应该也能带来一些效果提升。另外,对大模型输出的约束也很重要,比如不能输出废话,不能被恶意使用者越狱等。最后还有一个终极大招,就是对大模型本身进行微调。不过目前来看文心大模型现有的能力已经能够满足PP-ChatOCR的使用场景,因此大概率是没必要“杀鸡用牛刀”的。
到了这一步,作为PP-ChatOCR的使用者,模型开发基本就结束了。经过上述步骤的全方位调优之后,确认在评估数据中的精度和稳定性达标,就可以着手部署到真实的业务系统中去啦!
One more thing,未来在飞桨AI套件PaddleX,大家不仅可以开发自己的模型,还可以联创贡献,和平台收益共享!
联创模式不仅可以技术变现,还可以让个人开发者收获满满的成就感,为企业开发者吸引流量和关注,真可谓好事成双!而且,有了大量的用户,就能够收集到有价值的反馈,促进贡献者进一步优化模型,从而吸引更多的用户,可谓双螺旋上升~
为了保护贡献者的知识产权,我们会提供完善的加密鉴权机制,各位贡献者只需要按照我们的文档接入加密鉴权能力,就可以放心地贡献模型啦!关于联创的更多细节,敬请关注飞桨AI套件PaddleX后续更新!
最后,再次邀请大家进入PaddleX用户交流群~共创繁荣AI技术生态~
微信扫描二维码添加运营同学,并回复【PaddleX】,运营同学会邀请您加入官方交流群,先人一步体验PaddleX本地端,获得更高效的问题答疑!

PP-ChatOCR所使用的PP-OCRv4模型,目前已发布在PaddleOCR 2.7新版本中,欢迎大家使用!
AI Studio应用中心体验PP-ChatOCR:https://aistudio.baidu.com/aistudio/projectdetail/6488689
飞桨AI套件PaddleX中的PP-ChatOCR:https://aistudio.baidu.com/aistudio/modelsdetail?modelId=332
PaddleOCR GitHub: https://github.com/PaddlePaddle/PaddleOCR





关注【飞桨PaddlePaddle】公众号
获取更多技术内容~