注:本文的SIMD,指的是CPU指令架构中的相关概念。不涉及GPU端的算力机制。
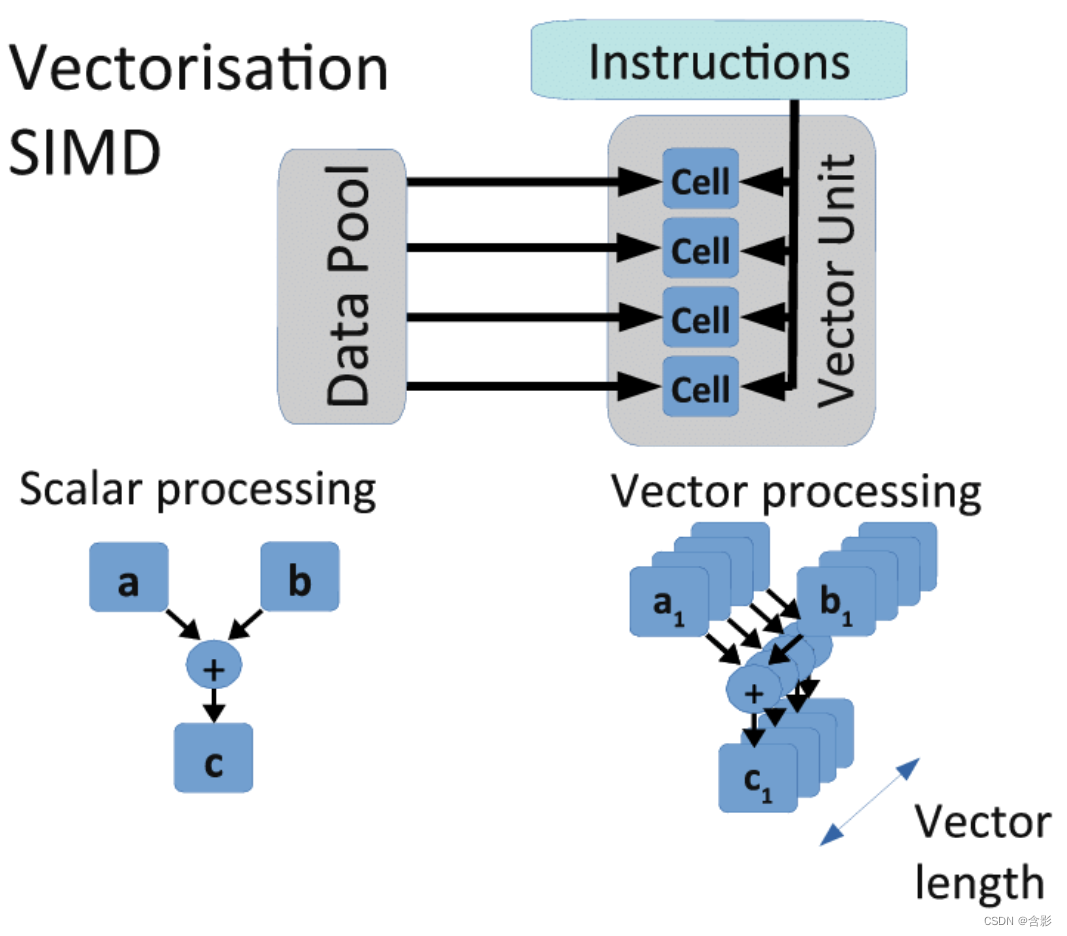
基本概念
SIMD,Single Instruction/Multiple Data, 即单指流令多数据流,例如一个乘法指令,可以并行的计算8个浮点数的乘法。
SIMD(Single Instruction/Multiple Data, 即)是目前通用的CPU端的指令级并行计算机制,也叫做矢量运算,这些SIMD包括SSE和AVX。
通过代码直观的简介SIMD机制
用下面两份代码做个基本说明
非矢量运算的代码
void mul4_scalar( float* ptr )
{
for( int i = 0; i < 4; i++ )
{
const float f = ptr[ i ];
ptr[ i ] = f * f;
}
}矢量运算的代码
void mul4_vectorized( float* ptr )
{
__m128 f = _mm_loadu_ps( ptr );
f = _mm_mul_ps( f, f );
_mm_storeu_ps( ptr, f );
}
// __m128 就是sse simd 对象
// _mm_mul_ps 和 _mm_storeu_ps 就是对应的乘法和赋值矢量运算指令(函数)上述两份代码源自于: http://const.me/articles/simd/simd.pdf
不难看出,在密集计算中SIMD程序的效能肯定比常规程序高很多。(这里就不去和异构计算架构下的机制做比较了)
相关指令在源代码中的位置
Linux系统GCC
gcc-master\gcc\config\i386\immintrin.h头文件中包含了各种simd指令的相关头文件
SSE, __m128, 这类SSE指令位置: gcc-master\gcc\config\i386\xmmintrin.h
/* The Intel API is flexible enough that we must allow aliasing with other
vector types, and their scalar components. */
typedef float __m128 __attribute__ ((__vector_size__ (16), __may_alias__));SSE2, __v4si, __128d定义在 gcc-master\gcc\config\i386\emmintrin.h中
typedef int __v4si __attribute__ ((__vector_size__ (16)));
typedef double __m128d __attribute__ ((__vector_size__ (16), __may_alias__));MMX指令 __m64定义在 gcc-master\gcc\config\i386\mmintrin.h中
typedef int __m64 __attribute__ ((__vector_size__ (8), __may_alias__));
typedef int __m32 __attribute__ ((__vector_size__ (4), __may_alias__));
typedef short __m16 __attribute__ ((__vector_size__ (2), __may_alias__));AVX指令, _v4df, __v8si, __m256定义在gcc-master\gcc\config\i386\avxintrin.h中
typedef double __v4df __attribute__ ((__vector_size__ (32)));
typedef int __v8si __attribute__ ((__vector_size__ (32)));
typedef unsigned char __v32qu __attribute__ ((__vector_size__ (32)));
typedef float __m256 __attribute__ ((__vector_size__ (32),
__may_alias__));linux系统中矢量运算 __attribute__ vector_size 定义的说明:
typedef int v4si __attribute__ ((vector_size (16)));
The int type specifies the base type, while the attribute specifies the vector size for the variable, measured in bytes. For example, the declaration above causes the compiler to set the mode for the v4si type to be 16 bytes wide and divided into int sized units. For a 32-bit int this means a vector of 4 units of 4 bytes, and the corresponding mode of foo will be V4SI.
相关细节请见: Vector Extensions (Using the GNU Compiler Collection (GCC))
Windows系统MSVC
头文件 Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.33.31629\include\intrin.h,也已经包含了相关指令函数的头文件
__m128d, __m128i定义在 Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.33.31629\include\emmintrin.h中
typedef union __declspec(intrin_type) __declspec(align(16)) __m128i {
__int8 m128i_i8[16];
__int16 m128i_i16[8];
__int32 m128i_i32[4];
__int64 m128i_i64[2];
unsigned __int8 m128i_u8[16];
unsigned __int16 m128i_u16[8];
unsigned __int32 m128i_u32[4];
unsigned __int64 m128i_u64[2];
} __m128i;
typedef struct __declspec(intrin_type) __declspec(align(16)) __m128d {
double m128d_f64[2];
} __m128d;__m128d, __m128i定义在 Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.33.31629\include\emmintrin.h
typedef union __declspec(intrin_type) __declspec(align(16)) __m128i {
__int8 m128i_i8[16];
__int16 m128i_i16[8];
__int32 m128i_i32[4];
__int64 m128i_i64[2];
unsigned __int8 m128i_u8[16];
unsigned __int16 m128i_u16[8];
unsigned __int32 m128i_u32[4];
unsigned __int64 m128i_u64[2];
} __m128i;
typedef struct __declspec(intrin_type) __declspec(align(16)) __m128d {
double m128d_f64[2];
} __m128d;AVX, __m256d, __m256, __m256i定义在 Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.33.31629\include\immintrin.h中
/*
* Intel(R) AVX compiler intrinsic functions.
*/
typedef union __declspec(intrin_type) __declspec(align(32)) __m256 {
float m256_f32[8];
} __m256;
typedef struct __declspec(intrin_type) __declspec(align(32)) __m256d {
double m256d_f64[4];
} __m256d;
typedef union __declspec(intrin_type) __declspec(align(32)) __m256i {
__int8 m256i_i8[32];
__int16 m256i_i16[16];
__int32 m256i_i32[8];
__int64 m256i_i64[4];
unsigned __int8 m256i_u8[32];
unsigned __int16 m256i_u16[16];
unsigned __int32 m256i_u32[8];
unsigned __int64 m256i_u64[4];
} __m256i;两个系统的定义有区别,所以跨平台应用这些SIMD功能需要主要一些细节。
检查Linux系统或者Windows系统对SSE和AVX的支持情况
注:下面的代码本人常用在在Linux Centos7和Windows 10上
检测代码如下:
#include <iostream>
#ifdef _MSC_VER
# include <intrin.h>
void __cpuidSpec(int p0[4], int p1)
{
__cpuid(p0, p1);
}
unsigned __int64 __cdecl _xgetbvSpec(unsigned int p)
{
return _xgetbv(p);
}
#endif
#ifdef __GNUC__
void __cpuidSpec(int* cpuinfo, int info)
{
__asm__ __volatile__(
"xchg %%ebx, %%edi;"
"cpuid;"
"xchg %%ebx, %%edi;"
: "=a"(cpuinfo[0]), "=D"(cpuinfo[1]), "=c"(cpuinfo[2]), "=d"(cpuinfo[3])
: "0"(info));
}
unsigned long long _xgetbvSpec(unsigned int index)
{
unsigned int eax, edx;
__asm__ __volatile__(
"xgetbv;"
: "=a"(eax), "=d"(edx)
: "c"(index));
return ((unsigned long long)edx << 32) | eax;
}
#include <immintrin.h>
#endif
namespace sseavx
{
void sseavxCheck()
{
bool sseSupportted = false;
bool sse2Supportted = false;
bool sse3Supportted = false;
bool ssse3Supportted = false;
bool sse4_1Supportted = false;
bool sse4_2Supportted = false;
bool sse4aSupportted = false;
bool sse5Supportted = false;
bool avxSupportted = false;
int cpuinfo[4];
__cpuidSpec(cpuinfo, 1);
// Check SSE, SSE2, SSE3, SSSE3, SSE4.1, and SSE4.2 support
sseSupportted = cpuinfo[3] & (1 << 25) || false;
sse2Supportted = cpuinfo[3] & (1 << 26) || false;
sse3Supportted = cpuinfo[2] & (1 << 0) || false;
ssse3Supportted = cpuinfo[2] & (1 << 9) || false;
sse4_1Supportted = cpuinfo[2] & (1 << 19) || false;
sse4_2Supportted = cpuinfo[2] & (1 << 20) || false;
avxSupportted = cpuinfo[2] & (1 << 28) || false;
bool osxsaveSupported = cpuinfo[2] & (1 << 27) || false;
if (osxsaveSupported && avxSupportted)
{
// _XCR_XFEATURE_ENABLED_MASK = 0
unsigned long long xcrFeatureMask = _xgetbvSpec(0);
avxSupportted = (xcrFeatureMask & 0x6) == 0x6;
}
// ----------------------------------------------------------------------
// Check SSE4a and SSE5 support
// Get the number of valid extended IDs
__cpuidSpec(cpuinfo, 0x80000000);
int numExtendedIds = cpuinfo[0];
if (numExtendedIds >= 0x80000001)
{
__cpuidSpec(cpuinfo, 0x80000001);
sse4aSupportted = cpuinfo[2] & (1 << 6) || false;
sse5Supportted = cpuinfo[2] & (1 << 11) || false;
}
// ----------------------------------------------------------------------
std::boolalpha(std::cout);
std::cout << " Support SSE: " << sseSupportted << std::endl;
std::cout << " Support SSE2: " << sse2Supportted << std::endl;
std::cout << " Support SSE3: " << sse3Supportted << std::endl;
std::cout << "Support SSE4.1: " << sse4_1Supportted << std::endl;
std::cout << "Support SSE4.2: " << sse4_2Supportted << std::endl;
std::cout << " Support SSE4a: " << sse4aSupportted << std::endl;
std::cout << " Support SSE5: " << sse5Supportted << std::endl;
std::cout << " Support AVX: " << avxSupportted << std::endl;
}
}