前言
利用多线程一般来说都是有 一定的大数据需求。
比如一个函数可能被不断的调用很多次
一般来说我们会使用for循环,但是为了节省时间,我们采用多线程的方式来解决这个问题
show you code
单参数输入
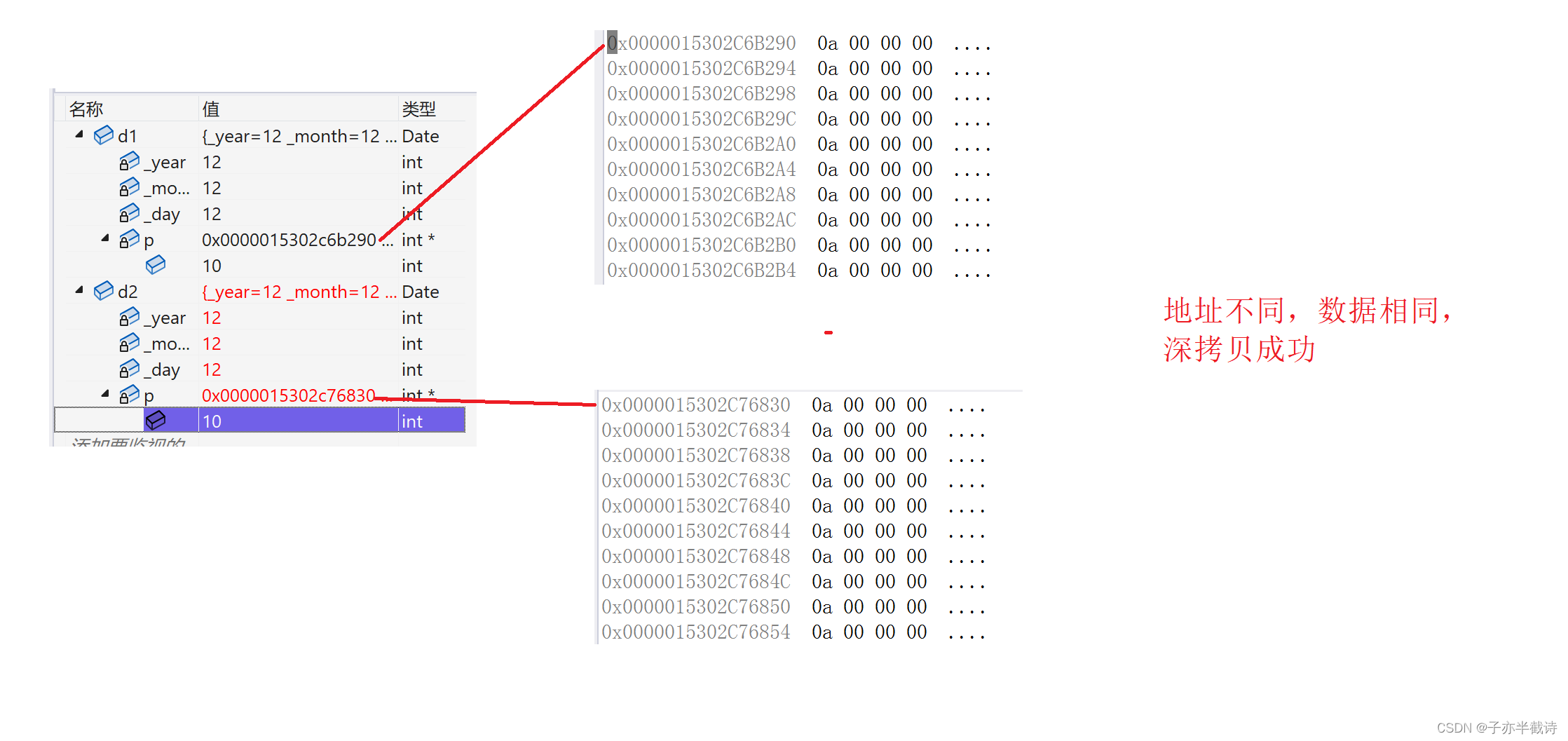
举了两个例子,一看便知 func为我们的函数 输入的参数为一个list,每一个元素对应于一个输入,每个输入并行
map 直接返回一个list
如果需要每个结果做不一样的结果操作,需要迭代器,那就用imap
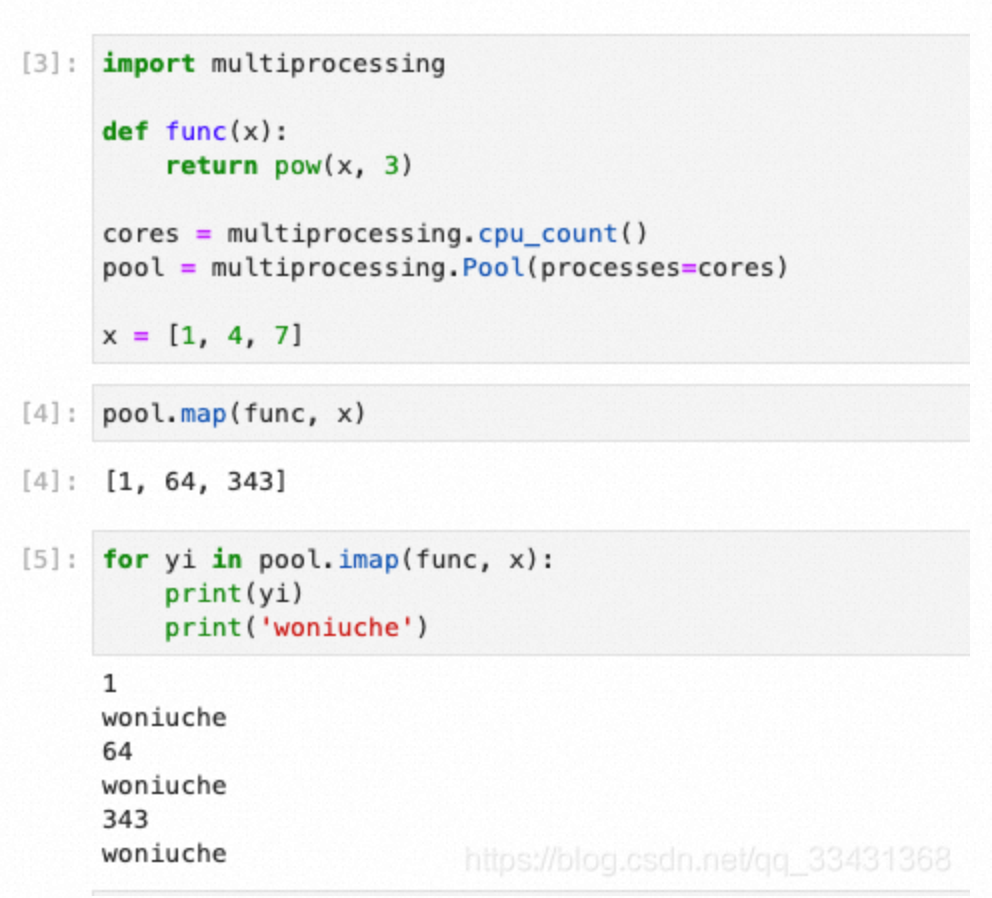
代码
import multiprocessing
def func(x):
return pow(x, 3)
cores = multiprocessing.cpu_count()
pool = multiprocessing.Pool(processes=cores)
x = [1, 4, 7]
print(pool.map(func, x))
for yi in pool.imap(func, x):
print(yi)
print('woniuche')
pool.close()
pool.join()多参数输入
这里用multiprocessing是不可行的 这里我们采用其他的包来实现 直接show code
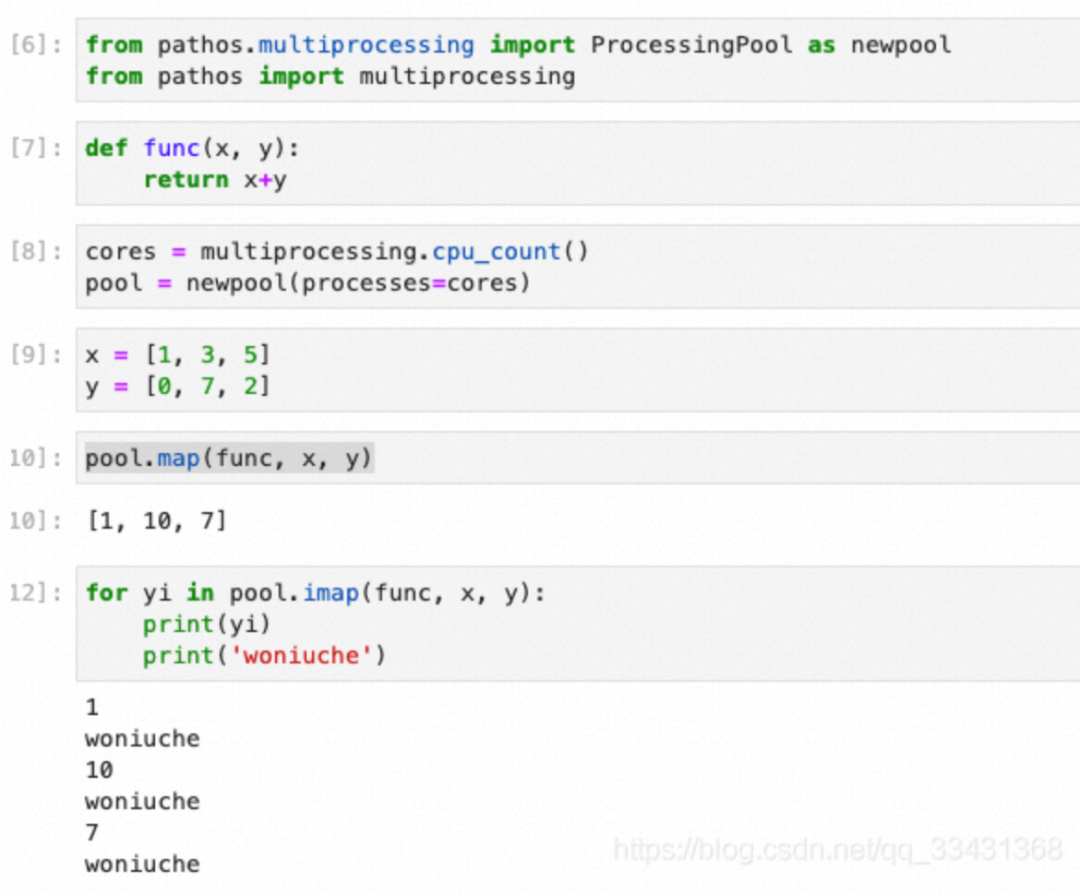
代码:
from pathos.multiprocessing import ProcessingPool as newpool
from pathos import multiprocessing
cores = multiprocessing.cpu_count()
pool = newpool(processes=cores)
def func(x, y):
return x+y
x = [1, 3, 5]
y = [0, 7, 2]
print(pool.map(func, x, y))
for yi in pool.imap(func, x, y):
print(yi)
print('woniuche')
pool.close()
pool.join()在类中使用的问题
会出现一些非序列化的问题,这里不太好举例,自己写的代码也不好公开,所以这边先留个坑,直接写可能出现问题和解决方案
问题
python多线程报错:AttributeError: Can't pickle local object问题
not serializable 不可序列化等问题
具体解决方法
直接把这个函数放在class外面,所有的参数都用传递进来的形式
https://cloud.tencent.com/developer/article/1730760
参考:
https://zhuanlan.zhihu.com/p/24311810
https://www.jianshu.com/p/06c6b553053f
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书