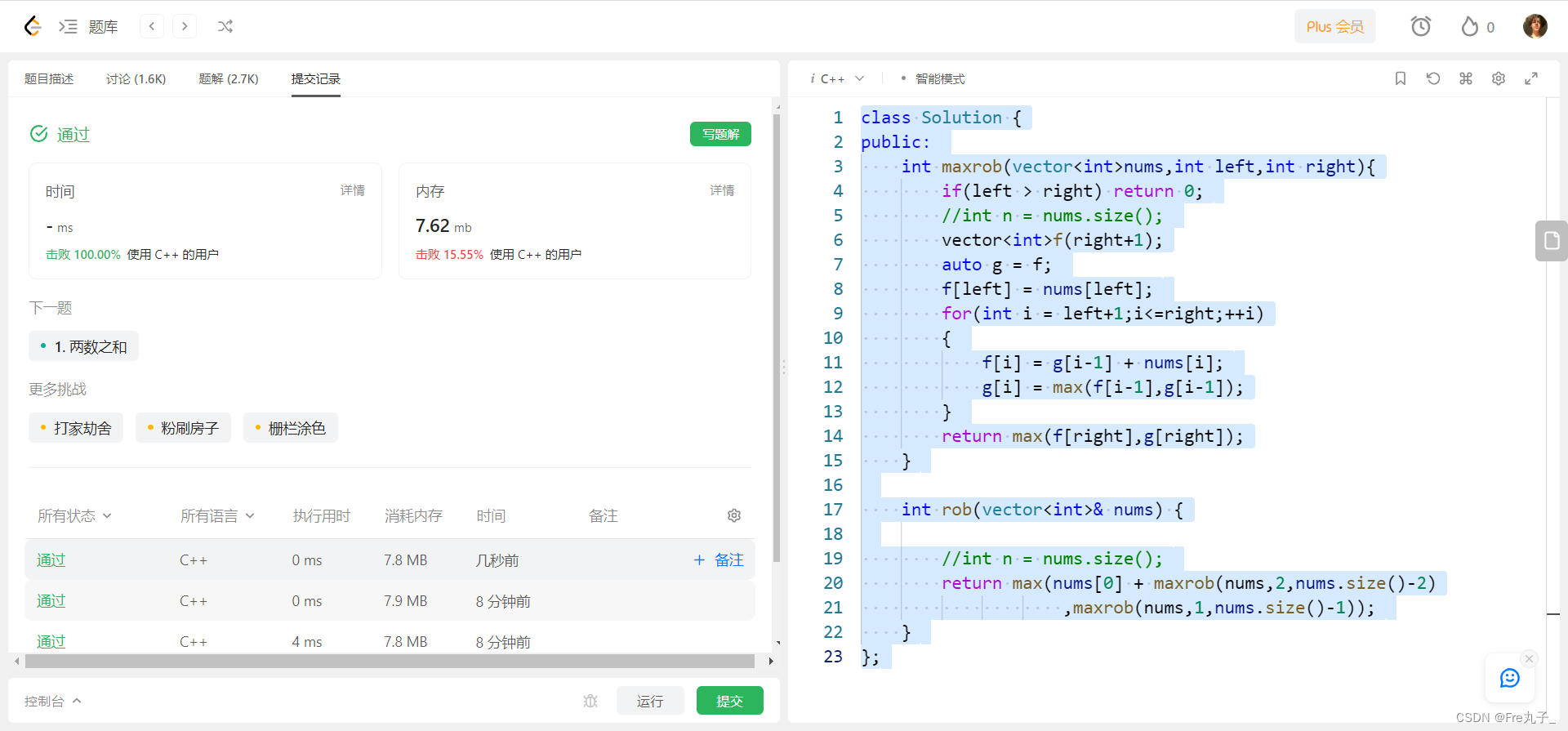
题目一
LRU算法的实现
做一个key-value结构 假如说这个LRU的大小为3 那么就是当KEY-value没满的时候 直接顺序加入 当满了的时候 把最长时间没有使用的key-value替换掉
要求实现一个put 和 get行为 时间复杂度均为O(1)
用双向链表+哈希表实现 哈希表可以用系统封装的双向链表要自己写 顺便练习一下泛型
双链表的优势是什么? 头部和尾部操作的时间复杂度为O(1) 但是查找很慢
所以我们结合hashmap 让他的查找的复杂度也变成O(1)
先看双链表
我们插入和弹出可以直接 用双链表实现 头部的是最可能被弹出的 尾部是最最近被使用的 还需要实现一个功能 把某一个节点放到尾部 代表这个点刚刚被使用过了 但是查找这个点是哪个点这个行为要交给哈希表
class Node<K,V>{
K key;
V value;
Node<K,V> last;
Node<K,V> next;
public Node(K k,V v) {
key = k;
value = v;
}
}
class NodeDoubleLinkedList<K , V>{//头部的是最可能被弹出的 尾部是最最近被使用的
Node<K,V> headNode;
Node<K,V> tailNode;
public NodeDoubleLinkedList() {
headNode = null;
tailNode = null;
}
public void addNode(Node<K,V> node) {
if (node == null) {
return;
}
// newNode != null
if (headNode == null) { // 双向链表中一个节点也没有
headNode = node;
tailNode = node;
} else { // 双向链表中之前有节点,tail(非null)
tailNode.last = node;
node.last = tailNode;
tailNode = node;//要连两条线呢
}
}
public Node<K,V> remove() {//后面需要用到这个弹出的值
if (headNode == null) {
return null;
}
Node<K, V> res = headNode;
if (headNode == tailNode) { // 链表中只有一个节点的时候
headNode = null;
tailNode = null;
} else {
headNode = res.next;
res.next = null;
headNode.last = null;
}
return res;
}
public void movetotail(Node<K,V> cur) {
if(cur==tailNode) {
return;
}
if (headNode == cur) { // 当前node是老头部
headNode = cur.next;
headNode.last = null;
} else { // 当前node是中间的一个节点
cur.last.next = cur.next;
cur.next.last = cur.last;
}
cur.last = tailNode;
cur.next = null;
tailNode.next = cur;
tailNode = cur;//后面的这部分调整是一致的 就是已经把指向这个点的部分都解决了 只剩这个点本身向外指的部分了 剩下的工序就像是已经把这个点剥离下来了 把这个点安置好
}
class MyCache<K, V> {
private HashMap<K, Node<K, V>> keyNodeMap;//map的key 是为了用key就能找到这个点 其实本质上这个map只需要存k和v就可以 但是为了双链表的便捷 还是封装成了node
private NodeDoubleLinkedList<K, V> nodeList;
private final int capacity;
public MyCache(int cap) {
if (cap < 1) {
throw new RuntimeException("should be more than 0.");
}
keyNodeMap = new HashMap<K, Node<K, V>>();
nodeList = new NodeDoubleLinkedList<K, V>();
capacity = cap;
}
public void set(K key,V value) {
if (keyNodeMap.containsKey(key)) {//如果包含 就把它的值给改了 然后诺到尾部 就行了
Node<K, V> node = keyNodeMap.get(key);
node.value = value;//map和双链表里面封装的都是node 的好处来了 只改一个就可以
nodeList.movetotail(node);
}else {//就要考虑满不满的问题了
if (keyNodeMap.size() == capacity) {
removeMostUnusedCache();
}
Node<K, V> newNode = new Node<K, V>(key, value);
keyNodeMap.put(key, newNode);
nodeList.addNode(newNode);
}
}
public V get(K key) {
if (keyNodeMap.containsKey(key)) {
Node<K, V> res = keyNodeMap.get(key);
nodeList.movetotail(res);
return res.value;
}
return null;
}
public void removeMostUnusedCache() {
Node<K,V> node = nodeList.remove();
keyNodeMap.remove(node.key);
}
}题目二
一个数组的异或和是指数组中所有的数异或在一起的结果给定一个数组arr, 求最大子数组异或和。
这题用动态规划不好解 不知道哪个位置是最大的
用常见数组累加和也不好解 没有单调性
最暴力的解法 那就是枚举每一个子数组
有一个优化方法 就是预处理数组tmp[i]是 0-i位置上的异或和 那么任何一个区间的异或和 都可以加工出来

然后再把所有的可能都加入前缀树 再贪心算法 对于每一条路径都要求尽可能大的话 就要前面的位置为1最好 对于符号位来说符号位0比较大(正数) 但是后面的部分是一样的 你看当负数的时候 负数的实际值应该是二进制取反+1 所以0越多 取反后的1越多 它的绝对值就越大 它的值就越小 所以我们希望还是1越多 它的值越大
如果直接把所有的可能都加入前缀树找最大值 那我为什么不把所有值都直接max抓一遍
它只把每一个预处理数组的值加入了 前缀树 然后 再在每一个预处理数组代表的区间求一个最大值不要忘记全0的时候(一个都不异或)
以0位置结尾的 以1位置结尾的 balabala
我先在前缀树中放了一个tmp[0]的 那确实只有一个值 我再加一个tmp[1] 那我可选择的路径那就是
我异或tmp[0] 看看单独1位置的值会不会比它大 然后把tmp[1]加入路径 错误的 在这之前我们要把全0放进去 逻辑就对了
先把全0放进去 然后tmp[0]放进去 也就是比较了一个不要 和要(0)的情况 再把tmp[1]放进去 就比较了 要(1)的情况 要(0,1)的情况(这是0^arr[0]^arr[1]) 再把tmp[2]放进去 这就对比了(0,1,2) (0) (0,1)....
那我有多种选择的时候 会不会为了最优解 这边走一个那边走一个 会不会走了两个数的二进制位
不会 因为有cur 即使会走上一条复用的路 这条路本身也只是一个数的二进制路径 而且这个best最后被修正成了实际走的路径
直接展示连招
class Node{
Node [] nexts = new Node[2];
}
class mypretree{
Node head = new Node();//之前没初始化 mad
public void add(int n) {
Node cur = head;
for(int move = 31;move>=0;move--) {
int v = (n>>move)&1;
if(cur.nexts[v] == null) {
cur.nexts[v] = new Node();
}
cur = cur.nexts[v];
}
}
public int getmax(int num) {
Node cur = head;
int res = 0;
for(int move = 31;move>=0;move--) {
int v = (num>>move)&1;
int best = move==31?v:v^1;//最好的情况 v为本身的时候就是 0 v ^v = 0 v^1 ^v = 1
best = cur.nexts[best]!=null?best:best^1;//不用担心走到空上面 我们分析一下 当best存在时 直接走best best不存在时 那就是存在不best的路 反正肯定至少会有一条路让你走的
res |= ((v^best)<<move);//v异或best 才是结果
cur = cur.nexts[best];
}
return res;
}
}
public class func {
public static int MAXEOR(int [] arr) {
if (arr == null || arr.length == 0) {
return 0;
}
int eor = 0;
int max = Integer.MIN_VALUE;
mypretree tree = new mypretree();
tree.add(0);
for(int i = 0;i<arr.length;i++) {
eor = eor^arr[i];
max = Math.max(max, tree.getmax(eor));
tree.add(eor);//这个顺序蛮诡异哈 先计算最大值 再加入eor 仔细想想其实是这么回事 直接getmax已经算了以i位置结尾的所有可能性了 add是为了下一步准备的
}
return max;
}