前言
对这次比赛中遇到的问题和卡住的思路进行复盘,整理相关心得,供以后比赛参考
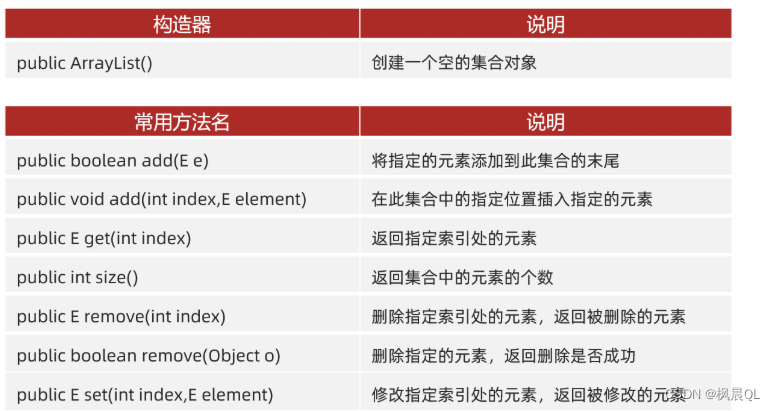
🧡1.认识数据类型🧡
连续变量:母亲年龄、妊娠时间、CBTS、EPDS、HADS、整晚睡醒时间、婴儿年龄
无序分类变量:婚姻状态、分娩反方式、婴儿行为特征、婴儿性别、入睡方式
有序分类变量:教育程度
🧡2.异常值处理🧡
2.1 excel筛选瞪眼法
对于分类种类少的分类变量,可直接excel筛选,
如婚姻状态(题目要求只有1,2两种)、分娩方式、教育程度、婴儿性别、入睡方式、婴儿行为特征等等

2.2 画正态直方图
可对分类变量(种类多)和连续变量,直观看出
如妊娠时间
可用spsspro(👇)或者spss(“分析-频率” 菜单)画
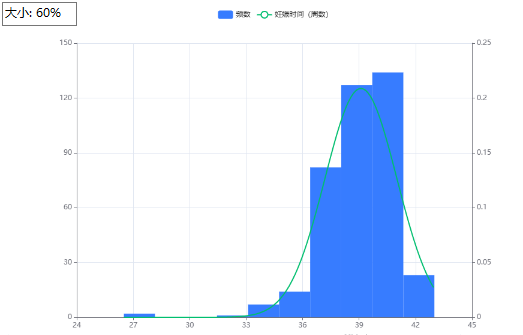
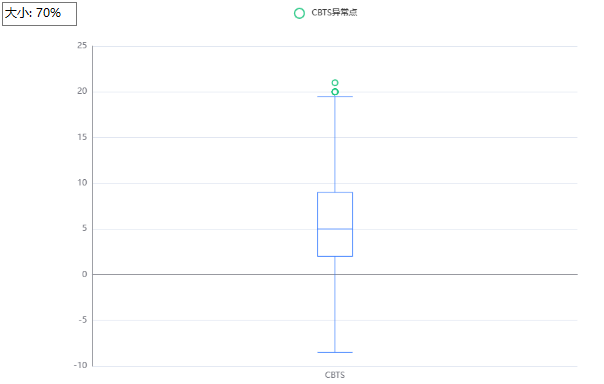
2.3 画箱型图
- 2.3.1使用spsspro👇
- 2.3.2使用spss👇(“分析-探索” 菜单)
spss软件的箱型图可以给出异常值所在索引
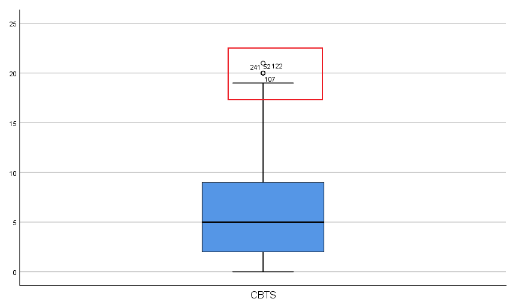
- 2.3.3使用python代码
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 获取 CBTS、EPDS 和 HADS 列的数据
cbts_data = df['CBTS']
epds_data = df['EPDS']
hads_data = df['HADS']
# 创建子图
fig, ax = plt.subplots()
# 设置每个箱型图的位置和数据
positions = [1, 2, 3]
boxplot_cbts = ax.boxplot(cbts_data, positions=[positions[0]], patch_artist=True, widths=0.5, boxprops=dict(facecolor='salmon')) # 也可用十六进制#fff表示
boxplot_epds = ax.boxplot(epds_data, positions=[positions[1]], patch_artist=True, widths=0.5, boxprops=dict(facecolor='skyblue'))
boxplot_hads = ax.boxplot(hads_data, positions=[positions[2]], patch_artist=True, widths=0.5, boxprops=dict(facecolor='limegreen'))
# 设置 x 轴标签和范围
ax.set_xticks(positions)
ax.set_xticklabels(['CBTS', 'EPDS', 'HADS'])
ax.set_xlim(0, 4)
# 显示图像
plt.show()
# 计算上边缘并找到离群点
data=[cbts_data,epds_data,hads_data]
outliers = []
for i, data_col in enumerate(data):
iqr = np.percentile(data_col, 75) - np.percentile(data_col, 25) # 75%分位数 - 25%分位数
upper_bound = np.percentile(data_col, 75) + 1.5 * iqr # 上边缘
outliers_col = data_col[data_col > upper_bound] # 根据上边缘确定离群点
outliers.extend(outliers_col.index + 1) # 保存离群点所在样本的索引
print("属性 {} 的离群点样本索引:{}".format(ax.get_xticks()[i], outliers_col.index + 1))
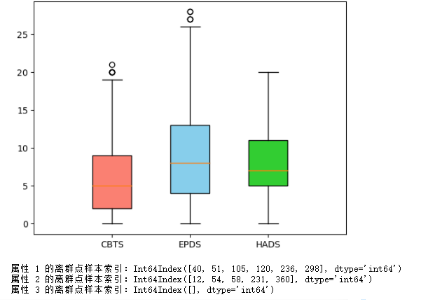
🧡3.数据处理🧡
3.1 分类数据 中文=>数字
toClassNum_map={'安静型': 1, '中等型': 2, '矛盾型': 3}
df['婴儿行为特征'] = df['婴儿行为特征'].map(toClassNum_map)
3.2 分类数据 转 独热编码
select_columns=['婚姻状况','教育程度','分娩方式','入睡方式']
df=pd.read_excel('oridata/附件.xlsx',usecols=select_columns)
one_hot_encoder = OneHotEncoder(sparse=False)
one_hot_data = one_hot_encoder.fit_transform(df)
one_hot_df = pd.DataFrame(one_hot_data, columns=one_hot_encoder.get_feature_names_out(select_columns))
print(one_hot_df)
one_hot_df.to_excel('out/onehot.xlsx', index=False)
3.3 时间转换
例如10:30:00 转成 10.5
# 时间处理
def time_process(time):
time=str(time)
hours, minutes, seconds = time.split(":")
hours=int(hours)
minutes=int(minutes)
seconds=int(seconds)
return hours+minutes/60+seconds/3600
df['整晚睡眠时间(时:分:秒)']=df['整晚睡眠时间(时:分:秒)'].apply(time_process)
🧡4.相关性分析🧡
题目中要求对母亲身体指标(年龄、教育程度、婚姻状况、妊娠时间、分娩方式)和心理指标(CBTS、EPDS、HADS)对婴儿行为特征进行相关性分析。
从数据类型分析:
- 婴儿行为特征可认为是无序分类变量
- 年龄、妊娠时间、心理指标(CBTS、EPDS、HADS)可认为是连续变量
- 婚姻状况、分娩方式可认为是无序分类变量
- 教育程度可认为是有序分类变量
因此👇👇👇
- 可将 年龄、妊娠时间、心理指标(CBTS、EPDS、HADS)与婴儿行为特征进行方差分析
- 可将与婚姻状况、分娩方式与婴儿行为特征进行卡方检验
- 可将教育程度*与婴儿行为特征**进行Mantel-Haenszel卡方检验
参考链接👉👉👉相关性分析
(或者去spsspro分析那里,看数据说明)
🧡5.K-prototpyes聚类🧡
适用于自变量中同时含有连续变量和分类变量的情况
import numpy as np
import pandas as pd
from kmodes.kprototypes import KPrototypes
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
from sklearn import preprocessing
#设置字体为楷体
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']
#数据预处理
data=pd.read_excel(r'oridata/问题1.xlsx')
data_num = data[['整晚睡眠时间','睡醒次数']]
data_cat = data['入睡方式']
data_num = data_num.apply(lambda x: (x - x.mean()) / np.std(x)) #数值型变量做标准化处理,类别型变量如果不是数值,需要先做LabelEncode
df3=pd.concat([data_num, data_cat], axis=1)
#模型训练不同的类别数对应的SSE及模型
def TrainCluster(df, model_name=None, start_k=2, end_k=20):
print('training cluster')
#df = StandardScaler().fit_transform(df) #数据标准化
K = []
SSE = []
silhouette_all=[]
models = [] #保存每次的模型
for i in range(start_k, end_k):
kproto_model = KPrototypes(n_clusters=i)
kproto_model.fit(df,categorical=[2])
SSE.append(kproto_model.cost_) # 保存每一个k值的SSE值
K.append(i)
print('{}-prototypes SSE loss = {}'.format(i, kproto_model.cost_))
return(K,SSE)
#用肘部法则来确定最佳的K值
train_cluster_res = TrainCluster(df3, model_name=None, start_k=2, end_k=20 )
K = train_cluster_res[0]
SSE = train_cluster_res[1]
plt.figure(dpi=300)
index = 2 # 要标记的点的索引
marker_x = K[index]
marker_y = SSE[index]
# 添加虚线
plt.axhline(y=marker_y, xmin=0, xmax=marker_x, linestyle='--', color='gray')
plt.axvline(x=marker_x, ymin=0, ymax=marker_y, linestyle='--', color='gray')
plt.plot(K, SSE, 'g-')
plt.plot(K, SSE, 'm*')
plt.xlabel('聚类类别数k')
plt.ylabel('SSE')
plt.xticks(K)
plt.title('用肘部法则来确定最佳的k值')
plt.show()
# 确定k后建立模型
kproto_model=KPrototypes(n_clusters=4,init='Cao',max_iter=300,n_init=15)
clusters=kproto_model.fit_predict(data.values,categorical=[2])
numeric_features = data[['整晚睡眠时间', '睡醒次数']].values
numeric_features
# Plot
from mpl_toolkits.mplot3d import Axes3D
# 绘制散点图,不同簇使用不同的颜色表示
fig = plt.figure(dpi=150)
ax = fig.add_subplot(111, projection='3d')
ax.scatter(data['整晚睡眠时间'], data['睡醒次数'], clusters, c=clusters)
ax.set_xlabel('整晚睡眠时间')
ax.set_ylabel('睡醒次数',labelpad=8)
ax.set_zlabel('入睡方式',labelpad=10)
plt.show()
data_out=pd.DataFrame(clusters,columns=['聚类结果'])
data_out.to_excel('out/聚类结果.xlsx',index=False)
🧡6.决策树🧡
6.1数据预处理
6.1.1导入
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier #分类树
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.tree import export_text
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['KaiTi'] # 设置字体为楷体
df=pd.read_excel('oridata/t4.xlsx')
X=df[['母亲年龄','CBTS','EPDS','HADS','教育程度']]
Y=df['睡眠质量等级']
#X=df[['母亲年龄','EPDS']]
6.1.2随机过采样
# 随机过采样方法
from imblearn.over_sampling import RandomOverSampler
from collections import Counter
ros = RandomOverSampler(random_state=0)
X_oversampled, Y_oversampled = ros.fit_resample(X, Y)
print('随机过采样处理后', Counter(Y_oversampled))
X=X_oversampled
Y=Y_oversampled
#df3=pd.concat([X, Y], axis=1)
#df3.to_excel('out/t2out_data.xlsx')
6.1.3查看离群点
#X=X.drop('母亲年龄',axis=1)
x=list(X['CBTS'])
y=list(X['EPDS'])
z=list(X['HADS'])
# 1.创建 3D 图形对象
fig = plt.figure(figsize=(18, 16))
ax = fig.add_subplot(111, projection='3d')
# 2.给每个点加上他们的坐标
for i in range(len(x)):
ax.text( x[i], y[i], z[i], f'({x[i]}, {y[i]}, {z[i]})')
# 3.绘制散点图
ax.scatter(x, y,z)
ax.set_xlabel('CBTS')
ax.set_ylabel('EPDS')
ax.set_zlabel('HADS')
plt.show()
len(z)
6.2调参过程
- 预剪枝:
- criterion:分裂准则:gini、entropy
- max_depth:树的最大深度
- splitter :特征划分标准,best在特征的所有划分点中找出最优的划分点,random随机的在部分划分点中找局部最优的划分点。默认的‘best’适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐‘random’。
- min_samples_split:一个节点最少需要多少样本才能分裂,如果
min_sample_split = 6并且节点中有4个样本,则不会发生拆分(不管熵是多少) - min_samples_leaf:一个节点最少需要多少样本才能成为叶子节点,假设
min_sample_leaf = 3并且一个含有5个样本的节点可以分别分裂成2个和3个大小的叶子节点,那么这个分裂就不会发生,因为最小的叶子大小为3 - class_weight:类别权重,【dict, list of dicts, balanced】,默认为None,指定样本各类别的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。balanced,算法自己计算权重,样本量少的类别所对应的样本权重会更高。如果样本类别分布没有明显的偏倚,则可以不管这个参数。
- 选择最优random
- 后剪枝:
- ccp_alpha:细讲sklearn决策树后剪枝(带例子),通过可视化图调整即可
6.2.1预剪枝
# 《《《《《《 调参1 》》》》》--预剪枝
# 用GridSearchCV寻找最优参数(字典)
param = {'criterion':['gini'],
'max_depth':np.arange(2,5),
'min_samples_leaf':list(range(2,10,2)),
'min_samples_split':list(range(2,10,2)),
}
grid = GridSearchCV(DecisionTreeClassifier(),param_grid=param,cv=6)
grid.fit(X_train,Y_train)
print('最优分类器:',grid.best_params_,'最优分数:', grid.best_score_) # 得到最优的参数和分值
6.2.2选择最优random
# 《《《《《《 调参2 》》》》》--randomm
maxAcu=-1
max_state=-1
for r in range(1,2023):
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size = 0.3,random_state = r)
model = DecisionTreeClassifier(criterion="gini",
random_state=r,
max_depth =4,
min_samples_leaf=2,
min_samples_split=2,
splitter="best",
) # 初始化模型
model.fit(X_train, Y_train)
Y_pred=model.predict(X_test)
if model.score(X_test,Y_test)>maxAcu:
maxAcu=model.score(X_test,Y_test)
max_state=r
print("max_test_acu:",maxAcu) # test_acu
print("max_state:",(max_state)) # max_state
# 用 目前最好的参数 建立模型
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size = 0.3,random_state = max_state)
model = DecisionTreeClassifier(criterion="gini",
max_depth =4,
random_state=360,
min_samples_leaf=6,
min_samples_split=3,
splitter="best",
) # 初始化模型
model.fit(X_train, Y_train) # 训练模型
[*zip(list(X.columns),model.feature_importances_)] # 计算每个特征的重要程度
6.2.3后剪枝
#-------后剪枝前:康康ccp路径------
pruning_path = model.cost_complexity_pruning_path(X_train, Y_train)
print("ccp_alphas:",pruning_path['ccp_alphas'])
print("impurities:",pruning_path['impurities'])
# 《《《《《《 调参3 》》》》》--后剪枝
# 《《《《《《 调参3 》》》》》--后剪枝
model = DecisionTreeClassifier(criterion="gini",
max_depth =4,
random_state=max_state,
min_samples_leaf=2,
min_samples_split=2,
splitter="best",
ccp_alpha=0.0098 #通过图形 来回调整这里
) # 初始化模型
model.fit(X_train, Y_train) # 训练模型
# 深拷贝,创建全新的副本,专门用于画图、评估模型,防止原模型受到影响(画图的库对原model会有影响,干脆直接分离开)
import copy
new_model_deep_plottree = copy.deepcopy(model)
new_model_deep_dtreeviz = copy.deepcopy(model)
new_model_deep_eva = copy.deepcopy(model)
print("train_acu:",model.score(X_train,Y_train))# train_acu
print("test_acu:",model.score(X_test,Y_test)) # test_acu
# 《《《plot画图》》》 ---可视化特征属性结果
r = export_text(new_model_shallow_plottree, feature_names= list(X.columns))
print(r)
plt.figure(figsize=(30,10), facecolor ='w') # facecolor设置背景色
a = tree.plot_tree(new_model_deep_plottree,
feature_names = list(X.columns),
class_names = ['安静型','中等型','矛盾型'],
# label='all',
rounded = True,
filled = True,
fontsize=14,
)
plt.savefig("save1_ccp00056.png", dpi=300)
plt.show()
附:用graphviz画图也可以(效果同上)
# 《《《graphviz画图》》》 ---可视化特征属性结果
from sklearn import tree
from IPython.display import Image
import graphviz
import pydotplus
dot_data = tree.export_graphviz(new_model_shallow_plottree, out_file=None,
feature_names=list(X.columns),
class_names = ['良','中','优','差'],
filled=True,
rounded=True,
special_characters=True,
fontname='FangSong')
dot_data=dot_data.replace('\n','') # 防止出现黑框
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("DTtree.pdf") ## 保存出pdf
Image(graph.create_png()) # 展示在ipy中
附:window中文字体对应的英文

6.2.4用dtreeviz包画更好看的分叉图
# 《《《dtreeviz》》》 ---可视化特征属性结果
from dtreeviz.trees import *
from sklearn import tree
import dtreeviz
viz = dtreeviz.model(new_model_deep_dtreeviz,
X_train=X_train,
y_train=Y_train,
target_name='婴儿行为特征',
feature_names = list(X.columns),
class_names = ['安静型','中等型','矛盾型'],
)
v=viz.view()
v.show()
v.save("sel_tree.svg") # optionally save as svg
6.3评估
6.3.1ROC
一文详解ROC曲线和AUC值 - 知乎 (zhihu.com)
## ----评估-----ROC、AUC
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize
# 1.预测概率
probabilities = new_model_deep_eva.predict_proba(X_test) # 返回[预测为0的概率,预测为1的概率,预测为2的概率,预测为3的概率]
#print(probabilities)
# 2.将标签进行二值化处理
y_test_bin = label_binarize(Y_test, classes=np.unique(Y)) # 1列转4列:独热编码
#print(y_test_bin)
# 3.计算每个类别的ROC曲线和AUC值
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(len(np.unique(Y))):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], probabilities[:, i])
print(y_test_bin[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# 4.绘制每个类别的ROC曲线
plt.figure()
colors = ['blue', 'green', 'red', 'cyan', 'magenta'] # 设置各个线条颜色
for i, color in zip(range(len(np.unique(Y))), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2, label='ROC Curve (Class %d, AUC = %0.2f)' % (i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'r--') # 绘制对角线
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc="lower right")
plt.show()
6.3.2F1、召回率、精确率
# ----评估-----F1、精确率、召回率
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score
precision = precision_score(Y_test, Y_pred,average='micro')
recall = recall_score(Y_test, Y_pred,average='micro')
f1 = f1_score(Y_test, Y_pred,average='micro')
print('精确率=',precision)
print('召回率=',recall)
print('F1=',f1)
6.3.3混淆矩阵
# ----评估-----混淆矩阵
cfu_matrix=confusion_matrix(Y_test, Y_pred)
plt.figure(figsize=(50, 16), dpi=600) # 设置画布的大小和dpi,为了使图片更加清晰
plt.matshow(cfu_matrix, cmap='GnBu') # 按自己需求更改颜色
plt.colorbar()
for i in range(len(cfu_matrix)):
for j in range(len(cfu_matrix)):
plt.annotate(cfu_matrix[j, i], xy=(i, j), horizontalalignment='center', verticalalignment='center',fontsize=13)
# 绘图格式
plt.tick_params(labelsize=12) # 设置左边和上面的label类别如0,1,2,3,4的字体大小。
plt.ylabel('真实值', fontdict={ 'size': 15}) # 设置字体大小。
plt.xlabel('预测值', fontdict={ 'size': 15})
plt.xticks(range(0,3), labels=['安静型','中等型','矛盾型']) # 将x轴或y轴坐标,刻度 替换为文字
plt.yticks(range(0,3), labels=['安静型','中等型','矛盾型'])
plt.savefig('cm.jpg')
plt.show()
6.4预测结果
data_willpred=pd.read_excel('oridata/t4_willPred.xlsx')
data_willpred=data_willpred[['母亲年龄','CBTS','EPDS','HADS','教育程度']]
ans=model.predict(data_willpred)
# 字典,用于将数值型数据转换为字符串数据
mapping_dict = {0: '良', 1: '中', 2: '优', 3: '差'}
# 将数值型数据转换为字符串数据
str_data_list = [mapping_dict[value] for value in ans]
print(str_data_list)
暂时想到这么多,如有错漏或不一样的见解,请不吝赐教。