VGG16模型详解
0、VGG16介绍
VGG16是一种深度卷积神经网络,由牛津大学的研究团队于2014年开发。
VGG16在2014年的ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 竞赛中取得了显著的成绩。它在图像分类任务中获得了当年的第二名,其准确率超过了之前的深度神经网络模型,并为后来的研究提供了重要的启示。
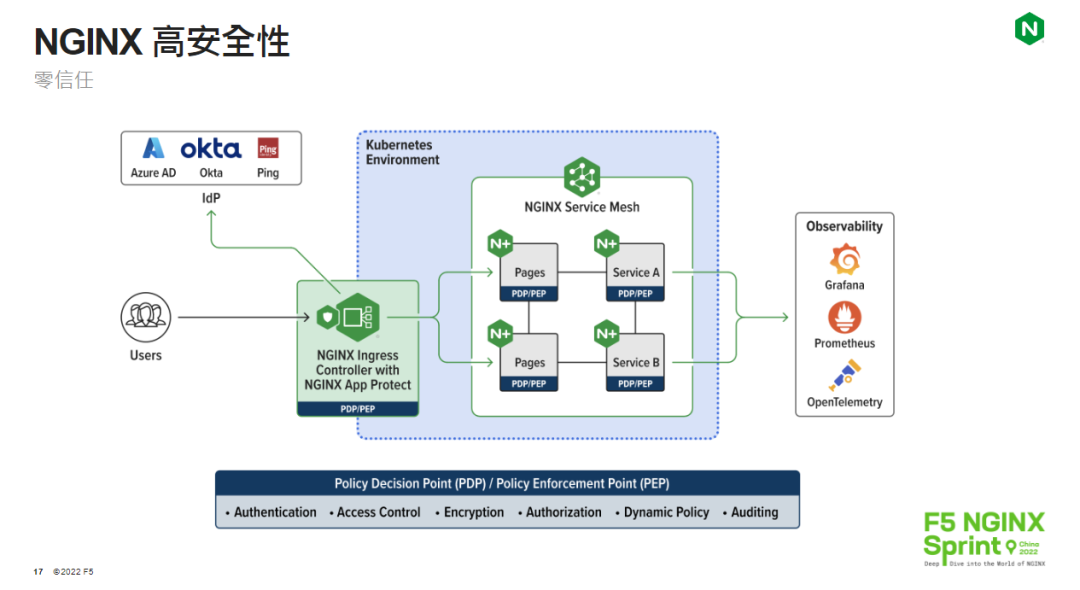
1、网络模型结构
这张图来源于论文《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》,其中的D、E就表示的是VGG16和VGG19。
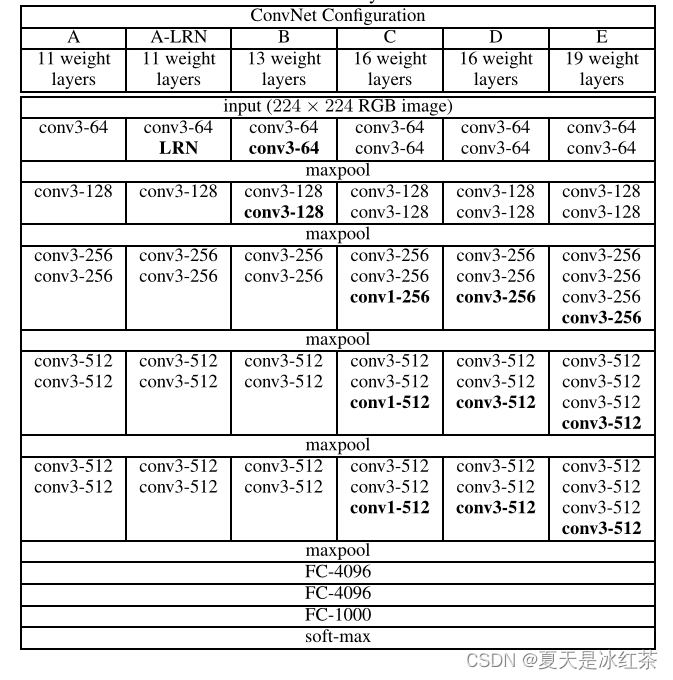
parameters:
- input(224x224 RGB image):输入尺寸为224x224的RGB彩色图片。
- conv3-64:前一个数字表示卷积核的大小,后一个数字表示卷积核的数量。其它的也如此。
- maxpool:最大池化,有助于提取主要特征、降低维度、增加不变性。
- FC-4096-1:全连接(Fully Connected)层,具体指的是包含4096个神经元的全连接层。将来自卷积和池化层的特征映射进行扁平化,然后与权重矩阵相乘并加上偏置,产生一组4096维的输出。
- FC-4096-2:这是VGG16网络的第二个全连接层,同样具有4096个神经元。它接收来自第一个全连接层的4096维输出作为输入,然后进行相同的矩阵相乘和偏置操作,得到最终的特征表示。
- FC-1000:最后一个全连接层是FC-1000,它有1000个神经元,对应于ImageNet数据集中的1000个类别(即网络被训练用于ImageNet图像分类任务)。这一层的输出经过softmax激活函数后,表示图像属于每个类别的概率分布,从而实现了分类功能。
2、VGG16的卷积核特点
VGG网络的卷积层全部采用的是3x3卷积核,这个设计是VGG16网络的一个显著特点。一个3x3卷积核包含了一个像素的上下左右的最小单元。连续多层的3x3卷积核可以拟合更复杂的特征,同时增加网络深度。
两个3x3卷积可以替代一个5x5卷积,三个3x3卷积可以替代一个7x7卷积。这样多个小卷积核的卷积层替代一个卷积核较大的卷积层,一方面参数数量减少了,另一方面非线性次数也变多了,学习能力变得更好,网络的表达能力也提升了。
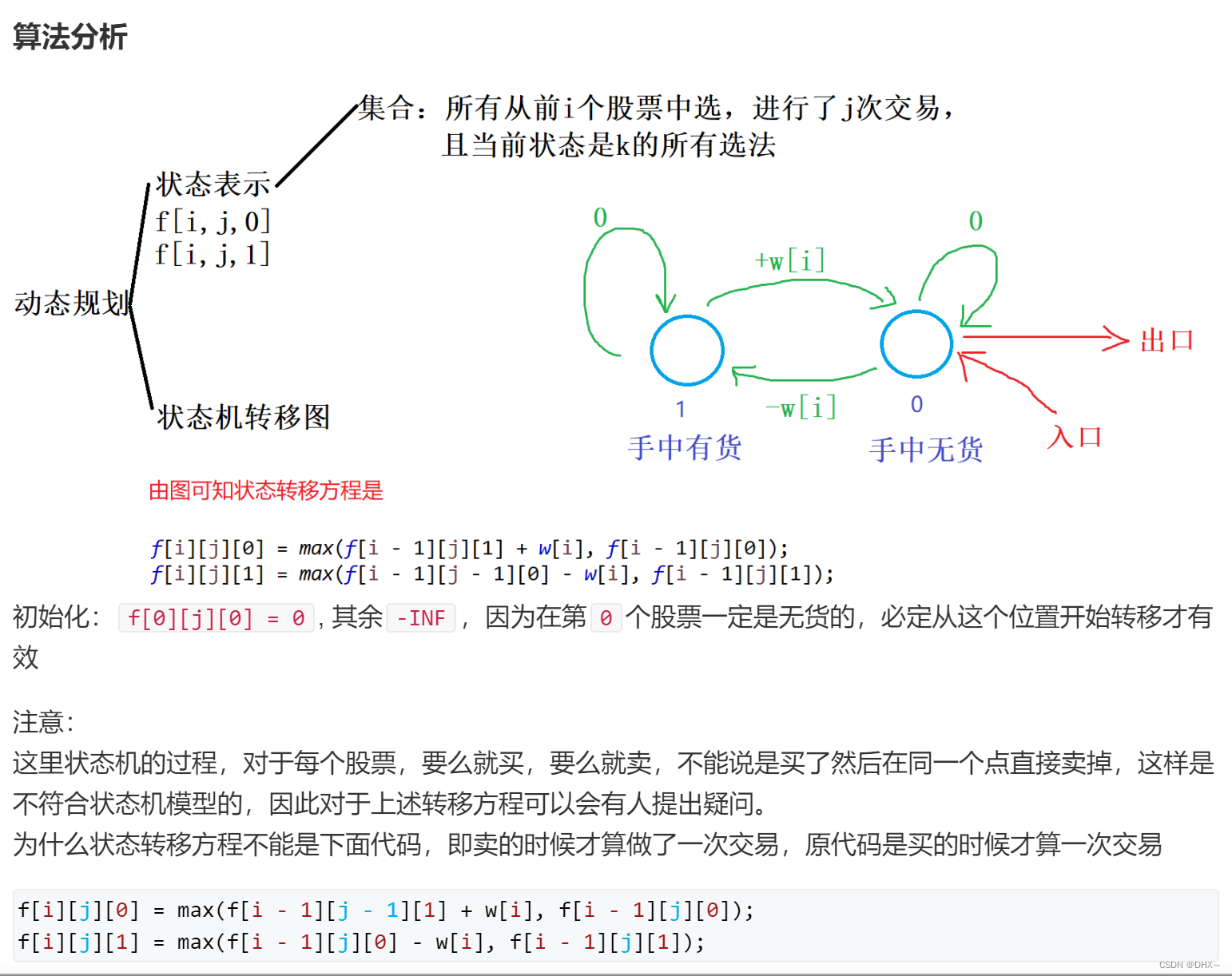
3、网络卷积过程

图片来源于同济子豪兄的视频。
- 输入尺寸为224x224x3的RGB图像,经过block1,步长为1,padding=1的填充。经过两个卷积层后,再经过ReLU函数激活,尺寸不变,通道数为64。尺寸变为224x224x64。
- 每经过maxpool,滤波器大小为2x2,步长为2,尺寸减半。尺寸变为112x112x64。
- 经过block2,两次卷积,ReLU激活。尺寸变为112x112x128。
- maxpool池化,尺寸变为56x56x128。
- 经过block3,三次卷积,ReLU激活。尺寸变为56x56x256。
- maxpool池化,尺寸变为28x28x256。
- 经过block4,三次卷积,ReLU激活。尺寸变为28x28x512。
- maxpool池化,尺寸变为14x14x512。
- 经过block5,三次卷积,ReLU激活。尺寸变为14x14x512。
- maxpool池化,尺寸变为7x7x512。
- 然后Flatten(),变成一维512*7*7=25088。
- 经过两层1x1x4096,一层1x1x1000的全连接层(共三层),经ReLU激活。
- 最后通过softmax输出1000个预测结果。
4、查看Pytorch内置的VGG16模型
import torch
import torchvision
import torch.nn as nn
import torchsummary
# pytorch内置的VGG16的模型
model = torchvision.models.vgg16()
print(model)控制台部分内容:

5、内置模型的参数量
import torch
import torchvision
import torch.nn as nn
import torchsummary
model = torchvision.models.vgg16()
torchsummary.summary(model,input_size=(3,244,244),batch_size=2,device='cpu')控制台部分内容:
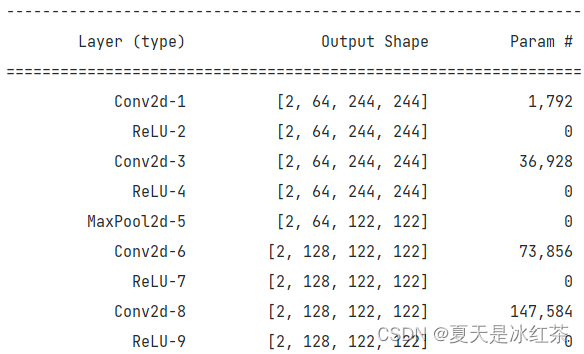
部分参数量
Total params: 138,357,544
总的参数量达到了1.38亿。VGG16具有如此之大的参数数目,可以预期它具有很高的拟合能力,但同时缺点也很明显,即训练时间过长,调参难度大。需要的存储容量大,不利于部署。
6、使用Pytorch实现VGG16
class VGG16(nn.Module):
"""
每个卷积核大小都是3x3,后面步长为1,padding=1
每个卷积后面都用了ReLU
"""
def __init__(self,in_channel=3,out_channel=1000,num_hidden=512*7*7):
super(VGG16,self).__init__()
self.features=nn.Sequential(
# block1
nn.Conv2d(in_channel,64,(3,3),(1,1),1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2,2),
# block2
nn.Conv2d(64, 128, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
# block3
nn.Conv2d(128, 256, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
# block4
nn.Conv2d(256, 512, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
# block5
nn.Conv2d(512, 512, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, (3, 3), (1, 1), 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2),
)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7,7))
self.classifier = nn.Sequential(
nn.Linear(num_hidden, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(),
nn.Linear(4096, out_channel),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x上面均为仿照Pytorch内置的VGG16模型的参数编写的。
7、总结
VGG16作为深度学习发展历程中的重要里程碑,强调了通过增加网络深度和一致性设计来提取图像特征。它的成功启发了后续更复杂的网络架构和方法,并在图像分类等任务中取得了重要成就。通过研究和实践,我们可以更好地理解VGG16的原理,并将其应用于实际问题中。