Linux 文件系统
磁盘和文件系统的关系:
-
磁盘为系统提供了最基本的持久化存储。
-
文件系统则在磁盘的基础上,提供了一个用来管理文件的树状结构。
文件系统工作原理
索引节点和目录项
文件系统,本身是对存储设备上的文件,进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
为了方便管理,Linux 文件系统为每个文件都分配两个数据结构,索引节点(index node)和目录项(directory entry)。它们主要用来记录文件的元信息和目录结构。
-
索引节点,简称为 inode,用来记录文件的元数据,比如 inode 编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
-
目录项,简称为 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
换句话说,索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
举个例子,通过硬链接为文件创建的别名,就会对应不同的目录项,不过这些目录项本质上还是链接同一个文件,所以,它们的索引节点相同。
磁盘读写的最小单位是扇区,然而扇区只有 512B 大小,如果每次都读写这么小的单位,效率一定很低。所以,文件系统又把连续的扇区组成了逻辑块,然后每次都以逻辑块为最小单元,来管理数据。常见的逻辑块大小为 4KB,也就是由连续的 8 个扇区组成。
目录项、索引节点、文件数据的关系如下:

-
第一,目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。为了协调慢速磁盘与快速 CPU 的性能差异,文件内容会缓存到页缓存 Cache 中,索引节点也会缓存到内存中,加速文件的访问。
-
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中:
(1)超级块,存储整个文件系统的状态
(2)索引节点区,用来存储索引节点
(3)数据块区,则用来存储文件数据
虚拟文件系统
为了支持各种不同的文件系统,Linux 内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统 VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
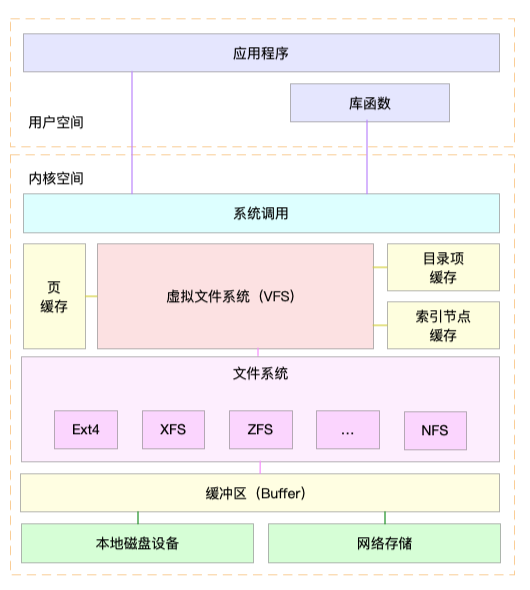
如图在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
-
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
-
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
-
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
文件系统 I/O
把文件系统挂载到挂载点后,你就能通过挂载点,再去访问它管理的文件了。VFS 提供了一组标准的文件访问接口。这些接口以系统调用的方式,提供给应用程序使用。
文件读写方式的各种差异,导致 I/O 的分类多种多样。最常见的有以下几种。
缓冲与非缓冲 I/O
-
缓冲 I/O,是指利用标准库缓存来加速文件的访问,而标准库内部再通过系统调度访问文件。
-
非缓冲 I/O,是指直接通过系统调用来访问文件,不再经过标准库缓存。
无论缓冲 I/O 还是非缓冲 I/O,它们最终还是要经过系统调用来访问文件。系统调用后,还会通过页缓存,来减少磁盘的 I/O 操作。
直接与非直接 I/O
-
直接 I/O,是指跳过操作系统的页缓存,直接跟文件系统交互来访问文件。
-
非直接 I/O 正好相反,文件读写时,先要经过系统的页缓存,然后再由内核或额外的系统调用,真正写入磁盘。
想要实现直接 I/O,需要你在系统调用中,指定 O_DIRECT 标志。如果没有设置过,默认的是非直接 I/O。不过要注意,直接 I/O、非直接 I/O,本质上还是和文件系统交互。如果是在数据库等场景中,你还会看到,跳过文件系统读写磁盘的情况,也就是我们通常所说的裸 I/O。
阻塞与非阻塞 I/O
-
阻塞 I/O,是指应用程序执行 I/O 操作后,如果没有获得响应,就会阻塞当前线程,自然就不能执行其他任务。
-
非阻塞 I/O,是指应用程序执行 I/O 操作后,不会阻塞当前的线程,可以继续执行其他的任务,随后再通过轮询或者事件通知的形式,获取调用的结果。
比方说,访问管道或者网络套接字时,设置 O_NONBLOCK 标志,就表示用非阻塞方式访问;而如果不做任何设置,默认的就是阻塞访问。
同步与异步 I/O
-
同步 I/O,是指应用程序执行 I/O 操作后,要一直等到整个 I/O 完成后,才能获得 I/O 响应。
-
异步 I/O,是指应用程序执行 I/O 操作后,不用等待完成和完成后的响应,而是继续执行就可以。等到这次 I/O 完成后,响应会用事件通知的方式,告诉应用程序。
比如,在访问管道或者网络套接字时,设置了 O_ASYNC 选项后,相应的 I/O 就是异步 I/O。这样,内核会再通过 SIGIO 或者 SIGPOLL,来通知进程文件是否可读写。
查看文件系统容量
文件系统和磁盘空间:
# -h表示有更好的可读性
df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 1.7G 0 1.7G 0% /dev
tmpfs 1.7G 24K 1.7G 1% /dev/shm
tmpfs 1.7G 8.4M 1.7G 1% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 1.7G 0 1.7G 0% /sys/fs/cgroup
/dev/vda1 50G 21G 27G 43% /
/dev/loop0 54M 54M 0 100% /snap/snapd/19361
/dev/loop2 45M 45M 0 100% /snap/certbot/3024
/dev/loop3 64M 64M 0 100% /snap/core20/1950
/dev/loop4 54M 54M 0 100% /snap/snapd/19457
/dev/loop5 64M 64M 0 100% /snap/core20/1974
tmpfs 344M 0 344M 0% /run/user/500也可以指定目录:
df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/vda1 50G 21G 27G 43% /索引节点的容量
# -h表示有更好的可读性, -i表示查看索引节点
df -hi
Filesystem Inodes IUsed IFree IUse% Mounted on
devtmpfs 427K 411 427K 1% /dev
tmpfs 430K 7 430K 1% /dev/shm
tmpfs 430K 2.5K 427K 1% /run
tmpfs 430K 5 430K 1% /run/lock
tmpfs 430K 18 430K 1% /sys/fs/cgroup
/dev/vda1 3.2M 307K 2.9M 10% /
/dev/loop0 658 658 0 100% /snap/snapd/19361
/dev/loop2 7.5K 7.5K 0 100% /snap/certbot/3024
/dev/loop3 12K 12K 0 100% /snap/core20/1950
/dev/loop4 658 658 0 100% /snap/snapd/19457
/dev/loop5 12K 12K 0 100% /snap/core20/1974
tmpfs 430K 18 430K 1% /run/user/500当发现索引节点空间不足,但磁盘空间充足时,很可能就是过多小文件导致的。一般来说,删除这些小文件,或者把它们移动到索引节点充足的其他磁盘中,就可以解决这个问题。
目录项和索引节点缓存
sudo cat /proc/slabinfo | grep -E '^#|dentry|inode'
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
isofs_inode_cache 108 168 664 12 2 : tunables 0 0 0 : slabdata 14 14 0
rpc_inode_cache 46 46 704 23 4 : tunables 0 0 0 : slabdata 2 2 0
mqueue_inode_cache 17 17 960 17 4 : tunables 0 0 0 : slabdata 1 1 0
fuse_inode 8752 9272 832 19 4 : tunables 0 0 0 : slabdata 488 488 0
ecryptfs_inode_cache 0 0 1024 16 4 : tunables 0 0 0 : slabdata 0 0 0
fat_inode_cache 0 0 752 21 4 : tunables 0 0 0 : slabdata 0 0 0
squashfs_inode_cache 9463 9706 704 23 4 : tunables 0 0 0 : slabdata 422 422 0
ext4_inode_cache 114164 143837 1096 29 8 : tunables 0 0 0 : slabdata 33741 33741 0
hugetlbfs_inode_cache 100 100 632 25 4 : tunables 0 0 0 : slabdata 4 4 0
sock_inode_cache 2578 2599 704 23 4 : tunables 0 0 0 : slabdata 113 113 0
shmem_inode_cache 3618 4224 720 22 4 : tunables 0 0 0 : slabdata 192 192 0
proc_inode_cache 8984 13846 688 23 4 : tunables 0 0 0 : slabdata 602 602 0
inode_cache 27039 28925 616 13 2 : tunables 0 0 0 : slabdata 2225 2225 0
dentry 104015 130956 192 21 1 : tunables 0 0 0 : slabdata 6236 6236 0dentry 行表示目录项缓存,inode_cache 行,表示 VFS 索引节点缓存,其余的则是各种文件系统的索引节点缓存。
也可以用 slabtop 来查看:
# 按下c按照缓存大小排序,按下a按照活跃对象数排序
sudo slabtop
Active / Total Objects (% used) : 1035480 / 1363157 (76.0%)
Active / Total Slabs (% used) : 72678 / 72678 (100.0%)
Active / Total Caches (% used) : 86 / 112 (76.8%)
Active / Total Size (% used) : 296260.45K / 370719.97K (79.9%)
Minimum / Average / Maximum Object : 0.01K / 0.27K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
143566 113865 0% 1.07K 33694 29 1078208K ext4_inode_cache
443586 267139 0% 0.10K 11374 39 45496K buffer_head
131082 104401 0% 0.19K 6242 21 24968K dentry
34692 27457 0% 0.57K 2478 14 19824K radix_tree_node
134190 112894 0% 0.13K 4473 30 17892K kernfs_node_cache
28925 27039 0% 0.60K 2225 13 17800K inode_cache
55566 55437 0% 0.19K 2646 21 10584K kmalloc-192
13846 9010 0% 0.67K 602 23 9632K proc_inode_cache
9272 8752 0% 0.81K 488 19 7808K fuse_inode
9706 9463 0% 0.69K 422 23 6752K squashfs_inode_cache
720 557 0% 7.56K 180 4 5760K task_struct
23902 23376 0% 0.20K 1258 19 5032K vm_area_struct可以看到我的系统中 ext4_inode_cache 用了最多的 Slab 缓存,超过1G
磁盘I/O工作原理
磁盘
常见磁盘可以分为两类:机械磁盘和固态磁盘。
-
机械磁盘(Hard Disk Driver),缩写为 HDD,由盘片和读写磁头组成。在读写数据前,需要移动读写磁头,定位到数据所在的磁道,然后才能访问数据。显然,如果 I/O 请求刚好连续,那就不需要磁道寻址,速度更快,这其实就是我们熟悉的连续 I/O 的工作原理。与之相对应的,当然就是随机 I/O,它需要不停地移动磁头,来定位数据位置,所以读写速度就会比较慢。
-
固态磁盘(Solid State Disk),缩写为 SSD,由固态电子元器件组成。固态磁盘不需要磁道寻址,所以,不管是连续 I/O,还是随机 I/O 的性能,都比机械磁盘要好得多。
无论机械磁盘,还是固态磁盘,相同磁盘的随机 I/O 都要比连续 I/O 慢很多。对固态磁盘来说,虽然它的随机性能比机械硬盘好很多,但同样存在“先擦除再写入”的限制。随机读写会导致大量的垃圾回收,所以相对应的,随机 I/O 的性能比起连续 I/O 来,也还是差了很多。
此外,连续 I/O 还可以通过预读的方式,来减少 I/O 请求的次数,这也是其性能优异的一个原因。很多性能优化的方案,也都会从这个角度出发,来优化 I/O 性能。
此外,机械磁盘和固态磁盘还分别有一个最小的读写单位。
-
机械磁盘的最小读写单位是扇区,一般大小为 512 字节。
-
固态磁盘的最小读写单位是页,通常大小是 4KB、8KB 等。
按照接口来分类,比如可以把硬盘分为 IDE(Integrated Drive Electronics)、SCSI(Small Computer System Interface) 、SAS(Serial Attached SCSI) 、SATA(Serial ATA) 、FC(Fibre Channel) 等。
不同的接口,往往分配不同的设备名称。比如, IDE 设备会分配一个 hd 前缀的设备名,SCSI 和 SATA 设备会分配一个 sd 前缀的设备名。如果是多块同类型的磁盘,就会按照 a、b、c 等的字母顺序来编号。
其实在 Linux 中,磁盘实际上是作为一个块设备来管理的,也就是以块为单位读写数据,并且支持随机读写。每个块设备都会被赋予两个设备号,分别是主、次设备号。主设备号用在驱动程序中,用来区分设备类型;而次设备号则是用来给多个同类设备编号。
通用块层
跟虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层,其实是处在文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能 。
-
第一个功能跟虚拟文件系统的功能类似。向上,为文件系统和应用程序,提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
-
第二个功能,通用块层还会给文件系统和应用程序发来的 I/O 请求排队,并通过重新排序、请求合并等方式,提高磁盘读写的效率。
其中,对 I/O 请求排序的过程,也就是我们熟悉的 I/O 调度。事实上,Linux 内核支持四种 I/O 调度算法,分别是 NONE、NOOP、CFQ 以及 DeadLine。
-
第一种 NONE ,更确切来说,并不能算 I/O 调度算法。因为它完全不使用任何 I/O 调度器,对文件系统和应用程序的 I/O 其实不做任何处理,常用在虚拟机中(此时磁盘 I/O 调度完全由物理机负责)。
-
第二种 NOOP ,是最简单的一种 I/O 调度算法。它实际上是一个先入先出的队列,只做一些最基本的请求合并,常用于 SSD 磁盘。
-
第三种 CFQ(Completely Fair Scheduler),也被称为完全公平调度器,是现在很多发行版的默认 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。类似于进程 CPU 调度,CFQ 还支持进程 I/O 的优先级调度,所以它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
-
最后一种 DeadLine 调度算法,分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。DeadLine 调度算法,多用在 I/O 压力比较重的场景,比如数据库等。
I/O 栈
我们可以把 Linux 存储系统的 I/O 栈,由上到下分为三个层次,分别是文件系统层、通用块层和设备层。这三个 I/O 层的关系如下图所示,这其实也是 Linux 存储系统的 I/O 栈全景图。
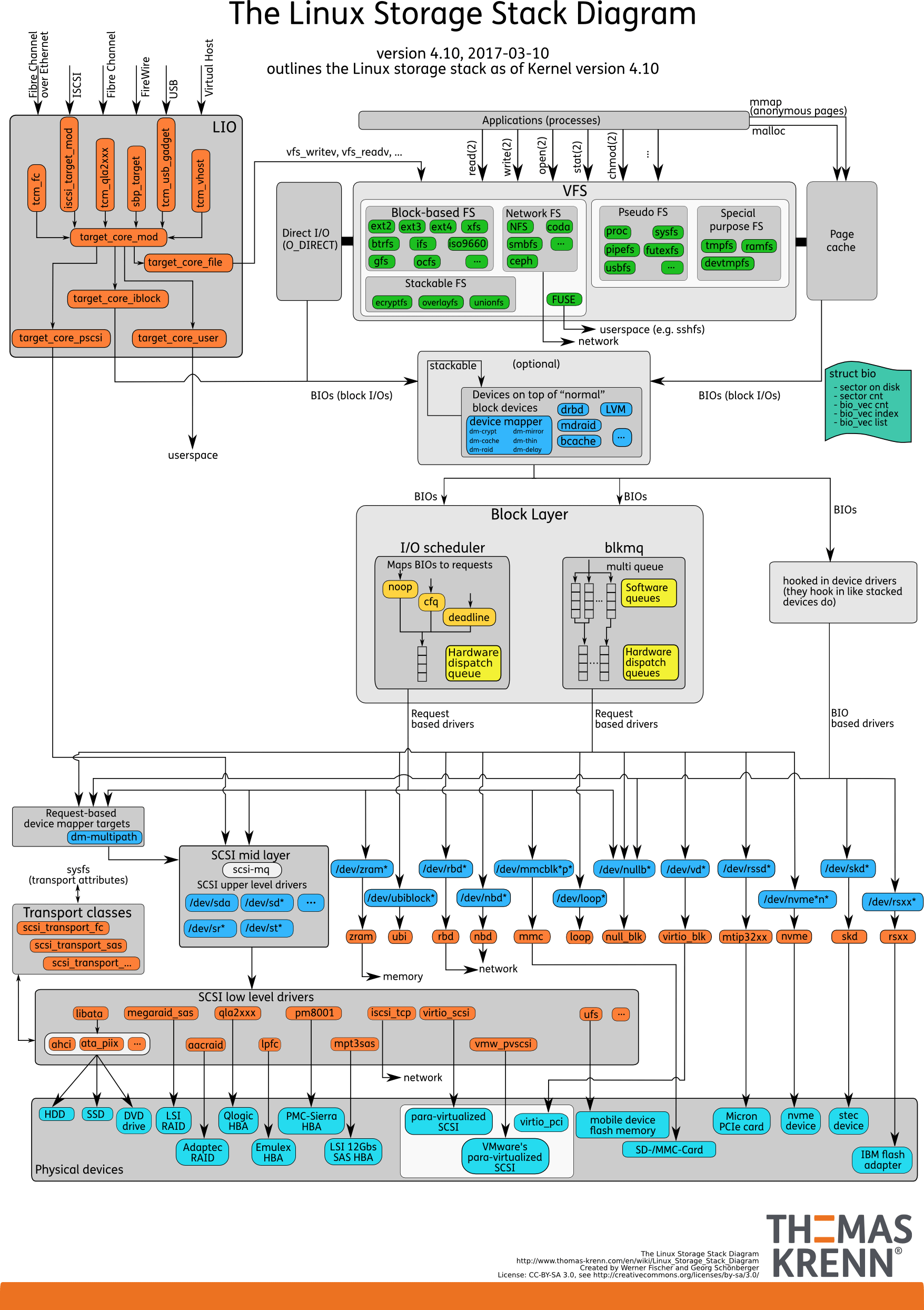
根据这张 I/O 栈的全景图,我们可以更清楚地理解,存储系统 I/O 的工作原理。
-
文件系统层,包括虚拟文件系统和其他各种文件系统的具体实现。它为上层的应用程序,提供标准的文件访问接口;对下会通过通用块层,来存储和管理磁盘数据。
-
通用块层,包括块设备 I/O 队列和 I/O 调度器。它会对文件系统的 I/O 请求进行排队,再通过重新排序和请求合并,然后才要发送给下一级的设备层。
-
设备层,包括存储设备和相应的驱动程序,负责最终物理设备的 I/O 操作。
存储系统的 I/O ,通常是整个系统中最慢的一环。所以, Linux 通过多种缓存机制来优化 I/O 效率。
比方说,为了优化文件访问的性能,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,以减少对下层块设备的直接调用。同样,为了优化块设备的访问效率,会使用缓冲区,来缓存块设备的数据。
磁盘性能指标
磁盘性能的衡量标准有使用率、饱和度、IOPS、吞吐量以及响应时间等。这五个指标,是衡量磁盘性能的基本指标。
-
使用率,是指磁盘处理 I/O 的时间百分比。过高的使用率(比如超过 80%),通常意味着磁盘 I/O 存在性能瓶颈。
-
饱和度,是指磁盘处理 I/O 的繁忙程度。过高的饱和度,意味着磁盘存在严重的性能瓶颈。当饱和度为 100% 时,磁盘无法接受新的 I/O 请求。
-
IOPS(Input/Output Per Second),是指每秒的 I/O 请求数。
-
吞吐量,是指每秒的 I/O 请求大小。
-
响应时间,是指 I/O 请求从发出到收到响应的间隔时间。
要注意的是,使用率只考虑有没有 I/O,而不考虑 I/O 的大小。换句话说,当使用率是 100% 的时候,磁盘依然有可能接受新的 I/O 请求。
要注意的是不要孤立地去比较某一指标,而要结合读写比例、I/O 类型(随机还是连续)以及 I/O 的大小,综合来分析。
举个例子,在数据库、大量小文件等这类随机读写比较多的场景中,IOPS 更能反映系统的整体性能;而在多媒体等顺序读写较多的场景中,吞吐量才更能反映系统的整体性能。
磁盘 I/O 观测
iostat 是最常用的磁盘 I/O 性能观测工具,它提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,当然,这些指标实际上来自 /proc/diskstats。
# -d -x表示显示所有磁盘I/O的指标
iostat -d -x 1
Linux 4.15.0-180-generic (VM-0-11-ubuntu) 08/08/2023 _x86_64_ (2 CPU)
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.10 0.00 0.00 1.01 0.00 0.00 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.08 0.00 0.00 1.03 0.00 0.00 0.00
loop2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.21 0.00 0.00 1.01 0.00 0.01 0.00
loop3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.08 0.00 0.00 1.02 0.00 0.01 0.00
loop4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.10 0.00 0.00 1.00 0.00 0.00 0.00
loop5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.25 0.00 0.00 1.02 0.00 0.01 0.00
scd0 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 3.46 0.00 0.00 33.96 0.00 2.63 0.00
vda 0.05 4.73 3.86 47.55 0.00 4.39 0.02 48.11 1.37 0.84 0.00 74.02 10.05 0.09 0.04各列指标含义如下:
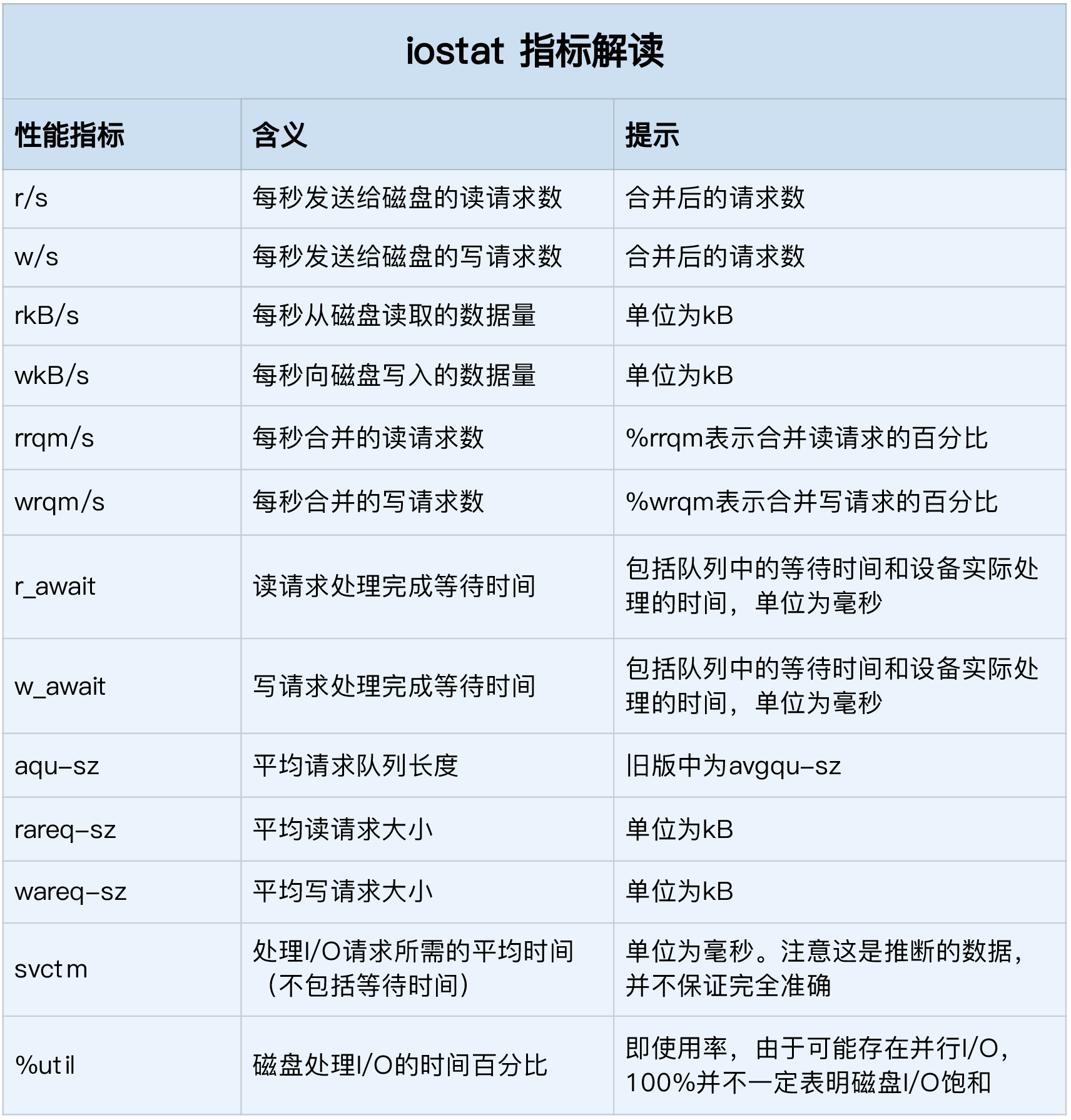
这些指标中,你要注意:
-
%util ,就是我们前面提到的磁盘 I/O 使用率;
-
r/s+ w/s ,就是 IOPS;
-
rkB/s+wkB/s ,就是吞吐量;
-
r_await+w_await ,就是响应时间。
在观测指标时,也别忘了结合请求的大小( rareq-sz 和 wareq-sz)一起分析。
进程 I/O 观测
除了每块磁盘的 I/O 情况,每个进程的 I/O 情况也是我们需要关注的重点。
上面提到的 iostat 只提供磁盘整体的 I/O 性能数据,缺点在于,并不能知道具体是哪些进程在进行磁盘读写。要观察进程的 I/O 情况,你还可以使用 pidstat 和 iotop 这两个工具。
给 pidstat 加上 -d 参数,你就可以看到进程的 I/O 情况:
pidstat -d 1
Linux 4.15.0-180-generic (VM-0-11-ubuntu) 08/08/2023 _x86_64_ (2 CPU)
06:04:14 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:15 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:16 PM 0 313 -1.00 -1.00 -1.00 1 jbd2/vda1-8
06:04:16 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:17 PM 0 313 -1.00 -1.00 -1.00 2 jbd2/vda1-8
06:04:17 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:18 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:19 PM 0 313 -1.00 -1.00 -1.00 1 jbd2/vda1-8
06:04:19 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:20 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
06:04:21 PM 0 313 -1.00 -1.00 -1.00 1 jbd2/vda1-8
^C
Average: UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
Average: 0 313 -1.00 -1.00 -1.00 1 jbd2/vda1-8从 pidstat 的输出你能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容:
-
用户 ID(UID)和进程 ID(PID) 。
-
每秒读取的数据大小(kB_rd/s) ,单位是 KB。
-
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
-
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
-
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
除了可以用 pidstat 实时查看,根据 I/O 大小对进程排序,也是性能分析中一个常用的方法,可以用 iotop。iotop 是一个类似于 top 的工具,你可以按照 I/O 大小对进程排序,然后找到 I/O 较大的那些进程。
sudo iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 2.16 M/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 129.98 K/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
313 be/3 root 0.00 B/s 0.00 B/s 0.00 % 2.59 % [jbd2/vda1-8]
26512 be/4 mysql 0.00 B/s 0.00 B/s 0.00 % 0.43 % mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
26526 be/4 mysql 0.00 B/s 7.88 K/s 0.00 % 0.32 % mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
26521 be/4 mysql 0.00 B/s 2.15 M/s 0.00 % 0.11 % mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
26517 be/4 mysql 0.00 B/s 0.00 B/s 0.00 % 0.08 % mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
24007 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.02 % [kworker/u4:0]
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 32
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
4 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kworker/0:0H]
6 be/0 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [mm_percpu_wq]从这个输出,你可以看到,前两行分别表示,进程的磁盘读写大小总数和磁盘真实的读写大小总数。因为缓存、缓冲区、I/O 合并等因素的影响,它们可能并不相等。剩下的部分,则是从各个角度来分别表示进程的 I/O 情况,包括线程 ID、I/O 优先级、每秒读磁盘的大小、每秒写磁盘的大小、换入和等待 I/O 的时钟百分比等。
这两个工具,是我们分析磁盘 I/O 性能时最常用到的。
I/O排查思路
-
可以先用 top ,来观察 CPU 和内存的使用情况;
-
再用 iostat ,来观察磁盘的 I/O 情况。
-
再用 pidstat ,观察进程的 I/O 情况。
-
最后用 strace 进行具体的跟踪。
top
# 按1切换到每个CPU的使用情况
top
top - 14:43:43 up 1 day, 1:39, 2 users, load average: 2.48, 1.09, 0.63
Tasks: 130 total, 2 running, 74 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.7 us, 6.0 sy, 0.0 ni, 0.7 id, 92.7 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.3 sy, 0.0 ni, 92.3 id, 7.3 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8169308 total, 747684 free, 741336 used, 6680288 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7113124 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
18940 root 20 0 656108 355740 5236 R 6.3 4.4 0:12.56 python
1312 root 20 0 236532 24116 9648 S 0.3 0.3 9:29.80 python3观察 top 的输出,你会发现,CPU0 的使用率非常高,它的系统 CPU 使用率(sys%)为 6%,而 iowait 超过了 90%。这说明 CPU0 上,可能正在运行 I/O 密集型的进程。
接着我们来看,进程部分的 CPU 使用情况。你会发现, python 进程的 CPU 使用率已经达到了 6%,而其余进程的 CPU 使用率都比较低,不超过 0.3%。看起来 python 是个可疑进程。
最后再看内存的使用情况,总内存 8G,剩余内存只有 730 MB,而 Buffer/Cache 占用内存高达 6GB 之多,这说明内存主要被缓存占用。虽然大部分缓存可回收,我们还是得了解下缓存的去处,确认缓存使用都是合理的。
到这一步,基本可以判断出,CPU 使用率中的 iowait 是一个潜在瓶颈,而内存部分的缓存占比较大,那磁盘 I/O 又是怎么样的情况呢?
再运行 iostat 命令,观察 I/O 的使用情况
iostat
# -d表示显示I/O性能指标,-x表示显示扩展统计(即所有I/O指标)
iostat -x -d 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20观察 iostat 的最后一列,你会看到,磁盘 sda 的 I/O 使用率已经高达 99%,很可能已经接近 I/O 饱和。
再看前面的各个指标,每秒写磁盘请求数是 64 ,写大小是 32 MB,写请求的响应时间为 7 秒,而请求队列长度则达到了 1100。
超慢的响应时间和特长的请求队列长度,进一步验证了 I/O 已经饱和的猜想。
此时,sda 磁盘已经遇到了严重的性能瓶颈。到这里,也就可以理解,为什么前面看到的 iowait 高达 90% 了,这正是磁盘 sda 的 I/O 瓶颈导致的。接下来的重点就是分析 I/O 性能瓶颈的根源了。
那要怎么知道,这些 I/O 请求相关的进程呢?可以用 pidstat 或者 iotop ,观察进程的 I/O 情况。这里,我就用 pidstat 来看一下。
pidstat
# pidstat 加上 -d 参数,就可以显示每个进程的 I/O 情况
pidstat -d 1
15:08:35 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:36 0 18940 0.00 45816.00 0.00 96 python
15:08:36 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
15:08:37 0 354 0.00 0.00 0.00 350 jbd2/sda1-8
15:08:37 0 18940 0.00 46000.00 0.00 96 python
15:08:37 0 20065 0.00 0.00 0.00 1503 kworker/u4:2从 pidstat 的输出,你可以发现,只有 python 进程的写比较大,而且每秒写的数据超过 45 MB,比上面 iostat 发现的 32MB 的结果还要大。很明显,正是 python 进程导致了 I/O 瓶颈。
strace
我们在终端中运行 strace 命令,并通过 -p 18940 指定 python 进程的 PID 号:
strace -p 18940
strace: Process 18940 attached
...
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000
write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844
) = 314572844
munmap(0x7f0f682e8000, 314576896) = 0
write(3, "\n", 1) = 1
munmap(0x7f0f7aee9000, 314576896) = 0
close(3) = 0
stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0定位到是写日志导致的。





![[vue-element-admin]下载与安装](https://img-blog.csdnimg.cn/c6488911475f4010929a5a2910fdf10f.png)

![[ubuntu]创建root权限的用户](https://img-blog.csdnimg.cn/e6d62a0f27cc4068b41edd9981cc0464.png)