目录
一.引言
二.随机森林实战
1.数据预处理
2.随机森林 Pipeline
3.模型预测与验证
三.总结
一.引言
之前介绍了 决策树 ,而随机森林则可以看作是多颗决策树的集合。在 Spark ML 中,随机森林中的每一颗树都被分配到不同的节点上进行并行计算,或者在一些特定的条件下,单独的一颗决策树也可以并行化运算,其中每一棵决策树之间没有相关性。
随机森林在运行的时候,每当有一个新的数据传输到系统中,都会由随机森林的每一颗决策树同时进行处理,如果处理一个连续常数,就会取所有树的平均值作为结果,这里可以看做是等权重;如果是非连续结果,就选择所有决策树结果中最多的一项,类似于投票法。
Tips:
训练过程中不同决策树的随机性来源于每次迭代中对原始数据进行的二次采样 boostrap,该采样方法可以使得决策树获得不同的训练集,从而在树节点上拆分不同的随机特征子集,这也是随机森林随机性的由来。
二.随机森林实战
随机森林支持回归与分类,回归可以看做是等权重的平均,分类可以看做是少数服从多数的投票。
1.数据预处理
数据存储为 libsvm 格式,最开始为标签 label,后面为不同特征的不同取值:
val spark = SparkSession
.builder //创建spark会话
.master("local")
.appName("RandomForestClassifierExample") //设置名称
.getOrCreate() //创建会话变量
// 读取文件,装载数据到spark dataframe 格式中
val data = spark.read.format("libsvm").load("/Users/xudong11/sparkV3/src/main/scala/org/example/RandomForest/sample_libsvm_data.txt")
// 搜索标签,添加元数据到标签列
// 对整个数据集包括索引的全部标签都要适应拟合
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(data)
// 自动识别分类特征,并对其进行索引
// 设置maxCategories以便大于4个不同值的特性被视为连续的。
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4)
.fit(data)
// 按照7:3的比例进行拆分数据,70%作为训练集,30%作为测试集
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))数据的预处理分为四步:
A - spark.read.format('libsvm') 负责解析 libsvm 格式数据
B - StringIndexer 负责将标签重新匹配,出现次数最多的标签索引为 0,以此类推
C - VectorIndexer 负责将特征重新映射,根据 MaxCategories 的取值决定特征是连续还是离散
D - randomSplit 负责将原始数据按照给定 RatioArray 进行划分,返回 Array[DataSet[Row]]
其中 B 和 C 提到的两个 indexer 可能解释不够清晰,决策树实战 一文中有两个函数方法的详细解释与示例,大家可以参考。
2.随机森林 Pipeline
这一步主要结合前面数据预处理部分定义的 Transformer 并添加 RandomForest 构建 pipeline fit 数据,从而获取最终的模型。RF 模型除了设定输入输出列外,还定义了 numTrees 代表随机森林中决策树的数量,该参数至少为1,默认为20。labelConverter 负责将 labelIndexer 转换后的标签再重新映射回去。通过组装4个部件我们得到了最终的 pipeline 并应用于到数据预处理中得到的 TrainData。
// 建立一个决策树分类器,并设置森林中含有10颗树
val rf = new RandomForestClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")
.setNumTrees(10)
// 将索引标签转换回原始标签
val labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labelsArray(0))
// 把索引和决策树链接(组合)到一个管道(工作流)之中
val pipeline = new Pipeline()
.setStages(Array(labelIndexer, featureIndexer, rf, labelConverter))
// 载入训练集数据正式训练模型
val model = pipeline.fit(trainingData)Tips 关于树的数量与深度:
通常情况下,随机森林的准确性与树的数量成正比,但是随之而来的是更多地训练与预测成本,除此之外也与自己的数据规模、特征多少有关,国外的同学在 29 个常规数据集上测试发现在 128 棵树之后随机森林的准确性不再有显著的改进。
其次关于树的深度,这个其实和单棵决策树是相同的,在特征较多的情况下,如果存在过拟合的情况需要通过剪枝解决。
除此之外,可以通过随机选择特征结合 out-of-bag [OOB] 袋外误差率评估模型效果,如果将某个特征换为随机值,OOB-Error 没有明显增加则代表当前特征不显著,反之特征显著。
3.模型预测与验证
这一步利用上一步 Pipeline fit 得到的 Transformer Model 进行 transform 对测试数据转换,随后使用 Evaluator 进行评估。
// 使用测试集作预测
val predictions = model.transform(testData)
// 选择一些样例进行显示
predictions.select("predictedLabel", "label", "features").show(5)
// 计算测试误差
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictions)
println(s"Test Error = ${1.0 - accuracy}")
val rfModel = model.stages(2).asInstanceOf[RandomForestClassificationModel]
println(s"Learned classification forest model:\n ${rfModel.toDebugString}")
spark.stop()最后调用 asInstanceOf 将 pipeline 中的 RF Model 转换出来,打印 toDebugString 获取当前的随机森林情况。
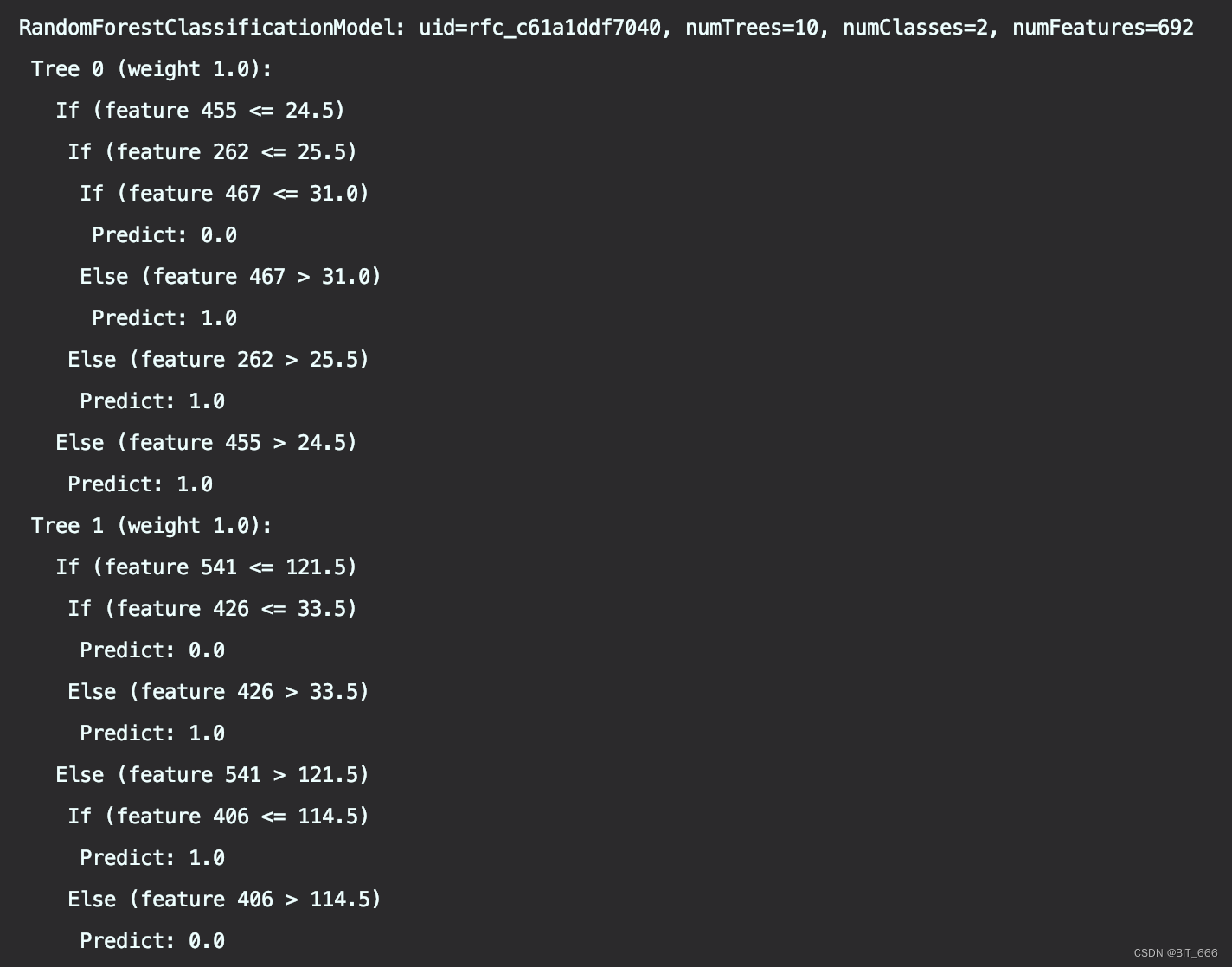
...... 此处忽略 Tree2 - Tree7 .....
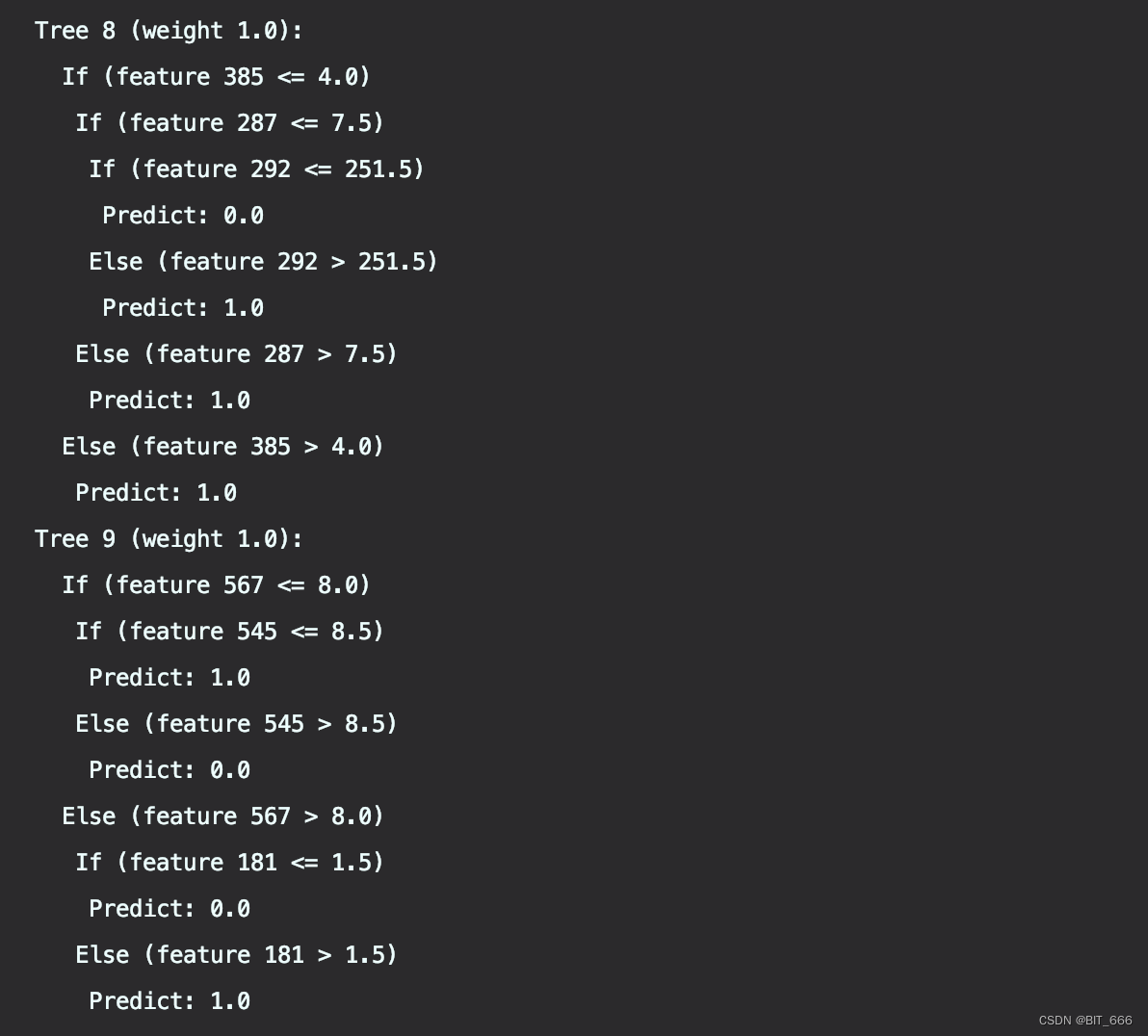
numTrees = 10,分别为 Tree0 -> Tree9,可以看到大家的 weight 均为 1.0,如果是 GBDT 的情况下,每棵树的权重也不同。每棵决策树的 If else 可以看做是分界点、其中分界条件即为特征划分选择。最终将 10 棵树的 Predict 进行投票法,选取大部分决策树都认同的结果作为随机森林的预测结果。
三.总结
随机森林的本质就是建立多颗决策树,然后取得所有决策树的平均值或者以投票的方式分类。随机森林是用于分类和回归最成功的机器学习模型之一,其结合多颗决策树,以降低过拟合的风险。与决策树相同,随机森林可以实现特征的自动选择,上述 IF ELSE 的每一个决策节点都可以看做是区分度较大的特征。

![[附源码]Nodejs计算机毕业设计基于web的家教管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/7297cc7ca48a406d9bd19b5fcfc6d185.png)

![[附源码]Node.js计算机毕业设计电影票网上订票系统Express](https://img-blog.csdnimg.cn/6241bce620574d6e9a91f0a6a9887d74.png)




![[附源码]Nodejs计算机毕业设计基于web的火车订票管理系统Express(程序+LW)](https://img-blog.csdnimg.cn/0a0f283ce4734e99aa72064e46a5b86a.png)