文章目录
- 介绍
- 特性
- 支持的数据库
- 安装
- 创建 Engine
- 单引擎
- 日志
- 连接池
- 引擎组
- 引擎组策略
- 负载策略
- 定义表结构体
- 各种映射规则
- 前缀映射,后缀映射和缓存映射
- 使用 Table 和 Tag 改变名称映射
- Column 属性定义
- Go与字段类型对应表
- 表结构操作
- 获取数据库信息
- 表操作
- 创建索引和唯一索引
- 同步数据库结构
- 导出导入SQL脚本
- Dump数据库结构和数据
- Import 执行数据库SQL脚本
- 插入数据
- 创建时间Created
- 查询和统计数据
- 查询条件方法
- 临时开关方法
- Get方法
- Find方法
- Count方法
- Exist系列方法
- 与Get的区别
- 建议
- Iterate方法
- Join的使用
- Rows方法
- Sum系列方法
- 更新数据
- 乐观锁Version
- 更新时间Updated
- 删除数据
- 软删除Deleted
- 执行SQL查询
- Query
- QueryInterface
- QueryString
- 执行SQL命令
- 事务处理
- 缓存
- 事件
- Builder
- Insert
- Select
- Update
- Delete
- Union
- Conditions
介绍
xorm是一个简单而强大的Go语言ORM库. 通过它可以使数据库操作非常简便。xorm的目标并不是让你完全不去学习SQL,我们认为SQL并不会为ORM所替代,但是ORM将可以解决绝大部分的简单SQL需求。xorm支持两种风格的混用。
特性
- 支持Struct和数据库表之间的灵活映射,并支持自动同步
- 事务支持
- 同时支持原始SQL语句和ORM操作的混合执行
- 使用连写来简化调用
- 支持使用Id, In, Where, Limit, Join, Having, Table, SQL, Cols等函数和结构体等方式作为条件
- 支持级联加载Struct
- Schema支持(仅Postgres)
- 支持缓存
- 支持根据数据库自动生成xorm的结构体
- 支持记录版本(即乐观锁)
- 内置SQL Builder支持
- 通过EngineGroup支持读写分离和负载均衡
支持的数据库
- Mysql: github.com/go-sql-driver/mysql
- MyMysql: github.com/ziutek/mymysql/godrv
- Postgres: github.com/lib/pq
- Tidb: github.com/pingcap/tidb
- SQLite: github.com/mattn/go-sqlite3
- MsSql: github.com/denisenkom/go-mssqldb
- MsSql: github.com/lunny/godbc
- Oracle: github.com/mattn/go-oci8 (试验性支持)
- ql: github.com/cznic/ql (试验性支持)
安装
go get xorm.io/xorm
创建 Engine
所有操作均需要事先创建并配置 ORM 引擎才可以进行。XORM 支持两种 ORM 引擎,即 Engine 引擎和 Engine Group 引擎。一个 Engine 引擎用于对单个数据库进行操作,一个 Engine Group 引擎用于对读写分离的数据库或者负载均衡的数据库进行操作。Engine 引擎和 EngineGroup 引擎的API基本相同,所有适用于 Engine 的 API 基本上都适用于 EngineGroup,并且可以比较容易的从 Engine 引擎迁移到 EngineGroup 引擎。
单引擎
单个ORM引擎,也称为Engine。一个 APP 可以同时存在多个 Engine 引擎,一个Engine一般只对应一个数据库。Engine 通过调用 xorm.NewEngine 生成,如:
import (
_ "github.com/go-sql-driver/mysql"
"xorm.io/xorm"
)
var engine *xorm.Engine
func main() {
var err error
engine, err = xorm.NewEngine("mysql", "root:123@/test?charset=utf8")
}
或者:
import (
_ "github.com/mattn/go-sqlite3"
"xorm.io/xorm"
)
var engine *xorm.Engine
func main() {
var err error
engine, err = xorm.NewEngine("sqlite3", "./test.db")
}
你也可以用 NewEngineWithParams, NewEngineWithDB 和 NewEngineWithDialectAndDB 来创建引擎。
一般情况下如果只操作一个数据库,只需要创建一个 engine 即可。engine 是 GoRoutine 安全的。
创建完成 engine 之后,并没有立即连接数据库,此时可以通过 engine.Ping() 或者 engine.PingContext() 来进行数据库的连接测试是否可以连接到数据库。另外对于某些数据库有连接超时设置的,可以通过起一个定期Ping的Go程来保持连接鲜活。
对于有大量数据并且需要分区的应用,也可以根据规则来创建多个Engine,比如:
var err error
for i:=0;i<5;i++ {
engines[i], err = xorm.NewEngine("sqlite3", fmt.Sprintf("./test%d.db", i))
}
engine 可以通过 engine.Close 来手动关闭,但是一般情况下可以不用关闭,在程序退出时会自动关闭。
NewEngine 传入的参数和sql.Open传入的参数完全相同,因此,在使用某个驱动前,请查看此驱动中关于传入参数的说明文档。以下为各个驱动的连接符对应的文档链接:
- sqlite3
- mysql dsn
- mymysql
- postgres
日志
日志是一个接口,通过设置日志,可以显示SQL,警告以及错误等,默认的显示级别为 INFO。
engine.ShowSQL(true),则会在控制台打印出生成的SQL语句;engine.Logger().SetLevel(log.LOG_DEBUG),则会在控制台打印调试及以上的信息;
package main
import (
_ "github.com/go-sql-driver/mysql"
"xorm.io/xorm"
"xorm.io/xorm/log"
)
var engine *xorm.Engine
func main() {
engine, _ = xorm.NewEngine("mysql", "root:@/test?charset=utf8mb4")
engine.ShowSQL(true)
engine.Logger().SetLevel(log.LOG_DEBUG)
engine.Close()
}
如果希望将信息不仅打印到控制台,而是保存为文件,那么可以通过类似如下的代码实现,NewSimpleLogger(w io.Writer)接收一个io.Writer接口来将数据写入到对应的设施中。
f, err := os.Create("sql.log")
if err != nil {
println(err.Error())
return
}
engine.SetLogger(log.NewSimpleLogger(f))
当然,如果希望将日志记录到 syslog 中,也可以如下:
logWriter, err := syslog.New(syslog.LOG_DEBUG, "rest-xorm-example")
if err != nil {
log.Fatalf("Fail to create xorm system logger: %v\n", err)
}
logger := log.NewSimpleLogger(logWriter)
logger.ShowSQL(true)
engine.SetLogger(logger)
你也可以自定义自己的接口,可通过日志接口中包含的 context 进行更详细的跟踪。
连接池
engine内部支持连接池接口和对应的函数。
- 如果需要设置连接池的空闲数大小,可以使用
engine.SetMaxIdleConns()来实现。 - 如果需要设置最大打开连接数,则可以使用
engine.SetMaxOpenConns()来实现。 - 如果需要设置连接的最大生存时间,则可以使用
engine.SetConnMaxLifetime()来实现。
引擎组
通过创建引擎组 EngineGroup 来实现对从数据库 (Master/Slave) 读写分离的支持。在创建引擎章节中,我们已经介绍过了,在 xorm 里面,可以同时存在多个 Orm 引擎,一个 Orm 引擎称为 Engine,一个 Engine 一般只对应一个数据库,而 EngineGroup 一般则对应一组数据库。EngineGroup 通过调用 xorm.NewEngineGroup 生成,如:
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
conns := []string{
"postgres://postgres:root@localhost:5432/test?sslmode=disable;", // 第一个默认是master
"postgres://postgres:root@localhost:5432/test1?sslmode=disable;", // 第二个开始都是slave
"postgres://postgres:root@localhost:5432/test2?sslmode=disable",
}
var err error
eg, err = xorm.NewEngineGroup("postgres", conns)
}
或者
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
var err error
master, err := xorm.NewEngine("postgres", "postgres://postgres:root@localhost:5432/test?sslmode=disable")
if err != nil {
return
}
slave1, err := xorm.NewEngine("postgres", "postgres://postgres:root@localhost:5432/test1?sslmode=disable")
if err != nil {
return
}
slave2, err := xorm.NewEngine("postgres", "postgres://postgres:root@localhost:5432/test2?sslmode=disable")
if err != nil {
return
}
slaves := []*xorm.Engine{slave1, slave2}
eg, err = xorm.NewEngineGroup(master, slaves)
}
创建完成 EngineGroup 之后,并没有立即连接数据库,此时可以通过 eg.Ping() 来进行数据库的连接测试是否可以连接到数据库,该方法会依次调用引擎组中每个Engine的Ping方法。另外对于某些数据库有连接超时设置的,可以通过起一个定期Ping的Go程来保持连接鲜活。EngineGroup 可以通过 eg.Close() 来手动关闭,但是一般情况下可以不用关闭,在程序退出时会自动关闭。
- NewEngineGroup方法
func NewEngineGroup(args1 interface{}, args2 interface{}, policies ...GroupPolicy) (*EngineGroup, error)
前两个参数的使用示例如上,有两种模式。
-
模式一:通过给定 DriverName,DataSourceName 来创建引擎组,每个引擎使用相同的Driver。每个引擎的 DataSourceNames 是 []string 类型,第一个元素是 Master 的 DataSourceName,之后的元素是 Slave的DataSourceName 。
-
模式二:通过给定*xorm.Engine,
[]*xorm.Engine来创建引擎组,每个引擎可以使用不同的 Driver。第一个参数为 Master 的 *xorm.Engine,第二个参数为 Slave 的 []*xorm.Engine。 NewEngineGroup 方法,第三个参数为 policies,为 Slave 设定负载策略,该参数将在负载策略章节详细介绍,如示例中未指定,则默认为轮询负载策略。 -
Master方法
func (eg *EngineGroup) Master() *Engine
返回Master数据库引擎
- Slave方法
func (eg *EngineGroup) Slave() *Engine
依据给定的负载策略返回一个Slave数据库引擎
- Slaves方法
func (eg *EngineGroup) Slaves() []*Engine
返回所以 Slave 数据库引擎
- SetPolicy方法
func (eg *EngineGroup) SetPolicy(policy GroupPolicy) *EngineGroup
引擎组策略
负载策略
通过 xorm.NewEngineGroup 创建 EngineGroup 时,第三个参数为 policies,我们可以通过该参数来指定 Slave 访问的负载策略。如创建EngineGroup 时未指定,则默认使用轮询的负载策略。
xorm 中内置五种负载策略,分别为随机访问负载策略,权重随机访问负载策略,轮询访问负载策略,权重轮询访问负载策略和最小连接数访问负载策略。开发者也可以通过实现 GroupPolicy 接口,来实现自定义负载策略。
- 随机访问负载策略
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
conns := []string{
"postgres://postgres:root@localhost:5432/test?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test1?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test2?sslmode=disable",
}
var err error
eg, err = xorm.NewEngineGroup("postgres", conns, xorm.RandomPolicy())
}
- 权重随机访问负载策略
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
conns := []string{
"postgres://postgres:root@localhost:5432/test?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test1?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test2?sslmode=disable",
}
var err error
//此时设置的test1数据库和test2数据库的随机访问权重为2和3
eg, err = xorm.NewEngineGroup("postgres", conns, xorm.WeightRandomPolicy([]int{2, 3}))
}
- 轮询访问负载策略
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
conns := []string{
"postgres://postgres:root@localhost:5432/test?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test1?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test2?sslmode=disable",
}
var err error
eg, err = xorm.NewEngineGroup("postgres", conns, xorm.RoundRobinPolicy())
}
- 权重轮询访问负载策略
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
conns := []string{
"postgres://postgres:root@localhost:5432/test?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test1?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test2?sslmode=disable",
}
var err error
//此时设置的test1数据库和test2数据库的轮询访问权重为2和3
eg, err = xorm.NewEngineGroup("postgres", conns, xorm.WeightRoundRobinPolicy([]int{2, 3}))
}
- 最小连接数访问负载策略
import (
_ "github.com/lib/pq"
"xorm.io/xorm"
)
var eg *xorm.EngineGroup
func main() {
conns := []string{
"postgres://postgres:root@localhost:5432/test?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test1?sslmode=disable;",
"postgres://postgres:root@localhost:5432/test2?sslmode=disable",
}
var err error
eg, err = xorm.NewEngineGroup("postgres", conns, xorm.LeastConnPolicy())
}
- 自定义负载策略
你也可以通过实现 GroupPolicy 接口来实现自定义负载策略。
type GroupPolicy interface {
Slave(*EngineGroup) *Engine
}
定义表结构体
各种映射规则
跟名称相关的函数包含在 xorm.io/xorm/names 下。名称映射规则主要负责结构体名称到表名和结构体 field 到表字段的名称映射。由 names.Mapper 接口的实现者来管理,xorm 内置了三种 Mapper 实现:names.SnakeMapper , names.SameMapper和names.GonicMapper。
- SnakeMapper 支持struct为驼峰式命名,表结构为下划线命名之间的转换,这个是默认的Maper;
- SameMapper 支持结构体名称和对应的表名称以及结构体field名称与对应的表字段名称相同的命名;
- GonicMapper 和SnakeMapper很类似,但是对于特定词支持更好,比如ID会翻译成id而不是i_d。
当前 SnakeMapper 为默认值,如果需要改变时,在 engine 创建完成后使用
engine.SetMapper(names.GonicMapper{})
同时需要注意的是:
- 如果你使用了别的命名规则映射方案,也可以自己实现一个 Mapper。
- 表名称和字段名称的映射规则默认是相同的,当然也可以设置为不同,如:
engine.SetTableMapper(names.SameMapper{})
engine.SetColumnMapper(names.SnakeMapper{})
当结构体自动转换为对应的数据库类型时,下面的表显示了转换关系:
| go type’s kind | value method | xorm type |
|---|---|---|
| implemented Conversion | Conversion.ToDB / Conversion.FromDB | Text |
| int, int8, int16, int32, uint, uint8, uint16, uint32 | Int | |
| int64, uint64 | BigInt | |
| float32 | Float | |
| float64 | Double | |
| complex64, complex128 | json.Marshal / json.UnMarshal | Varchar(64) |
| []uint8 | Blob | |
| array, slice, map except []uint8 | json.Marshal / json.UnMarshal | Text |
| bool | 1 or 0 | Bool |
| string | Varchar(255) | |
| time.Time | DateTime | |
| cascade struct | primary key field value | BigInt |
| struct | json.Marshal / json.UnMarshal | Text |
| Others | Text |
前缀映射,后缀映射和缓存映射
- 通过
names.NewPrefixMapper(names.SnakeMapper{}, "prefix")可以创建一个在 SnakeMapper 的基础上在命名中添加统一的前缀,当然也可以把 SnakeMapper{} 换成 SameMapper 或者你自定义的 Mapper。
例如,如果希望所有的表名都在结构体自动命名的基础上加一个前缀而字段名不加前缀,则可以在 engine 创建完成后执行以下语句:
tbMapper := names.NewPrefixMapper(names.SnakeMapper{}, "prefix_")
engine.SetTableMapper(tbMapper)
执行之后,结构体 type User struct 默认对应的表名就变成了 prefix_user 了,而之前默认的是 user
- 通过
names.NewSuffixMapper(names.SnakeMapper{}, "suffix")可以创建一个在 SnakeMapper 的基础上在命名中添加统一的后缀,当然也可以把SnakeMapper换成SameMapper或者你自定义的Mapper。 - 通过
names.NewCacheMapper(names.SnakeMapper{})可以创建一个组合了其它的映射规则,起到在内存中缓存曾经映射过的命名映射。
使用 Table 和 Tag 改变名称映射
如果所有的命名都是按照 Mapper 的映射来操作的,那当然是最理想的。但是如果碰到某个表名或者某个字段名跟映射规则不匹配时,我们就需要别的机制来改变。xorm 提供了如下几种方式来进行:
- 如果结构体拥有
TableName() string的成员方法,那么此方法的返回值即是该结构体对应的数据库表名。 - 通过
engine.Table()方法可以改变 struct 对应的数据库表的名称,通过 sturct 中 field 对应的 Tag 中使用xorm:"'column_name'"可以使该 field 对应的 Column 名称为指定名称。这里使用两个单引号将 Column 名称括起来是为了防止名称冲突,因为我们在Tag中还可以对这个Column进行更多的定义。如果名称不冲突的情况,单引号也可以不使用。
到此名称映射的所有方法都给出了,一共三种方式,这三种是有优先级顺序的。
- 表名的优先级顺序如下:
engine.Table()指定的临时表名优先级最高TableName() string其次Mapper自动映射的表名优先级最后
- 字段名的优先级顺序如下:
- 结构体tag指定的字段名优先级较高
Mapper自动映射的表名优先级较低
Column 属性定义
我们在 field 对应的 Tag 中对 Column 的一些属性进行定义,定义的方法基本和我们写SQL定义表结构类似,比如:
type User struct {
Id int64
Name string `xorm:"varchar(25) notnull unique 'usr_name' comment('姓名')"`
}
对于不同的数据库系统,数据类型其实是有些差异的。因此xorm中对数据类型有自己的定义,基本的原则是尽量兼容各种数据库的字段类型,具体的字段对应关系可以查看字段类型对应表。对于使用者,一般只要使用自己熟悉的数据库字段定义即可。
具体的 Tag 规则如下,另 Tag 中的关键字均不区分大小写,但字段名根据不同的数据库是区分大小写:
| name | 当前field对应的字段的名称,可选,如不写,则自动根据field名字和转换规则命名,如与其它关键字冲突,请使用单引号括起来。 |
|---|---|
| pk | 是否是Primary Key,如果在一个struct中有多个字段都使用了此标记,则这多个字段构成了复合主键,单主键当前支持int32,int,int64,uint32,uint,uint64,string这7种Go的数据类型,复合主键支持这7种Go的数据类型的组合。 |
| 当前支持30多种字段类型,详情参见本文最后一个表格 | 字段类型 |
| autoincr | 是否是自增 |
| [not ]null 或 notnull | 是否可以为空 |
| unique或unique(uniquename) | 是否是唯一,如不加括号则该字段不允许重复;如加上括号,则括号中为联合唯一索引的名字,此时如果有另外一个或多个字段和本unique的uniquename相同,则这些uniquename相同的字段组成联合唯一索引 |
| index或index(indexname) | 是否是索引,如不加括号则该字段自身为索引,如加上括号,则括号中为联合索引的名字,此时如果有另外一个或多个字段和本index的indexname相同,则这些indexname相同的字段组成联合索引 |
| extends | 应用于一个匿名成员结构体或者非匿名成员结构体之上,表示此结构体的所有成员也映射到数据库中,extends可加载无限级 |
| - | 这个Field将不进行字段映射 |
| -> | 这个Field将只写入到数据库而不从数据库读取 |
| <- | 这个Field将只从数据库读取,而不写入到数据库 |
| created | 这个Field将在Insert时自动赋值为当前时间 |
| updated | 这个Field将在Insert或Update时自动赋值为当前时间 |
| deleted | 这个Field将在Delete时设置为当前时间,并且当前记录不删除 |
| version | 这个Field将会在insert时默认为1,每次更新自动加1 |
| default 0或default(0) | 设置默认值,紧跟的内容如果是Varchar等需要加上单引号 |
| json | 表示内容将先转成Json格式,然后存储到数据库中,数据库中的字段类型可以为Text或者二进制 |
| comment | 设置字段的注释(当前仅支持mysql) |
另外有如下几条自动映射的规则:
- 1.如果field名称为
Id而且类型为int64并且没有定义tag,则会被xorm视为主键,并且拥有自增属性。如果想用Id以外的名字或非int64类型做为主键名,必须在对应的Tag上加上xorm:"pk"来定义主键,加上xorm:"autoincr"作为自增。这里需要注意的是,有些数据库并不允许非主键的自增属性。 - 2.string类型默认映射为
varchar(255),如果需要不同的定义,可以在tag中自定义,如:varchar(1024) - 3.支持
type MyString string等自定义的field,支持Slice, Map等field成员,这些成员默认存储为Text类型,并且默认将使用Json格式来序列化和反序列化。也支持数据库字段类型为Blob类型。如果是Blob类型,则先使用Json格式序列化再转成[]byte格式。如果是[]byte或者[]uint8,则不做转换二十直接以二进制方式存储。具体参见 Go与字段类型对应表 - 4.实现了Conversion接口的类型或者结构体,将根据接口的转换方式在类型和数据库记录之间进行相互转换,这个接口的优先级是最高的。
type Conversion interface {
FromDB([]byte) error
ToDB() ([]byte, error)
}
- 5.如果一个结构体包含一个 Conversion 的接口类型,那么在获取数据时,必须要预先设置一个实现此接口的struct或者struct的指针。此时可以在此struct中实现
BeforeSet(name string, cell xorm.Cell)方法来进行预先给Conversion赋值。例子参见 testConversion
下表为xorm类型和各个数据库类型的对应表:
| xorm | mysql | sqlite3 | postgres | remark |
|---|---|---|---|---|
| BIT | BIT | INTEGER | BIT | |
| TINYINT | TINYINT | INTEGER | SMALLINT | |
| SMALLINT | SMALLINT | INTEGER | SMALLINT | |
| MEDIUMINT | MEDIUMINT | INTEGER | INTEGER | |
| INT | INT | INTEGER | INTEGER | |
| INTEGER | INTEGER | INTEGER | INTEGER | |
| BIGINT | BIGINT | INTEGER | BIGINT | |
| CHAR | CHAR | TEXT | CHAR | |
| VARCHAR | VARCHAR | TEXT | VARCHAR | |
| TINYTEXT | TINYTEXT | TEXT | TEXT | |
| TEXT | TEXT | TEXT | TEXT | |
| MEDIUMTEXT | MEDIUMTEXT | TEXT | TEXT | |
| LONGTEXT | LONGTEXT | TEXT | TEXT | |
| BINARY | BINARY | BLOB | BYTEA | |
| VARBINARY | VARBINARY | BLOB | BYTEA | |
| DATE | DATE | NUMERIC | DATE | |
| DATETIME | DATETIME | NUMERIC | TIMESTAMP | |
| TIME | TIME | NUMERIC | TIME | |
| TIMESTAMP | TIMESTAMP | NUMERIC | TIMESTAMP | |
| TIMESTAMPZ | TEXT | TEXT | TIMESTAMP with zone | timestamp with zone info |
| REAL | REAL | REAL | REAL | |
| FLOAT | FLOAT | REAL | REAL | |
| DOUBLE | DOUBLE | REAL | DOUBLE PRECISION | |
| DECIMAL | DECIMAL | NUMERIC | DECIMAL | |
| NUMERIC | NUMERIC | NUMERIC | NUMERIC | |
| TINYBLOB | TINYBLOB | BLOB | BYTEA | |
| BLOB | BLOB | BLOB | BYTEA | |
| MEDIUMBLOB | MEDIUMBLOB | BLOB | BYTEA | |
| LONGBLOB | LONGBLOB | BLOB | BYTEA | |
| BYTEA | BLOB | BLOB | BYTEA | |
| BOOL | TINYINT | INTEGER | BOOLEAN | |
| SERIAL | INT | INTEGER | SERIAL | auto increment |
| BIGSERIAL | BIGINT | INTEGER | BIGSERIAL | auto increment |
Go与字段类型对应表
如果不使用 tag 来定义 field 对应的数据库字段类型,那么系统会自动给出一个默认的字段类型,对应表如下:
| go type’s kind | value method | xorm type |
|---|---|---|
| implemented Conversion | Conversion.ToDB / Conversion.FromDB | Text |
| int, int8, int16, int32, uint, uint8, uint16, uint32 | Int | |
| int64, uint64 | BigInt | |
| float32 | Float | |
| float64 | Double | |
| complex64, complex128 | json.Marshal / json.UnMarshal | Varchar(64) |
| []uint8 | Blob | |
| array, slice, map except []uint8 | json.Marshal / json.UnMarshal | Text |
| bool | 1 or 0 | Bool |
| string | Varchar(255) | |
| time.Time | DateTime | |
| cascade struct | primary key field value | BigInt |
| struct | json.Marshal / json.UnMarshal | Text |
| Others | Text |
表结构操作
xorm 提供了一些动态获取和修改表结构的方法,通过这些方法可以动态同步数据库结构,导出数据库结构,导入数据库结构。
获取数据库信息
- DBMetas()
xorm支持获取表结构信息,通过调用 engine.DBMetas() 可以获取到数据库中所有的表,字段,索引的信息。
- TableInfo()
根据传入的结构体指针及其对应的Tag,提取出模型对应的表结构信息。这里不是数据库当前的表结构信息,而是我们通过struct建模时希望数据库的表的结构信息。
表操作
- CreateTables()
创建表使用engine.CreateTables(),参数为一个或多个空的对应Struct的指针。同时可用的方法有Charset()和StoreEngine(),如果对应的数据库支持,这两个方法可以在创建表时指定表的字符编码和使用的引擎。Charset()和StoreEngine()当前仅支持Mysql数据库。
- IsTableEmpty()
判断表是否为空,参数和CreateTables相同
- IsTableExist()
判断表是否存在
- DropTables()
删除表使用engine.DropTables(),参数为一个或多个空的对应Struct的指针或者表的名字。如果为string传入,则只删除对应的表,如果传入的为Struct,则删除表的同时还会删除对应的索引。
创建索引和唯一索引
- CreateIndexes
根据struct中的tag来创建索引
- CreateUniques
根据struct中的tag来创建唯一索引
同步数据库结构
同步能够部分智能的根据结构体的变动检测表结构的变动,并自动同步。目前有两个实现:
- Sync
Sync将进行如下的同步操作:
- 自动检测和创建表,这个检测是根据表的名字
- 自动检测和新增表中的字段,这个检测是根据字段名
- 自动检测和创建索引和唯一索引,这个检测是根据索引的一个或多个字段名,而不根据索引名称
调用方法如下:
err := engine.Sync(new(User), new(Group))
- Sync2
Sync2对Sync进行了改进,目前推荐使用Sync2。Sync2函数将进行如下的同步操作:
- 自动检测和创建表,这个检测是根据表的名字
- 自动检测和新增表中的字段,这个检测是根据字段名,同时对表中多余的字段给出警告信息
- 自动检测,创建和删除索引和唯一索引,这个检测是根据索引的一个或多个字段名,而不根据索引名称。因此这里需要注意,如果在一个有大量数据的表中引入新的索引,数据库可能需要一定的时间来建立索引。
- 自动转换varchar字段类型到text字段类型,自动警告其它字段类型在模型和数据库之间不一致的情况。
- 自动警告字段的默认值,是否为空信息在模型和数据库之间不匹配的情况
以上这些警告信息需要将engine.ShowWarn 设置为 true 才会显示。
调用方法和Sync一样:
err := engine.Sync2(new(User), new(Group))
导出导入SQL脚本
Dump数据库结构和数据
如果需要在程序中Dump数据库的结构和数据可以调用
engine.DumpAll(w io.Writer)
和
engine.DumpAllToFile(fpath string)。
DumpAll方法接收一个io.Writer接口来保存Dump出的数据库结构和数据的SQL语句,这个方法导出的SQL语句并不能通用。只针对当前engine所对应的数据库支持的SQL。
例如:
package main
import (
"fmt"
"os"
_ "github.com/go-sql-driver/mysql"
"xorm.io/xorm"
"xorm.io/xorm/log"
)
func main() {
engine, err := xorm.NewEngine("mysql", "root:123@/weblog?charset=utf8mb4")
if err != nil {
fmt.Println(err)
return
}
engine.ShowSQL(true)
engine.Logger().SetLevel(log.LOG_DEBUG)
f, err := os.Create("dump.sql")
if err != nil {
fmt.Println(err)
return
}
engine.DumpAll(f)
f.Close()
engine.Close()
}
Import 执行数据库SQL脚本
如果你需要将保存在文件或者其它存储设施中的SQL脚本执行,那么可以调用
engine.Import(r io.Reader)
和
engine.ImportFile(fpath string)
同样,这里需要对应的数据库的SQL语法支持。
插入数据
插入数据使用Insert方法,Insert方法的参数可以是一个或多个Struct的指针,一个或多个Struct的Slice的指针。
如果传入的是Slice并且当数据库支持批量插入时,Insert会使用批量插入的方式进行插入。
- 插入一条数据,此时可以用Insert或者InsertOne
user := new(User)
user.Name = "myname"
affected, err := engine.Insert(user)
// INSERT INTO user (name) values (?)
在插入单条数据成功后,如果该结构体有自增字段(设置为autoincr),则自增字段会被自动赋值为数据库中的id。这里需要注意的是,如果插入的结构体中,自增字段已经赋值,则该字段会被作为非自增字段插入。
fmt.Println(user.Id)
- 插入同一个表的多条数据,此时如果数据库支持批量插入,那么会进行批量插入,但是这样每条记录就无法被自动赋予id值。如果数据库不支持批量插入,那么就会一条一条插入。
users := make([]User, 1)
users[0].Name = "name0"
...
affected, err := engine.Insert(&users)
- 使用指针Slice插入多条记录,同上
users := make([]*User, 1)
users[0] = new(User)
users[0].Name = "name0"
...
affected, err := engine.Insert(&users)
- 插入多条记录并且不使用批量插入,此时实际生成多条插入语句,每条记录均会自动赋予Id值。
users := make([]*User, 1)
users[0] = new(User)
users[0].Name = "name0"
...
affected, err := engine.Insert(users)
- 插入不同表的一条记录
user := new(User)
user.Name = "myname"
question := new(Question)
question.Content = "whywhywhwy?"
affected, err := engine.Insert(user, question)
- 插入不同表的多条记录
users := make([]User, 1)
users[0].Name = "name0"
...
questions := make([]Question, 1)
questions[0].Content = "whywhywhwy?"
affected, err := engine.Insert(&users, &questions)
- 插入不同表的一条或多条记录
user := new(User)
user.Name = "myname"
...
questions := make([]Question, 1)
questions[0].Content = "whywhywhwy?"
affected, err := engine.Insert(user, &questions)
这里需要注意以下几点:
- 这里虽然支持同时插入,但这些插入并没有事务关系。因此有可能在中间插入出错后,后面的插入将不会继续。此时前面的插入已经成功,如果需要回滚,请开启事务。
- 批量插入会自动生成
Insert into table values (),(),()的语句,因此各个数据库对SQL语句有长度限制,因此这样的语句有一个最大的记录数,根据经验测算在150条左右。大于150条后,生成的sql语句将太长可能导致执行失败。因此在插入大量数据时,目前需要自行分割成每150条插入一次。
创建时间Created
Created可以让您在数据插入到数据库时自动将对应的字段设置为当前时间,需要在xorm标记中使用created标记,如下所示进行标记,对应的字段可以为time.Time或者自定义的time.Time或者int,int64等int类型。
type User struct {
Id int64
Name string
CreatedAt time.Time `xorm:"created"`
}
或
type JsonTime time.Time
func (j JsonTime) MarshalJSON() ([]byte, error) {
return []byte(`"`+time.Time(j).Format("2006-01-02 15:04:05")+`"`), nil
}
type User struct {
Id int64
Name string
CreatedAt JsonTime `xorm:"created"`
}
或
type User struct {
Id int64
Name string
CreatedAt int64 `xorm:"created"`
}
在Insert()或InsertOne()方法被调用时,created标记的字段将会被自动更新为当前时间或者当前时间的秒数(对应为time.Unix()),如下所示:
var user User
engine.Insert(&user)
// INSERT user (created...) VALUES (?...)
最后一个值得注意的是时区问题,默认xorm采用Local时区,所以默认调用的time.Now()会先被转换成对应的时区。要改变xorm的时区,可以使用:
engine.TZLocation, _ = time.LoadLocation("Asia/Shanghai")
查询和统计数据
所有的查询条件不区分调用顺序,但必须在调用Get,Exist, Sum, Find,Count, Iterate, Rows这几个函数之前调用。同时需要注意的一点是,在调用的参数中,如果采用默认的SnakeMapper所有的字符字段名均为映射后的数据库的字段名,而不是field的名字。
查询条件方法
查询和统计主要使用Get, Find, Count, Rows, Iterate这几个方法,同时大部分函数在调用Update, Delete时也是可用的。在进行查询时可以使用多个方法来形成查询条件,条件函数如下:
- Alias(string)
给Table设定一个别名
engine.Alias("o").Where("o.name = ?", name).Get(&order)
- And(string, …interface{})
和Where函数中的条件基本相同,作为条件
engine.Where(...).And(...).Get(&order)
- Asc(…string)
指定字段名正序排序,可以组合
engine.Asc("id").Find(&orders)
- Desc(…string)
指定字段名逆序排序,可以组合
engine.Asc("id").Desc("time").Find(&orders)
- ID(interface{})
传入一个主键字段的值,作为查询条件,如
var user User
engine.ID(1).Get(&user)
// SELECT * FROM user Where id = 1
如果是复合主键,则可以
engine.ID(schemas.PK{1, "name"}).Get(&user)
// SELECT * FROM user Where id =1 AND name= 'name'
传入的两个参数按照struct中pk标记字段出现的顺序赋值。
- Or(interface{}, …interface{})
和Where函数中的条件基本相同,作为条件
- OrderBy(string)
按照指定的顺序进行排序
- Select(string)
指定select语句的字段部分内容,例如:
engine.Select("a.*, (select name from b limit 1) as name").Find(&beans)
engine.Select("a.*, (select name from b limit 1) as name").Get(&bean)
- SQL(string, …interface{})
执行指定的Sql语句,并把结果映射到结构体。有时,当选择内容或者条件比较复杂时,可以直接使用Sql,例如:
engine.SQL("select * from table").Find(&beans)
- Where(string, …interface{})
和SQL中Where语句中的条件基本相同,作为条件
engine.Where("a = ? AND b = ?", 1, 2).Find(&beans)
engine.Where(builder.Eq{"a":1, "b": 2}).Find(&beans)
engine.Where(builder.Eq{"a":1}.Or(builder.Eq{"b": 2})).Find(&beans)
- In(string, …interface{})
某字段在一些值中,这里需要注意必须是[]interface{}才可以展开,由于Go语言的限制,[]int64等不可以直接展开,而是通过传递一个slice。第二个参数也可以是一个*builder.Builder 指针。示例代码如下:
// select from table where column in (1,2,3)
engine.In("cloumn", 1, 2, 3).Find()
// select from table where column in (1,2,3)
engine.In("column", []int{1, 2, 3}).Find()
// select from table where column in (select column from table2 where a = 1)
engine.In("column", builder.Select("column").From("table2").Where(builder.Eq{"a":1})).Find()
- Cols(…string)
只查询或更新某些指定的字段,默认是查询所有映射的字段或者根据Update的第一个参数来判断更新的字段。例如:
engine.Cols("age", "name").Get(&usr)
// SELECT age, name FROM user limit 1
engine.Cols("age", "name").Find(&users)
// SELECT age, name FROM user
engine.Cols("age", "name").Update(&user)
// UPDATE user SET age=? AND name=?
- AllCols()
查询或更新所有字段,一般与Update配合使用,因为默认Update只更新非0,非"",非bool的字段。
engine.AllCols().ID(1).Update(&user)
// UPDATE user SET name = ?, age =?, gender =? WHERE id = 1
- MustCols(…string)
某些字段必须更新,一般与Update配合使用。
- Omit(…string)
和cols相反,此函数指定排除某些指定的字段。注意:此方法和Cols方法不可同时使用。
// 例1:
engine.Omit("age", "gender").Update(&user)
// UPDATE user SET name = ? AND department = ?
// 例2:
engine.Omit("age, gender").Insert(&user)
// INSERT INTO user (name) values (?) // 这样的话age和gender会给默认值
// 例3:
engine.Omit("age", "gender").Find(&users)
// SELECT name FROM user //只select除age和gender字段的其它字段
- Distinct(…string)
按照参数中指定的字段归类结果。
engine.Distinct("age", "department").Find(&users)
// SELECT DISTINCT age, department FROM user
注意:当开启了缓存时,此方法的调用将在当前查询中禁用缓存。因为缓存系统当前依赖Id,而此时无法获得Id
- Table(nameOrStructPtr interface{})
传入表名称或者结构体指针,如果传入的是结构体指针,则按照IMapper的规则提取出表名
- Limit(int, …int)
限制获取的数目,第一个参数为条数,第二个参数表示开始位置,如果不传则为0
- Top(int)
相当于Limit(int, 0)
- Join(string,interface{},string)
第一个参数为连接类型,当前支持INNER, LEFT OUTER, CROSS中的一个值, 第二个参数为string类型的表名,表对应的结构体指针或者为两个值的[]string,表示表名和别名, 第三个参数为连接条件
- GroupBy(string)
Groupby的参数字符串
- Having(string)
Having的参数字符串
临时开关方法
- NoAutoTime()
如果此方法执行,则此次生成的语句中Created和Updated字段将不自动赋值为当前时间
- NoCache()
如果此方法执行,则此次生成的语句则在非缓存模式下执行
- NoAutoCondition()
禁用自动根据结构体中的值来生成条件
engine.Where("name = ?", "lunny").Get(&User{Id:1})
// SELECT * FROM user where name='lunny' AND id = 1 LIMIT 1
engine.Where("name = ?", "lunny").NoAutoCondition().Get(&User{Id:1})
// SELECT * FROM user where name='lunny' LIMIT 1
- UseBool(…string)
当从一个struct来生成查询条件或更新字段时,xorm会判断struct的field是否为0,“”,nil,如果为以上则不当做查询条件或者更新内容。因为bool类型只有true和false两种值,因此默认所有bool类型不会作为查询条件或者更新字段。如果可以使用此方法,如果默认不传参数,则所有的bool字段都将会被使用,如果参数不为空,则参数中指定的为字段名,则这些字段对应的bool值将被使用。
- NoCascade()
是否自动关联查询field中的数据,如果struct的field也是一个struct并且映射为某个Id,则可以在查询时自动调用Get方法查询出对应的数据。
Get方法
查询单条数据使用Get方法,在调用Get方法时需要传入一个对应结构体的指针,同时结构体中的非空field自动成为查询的条件和前面的方法条件组合在一起查询。
如:
- 根据Id来获得单条数据:
user := new(User)
has, err := engine.ID(id).Get(user)
// 复合主键的获取方法
// has, errr := engine.ID(xorm.PK{1,2}).Get(user)
- 根据Where来获得单条数据:
user := new(User)
has, err := engine.Where("name=?", "xlw").Get(user)
- 根据user结构体中已有的非空数据来获得单条数据:
user := &User{Id:1}
has, err := engine.Get(user)
或者其它条件
user := &User{Name:"xlw"}
has, err := engine.Get(user)
返回的结果为两个参数,一个has为该条记录是否存在,第二个参数err为是否有错误。不管err是否为nil,has都有可能为true或者false。
Find方法
查询多条数据使用Find方法,Find方法的第一个参数为slice的指针或Map指针,即为查询后返回的结果,第二个参数可选,为查询的条件struct的指针。
- 传入Slice用于返回数据
everyone := make([]Userinfo, 0)
err := engine.Find(&everyone)
pEveryOne := make([]*Userinfo, 0)
err := engine.Find(&pEveryOne)
- 传入Map用户返回数据,map必须为
map[int64]Userinfo的形式,map的key为id,因此对于复合主键无法使用这种方式。
users := make(map[int64]Userinfo)
err := engine.Find(&users)
pUsers := make(map[int64]*Userinfo)
err := engine.Find(&pUsers)
- 也可以加入各种条件
users := make([]Userinfo, 0)
err := engine.Where("age > ? or name = ?", 30, "xlw").Limit(20, 10).Find(&users)
- 如果只选择单个字段,也可使用非结构体的Slice
var ints []int64
err := engine.Table("user").Cols("id").Find(&ints)
Count方法
统计数据使用Count方法,Count方法的参数为struct的指针并且成为查询条件。
user := new(User)
total, err := engine.Where("id >?", 1).Count(user)
Exist系列方法
判断某个记录是否存在可以使用Exist, 相比Get,Exist性能更好。
has, err := testEngine.Exist(new(RecordExist))
// SELECT * FROM record_exist LIMIT 1
has, err = testEngine.Exist(&RecordExist{
Name: "test1",
})
// SELECT * FROM record_exist WHERE name = ? LIMIT 1
has, err = testEngine.Where("name = ?", "test1").Exist(&RecordExist{})
// SELECT * FROM record_exist WHERE name = ? LIMIT 1
has, err = testEngine.SQL("select * from record_exist where name = ?", "test1").Exist()
// select * from record_exist where name = ?
has, err = testEngine.Table("record_exist").Exist()
// SELECT * FROM record_exist LIMIT 1
has, err = testEngine.Table("record_exist").Where("name = ?", "test1").Exist()
// SELECT * FROM record_exist WHERE name = ? LIMIT 1
与Get的区别
Get与Exist方法返回值都为bool和error,如果查询到实体存在,则Get方法会将查到的实体赋值给参数
user := &User{Id:1}
has,err := testEngine.Get(user) // 执行结束后,user会被赋值为数据库中Id为1的实体
has,err = testEngine.Exist(user) // user中仍然是初始声明的user,不做改变
建议
如果你的需求是:判断某条记录是否存在,若存在,则返回这条记录。
建议直接使用Get方法。
如果仅仅判断某条记录是否存在,则使用Exist方法,Exist的执行效率要比Get更高。
Iterate方法
Iterate方法提供逐条执行查询到的记录的方法,它所能使用的条件和Find方法完全相同
err := engine.Where("age > ? or name=?)", 30, "xlw").Iterate(new(Userinfo), func(i int, bean interface{})error{
user := bean.(*Userinfo)
//do somthing use i and user
})
Join的使用
- Join(string,interface{},string)
第一个参数为连接类型,当前支持INNER, LEFT OUTER, CROSS中的一个值, 第二个参数为string类型的表名,表对应的结构体指针或者为两个值的[]string,表示表名和别名, 第三个参数为连接条件。
以下将通过示例来讲解具体的用法:
假如我们拥有两个表user和group,每个User只在一个Group中,那么我们可以定义对应的struct
type Group struct {
Id int64
Name string
}
type User struct {
Id int64
Name string
GroupId int64 `xorm:"index"`
}
问题来了,我们现在需要列出所有的User,并且列出对应的GroupName。利用extends和Join我们可以比较优雅的解决这个问题。代码如下:
type UserGroup struct {
User `xorm:"extends"`
Name string
}
func (UserGroup) TableName() string {
return "user"
}
users := make([]UserGroup, 0)
engine.Join("INNER", "group", "group.id = user.group_id").Find(&users)
这里我们将User这个匿名结构体加了xorm的extends标记(实际上也可以是非匿名的结构体,只要有extends标记即可),这样就减少了重复代码的书写。实际上这里我们直接用Sql函数也是可以的,并不一定非要用Join。
users := make([]UserGroup, 0)
engine.Sql("select user.*, group.name from user, group where user.group_id = group.id").Find(&users)
然后,我们忽然发现,我们还需要显示Group的Id,因为我们需要链接到Group页面。这样又要加一个字段,算了,不如我们把Group也加个extends标记吧,代码如下:
type UserGroup struct {
User `xorm:"extends"`
Group `xorm:"extends"`
}
func (UserGroup) TableName() string {
return "user"
}
users := make([]UserGroup, 0)
engine.Join("INNER", "group", "group.id = user.group_id").Find(&users)
这次,我们把两个表的所有字段都查询出来了,并且赋值到对应的结构体上了。
这里要注意,User和Group分别有Id和Name,这个是重名的,但是xorm是可以区分开来的,不过需要特别注意UserGroup中User和Group的顺序,如果顺序反了,则有可能会赋值错误,但是程序不会报错。
这里的顺序应遵循如下原则:
结构体中extends标记对应的结构顺序应和最终生成SQL中对应的表出现的顺序相同。
还有一点需要注意的,如果在模板中使用这个UserGroup结构体,对于字段名重复的必须加匿名引用,如:
对于不重复字段,可以{{.GroupId}},对于重复字段{{.User.Id}}和{{.Group.Id}}
这是2个表的用法,3个或更多表用法类似,如:
type Type struct {
Id int64
Name string
}
type UserGroupType struct {
User `xorm:"extends"`
Group `xorm:"extends"`
Type `xorm:"extends"`
}
users := make([]UserGroupType, 0)
engine.Table("user").Join("INNER", "group", "group.id = user.group_id").
Join("INNER", "type", "type.id = user.type_id").
Find(&users)
同时,在使用Join时,也可同时使用Where和Find的第二个参数作为条件,Find的第二个参数同时也允许为各种bean来作为条件。Where里可以是各个表的条件,Find的第二个参数只是被关联表的条件。
engine.Table("user").Join("INNER", "group", "group.id = user.group_id").
Join("INNER", "type", "type.id = user.type_id").
Where("user.name like ?", "%"+name+"%").Find(&users, &User{Name:name})
当然,如果表名字太长,我们可以使用别名:
engine.Table("user").Alias("u").
Join("INNER", []string{"group", "g"}, "g.id = u.group_id").
Join("INNER", "type", "type.id = u.type_id").
Where("u.name like ?", "%"+name+"%").Find(&users, &User{Name:name})
Rows方法
Rows方法和Iterate方法类似,提供逐条执行查询到的记录的方法,不过Rows更加灵活好用。
user := new(User)
rows, err := engine.Where("id >?", 1).Rows(user)
if err != nil {
}
defer rows.Close()
for rows.Next() {
err = rows.Scan(user)
//...
}
Sum系列方法
求和数据可以使用Sum, SumInt, Sums 和 SumsInt 四个方法,Sums系列方法的参数为struct的指针并且成为查询条件。
- Sum 求某个字段的和,返回float64
type SumStruct struct {
Id int64
Money int
Rate float32
}
ss := new(SumStruct)
total, err := engine.Where("id >?", 1).Sum(ss, "money")
fmt.Printf("money is %d", int(total))
- SumInt 求某个字段的和,返回int64
type SumStruct struct {
Id int64
Money int
Rate float32
}
ss := new(SumStruct)
total, err := engine.Where("id >?", 1).SumInt(ss, "money")
fmt.Printf("money is %d", total)
- Sums 求某几个字段的和, 返回float64的Slice
ss := new(SumStruct)
totals, err := engine.Where("id >?", 1).Sums(ss, "money", "rate")
fmt.Printf("money is %d, rate is %.2f", int(total[0]), total[1])
- SumsInt 求某几个字段的和, 返回int64的Slice
ss := new(SumStruct)
totals, err := engine.Where("id >?", 1).SumsInt(ss, "money")
fmt.Printf("money is %d", total[0])
更新数据
更新数据使用Update方法,Update方法的第一个参数为需要更新的内容,可以为一个结构体指针或者一个Map[string]interface{}类型。当传入的为结构体指针时,只有非空和0的field才会被作为更新的字段。当传入的为Map类型时,key为数据库Column的名字,value为要更新的内容。
Update方法将返回两个参数,第一个为 更新的记录数,需要注意的是 SQLITE 数据库返回的是根据更新条件查询的记录数而不是真正受更新的记录数。
user := new(User)
user.Name = "myname"
affected, err := engine.ID(id).Update(user)
这里需要注意,Update会自动从user结构体中提取非0和非nil得值作为需要更新的内容,因此,如果需要更新一个值为0,则此种方法将无法实现,因此有两种选择:
- 通过添加Cols函数指定需要更新结构体中的哪些值,未指定的将不更新,指定了的即使为0也会更新。
affected, err := engine.ID(id).Cols("age").Update(&user)
- 通过传入map[string]interface{}来进行更新,但这时需要额外指定更新到哪个表,因为通过map是无法自动检测更新哪个表的。
affected, err := engine.Table(new(User)).ID(id).Update(map[string]interface{}{"age":0})
有时候希望能够指定必须更新某些字段,而其它字段根据值的情况自动判断,可以使用 MustCols 来组合 Update 使用。
affected, err := engine.ID(id).MustCols("age").Update(&user)
另外,如果需要更新所有的字段,可以使用 AllCols()。
affected, err := engine.ID(id).AllCols().Update(&user)
乐观锁Version
要使用乐观锁,需要使用version标记
type User struct {
Id int64
Name string
Version int `xorm:"version"`
}
在Insert时,version标记的字段将会被设置为1,在Update时,Update的内容必须包含version原来的值。
var user User
engine.ID(1).Get(&user)
// SELECT * FROM user WHERE id = ?
engine.ID(1).Update(&user)
// UPDATE user SET ..., version = version + 1 WHERE id = ? AND version = ?
更新时间Updated
Updated可以让您在记录插入或每次记录更新时自动更新数据库中的标记字段为当前时间,需要在xorm标记中使用updated标记,如下所示进行标记,对应的字段可以为time.Time或者自定义的time.Time或者int,int64等int类型。
type User struct {
Id int64
Name string
UpdatedAt time.Time `xorm:"updated"`
}
在Insert(), InsertOne(), Update()方法被调用时,updated标记的字段将会被自动更新为当前时间,如下所示:
var user User
engine.ID(1).Get(&user)
// SELECT * FROM user WHERE id = ?
engine.ID(1).Update(&user)
// UPDATE user SET ..., updaetd_at = ? WHERE id = ?
如果你希望临时不自动插入时间,则可以组合NoAutoTime()方法:
engine.NoAutoTime().Insert(&user)
这个在从一张表拷贝字段到另一张表时比较有用。
删除数据
删除数据用 Delete方法,参数为struct的指针并且成为查询条件。
user := new(User)
affected, err := engine.ID(id).Delete(user)
Delete的返回值第一个参数为删除的记录数,第二个参数为错误。
注意1:
当删除时,如果user中包含有bool,float64或者float32类型,有可能会使删除失败。
注意2:必须至少包含一个条件才能够进行删除,这意味着直接用
engine.Delete(new(User))
将会报一个保护性的错误,如果你真的希望将整个表删除,你可以
engine.Where("1=1").Delete(new(User))
软删除Deleted
Deleted可以让您不真正的删除数据,而是标记一个删除时间。使用此特性需要在xorm标记中使用deleted标记,如下所示进行标记,对应的字段可以为time.Time, type MyTime time.Time,int 或者 int64类型。
type User struct {
Id int64
Name string
DeletedAt time.Time `xorm:"deleted"`
}
在Delete()时,deleted标记的字段将会被自动更新为当前时间而不是去删除该条记录,如下所示:
var user User
engine.ID(1).Get(&user)
// SELECT * FROM user WHERE id = ?
engine.ID(1).Delete(&user)
// UPDATE user SET ..., deleted_at = ? WHERE id = ?
engine.ID(1).Get(&user)
// 再次调用Get,此时将返回false, nil,即记录不存在
engine.ID(1).Delete(&user)
// 再次调用删除会返回0, nil,即记录不存在
那么如果记录已经被标记为删除后,要真正的获得该条记录或者真正的删除该条记录,需要启用Unscoped,如下所示:
var user User
engine.ID(1).Unscoped().Get(&user)
// 此时将可以获得记录
engine.ID(1).Unscoped().Delete(&user)
// 此时将可以真正的删除记录
执行SQL查询
Query
也可以直接执行一个SQL查询,即Select命令。在Postgres中支持原始SQL语句中使用 ` 和 ? 符号。
sql := "select * from userinfo"
results, err := engine.Query(sql)
当调用 Query 时,第一个返回值 results 为 []map[string][]byte 的形式。
Query 的参数也允许传入 *builder.Buidler 对象
// SELECT * FROM table
results, err := engine.Query(builder.Select("*").From("table"))
QueryInterface
和 Query 类似,但是返回值为 []map[string]interface{}
QueryString
和 Query 类似,但是返回值为 []map[string]string
执行SQL命令
也可以直接执行一个SQL命令,即执行Insert, Update, Delete 等操作。此时不管数据库是何种类型,都可以使用 ` 和 ? 符号。
sql = "update `userinfo` set username=? where id=?"
res, err := engine.Exec(sql, "xiaolun", 1)
事务处理
当使用事务处理时,需要创建 Session 对象。在进行事务处理时,可以混用 ORM 方法和 RAW 方法,如下代码所示:
func MyTransactionOps() error {
session := engine.NewSession()
defer session.Close()
// add Begin() before any action
if err := session.Begin(); err != nil {
return err
}
user1 := Userinfo{Username: "xiaoxiao", Departname: "dev", Alias: "lunny", Created: time.Now()}
if _, err := session.Insert(&user1); err != nil {
return err
}
user2 := Userinfo{Username: "yyy"}
if _, err = session.Where("id = ?", 2).Update(&user2); err != nil {
return err
}
if _, err = session.Exec("delete from userinfo where username = ?", user2.Username); err != nil {
return err
}
// add Commit() after all actions
return session.Commit()
}
- 注意如果您使用的是 mysql,数据库引擎为 innodb 事务才有效,myisam 引擎是不支持事务的。
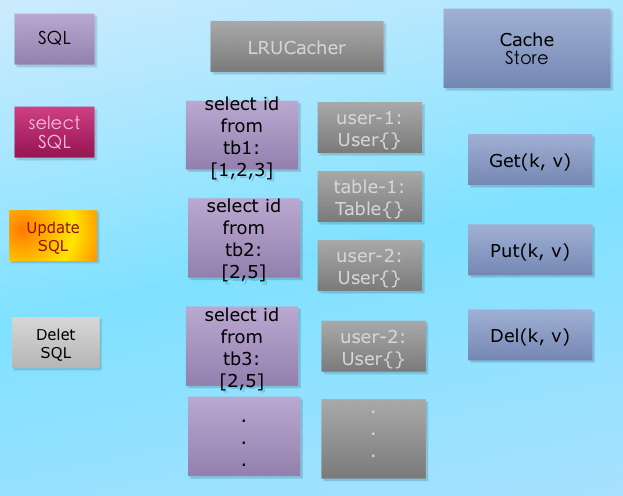
缓存
xorm 内置了一致性缓存支持,不过默认并没有开启。要开启缓存,需要在 engine 创建完后进行配置。缓存相关的 内容存放在 xorm.io/xorm/caches 这个包中:
启用一个全局的内存缓存
cacher := caches.NewLRUCacher(caches.NewMemoryStore(), 1000)
engine.SetDefaultCacher(cacher)
上述代码采用了LRU算法的一个缓存,缓存方式是存放到内存中,缓存struct的记录数为1000条,缓存针对的范围是所有具有主键的表,没有主键的表中的数据将不会被缓存。 如果只想针对部分表,则:
cacher := caches.NewLRUCacher(caches.NewMemoryStore(), 1000)
engine.MapCacher(&user, cacher)
如果要禁用某个表的缓存,则:
engine.MapCacher(&user, nil)
设置完之后,其它代码基本上就不需要改动了,缓存系统已经在后台运行。
当前实现了内存存储的CacheStore接口MemoryStore,如果需要采用其它设备存储,可以实现CacheStore接口。
不过需要特别注意不适用缓存或者需要手动编码的地方:
- 当使用了
Distinct,Having,GroupBy方法将不会使用缓存 - 在
Get或者Find时使用了Cols,Omit方法,则在开启缓存后此方法无效,系统仍旧会取出这个表中的所有字段。 - 在使用Exec方法执行了方法之后,可能会导致缓存与数据库不一致的地方。因此如果启用缓存,尽量避免使用Exec。如果必须使用,则需要在使用了Exec之后调用ClearCache手动做缓存清除的工作。比如:
engine.Exec("update user set name = ? where id = ?", "xlw", 1)
engine.ClearCache(new(User))
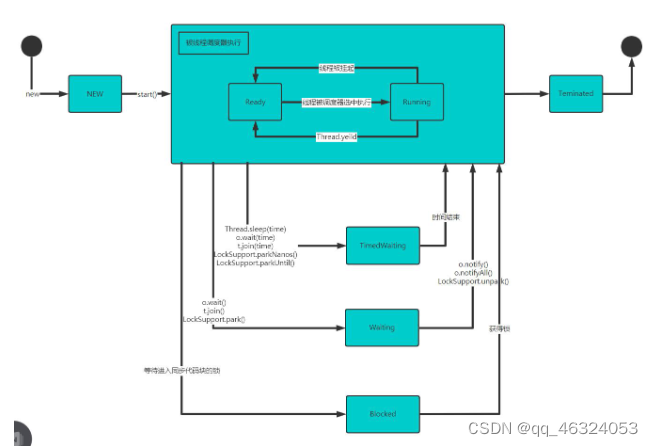
缓存的实现原理如下图所示:
事件
xorm 支持两种方式的事件,一种是在 Struct中的特定方法来作为事件的方法,一种是在执行语句的过程中执行事件。
在Struct中作为成员方法的事件如下:
BeforeInsert()
在将此struct插入到数据库之前执行
BeforeUpdate()
在将此struct更新到数据库之前执行
BeforeDelete()
在将此struct对应的条件数据从数据库删除之前执行
func BeforeSet(name string, cell xorm.Cell)
在 Get 或 Find 方法中,当数据已经从数据库查询出来,而在设置到结构体之前调用,name为数据库字段名称,cell为数据库中的字段值。
func AfterSet(name string, cell xorm.Cell)
在 Get 或 Find 方法中,当数据已经从数据库查询出来,而在设置到结构体之后调用,name为数据库字段名称,cell为数据库中的字段值。
AfterLoad()
在 Get 或 Find 方法中,当数据已经从数据库查询出来,而在设置到结构体之后调用。
AfterLoad(*xorm.Session)
在 Get 或 Find 方法中,当数据已经从数据库查询出来,而在设置到结构体之后调用,并传递xorm.Session参数。
AfterInsert()
在将此struct成功插入到数据库之后执行
AfterUpdate()
在将此struct成功更新到数据库之后执行
AfterDelete()
在将此struct对应的条件数据成功从数据库删除之后执行
在语句执行过程中的事件方法为:
Before(beforeFunc interface{})
临时执行某个方法之前执行
before := func(bean interface{}){
fmt.Println("before", bean)
}
engine.Before(before).Insert(&obj)
- After(afterFunc interface{})
临时执行某个方法之后执行
after := func(bean interface{}){
fmt.Println("after", bean)
}
engine.After(after).Insert(&obj)
其中beforeFunc和afterFunc的原型为func(bean interface{}).
Builder
Builder 是一个 XORM 内置的轻量级快速 SQL 构建引擎。
请注意此包为独立安装,请确保你的 Go 版本在 1.8+ 以上可以如下安装。
go get xorm.io/builder
Insert
sql, args, err := builder.Insert(Eq{"c": 1, "d": 2}).Into("table1").ToSQL()
// INSERT INTO table1 SELECT * FROM table2
sql, err := builder.Insert().Into("table1").Select().From("table2").ToBoundSQL()
// INSERT INTO table1 (a, b) SELECT b, c FROM table2
sql, err = builder.Insert("a, b").Into("table1").Select("b, c").From("table2").ToBoundSQL()
Select
// Simple Query
sql, args, err := Select("c, d").From("table1").Where(Eq{"a": 1}).ToSQL()
// With join
sql, args, err = Select("c, d").From("table1").LeftJoin("table2", Eq{"table1.id": 1}.And(Lt{"table2.id": 3})).
RightJoin("table3", "table2.id = table3.tid").Where(Eq{"a": 1}).ToSQL()
// From sub query
sql, args, err := Select("sub.id").From(Select("c").From("table1").Where(Eq{"a": 1}), "sub").Where(Eq{"b": 1}).ToSQL()
// From union query
sql, args, err = Select("sub.id").From(
Select("id").From("table1").Where(Eq{"a": 1}).Union("all", Select("id").From("table1").Where(Eq{"a": 2})),"sub").
Where(Eq{"b": 1}).ToSQL()
// With order by
sql, args, err = Select("a", "b", "c").From("table1").Where(Eq{"f1": "v1", "f2": "v2"}).
OrderBy("a ASC").ToSQL()
// With limit.
// Be careful! You should set up specific dialect for builder before performing a query with LIMIT
sql, args, err = Dialect(MYSQL).Select("a", "b", "c").From("table1").OrderBy("a ASC").
Limit(5, 10).ToSQL()
Update
sql, args, err := Update(Eq{"a": 2}).From("table1").Where(Eq{"a": 1}).ToSQL()
Delete
sql, args, err := Delete(Eq{"a": 1}).From("table1").ToSQL()
Union
sql, args, err := Select("*").From("a").Where(Eq{"status": "1"}).
Union("all", Select("*").From("a").Where(Eq{"status": "2"})).
Union("distinct", Select("*").From("a").Where(Eq{"status": "3"})).
Union("", Select("*").From("a").Where(Eq{"status": "4"})).
ToSQL()
Conditions
Eqis a redefine of a map, you can give one or more conditions toEq
import . "xorm.io/builder"
sql, args, _ := ToSQL(Eq{"a":1})
// a=? [1]
sql, args, _ := ToSQL(Eq{"b":"c"}.And(Eq{"c": 0}))
// b=? AND c=? ["c", 0]
sql, args, _ := ToSQL(Eq{"b":"c", "c":0})
// b=? AND c=? ["c", 0]
sql, args, _ := ToSQL(Eq{"b":"c"}.Or(Eq{"b":"d"}))
// b=? OR b=? ["c", "d"]
sql, args, _ := ToSQL(Eq{"b": []string{"c", "d"}})
// b IN (?,?) ["c", "d"]
sql, args, _ := ToSQL(Eq{"b": 1, "c":[]int{2, 3}})
// b=? AND c IN (?,?) [1, 2, 3]
Neqis the same toEq
import . "xorm.io/builder"
sql, args, _ := ToSQL(Neq{"a":1})
// a<>? [1]
sql, args, _ := ToSQL(Neq{"b":"c"}.And(Neq{"c": 0}))
// b<>? AND c<>? ["c", 0]
sql, args, _ := ToSQL(Neq{"b":"c", "c":0})
// b<>? AND c<>? ["c", 0]
sql, args, _ := ToSQL(Neq{"b":"c"}.Or(Neq{"b":"d"}))
// b<>? OR b<>? ["c", "d"]
sql, args, _ := ToSQL(Neq{"b": []string{"c", "d"}})
// b NOT IN (?,?) ["c", "d"]
sql, args, _ := ToSQL(Neq{"b": 1, "c":[]int{2, 3}})
// b<>? AND c NOT IN (?,?) [1, 2, 3]
Gt,Gte,Lt,Lte
import . "xorm.io/builder"
sql, args, _ := ToSQL(Gt{"a", 1}.And(Gte{"b", 2}))
// a>? AND b>=? [1, 2]
sql, args, _ := ToSQL(Lt{"a", 1}.Or(Lte{"b", 2}))
// a<? OR b<=? [1, 2]
Like
import . "xorm.io/builder"
sql, args, _ := ToSQL(Like{"a", "c"})
// a LIKE ? [%c%]
Expryou can customerize your sql withExpr
import . "xorm.io/builder"
sql, args, _ := ToSQL(Expr("a = ? ", 1))
// a = ? [1]
sql, args, _ := ToSQL(Eq{"a": Expr("select id from table where c = ?", 1)})
// a=(select id from table where c = ?) [1]
InandNotIn
import . "xorm.io/builder"
sql, args, _ := ToSQL(In("a", 1, 2, 3))
// a IN (?,?,?) [1,2,3]
sql, args, _ := ToSQL(In("a", []int{1, 2, 3}))
// a IN (?,?,?) [1,2,3]
sql, args, _ := ToSQL(NotIn("a", Expr("select id from b where c = ?", 1))))
// a NOT IN (select id from b where c = ?) [1]
ExistsandNotExists
import . "xorm.io/builder"
sql, args, _ := ToSQL(Exists(Select("a").From("table")))
// EXISTS (SELECT a FROM table)
sql, args, _ := ToSQL(NotExists(Select("a").From("table")))
// NOT EXISTS (SELECT a FROM table)
IsNullandNotNull
import . "xorm.io/builder"
sql, args, _ := ToSQL(IsNull{"a"})
// a IS NULL []
sql, args, _ := ToSQL(NotNull{"b"})
// b IS NOT NULL []
And(conds ...Cond), And can connect one or more conditions via And
import . "xorm.io/builder"
sql, args, _ := ToSQL(And(Eq{"a":1}, Like{"b", "c"}, Neq{"d", 2}))
// a=? AND b LIKE ? AND d<>? [1, %c%, 2]
Or(conds ...Cond), Or can connect one or more conditions via Or
import . "xorm.io/builder"
sql, args, _ := ToSQL(Or(Eq{"a":1}, Like{"b", "c"}, Neq{"d", 2}))
// a=? OR b LIKE ? OR d<>? [1, %c%, 2]
sql, args, _ := ToSQL(Or(Eq{"a":1}, And(Like{"b", "c"}, Neq{"d", 2})))
// a=? OR (b LIKE ? AND d<>?) [1, %c%, 2]
Between
import . "xorm.io/builder"
sql, args, _ := ToSQL(Between{"a", 1, 2})
// a BETWEEN 1 AND 2
- Define yourself conditions
Since Cond is an interface.
type Cond interface {
WriteTo(Writer) error
And(...Cond) Cond
Or(...Cond) Cond
IsValid() bool
}
You can define yourself conditions and compose with other Cond.




![[自动化测试] 读取CSV 文件](https://img-blog.csdnimg.cn/5d56cba78d64410eaf5279e6cde41f93.png)