一、回顾RocketMQ的消息模型
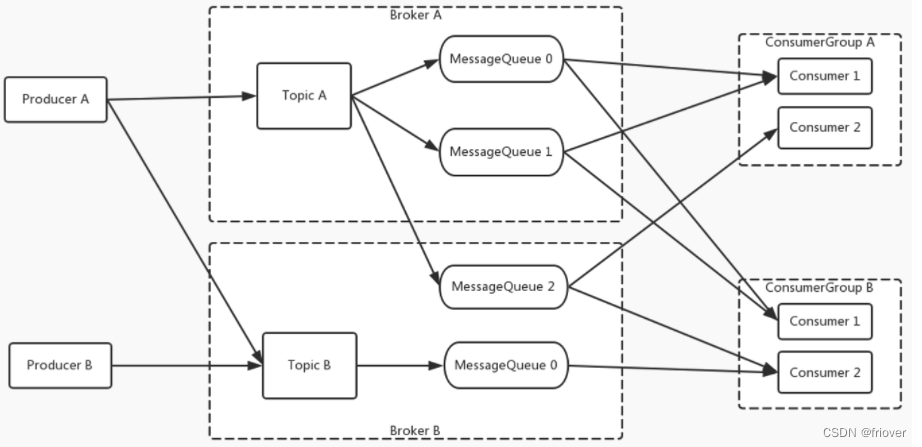
上一章节我们从试验整理出了RocketMQ的消息模型,这也是我们使用RocketMQ时最直接的指导。
二、深入理解RocketMQ的消息模型
1、RocketMQ客户端基本流程
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.5</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-acl</artifactId>
<version>4.9.5</version>
</dependency>
一个最为简单的消息生产者代码如下:
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
//初始化一个消息生产者
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
// 指定nameserver地址
producer.setNamesrvAddr("192.168.85.200:9876");
// 启动消息生产者服务
producer.start();
for (int i = 0; i < 2; i++) {
try {
// 创建消息。消息由Topic,Tag和body三个属性组成,其中Body就是消息内容
Message msg = new Message("TopicTest","TagA",("Hello RocketMQ " +i).getBytes(RemotingHelper.DEFAULT_CHARSET));
//发送消息,获取发送结果
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
Thread.sleep(1000);
}
}
//消息发送完后,停止消息生产者服务。
producer.shutdown();
}
}
一个简单的消息消费者代码如下:
public class Consumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
//构建一个消息消费者
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");
//指定nameserver地址
consumer.setNamesrvAddr("192.168.85.200:9876");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
// 订阅一个感兴趣的话题,这个话题需要与消息的topic一致
consumer.subscribe("TopicTest", "*");
// 注册一个消息回调函数,消费到消息后就会触发回调。
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,ConsumeConcurrentlyContext context) {
msgs.forEach(messageExt -> {
try {
System.out.println("收到消息:"+new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET));
} catch (UnsupportedEncodingException e) {}
});
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
//启动消费者服务
consumer.start();
System.out.print("Consumer Started");
}
}
- 消息生产者的固定步骤
1.创建消息生产者producer,并指定生产者组名
2.指定Nameserver地址
3.启动producer。 这个步骤比较容易忘记。可以认为这是消息生产者与服务端建立连接的过程。
4.创建消息对象,指定主题Topic、Tag和消息体
5.发送消息
6.关闭生产者producer,释放资源。 - 消息消费者的固定步骤
1.创建消费者Consumer,必须指定消费者组名
2.指定Nameserver地址
3.订阅主题Topic和Tag
4.设置回调函数,处理消息
5.启动消费者consumer。消费者会一直挂起,持续处理消息。
其中,最为关键的就是NameServer。从示例中可以看到,RocketMQ的客户端只需要指定NameServer地址,而不需要指定具体的Broker地址。
指定NameServer的方式有两种。可以在客户端直接指定,例如 consumer.setNameSrvAddr(“127.0.0.1:9876”)。然后,也可以通过读取系统环境变量NAMESRV_ADDR指定。其中第一种方式的优先级更高。
2、消息确认机制
RocketMQ要支持互联网金融场景,那么消息安全是必须优先保障的。而消息安全有两方面的要求,一方面是生产者要能确保将消息发送到Broker上。另一方面是消费者要能确保从Broker上争取获取到消息。
1、消息生产端采用消息确认加多次重试的机制保证消息正常发送到RocketMQ
针对消息发送的不确定性,封装了三种发送消息的方式。
第一种称为单向发送
单向发送方式下,消息生产者只管往Broker发送消息,而全然不关心Broker端有没有成功接收到消息。这就好比生产者向Broker发一封电子邮件,Broker有没有处理电子邮件,生产者并不知道。
public class OnewayProducer {
public static void main(String[] args)throws Exception{
DefaultMQProducer producer = new DefaultMQProducer("producerGroup");
producer.start();
Message message = new Message("Order","tag","order info : orderId = xxx".getBytes(StandardCharsets.UTF_8));
producer.sendOneway(message);
Thread.sleep(50000);
producer.shutdown();
}
}
sendOneway方法没有返回值,如果发送失败,生产者无法补救。
单向发送有一个好处,就是发送消息的效率更高。适用于一些追求消息发送效率,而允许消息丢失的业务场景。比如日志。
第二种称为同步发送
同步发送方式下,消息生产者在往Broker端发送消息后,会阻塞当前线程,等待Broker端的相应结果。这就好比生产者给Broker打了个电话。通话期间生产者就停下手头的事情,直到Broker明确表示消息处理成功了,生产者才继续做其他的事情。
SendResult sendResult = producer.send(msg);
SendResult来自于Broker的反馈。producer在send发出消息,到Broker返回SendResult的过程中,无法做其他的事情。
在SendResult中有一个SendStatus属性,这个SendStatus是一个枚举类型,其中包含了Broker端的各种情况
public enum SendStatus {
SEND_OK,
FLUSH_DISK_TIMEOUT,
FLUSH_SLAVE_TIMEOUT,
SLAVE_NOT_AVAILABLE,
}
在这几种枚举值中,SEND_OK表示消息已经成功发送到Broker上。至于其他几种枚举值,都是表示消息在Broker端处理失败了。使用同步发送的机制,我们就可以在消息生产者发送完消息后,对发送失败的消息进行补救。例如重新发送。
但是此时要注意,如果Broker端返回的SendStatus不是SEND_OK,也并不表示消息就一定不会推送给下游的消费者。仅仅只是表示Broker端并没有完全正确的处理这些消息。因此,如果要重新发送消息,最好要带上唯一的系统标识,这样在消费者端,才能自行做幂等判断。也就是用具有业务含义的OrderID这样的字段来判断消息有没有被重复处理。
这种同步发送的机制能够很大程度上保证消息发送的安全性。但是,这种同步发送机制的发送效率比较低。毕竟,send方法需要消息在生产者和Broker之间传输一个来回后才能结束。如果网速比较慢,同步发送的耗时就会很长。
第三种称为异步发送
异步发送机制下,生产者在向Broker发送消息时,会同时注册一个回调函数。接下来生产者并不等待Broker的响应。当Broker端有响应数据过来时,自动触发回调函数进行对应的处理。这就好比生产者向Broker发电子邮件通知时,另外找了一个代理人专门等待Broker的响应。而生产者自己则发完消息后就去做其他的事情去了。
producer.send(msg, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
countDownLatch.countDown();
System.out.printf("%-10d OK %s %n", index, sendResult.getMsgId());
}
@Override
public void onException(Throwable e) {
countDownLatch.countDown();
System.out.printf("%-10d Exception %s %n", index, e);
e.printStackTrace();
}
});
在SendCallback接口中有两个方法,onSuccess和onException。当Broker端返回消息处理成功的响应信息SendResult时,就会调用onSuccess方法。当Broker端处理消息超时或者失败时,就会调用onExcetion方法,生产者就可以在onException方法中进行补救措施。
此时同样有几个问题需要注意。一是与同步发送机制类似,触发了SendCallback的onException方法同样并不一定就表示消息不会向消费者推送。如果Broker端返回响应信息太慢,超过了超时时间,也会触发onException方法。超时时间默认是3秒,可以通过producer.setSendMsgTimeout方法定制。而造成超时的原因则有很多,消息太大造成网络拥堵、网速太慢、Broker端处理太慢等都可能造成消息处理超时。
二是在SendCallback的对应方法被触发之前,生产者不能调用shutdown()方法。如果消息处理完之前,生产者线程就关闭了,生产者的SendCallback对应方法就不会触发。这是因为使用异步发送机制后,生产者虽然不用阻塞下来等待Broker端响应,但是SendCallback还是需要附属于生产者的主线程才能执行。如果Broker端还没有返回SendResult,而生产者主线程已经停止了,那么SendCallback的执行线程也就会随主线程一起停止,对应的方法自然也就无法执行了。
这种异步发送的机制能够比较好的兼容消息的安全性以及生产者的高吞吐需求,是很多MQ产品都支持的方式。RabbitMQ和Kafka都支持这种异步发送的机制。但是异步发送机制也并不是万能的,毕竟异步发送机制对消息生产者的主线业务是有侵入的。具体使用时还是需要根据业务场景考虑。
RocketMQ提供的这三种发送消息的方式,并不存在绝对的好坏之分。我们更多的是需要根据业务场景进行选择。例如在电商下单这个场景,我们就应该尽量选择同步发送或异步发送,优先保证数据安全。然后,如果下单场景的并发比较高,业务比较繁忙,就应该尽量优先选择异步发送的机制。这时,我们就应该对下单服务的业务进行优化定制,尽量适应异步发送机制的要求。这样就可以尽量保证下单服务能够比较可靠的将用户的订单消息发送到RocketMQ了。
2、消息消费者端采用状态确认机制保证消费者一定能正常处理对应的消息
我们之前分析生产者的可靠性问题,核心的解决思路就是通过确认Broker端的状态来保证生产者发送消息的可靠性。对于RocketMQ的消费者来说,保证消息处理可靠性的思路也是类似的。只不过这次换成了Broker等待消费者返回消息处理状态。
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
这个返回值是一个枚举值,有两个选项 CONSUME_SUCCESS和RECONSUME_LATER。如果消费者返回CONSUME_SUCCESS,那么消息自然就处理结束了。但是如果消费者没有处理成功,返回的是RECONSUME_LATER,Broker就会过一段时间再发起消息重试。
为了要兼容重试机制的成功率和性能,RocketMQ设计了一套非常完善的消息重试机制,从而尽可能保证消费者能够正常处理用户的订单信息。
1、Broker不可能无限制的向消费失败的消费者推送消息。如果消费者一直没有恢复,Broker显然不可能一直无限制的推送,这会浪费集群很多的性能。所以,Broker会记录每一个消息的重试次数。如果一个消息经过很多次重试后,消费者依然无法正常处理,那么Broker会将这个消息推入到消费者组对应的死信Topic中。死信Topic相当于windows当中的垃圾桶。你可以人工介入对死信Topic中的消息进行补救,也可以直接彻底删除这些消息。RocketMQ默认的最大重试次数是16次。
2、为了让这些重试的消息不会影响Topic下其他正常的消息,Broker会给每个消费者组设计对应的重试Topic。MessageQueue是一个具有严格FIFO特性的数据结构。如果需要重试的这些消息还是放在原来的MessageQueue中,就会对当前MessageQueue产生阻塞,让其他正常的消息无法处理。RocketMQ的做法是给每个消费者组自动生成一个对应的重试Topic。在消息需要重试时,会先移动到对应的重试Topic中。后续Broker只要从这些重试Topic中不断拿出消息,往消费者组重新推送即可。这样,这些重试的消息有了自己单独的队列,就不会影响到Topic下的其他消息了。
3、RocketMQ中设定的消费者组都是订阅主题和消费逻辑相同的服务备份,所以当消息重试时,Broker只要往消费者组中随意一个实例推送即可。这是消息重试机制能够正常运行的基础。但是,在客户端的具体实现时,MQDefaultMQConsumer并没有强制规定消费者组不能重复。也就是说,你完全可以实现出一些订阅主题和消费逻辑完全不同的消费者服务,共同组成一个消费组。在这种情况下,RocketMQ不会报错,但是消息的处理逻辑就无法保持一致了。这会给业务带来很大的麻烦。这是在实际应用时需要注意的地方。
4、Broker端最终只通过消费者组返回的状态来确定消息有没有处理成功。至于消费者组自己的业务执行是否正常,Broker端是没有办法知道的。因此,在实现消费者的业务逻辑时,应该要尽量使用同步实现方式,保证在自己业务处理完成之后再向Broker端返回状态。而应该尽量避免异步的方式处理业务逻辑。
3、消费者也可以自行指定起始消费位点
虽然Offset完全由Broker进行维护,但是,RocketMQ也允许Consumer自己指定消费位点。核心代码是在Consumer中设定了一个属性ConsumeFromWhere,表示在Consumer启动时,从哪一条消息开始进行消费。Consumer当然不可能精确的知道Offset的具体参数,所以这个ConsumerFromWhere并不是直接传入Offset位点,而是可以传入一个ConsumerFromWhere对象,这是一个枚举值。名字一目了然
public enum ConsumeFromWhere {
CONSUME_FROM_LAST_OFFSET, //从队列的第一条消息开始重新消费
CONSUME_FROM_FIRST_OFFSET, //从上次消费到的地方开始继续消费
CONSUME_FROM_TIMESTAMP; //从某一个时间点开始重新消费
}
另外,如果指定了ConsumerFromWhere.CONSUME_FROM_TIMESTAMP,这就表示要从一个具体的时间开始。具体时间点,需要通过Consumer的另一个属性ConsumerTimestamp。这个属性可以传入一个表示时间的字符串。
consumer.setConsumerTimestamp("20131223171201");
到这里,我们就从客户端的角度分析清楚了要如何保证消息的安全性。但是消息安全问题其实是一个非常体系化的问题,涉及到的不光是客户端,还需要服务端配合。关于这个问题,我们会在后面的分享过程当中继续带你一起思考。
3、广播消息
广播模式和集群模式是RocketMQ的消费者端处理消息最基本的两种模式。集群模式下,一个消息,只会被一个消费者组中的多个消费者实例 共同 处理一次。广播模式下,一个消息,则会推送给所有消费者实例处理,不再关心消费者组。
示例代码:
消费者核心代码
consumer.setMessageModel(MessageModel.BROADCASTING);
默认模式(也就是集群模式)下,Broker端会给每个ConsumerGroup维护一个统一的Offset,这个Offset可以保证一个消息,在同一个ConsumerGroup内只会被消费一次。而广播模式的实现方式,是将Offset转移到消费者端自行保管,这样Broker端只管向所有消费者推送消息,而不用负责维护消费进度。
注意点:
1、Broker端不维护消费进度,意味着,如果消费者处理消息失败了,将无法进行消息重试。
2、消费者端维护Offset的作用是可以在服务重启时,按照上一次消费的进度,处理后面没有消费过的消息。丢了也不影响服务稳定性。
比如生产者发送了1~10号消息。消费者当消费到第6个时宕机了。当他重启时,Broker端已经把第10个消息都推送完成了。如果消费者端维护好了自己的Offset,那么他就可以在服务重启时,重新向Broker申请6号到10号的消息。但是,如果消费者端的Offset丢失了,消费者服务依然可以正常运行,但是6到10号消息就无法再申请了。后续这个消费者就只能获取10号以后的消息。
实际上,Offset的维护数据是放在 u s e r . h o m e / . r o c k e t m q o f f s e t / {user.home}/.rocketmq_offset/ user.home/.rocketmqoffset/{clientIp} i n s t a n c e N a m e / {instanceName}/ instanceName/{group}/offsets.json 文件下的。
消费者端存储广播消费的本地offsets文件的默认缓存目录是 System.getProperty(“user.home”) + File.separator + “.rocketmq_offsets” ,可以通过定制 rocketmq.client.localOffsetStoreDir 系统属性进行修改。
本地offsets文件在缓存目录中的具体位置与消费者的clientIp 和 instanceName有关。其中instanceName默认是DEFAULT,可以通过定制系统属性 rocketmq.client.name 进行修改。另外,每个消费者对象也可以单独设定instanceName。
RocketMQ会通过定时任务不断尝试本地Offsets文件的写入,但是,如果本地Offsets文件写入失败,RocketMQ不会进行任何的补救。
4、顺序消息机制
每一个订单有从下单、锁库存、支付、下物流等几个业务步骤。每个业务步骤都由一个消息生产者通知给下游服务。如何保证对每个订单的业务处理顺序不乱?
生产者核心代码:
for (int i = 0; i < 10; i++) {
int orderId = i;
for(int j = 0 ; j <= 5 ; j ++){
Message msg =
new Message("OrderTopicTest", "order_"+orderId, "KEY" + orderId,
("order_"+orderId+" step " + j).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
int index = id % mqs.size();
return mqs.get(index);
}
}, orderId);
System.out.printf("%s%n", sendResult);
}
}
通过MessageSelector,将orderId相同的消息,都转发到同一个MessageQueue中。
消费者核心代码:
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
context.setAutoCommit(true);
for(MessageExt msg:msgs){
System.out.println("收到消息内容 "+new String(msg.getBody()));
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
注入一个MessageListenerOrderly实现。
实现思路:
基础思路:只有放到一起的一批消息,才有可能保持消息的顺序。
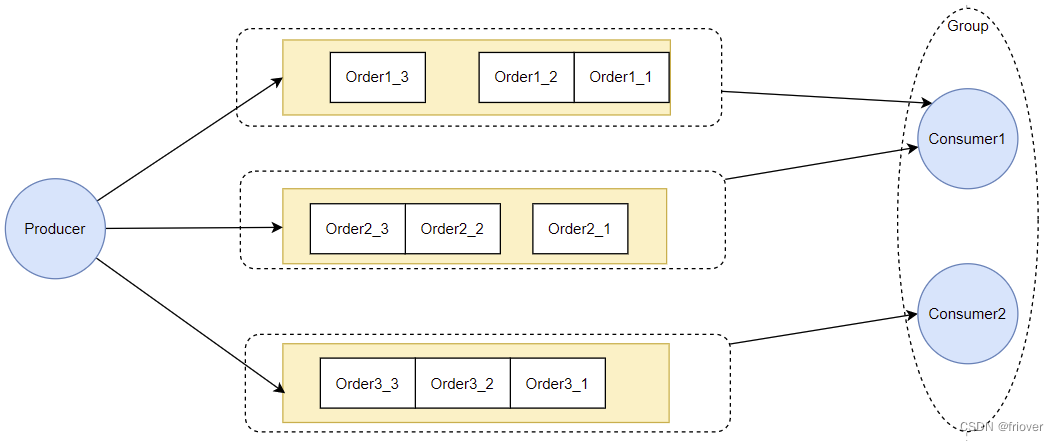
1、生产者只有将一批有顺序要求的消息,放到同一个MesasgeQueue上,Broker才有可能保持这一批消息的顺序。
2、消费者只有一次锁定一个MessageQueue,拿到MessageQueue上所有的消息,
注意点:
1、理解局部有序与全局有序。大部分业务场景下,我们需要的其实是局部有序。如果要保持全局有序,那就只保留一个MessageQueue。性能显然非常低。
2、生产者端尽可能将有序消息打散到不同的MessageQueue上,避免过于几种导致数据热点竞争。
2、消费者端只能用同步的方式处理消息,不要使用异步处理。更不能自行使用批量处理。
3、消费者端只进行有限次数的重试。如果一条消息处理失败,RocketMQ会将后续消息阻塞住,让消费者进行重试。但是,如果消费者一直处理失败,超过最大重试次数,那么RocketMQ就会跳过这一条消息,处理后面的消息,这会造成消息乱序。
4、消费者端如果确实处理逻辑中出现问题,不建议抛出异常,可以返回ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT作为替代。
5、延迟消息
应用场景:
延迟消息发送是指消息发送到Apache RocketMQ后,并不期望立马投递这条消息,而是延迟一定时间后才投递到Consumer进行消费。
生产者端核心代码:
msg.setDelayTimeLevel(3);
只要给消息设定一个延迟级别就行了,无比简单。
RocketMQ给消息定制了18个默认的延迟级别,分别对应18个不同的预设好的延迟时间

注意点:
这样预设延迟时间其实是不太灵活的。5.x版本已经支持预设一个具体的时间戳,按秒的精度进行定时发送。
但是可以看到,这18个延迟级别虽然无法调整,但是每个延迟级别对应的延迟时间其实是可以调整的。只需要修改截图中的参数就行。不过通常不建议这么做。
6、批量消息
应用场景:
生产者要发送的消息比较多时,可以将多条消息合并成一个批量消息,一次性发送出去。这样可以减少网络IO,提升消息发送的吞吐量。
示例代码:
生产者核心代码:
List<Message> messages = new ArrayList<>();
messages.add(new Message(topic, "Tag", "OrderID001", "Hello world 0".getBytes()));
messages.add(new Message(topic, "Tag", "OrderID002", "Hello world 1".getBytes()));
messages.add(new Message(topic, "Tag", "OrderID003", "Hello world 2".getBytes()));
producer.send(messages);
注意点:
批量消息的使用非常简单,但是要注意RocketMQ做了限制。同一批消息的Topic必须相同,另外,不支持延迟消息。
还有批量消息的大小不要超过1M,如果太大就需要自行分割。
7、过滤消息(重要)
应用场景:
同一个Topic下有多种不同的消息,消费者只希望关注某一类消息。
例如,某系统中给仓储系统分配一个Topic,在Topic下,会传递过来入库、出库等不同的消息,仓储系统的不同业务消费者就需要过滤出自己感兴趣的消息,进行不同的业务操作。

示例代码1:简单过滤
生产者端需要在发送消息时,增加Tag属性。比如我们上面举例当中的入库、出库。
核心代码:
String[] tags = new String[] {"TagA", "TagB", "TagC"};
for (int i = 0; i < 15; i++) {
Message msg = new Message("TagFilterTest",
tags[i % tags.length],
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
消费者端就可以通过这个Tag属性订阅自己感兴趣的内容。核心代码:
consumer.subscribe("TagFilterTest", "TagA");
这样,后续Consumer就只会出处理TagA的消息。
示例代码2:SQL过滤
通过Tag属性,只能进行简单的消息匹配。如果要进行更复杂的消息过滤,比如数字比较,模糊匹配等,就需要使用SQL过滤方式。SQL过滤方式可以通过Tag属性以及用户自定义的属性一起,以标准SQL的方式进行消息过滤。
生产者端在发送消息时,出了Tag属性外,还可以增加自定义属性。核心代码
String[] tags = new String[] {"TagA", "TagB", "TagC"};
for (int i = 0; i < 15; i++) {
Message msg = new Message("SqlFilterTest",
tags[i % tags.length],
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)
);
msg.putUserProperty("a", String.valueOf(i));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
消费者端在进行过滤时,可以指定一个标准的SQL语句,定制复杂的过滤规则。核心代码:
consumer.subscribe("SqlFilterTest",
MessageSelector.bySql("(TAGS is not null and TAGS in ('TagA', 'TagB'))" +
"and (a is not null and a between 0 and 3)"));
Tag属性的处理比较简单,就是直接匹配。而SQL语句的处理会比较麻烦一点。RocketMQ也是通过ANLTR引擎来解析SQL语句,然后再进行消息过滤的。
ANLTR是一个开源的SQL语句解析框架。很多开源产品都在使用ANLTR来解析SQL语句。比如ShardingSphere,Flink等。
注意点:
1、使用Tag过滤时,如果希望匹配多个Tag,可以使用两个竖线(||)连接多个Tag值。另外,也可以使用星号(*)匹配所有。
2、使用SQL顾虑时,SQL语句是按照SQL92标准来执行的。SQL语句中支持一些常见的基本操作:
数值比较,比如:>,>=,<,<=,BETWEEN,=;
字符比较,比如:=,<>,IN;
IS NULL 或者 IS NOT NULL;
逻辑符号 AND,OR,NOT;
3、消息过滤,其实在Broker端和在Consumer端都可以做。Consumer端也可以自行获取用户属性,不感兴趣的消息,直接返回不成功的状态,跳过该消息就行了。但是RocketMQ会在Broker端完成过滤条件的判断,只将Consumer感兴趣的消息推送给Consumer。这样的好处是减少了不必要的网络IO,但是缺点是加大了服务端的压力。不过在RocketMQ的良好设计下,更建议使用消息过滤机制。
4、Consumer不感兴趣的消息并不表示直接丢弃。通常是需要在同一个消费者组,定制另外的消费者实例,消费那些剩下的消息。但是,如果一直没有另外的Consumer,那么,Broker端还是会推进Offset。
8、事务消息
事务消息是RocketMQ非常有特色的一个高级功能。他的基础诉求是通过RocketMQ的事务机制,来保证上下游的数据一致性。
以电商为例,用户支付订单这一核心操作的同时会涉及到下游物流发货、积分变更、购物车状态清空等多个子系统的变更。这种场景,非常适合使用RocketMQ的解耦功能来进行串联。
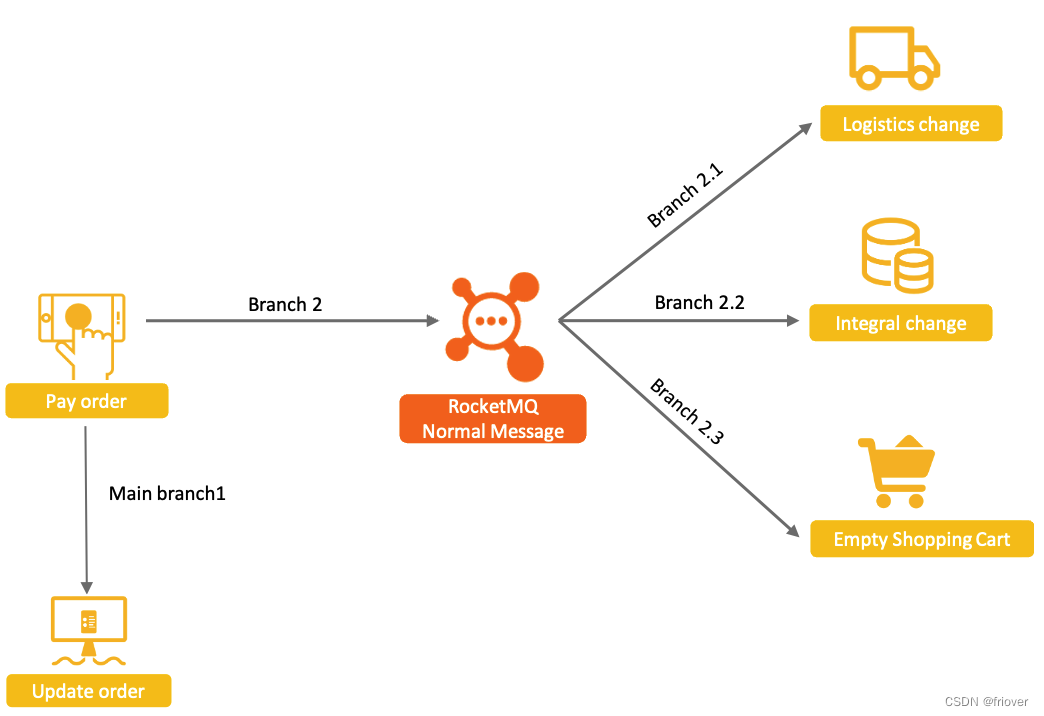
考虑到事务的安全性,即要保证相关联的这几个业务一定是同时成功或者同时失败的。如果要将四个服务一起作为一个分布式事务来控制,可以做到,但是会非常麻烦。而使用RocketMQ在中间串联了之后,事情可以得到一定程度的简化。由于RocketMQ与消费者端有失败重试机制,所以,只要消息成功发送到RocketMQ了,那么可以认为Branch2.1,Branch2.2,Branch2.3这几个分支步骤,是可以保证最终的数据一致性的。这样,一个复杂的分布式事务问题,就变成了MinBranch1和Branch2两个步骤的分布式事务问题。
然后,在此基础上,RocketMQ提出了事务消息机制,采用两阶段提交的思路,保证Main Branch1和Branch2之间的事务一致性。
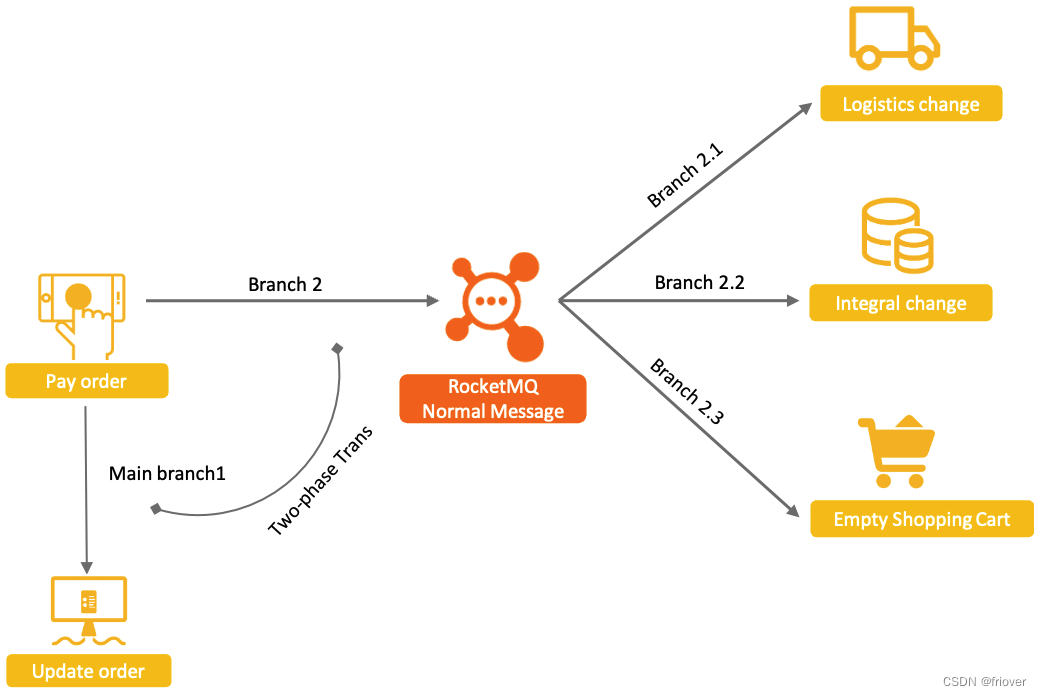
具体的实现思路是这样的:
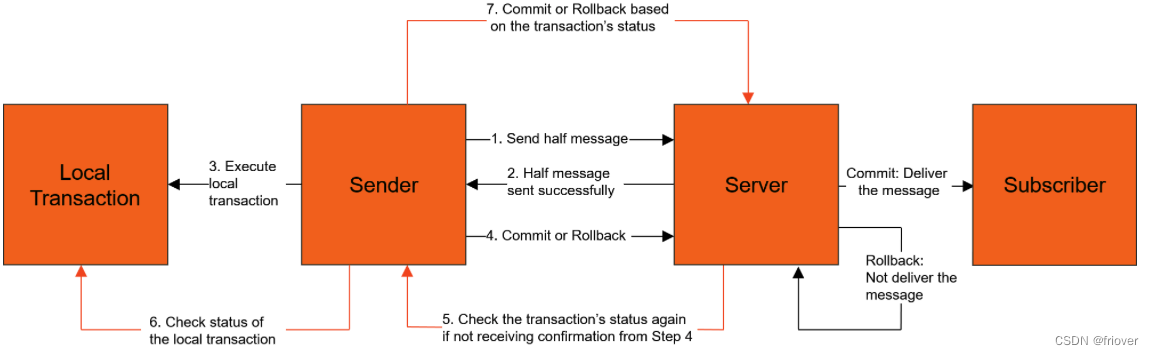
- 生产者将消息发送至Apache RocketMQ服务端。
- Apache RocketMQ服务端将消息持久化成功之后,向生产者返回Ack确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下的消息即为半事务消息。
- 生产者开始执行本地事务逻辑。
- 生产者根据本地事务执行结果向服务端提交二次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
二次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
二次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。 - 在断网或者是生产者应用重启的特殊情况下,若服务端未收到发送者提交的二次确认结果,或服务端收到的二次确认结果为Unknown未知状态,经过固定时间后,服务端将对消息生产者即生产者集群中任一生产者实例发起消息回查。
- 生产者收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 生产者根据检查到的本地事务的最终状态再次提交二次确认,服务端仍按照步骤4对半事务消息进行处理。
示例代码:
public static void main(String[] args) throws MQClientException, InterruptedException {
TransactionListener transactionListener = new TransactionListenerImpl();
TransactionMQProducer producer = new TransactionMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("192.168.85.200:9876");
producer.setSendMsgTimeout(8000);
ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2000), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName("client-transaction-msg-check-thread");
return thread;
}
});
producer.setExecutorService(executorService);
producer.setTransactionListener(transactionListener);
producer.start();
String[] tags = new String[] {"TagA", "TagB", "TagC", "TagD", "TagE"};
for (int i = 0; i < 10; i++) {
try {
Message msg =
new Message("TopicTest445", tags[i % tags.length], "KEY" + i,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
// msg.putUserProperty("CHECK_IMMUNITY_TIME_IN_SECONDS","10000");
SendResult sendResult = producer.sendMessageInTransaction(msg, null);
System.out.printf("%s%n", sendResult);
Thread.sleep(10);
} catch (MQClientException | UnsupportedEncodingException e) {
e.printStackTrace();
}
}
for (int i = 0; i < 100000; i++) {
Thread.sleep(1000);
}
producer.shutdown();
}
public class TransactionListenerImpl implements TransactionListener {
private AtomicInteger transactionIndex = new AtomicInteger(0);
private ConcurrentHashMap<String, Integer> localTrans = new ConcurrentHashMap<>();
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// int value = transactionIndex.getAndIncrement();
// int status = value % 3;
// localTrans.put(msg.getTransactionId(), status);
// return LocalTransactionState.UNKNOW;
String tags = msg.getTags();
if(StringUtils.contains(tags,"TagA")){
return LocalTransactionState.COMMIT_MESSAGE;
}else if(StringUtils.contains(tags,"TagB")){
return LocalTransactionState.ROLLBACK_MESSAGE;
}else{
return LocalTransactionState.UNKNOW;
}
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// Integer status = localTrans.get(msg.getTransactionId());
// if (null != status) {
// switch (status) {
// case 0:
// return LocalTransactionState.UNKNOW;
// case 1:
// return LocalTransactionState.COMMIT_MESSAGE;
// case 2:
// return LocalTransactionState.ROLLBACK_MESSAGE;
// default:
// return LocalTransactionState.COMMIT_MESSAGE;
// }
// }
// return LocalTransactionState.COMMIT_MESSAGE;
String tags = msg.getTags();
if(StringUtils.contains(tags,"TagC")){
return LocalTransactionState.COMMIT_MESSAGE;
}else if(StringUtils.contains(tags,"TagD")){
return LocalTransactionState.ROLLBACK_MESSAGE;
}else{
return LocalTransactionState.UNKNOW;
}
}
}
实现时的重点是使用RocketMQ提供的TransactionMQProducer事务生产者,在TransactionMQProducer中注入一个TransactionListener事务监听器来执行本地事务,以及后续对本地事务的检查。
注意点:
1、半消息是对消费者不可见的一种消息。实际上,RocketMQ的做法是将消息转到了一个系统Topic,RMQ_SYS_TRANS_HALF_TOPIC。
2、事务消息中,本地事务回查次数通过参数transactionCheckMax设定,默认15次。本地事务回查的间隔通过参数transactionCheckInterval设定,默认60秒。超过回查次数后,消息将会被丢弃。
3、其实,了解了事务消息的机制后,在具体执行时,可以对事务流程进行适当的调整。