第一个GPU程序
#include <stdio.h>
__global__ void square(float* d_out,float* d_in){
int idx = threadIdx.x;
float f = d_in[idx];
d_out[idx] = f * f;
}
int main(int argc,char** argv){
const int ARRAY_SIZE = 8;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for(int i=0;i<ARRAY_SIZE;i++){
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float* d_in;
float* d_out;
// allocate GPU memory
cudaMalloc((void**) &d_in,ARRAY_BYTES);
cudaMalloc((void**) &d_out,ARRAY_BYTES);
// transfer the array to GPU
cudaMemcpy(d_in,h_in,ARRAY_BYTES,cudaMemcpyHostToDevice);
// launch the kernel
square<<<1,ARRAY_SIZE>>>(d_out,d_in);
// copy back the result array to the GPU
cudaMemcpy(h_out,d_out,ARRAY_BYTES,cudaMemcpyDeviceToHost);
// print out the resulting array
for(int i=0;i<ARRAY_SIZE;i++){
printf("%f",h_out[i]);
printf(((i%4) != 3) ? "\t" : "\n");
}
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_out);
return 0;
}






CUDA中的内存
// Using different memory spaces in CUDA
#include <stdio.h>
/**********************
* using local memory *
**********************/
// a __device__ or __global__ function runs on the GPU
__global__ void use_local_memory_GPU(float in)
{
float f; // variable "f" is in local memory and private to each thread
f = in; // parameter "in" is in local memory and private to each thread
// ... real code would presumably do other stuff here ...
}
/**********************
* using global memory *
**********************/
// a __global__ function runs on the GPU & can be called from host
__global__ void use_global_memory_GPU(float *array)
{
// "array" is a pointer into global memory on the device
array[threadIdx.x] = 2.0f * (float) threadIdx.x;
}
/**********************
* using shared memory *
**********************/
// (for clarity, hardcoding 128 threads/elements and omitting out-of-bounds checks)
__global__ void use_shared_memory_GPU(float *array)
{
// local variables, private to each thread
int i, index = threadIdx.x;
float average, sum = 0.0f;
// __shared__ variables are visible to all threads in the thread block
// and have the same lifetime as the thread block
__shared__ float sh_arr[128];
// copy data from "array" in global memory to sh_arr in shared memory.
// here, each thread is responsible for copying a single element.
sh_arr[index] = array[index];
__syncthreads(); // ensure all the writes to shared memory have completed
// now, sh_arr is fully populated. Let's find the average of all previous elements
for (i=0; i<index; i++) { sum += sh_arr[i]; }
average = sum / (index + 1.0f);
// if array[index] is greater than the average of array[0..index-1], replace with average.
// since array[] is in global memory, this change will be seen by the host (and potentially
// other thread blocks, if any)
if (array[index] > average) { array[index] = average; }
// the following code has NO EFFECT: it modifies shared memory, but
// the resulting modified data is never copied back to global memory
// and vanishes when the thread block completes
sh_arr[index] = 3.14;
}
int main(int argc, char **argv)
{
/*
* First, call a kernel that shows using local memory
*/
use_local_memory_GPU<<<1, 128>>>(2.0f);
/*
* Next, call a kernel that shows using global memory
*/
float h_arr[128]; // convention: h_ variables live on host
float *d_arr; // convention: d_ variables live on device (GPU global mem)
// allocate global memory on the device, place result in "d_arr"
cudaMalloc((void **) &d_arr, sizeof(float) * 128);
// now copy data from host memory "h_arr" to device memory "d_arr"
cudaMemcpy((void *)d_arr, (void *)h_arr, sizeof(float) * 128, cudaMemcpyHostToDevice);
// launch the kernel (1 block of 128 threads)
use_global_memory_GPU<<<1, 128>>>(d_arr); // modifies the contents of array at d_arr
// copy the modified array back to the host, overwriting contents of h_arr
cudaMemcpy((void *)h_arr, (void *)d_arr, sizeof(float) * 128, cudaMemcpyDeviceToHost);
// ... do other stuff ...
/*
* Next, call a kernel that shows using shared memory
*/
// as before, pass in a pointer to data in global memory
use_shared_memory_GPU<<<1, 128>>>(d_arr);
// copy the modified array back to the host
cudaMemcpy((void *)h_arr, (void *)d_arr, sizeof(float) * 128, cudaMemcpyHostToDevice);
// ... do other stuff ...
return 0;
}
规约算法
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
__global__ void global_reduce_kernel(float * d_out, float * d_in)
{
int myId = threadIdx.x + blockDim.x * blockIdx.x;
int tid = threadIdx.x;
// do reduction in global mem
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1)
{
if (tid < s)
{
d_in[myId] += d_in[myId + s];
}
__syncthreads(); // make sure all adds at one stage are done!
}
// only thread 0 writes result for this block back to global mem
if (tid == 0)
{
d_out[blockIdx.x] = d_in[myId];
}
}
__global__ void shmem_reduce_kernel(float * d_out, const float * d_in)
{
// sdata is allocated in the kernel call: 3rd arg to <<<b, t, shmem>>>
extern __shared__ float sdata[];
int myId = threadIdx.x + blockDim.x * blockIdx.x;
int tid = threadIdx.x;
// load shared mem from global mem
sdata[tid] = d_in[myId];
__syncthreads(); // make sure entire block is loaded!
// do reduction in shared mem
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1)
{
if (tid < s)
{
sdata[tid] += sdata[tid + s];
}
__syncthreads(); // make sure all adds at one stage are done!
}
// only thread 0 writes result for this block back to global mem
if (tid == 0)
{
d_out[blockIdx.x] = sdata[0];
}
}
void reduce(float * d_out, float * d_intermediate, float * d_in,
int size, bool usesSharedMemory)
{
// assumes that size is not greater than maxThreadsPerBlock^2
// and that size is a multiple of maxThreadsPerBlock
const int maxThreadsPerBlock = 1024;
int threads = maxThreadsPerBlock;
int blocks = size / maxThreadsPerBlock;
if (usesSharedMemory)
{
shmem_reduce_kernel<<<blocks, threads, threads * sizeof(float)>>>
(d_intermediate, d_in);
}
else
{
global_reduce_kernel<<<blocks, threads>>>
(d_intermediate, d_in);
}
// now we're down to one block left, so reduce it
threads = blocks; // launch one thread for each block in prev step
blocks = 1;
if (usesSharedMemory)
{
shmem_reduce_kernel<<<blocks, threads, threads * sizeof(float)>>>
(d_out, d_intermediate);
}
else
{
global_reduce_kernel<<<blocks, threads>>>
(d_out, d_intermediate);
}
}
int main(int argc, char **argv)
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount == 0) {
fprintf(stderr, "error: no devices supporting CUDA.\n");
exit(EXIT_FAILURE);
}
int dev = 0;
cudaSetDevice(dev);
cudaDeviceProp devProps;
if (cudaGetDeviceProperties(&devProps, dev) == 0)
{
printf("Using device %d:\n", dev);
printf("%s; global mem: %dB; compute v%d.%d; clock: %d kHz\n",
devProps.name, (int)devProps.totalGlobalMem,
(int)devProps.major, (int)devProps.minor,
(int)devProps.clockRate);
}
const int ARRAY_SIZE = 1 << 20;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
float sum = 0.0f;
for(int i = 0; i < ARRAY_SIZE; i++) {
// generate random float in [-1.0f, 1.0f]
h_in[i] = -1.0f + (float)random()/((float)RAND_MAX/2.0f);
sum += h_in[i];
}
// declare GPU memory pointers
float * d_in, * d_intermediate, * d_out;
// allocate GPU memory
cudaMalloc((void **) &d_in, ARRAY_BYTES);
cudaMalloc((void **) &d_intermediate, ARRAY_BYTES); // overallocated
cudaMalloc((void **) &d_out, sizeof(float));
// transfer the input array to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
int whichKernel = 0;
if (argc == 2) {
whichKernel = atoi(argv[1]);
}
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
// launch the kernel
switch(whichKernel) {
case 0:
printf("Running global reduce\n");
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
reduce(d_out, d_intermediate, d_in, ARRAY_SIZE, false);
}
cudaEventRecord(stop, 0);
break;
case 1:
printf("Running reduce with shared mem\n");
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
reduce(d_out, d_intermediate, d_in, ARRAY_SIZE, true);
}
cudaEventRecord(stop, 0);
break;
default:
fprintf(stderr, "error: ran no kernel\n");
exit(EXIT_FAILURE);
}
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
elapsedTime /= 100.0f; // 100 trials
// copy back the sum from GPU
float h_out;
cudaMemcpy(&h_out, d_out, sizeof(float), cudaMemcpyDeviceToHost);
printf("average time elapsed: %f\n", elapsedTime);
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_intermediate);
cudaFree(d_out);
return 0;
}
扫描算法
#include <stdio.h>
__global__ void global_scan(float* d_out,float* d_in){
int idx = threadIdx.x;
float out = 0.00f;
d_out[idx] = d_in[idx];
__syncthreads();
for(int interpre=1;interpre<sizeof(d_in);interpre*=2){
if(idx-interpre>=0){
out = d_out[idx]+d_out[idx-interpre];
}
__syncthreads();
if(idx-interpre>=0){
d_out[idx] = out;
out = 0.00f;
}
}
}
//TODO:[homework] use shared memory to complete the scan algorithm.
//![Notice]remember to modify the kernel loading.
__global__ void shmem_scan(float* d_out,float* d_in){
extern __shared__ float sdata[];
int idx = threadIdx.x;
float out = 0.00f;
sdata[idx] = d_in[idx];
__syncthreads();
for(int interpre=1;interpre<sizeof(d_in);interpre*=2){
if(idx-interpre>=0){
out = sdata[idx]+sdata[idx-interpre];
}
__syncthreads();
if(idx-interpre>=0){
sdata[idx] = out;
out = 0.00f;
}
}
d_out[idx] = sdata[idx];
}
int main(int argc,char** argv){
const int ARRAY_SIZE = 8;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float);
// generate the input array on the host
float h_in[ARRAY_SIZE];
for(int i=0;i<ARRAY_SIZE;i++){
h_in[i] = float(i);
}
float h_out[ARRAY_SIZE];
// declare GPU memory pointers
float* d_in;
float* d_out;
// allocate GPU memory
cudaMalloc((void**) &d_in,ARRAY_BYTES);
cudaMalloc((void**) &d_out,ARRAY_BYTES);
// transfer the array to GPU
cudaMemcpy(d_in,h_in,ARRAY_BYTES,cudaMemcpyHostToDevice);
// launch the kernel
shmem_scan<<<1,ARRAY_SIZE,ARRAY_SIZE*sizeof(float)>>>(d_out,d_in);
// copy back the result array to the GPU
cudaMemcpy(h_out,d_out,ARRAY_BYTES,cudaMemcpyDeviceToHost);
// print out the resulting array
for(int i=0;i<ARRAY_SIZE;i++){
printf("%f",h_out[i]);
printf(((i%4) != 3) ? "\t" : "\n");
}
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_out);
return 0;
}
GPU计算直方图
方法一:直接做累加(错误)
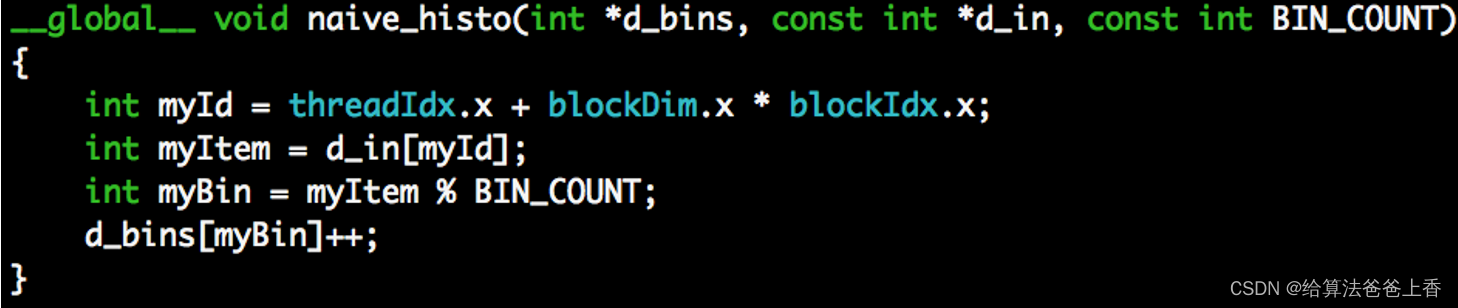
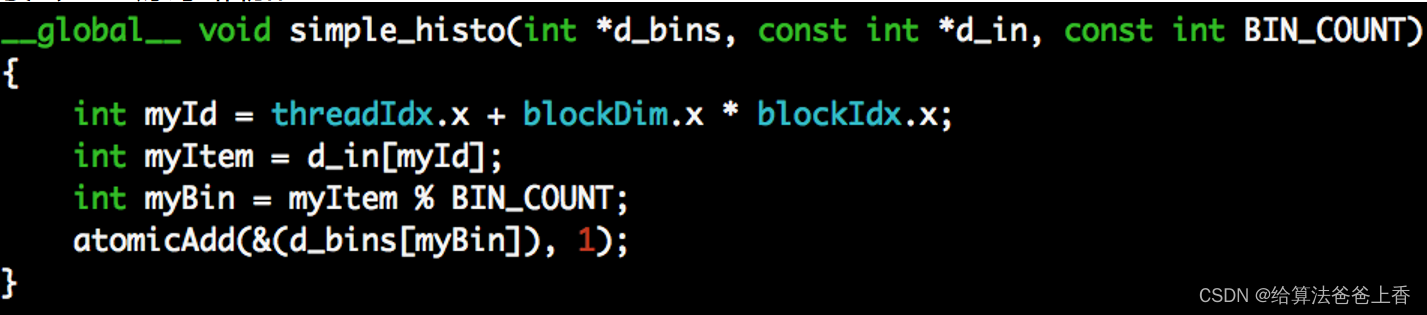
方法二:原子相加(分组bins越少,并行化程度越低,方法二适合用于分组bins很多的时候)
方法三:局部直方图
第一步:并行计算局部直方图;
第二步:把所有局部直方图每个分组bin使用Reduction(归约)并行累加起来行程一个总的直方图。
#include <stdio.h>
#include <cuda_runtime.h>
int log2(int i)
{
int r = 0;
while (i >>= 1) r++;
return r;
}
int bit_reverse(int w, int bits)
{
int r = 0;
for (int i = 0; i < bits; i++)
{
int bit = (w & (1 << i)) >> i;
r |= bit << (bits - i - 1);
}
return r;
}
__global__ void naive_histo(int *d_bins, const int *d_in, const int BIN_COUNT)
{
int myId = threadIdx.x + blockDim.x * blockIdx.x;
int myItem = d_in[myId];
int myBin = myItem % BIN_COUNT;
d_bins[myBin]++;
}
__global__ void simple_histo(int *d_bins, const int *d_in, const int BIN_COUNT)
{
int myId = threadIdx.x + blockDim.x * blockIdx.x;
int myItem = d_in[myId];
int myBin = myItem % BIN_COUNT;
atomicAdd(&(d_bins[myBin]), 1);
}
int main(int argc, char **argv)
{
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount == 0) {
fprintf(stderr, "error: no devices supporting CUDA.\n");
exit(EXIT_FAILURE);
}
int dev = 0;
cudaSetDevice(dev);
cudaDeviceProp devProps;
if (cudaGetDeviceProperties(&devProps, dev) == 0)
{
printf("Using device %d:\n", dev);
printf("%s; global mem: %dB; compute v%d.%d; clock: %d kHz\n",
devProps.name, (int)devProps.totalGlobalMem,
(int)devProps.major, (int)devProps.minor,
(int)devProps.clockRate);
}
const int ARRAY_SIZE = 65536;
const int ARRAY_BYTES = ARRAY_SIZE * sizeof(int);
const int BIN_COUNT = 16;
const int BIN_BYTES = BIN_COUNT * sizeof(int);
// generate the input array on the host
int h_in[ARRAY_SIZE];
for(int i = 0; i < ARRAY_SIZE; i++) {
h_in[i] = bit_reverse(i, log2(ARRAY_SIZE));
}
int h_bins[BIN_COUNT];
for(int i = 0; i < BIN_COUNT; i++) {
h_bins[i] = 0;
}
// declare GPU memory pointers
int * d_in;
int * d_bins;
// allocate GPU memory
cudaMalloc((void **) &d_in, ARRAY_BYTES);
cudaMalloc((void **) &d_bins, BIN_BYTES);
// transfer the arrays to the GPU
cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice);
cudaMemcpy(d_bins, h_bins, BIN_BYTES, cudaMemcpyHostToDevice);
int whichKernel = 0;
if (argc == 2) {
whichKernel = atoi(argv[1]);
}
// launch the kernel
switch(whichKernel) {
case 0:
printf("Running naive histo\n");
naive_histo<<<ARRAY_SIZE / 64, 64>>>(d_bins, d_in, BIN_COUNT);
break;
case 1:
printf("Running simple histo\n");
simple_histo<<<ARRAY_SIZE / 64, 64>>>(d_bins, d_in, BIN_COUNT);
break;
default:
fprintf(stderr, "error: ran no kernel\n");
exit(EXIT_FAILURE);
}
// copy back the sum from GPU
cudaMemcpy(h_bins, d_bins, BIN_BYTES, cudaMemcpyDeviceToHost);
for(int i = 0; i < BIN_COUNT; i++) {
printf("bin %d: count %d\n", i, h_bins[i]);
}
// free GPU memory allocation
cudaFree(d_in);
cudaFree(d_bins);
return 0;
}
并行化实现图像的RGB转灰度图
#include <iostream>
#include <string>
#include <cassert>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/opencv.hpp>
#include <cuda.h>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#define checkCudaErrors(val) check( (val), #val, __FILE__, __LINE__)
cv::Mat imageRGBA;
cv::Mat imageGrey;
uchar4 *d_rgbaImage__;
unsigned char *d_greyImage__;
size_t numRows() { return imageRGBA.rows; }
size_t numCols() { return imageRGBA.cols; }
template<typename T>
void check(T err, const char* const func, const char* const file, const int line) {
if (err != cudaSuccess) {
std::cerr << "CUDA error at: " << file << ":" << line << std::endl;
std::cerr << cudaGetErrorString(err) << " " << func << std::endl;
exit(1);
}
}
void preProcess(uchar4 **inputImage, unsigned char **greyImage,
uchar4 **d_rgbaImage, unsigned char **d_greyImage,
const std::string &filename) {
//make sure the context initializes ok
checkCudaErrors(cudaFree(0));
cv::Mat image;
image = cv::imread(filename.c_str(), CV_LOAD_IMAGE_COLOR);
if (image.empty()) {
std::cerr << "Couldn't open file: " << filename << std::endl;
exit(1);
}
cv::cvtColor(image, imageRGBA, CV_BGR2RGBA);
//allocate memory for the output
imageGrey.create(image.rows, image.cols, CV_8UC1);
//This shouldn't ever happen given the way the images are created
//at least based upon my limited understanding of OpenCV, but better to check
if (!imageRGBA.isContinuous() || !imageGrey.isContinuous()) {
std::cerr << "Images aren't continuous!! Exiting." << std::endl;
exit(1);
}
*inputImage = (uchar4 *)imageRGBA.ptr<unsigned char>(0);
*greyImage = imageGrey.ptr<unsigned char>(0);
const size_t numPixels = numRows() * numCols();
//allocate memory on the device for both input and output
checkCudaErrors(cudaMalloc(d_rgbaImage, sizeof(uchar4) * numPixels));
checkCudaErrors(cudaMalloc(d_greyImage, sizeof(unsigned char) * numPixels));
checkCudaErrors(cudaMemset(*d_greyImage, 0, numPixels * sizeof(unsigned char))); //make sure no memory is left laying around
//copy input array to the GPU
checkCudaErrors(cudaMemcpy(*d_rgbaImage, *inputImage, sizeof(uchar4) * numPixels, cudaMemcpyHostToDevice));
d_rgbaImage__ = *d_rgbaImage;
d_greyImage__ = *d_greyImage;
}
__global__
void rgba_to_greyscale(const uchar4* const rgbaImage,unsigned char* const greyImage,int numRows, int numCols){
int threadId = blockIdx.x * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
if (threadId < numRows * numCols){
const unsigned char R = rgbaImage[threadId].x;
const unsigned char G = rgbaImage[threadId].y;
const unsigned char B = rgbaImage[threadId].z;
greyImage[threadId] = .299f * R + .587f * G + .114f * B;
}
}
void postProcess(const std::string& output_file, unsigned char* data_ptr) {
cv::Mat output(numRows(), numCols(), CV_8UC1, (void*)data_ptr);
//output the image
cv::imwrite(output_file.c_str(), output);
}
void cleanup(){
//cleanup
cudaFree(d_rgbaImage__);
cudaFree(d_greyImage__);
}
int main(int argc,char* argv[]){
//load input file
std::string input_file = argv[1];
//define output file
std::string output_file = argv[2];
uchar4 *h_rgbaImage, *d_rgbaImage;
unsigned char *h_greyImage, *d_greyImage;
//load the image and give us our input and output pointers
preProcess(&h_rgbaImage, &h_greyImage, &d_rgbaImage, &d_greyImage, input_file);
int thread = 16;
int grid = (numRows()*numCols() + thread - 1)/ (thread * thread);
const dim3 blockSize(thread, thread);
const dim3 gridSize(grid);
rgba_to_greyscale<<<gridSize, blockSize>>>(d_rgbaImage, d_greyImage, numRows(), numCols());
cudaDeviceSynchronize(); //checkCudaErrors(cudaGetLastError());
size_t numPixels = numRows()*numCols();
checkCudaErrors(cudaMemcpy(h_greyImage, d_greyImage, sizeof(unsigned char) * numPixels, cudaMemcpyDeviceToHost));
//check results and output the grey image
postProcess(output_file, h_greyImage);
cleanup();
}
并行化实现图像的均值模糊处理
#include <iostream>
#include <string>
#include <cassert>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/opencv.hpp>
#include <cuda.h>
#include <cuda_runtime.h>
#include <cuda_runtime_api.h>
#define checkCudaErrors(val) check( (val), #val, __FILE__, __LINE__)
cv::Mat imageInputRGBA;
cv::Mat imageOutputRGBA;
uchar4 *d_inputImageRGBA__;
uchar4 *d_outputImageRGBA__;
float *h_filter__;
size_t numRows() { return imageInputRGBA.rows; }
size_t numCols() { return imageInputRGBA.cols; }
template<typename T>
void check(T err, const char* const func, const char* const file, const int line) {
if (err != cudaSuccess) {
std::cerr << "CUDA error at: " << file << ":" << line << std::endl;
std::cerr << cudaGetErrorString(err) << " " << func << std::endl;
exit(1);
}
}
void preProcess(uchar4 **h_inputImageRGBA, uchar4 **h_outputImageRGBA,
uchar4 **d_inputImageRGBA, uchar4 **d_outputImageRGBA,
unsigned char **d_redBlurred,
unsigned char **d_greenBlurred,
unsigned char **d_blueBlurred,
float **h_filter, int *filterWidth,
const std::string &filename) {
//make sure the context initializes ok
checkCudaErrors(cudaFree(0));
cv::Mat image = cv::imread(filename.c_str(), CV_LOAD_IMAGE_COLOR);
if (image.empty()) {
std::cerr << "Couldn't open file: " << filename << std::endl;
exit(1);
}
cv::cvtColor(image, imageInputRGBA, CV_BGR2RGBA);
//allocate memory for the output
imageOutputRGBA.create(image.rows, image.cols, CV_8UC4);
//This shouldn't ever happen given the way the images are created
//at least based upon my limited understanding of OpenCV, but better to check
if (!imageInputRGBA.isContinuous() || !imageOutputRGBA.isContinuous()) {
std::cerr << "Images aren't continuous!! Exiting." << std::endl;
exit(1);
}
*h_inputImageRGBA = (uchar4 *)imageInputRGBA.ptr<unsigned char>(0);
*h_outputImageRGBA = (uchar4 *)imageOutputRGBA.ptr<unsigned char>(0);
const size_t numPixels = numRows() * numCols();
//allocate memory on the device for both input and output
checkCudaErrors(cudaMalloc(d_inputImageRGBA, sizeof(uchar4) * numPixels));
checkCudaErrors(cudaMalloc(d_outputImageRGBA, sizeof(uchar4) * numPixels));
checkCudaErrors(cudaMemset(*d_outputImageRGBA, 0, numPixels * sizeof(uchar4))); //make sure no memory is left laying around
//copy input array to the GPU
checkCudaErrors(cudaMemcpy(*d_inputImageRGBA, *h_inputImageRGBA, sizeof(uchar4) * numPixels, cudaMemcpyHostToDevice));
d_inputImageRGBA__ = *d_inputImageRGBA;
d_outputImageRGBA__ = *d_outputImageRGBA;
//now create the filter that they will use
const int blurKernelWidth = 9;
const float blurKernelSigma = 2.;
*filterWidth = blurKernelWidth;
//create and fill the filter we will convolve with
*h_filter = new float[blurKernelWidth * blurKernelWidth];
h_filter__ = *h_filter;
float filterSum = 0.f; //for normalization
for (int r = -blurKernelWidth/2; r <= blurKernelWidth/2; ++r) {
for (int c = -blurKernelWidth/2; c <= blurKernelWidth/2; ++c) {
float filterValue = expf( -(float)(c * c + r * r) / (2.f * blurKernelSigma * blurKernelSigma));
(*h_filter)[(r + blurKernelWidth/2) * blurKernelWidth + c + blurKernelWidth/2] = filterValue;
filterSum += filterValue;
}
}
float normalizationFactor = 1.f / filterSum;
for (int r = -blurKernelWidth/2; r <= blurKernelWidth/2; ++r) {
for (int c = -blurKernelWidth/2; c <= blurKernelWidth/2; ++c) {
(*h_filter)[(r + blurKernelWidth/2) * blurKernelWidth + c + blurKernelWidth/2] *= normalizationFactor;
}
}
//blurred
checkCudaErrors(cudaMalloc(d_redBlurred,sizeof(unsigned char) * numPixels));
checkCudaErrors(cudaMalloc(d_greenBlurred,sizeof(unsigned char) * numPixels));
checkCudaErrors(cudaMalloc(d_blueBlurred,sizeof(unsigned char) * numPixels));
checkCudaErrors(cudaMemset(*d_redBlurred,0,sizeof(unsigned char) * numPixels));
checkCudaErrors(cudaMemset(*d_greenBlurred,0,sizeof(unsigned char) * numPixels));
checkCudaErrors(cudaMemset(*d_blueBlurred,0,sizeof(unsigned char) * numPixels));//make sure the context initializes ok
checkCudaErrors(cudaFree(0));
}
__global__
void gaussian_blur(const unsigned char* const inputChannel,
unsigned char* const outputChannel,
int numRows, int numCols,
const float* const filter, const int filterWidth)
{
const int2 thread_2D_pos = make_int2( blockIdx.x * blockDim.x + threadIdx.x,
blockIdx.y * blockDim.y + threadIdx.y);
const int thread_1D_pos = thread_2D_pos.y * numCols + thread_2D_pos.x;
const int absolute_image_position_x = thread_2D_pos.x;
const int absolute_image_position_y = thread_2D_pos.y;
if ( absolute_image_position_x >= numCols ||
absolute_image_position_y >= numRows )
{
return;
}
float color = 0.0f;
for(int py=0; py < filterWidth; py++){
for(int px=0; px < filterWidth; px++){
int c_x = absolute_image_position_x + px - filterWidth / 2;
int c_y = absolute_image_position_y + py - filterWidth / 2;
c_x = min(max(c_x, 0), numCols - 1);
c_y = min(max(c_y, 0), numRows - 1);
float filter_value = filter[py*filterWidth + px];
color += filter_value*static_cast<float>(inputChannel[c_y*numCols + c_x]);
}
}
outputChannel[thread_1D_pos] = color;
}
//This kernel takes in an image represented as a uchar4 and splits
//it into three images consisting of only one color channel each
__global__
void separateChannels(const uchar4* const inputImageRGBA,
int numRows,
int numCols,
unsigned char* const redChannel,
unsigned char* const greenChannel,
unsigned char* const blueChannel)
{
// NOTE: Be careful not to try to access memory that is outside the bounds of
// the image. You'll want code that performs the following check before accessing
// GPU memory:
const int2 thread_2D_pos = make_int2( blockIdx.x * blockDim.x + threadIdx.x,
blockIdx.y * blockDim.y + threadIdx.y);
const int thread_1D_pos = thread_2D_pos.y * numCols + thread_2D_pos.x;
const int absolute_image_position_x = thread_2D_pos.x;
const int absolute_image_position_y = thread_2D_pos.y;
if ( absolute_image_position_x >= numCols ||
absolute_image_position_y >= numRows )
{
return;
}
redChannel[thread_1D_pos] = inputImageRGBA[thread_1D_pos].x;
greenChannel[thread_1D_pos] = inputImageRGBA[thread_1D_pos].y;
blueChannel[thread_1D_pos] = inputImageRGBA[thread_1D_pos].z;
}
//This kernel takes in three color channels and recombines them
//into one image. The alpha channel is set to 255 to represent
//that this image has no transparency.
__global__
void recombineChannels(const unsigned char* const redChannel,
const unsigned char* const greenChannel,
const unsigned char* const blueChannel,
uchar4* const outputImageRGBA,
int numRows,
int numCols)
{
const int2 thread_2D_pos = make_int2( blockIdx.x * blockDim.x + threadIdx.x,
blockIdx.y * blockDim.y + threadIdx.y);
const int thread_1D_pos = thread_2D_pos.y * numCols + thread_2D_pos.x;
//make sure we don't try and access memory outside the image
//by having any threads mapped there return early
if (thread_2D_pos.x >= numCols || thread_2D_pos.y >= numRows)
return;
unsigned char red = redChannel[thread_1D_pos];
unsigned char green = greenChannel[thread_1D_pos];
unsigned char blue = blueChannel[thread_1D_pos];
//Alpha should be 255 for no transparency
uchar4 outputPixel = make_uchar4(red, green, blue, 255);
outputImageRGBA[thread_1D_pos] = outputPixel;
}
unsigned char *d_red, *d_green, *d_blue;
float *d_filter;
void allocateMemoryAndCopyToGPU(const size_t numRowsImage, const size_t numColsImage,
const float* const h_filter, const size_t filterWidth)
{
//allocate memory for the three different channels
//original
checkCudaErrors(cudaMalloc(&d_red, sizeof(unsigned char) * numRowsImage * numColsImage));
checkCudaErrors(cudaMalloc(&d_green, sizeof(unsigned char) * numRowsImage * numColsImage));
checkCudaErrors(cudaMalloc(&d_blue, sizeof(unsigned char) * numRowsImage * numColsImage));
//Allocate memory for the filter on the GPU
//Use the pointer d_filter that we have already declared for you
//You need to allocate memory for the filter with cudaMalloc
//be sure to use checkCudaErrors like the above examples to
//be able to tell if anything goes wrong
//IMPORTANT: Notice that we pass a pointer to a pointer to cudaMalloc
checkCudaErrors(cudaMalloc(&d_filter, sizeof( float) * filterWidth * filterWidth));
//Copy the filter on the host (h_filter) to the memory you just allocated
//on the GPU. cudaMemcpy(dst, src, numBytes, cudaMemcpyHostToDevice);
//Remember to use checkCudaErrors!
checkCudaErrors(cudaMemcpy(d_filter, h_filter, sizeof(float) * filterWidth * filterWidth, cudaMemcpyHostToDevice));
}
void postProcess(const std::string& output_file, uchar4* data_ptr) {
cv::Mat output(numRows(), numCols(), CV_8UC4, (void*)data_ptr);
cv::Mat imageOutputBGR;
cv::cvtColor(output, imageOutputBGR, CV_RGBA2BGR);
//output the image
cv::imwrite(output_file.c_str(), imageOutputBGR);
}
void cleanup(){
//cleanup
cudaFree(d_inputImageRGBA__);
cudaFree(d_outputImageRGBA__);
delete[] h_filter__;
}
int main(int argc,char* argv[]){
//load input file
std::string input_file = argv[1];
//define output file
std::string output_file = argv[2];
uchar4 *h_inputImageRGBA, *d_inputImageRGBA;
uchar4 *h_outputImageRGBA, *d_outputImageRGBA;
unsigned char *d_redBlurred, *d_greenBlurred, *d_blueBlurred;
float *h_filter;
int filterWidth;
//load the image and give us our input and output pointers
preProcess(&h_inputImageRGBA, &h_outputImageRGBA, &d_inputImageRGBA, &d_outputImageRGBA,
&d_redBlurred, &d_greenBlurred, &d_blueBlurred,
&h_filter, &filterWidth, input_file);
allocateMemoryAndCopyToGPU(numRows(), numCols(), h_filter, filterWidth);
const dim3 blockSize(16, 16);
const dim3 gridSize(numCols()/blockSize.x+1,numRows()/blockSize.y+1);
//Launch a kernel for separating the RGBA image into different color channels
separateChannels<<<gridSize, blockSize>>>(d_inputImageRGBA,
numRows(),
numCols(),
d_red,
d_green,
d_blue);
cudaDeviceSynchronize(); //checkCudaErrors(cudaGetLastError());
//Call your convolution kernel here 3 times, once for each color channel.
gaussian_blur<<<gridSize, blockSize>>>(d_red,
d_redBlurred,
numRows(),
numCols(),
d_filter,
filterWidth);
cudaDeviceSynchronize(); //checkCudaErrors(cudaGetLastError());
gaussian_blur<<<gridSize, blockSize>>>(d_green,
d_greenBlurred,
numRows(),
numCols(),
d_filter,
filterWidth);
cudaDeviceSynchronize(); //checkCudaErrors(cudaGetLastError());
gaussian_blur<<<gridSize, blockSize>>>(d_blue,
d_blueBlurred,
numRows(),
numCols(),
d_filter,
filterWidth);
cudaDeviceSynchronize(); //checkCudaErrors(cudaGetLastError());
// Now we recombine your results. We take care of launching this kernel for you.
//
// NOTE: This kernel launch depends on the gridSize and blockSize variables,
// which you must set yourself.
recombineChannels<<<gridSize, blockSize>>>(d_redBlurred,
d_greenBlurred,
d_blueBlurred,
d_outputImageRGBA,
numRows(),
numCols());
cudaDeviceSynchronize(); //checkCudaErrors(cudaGetLastError());
size_t numPixels = numRows()*numCols();
//copy the output back to the host
checkCudaErrors(cudaMemcpy(h_outputImageRGBA, d_outputImageRGBA__, sizeof(uchar4) * numPixels, cudaMemcpyDeviceToHost));
postProcess(output_file, h_outputImageRGBA);
checkCudaErrors(cudaFree(d_redBlurred));
checkCudaErrors(cudaFree(d_greenBlurred));
checkCudaErrors(cudaFree(d_blueBlurred));
cleanup();
return 0;
}
GPU程序优化–以矩阵转置为例




#include <stdio.h>
#include "gputimer.h"
const int N= 1024; // matrix size is NxN
const int K= 32; // tile size is KxK
// Utility functions: compare, print, and fill matrices
#define checkCudaErrors(val) check( (val), #val, __FILE__, __LINE__)
template<typename T>
void check(T err, const char* const func, const char* const file, const int line)
{
if (err != cudaSuccess) {
fprintf(stderr, "CUDA error at: %s : %d\n", file,line);
fprintf(stderr, "%s %s\n", cudaGetErrorString(err), func);;
exit(1);
}
}
int compare_matrices(float *gpu, float *ref)
{
int result = 0;
for(int j=0; j < N; j++)
for(int i=0; i < N; i++)
if (ref[i + j*N] != gpu[i + j*N])
{
// printf("reference(%d,%d) = %f but test(%d,%d) = %f\n",
// i,j,ref[i+j*N],i,j,test[i+j*N]);
result = 1;
}
return result;
}
void print_matrix(float *mat)
{
for(int j=0; j < N; j++)
{
for(int i=0; i < N; i++) { printf("%4.4g ", mat[i + j*N]); }
printf("\n");
}
}
// fill a matrix with sequential numbers in the range 0..N-1
void fill_matrix(float *mat)
{
for(int j=0; j < N * N; j++)
mat[j] = (float) j;
}
void
transpose_CPU(float in[], float out[])
{
for(int j=0; j < N; j++)
for(int i=0; i < N; i++)
out[j + i*N] = in[i + j*N]; // out(j,i) = in(i,j)
}
// to be launched on a single thread
__global__ void
transpose_serial(float in[], float out[])
{
for(int j=0; j < N; j++)
for(int i=0; i < N; i++)
out[j + i*N] = in[i + j*N]; // out(j,i) = in(i,j)
}
// to be launched with one thread per row of output matrix
__global__ void
transpose_parallel_per_row(float in[], float out[])
{
int i = threadIdx.x;
for(int j=0; j < N; j++)
out[j + i*N] = in[i + j*N]; // out(j,i) = in(i,j)
}
// to be launched with one thread per element, in KxK threadblocks
// thread (x,y) in grid writes element (i,j) of output matrix
__global__ void
transpose_parallel_per_element(float in[], float out[])
{
int i = blockIdx.x * K + threadIdx.x;
int j = blockIdx.y * K + threadIdx.y;
out[j + i*N] = in[i + j*N]; // out(j,i) = in(i,j)
}
// to be launched with one thread per element, in (tilesize)x(tilesize) threadblocks
// thread blocks read & write tiles, in coalesced fashion
// adjacent threads read adjacent input elements, write adjacent output elmts
__global__ void
transpose_parallel_per_element_tiled(float in[], float out[])
{
// (i,j) locations of the tile corners for input & output matrices:
int in_corner_i = blockIdx.x * K, in_corner_j = blockIdx.y * K;
int out_corner_i = blockIdx.y * K, out_corner_j = blockIdx.x * K;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[K][K];
// coalesced read from global mem, TRANSPOSED write into shared mem:
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y)*N];
__syncthreads();
// read from shared mem, coalesced write to global mem:
out[(out_corner_i + x) + (out_corner_j + y)*N] = tile[x][y];
}
// to be launched with one thread per element, in (tilesize)x(tilesize) threadblocks
// thread blocks read & write tiles, in coalesced fashion
// adjacent threads read adjacent input elements, write adjacent output elmts
__global__ void
transpose_parallel_per_element_tiled16(float in[], float out[])
{
// (i,j) locations of the tile corners for input & output matrices:
int in_corner_i = blockIdx.x * 16, in_corner_j = blockIdx.y * 16;
int out_corner_i = blockIdx.y * 16, out_corner_j = blockIdx.x * 16;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[16][16];
// coalesced read from global mem, TRANSPOSED write into shared mem:
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y)*N];
__syncthreads();
// read from shared mem, coalesced write to global mem:
out[(out_corner_i + x) + (out_corner_j + y)*N] = tile[x][y];
}
// to be launched with one thread per element, in KxK threadblocks
// thread blocks read & write tiles, in coalesced fashion
// shared memory array padded to avoid bank conflicts
__global__ void
transpose_parallel_per_element_tiled_padded(float in[], float out[])
{
// (i,j) locations of the tile corners for input & output matrices:
int in_corner_i = blockIdx.x * K, in_corner_j = blockIdx.y * K;
int out_corner_i = blockIdx.y * K, out_corner_j = blockIdx.x * K;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[K][K+1];
// coalesced read from global mem, TRANSPOSED write into shared mem:
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y)*N];
__syncthreads();
// read from shared mem, coalesced write to global mem:
out[(out_corner_i + x) + (out_corner_j + y)*N] = tile[x][y];
}
// to be launched with one thread per element, in KxK threadblocks
// thread blocks read & write tiles, in coalesced fashion
// shared memory array padded to avoid bank conflicts
__global__ void
transpose_parallel_per_element_tiled_padded16(float in[], float out[])
{
// (i,j) locations of the tile corners for input & output matrices:
int in_corner_i = blockIdx.x * 16, in_corner_j = blockIdx.y * 16;
int out_corner_i = blockIdx.y * 16, out_corner_j = blockIdx.x * 16;
int x = threadIdx.x, y = threadIdx.y;
__shared__ float tile[16][16+1];
// coalesced read from global mem, TRANSPOSED write into shared mem:
tile[y][x] = in[(in_corner_i + x) + (in_corner_j + y)*N];
__syncthreads();
// read from shared mem, coalesced write to global mem:
out[(out_corner_i + x) + (out_corner_j + y)*N] = tile[x][y];
}
int main(int argc, char **argv)
{
int numbytes = N * N * sizeof(float);
float *in = (float *) malloc(numbytes);
float *out = (float *) malloc(numbytes);
float *gold = (float *) malloc(numbytes);
fill_matrix(in);
transpose_CPU(in, gold);
float *d_in, *d_out;
cudaMalloc(&d_in, numbytes);
cudaMalloc(&d_out, numbytes);
cudaMemcpy(d_in, in, numbytes, cudaMemcpyHostToDevice);
GpuTimer timer;
/*
* Now time each kernel and verify that it produces the correct result.
*
* To be really careful about benchmarking purposes, we should run every kernel once
* to "warm" the system and avoid any compilation or code-caching effects, then run
* every kernel 10 or 100 times and average the timings to smooth out any variance.
* But this makes for messy code and our goal is teaching, not detailed benchmarking.
*/
timer.Start();
transpose_serial<<<1,1>>>(d_in, d_out);
timer.Stop();
cudaMemcpy(out, d_out, numbytes, cudaMemcpyDeviceToHost);
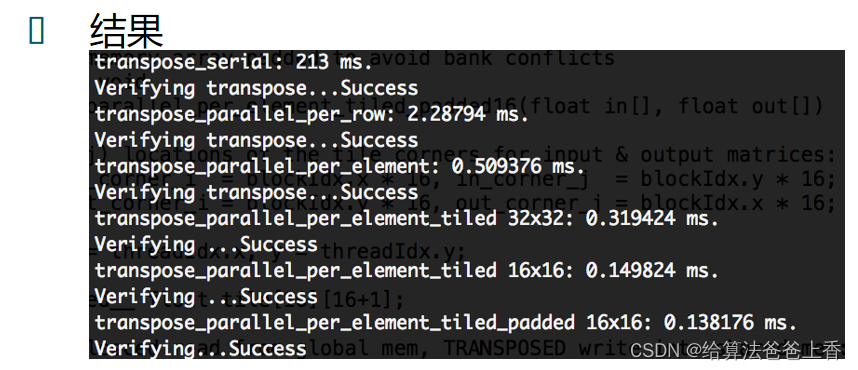
printf("transpose_serial: %g ms.\nVerifying transpose...%s\n",
timer.Elapsed(), compare_matrices(out, gold) ? "Failed" : "Success");
timer.Start();
transpose_parallel_per_row<<<1,N>>>(d_in, d_out);
timer.Stop();
cudaMemcpy(out, d_out, numbytes, cudaMemcpyDeviceToHost);
printf("transpose_parallel_per_row: %g ms.\nVerifying transpose...%s\n",
timer.Elapsed(), compare_matrices(out, gold) ? "Failed" : "Success");
dim3 blocks(N/K,N/K); // blocks per grid
dim3 threads(K,K); // threads per block
timer.Start();
transpose_parallel_per_element<<<blocks,threads>>>(d_in, d_out);
timer.Stop();
cudaMemcpy(out, d_out, numbytes, cudaMemcpyDeviceToHost);
printf("transpose_parallel_per_element: %g ms.\nVerifying transpose...%s\n",
timer.Elapsed(), compare_matrices(out, gold) ? "Failed" : "Success");
timer.Start();
transpose_parallel_per_element_tiled<<<blocks,threads>>>(d_in, d_out);
timer.Stop();
cudaMemcpy(out, d_out, numbytes, cudaMemcpyDeviceToHost);
printf("transpose_parallel_per_element_tiled %dx%d: %g ms.\nVerifying ...%s\n",
K, K, timer.Elapsed(), compare_matrices(out, gold) ? "Failed" : "Success");
dim3 blocks16x16(N/16,N/16); // blocks per grid
dim3 threads16x16(16,16); // threads per block
timer.Start();
transpose_parallel_per_element_tiled16<<<blocks16x16,threads16x16>>>(d_in, d_out);
timer.Stop();
cudaMemcpy(out, d_out, numbytes, cudaMemcpyDeviceToHost);
printf("transpose_parallel_per_element_tiled 16x16: %g ms.\nVerifying ...%s\n",
timer.Elapsed(), compare_matrices(out, gold) ? "Failed" : "Success");
timer.Start();
transpose_parallel_per_element_tiled_padded16<<<blocks16x16,threads16x16>>>(d_in, d_out);
timer.Stop();
cudaMemcpy(out, d_out, numbytes, cudaMemcpyDeviceToHost);
printf("transpose_parallel_per_element_tiled_padded 16x16: %g ms.\nVerifying...%s\n",
timer.Elapsed(), compare_matrices(out, gold) ? "Failed" : "Success");
cudaFree(d_in);
cudaFree(d_out);
}