深度学习论文分享(六)Simple Baselines for Image Restoration
- 前言
- Abstract
- 1 Introduction
- 2 Related Works
- 2.1 Image Restoration
- 2.2 Gated Linear Units
- 3 Build A Simple Baseline
- 3.1 Architecture
- 3.2 A Plain Block
- 3.3 Normalization
- 3.4 Activation
- 3.5 Attention
- 3.6 Summary
- 4 Nonlinear Activation Free Network
- 5 Experiments
- 5.1 Ablations
- 5.2 Applications
- 6 Conclusions
- Appendix
- A Other Details
- A.1 Inverted Bottleneck
- A.2 Channel Attention and Simplified Channel Attention
- A.3 Feature Fusion
- A.4 Downsample/Upsample Layer
- B More Visualization Results
- References
前言
论文原文:https://arxiv.org/abs/2204.0467
论文代码:https://github.com/megvii-research/NAFNet
Title:Simple Baselines for Image Restoration
Authors:Liangyu Chen ⋆ , Xiaojie Chu ⋆ , Xiangyu Zhang, and Jian Sun
MEGVII Technology, Beijing, CN
在此仅做翻译
Abstract
尽管近年来在图像恢复领域取得了重大进展,但最先进的(SOTA)方法的系统复杂性也在增加,这可能会阻碍方法的方便分析和比较。在本文中,我们提出了一个简单的基线,它超过了SOTA方法,并且计算效率很高。为了进一步简化基线,我们揭示了非线性激活函数,如Sigmoid, ReLU, GELU, Softmax等是不必要的:它们可以用乘法代替或删除。因此,我们从基线推导出一个非线性激活自由网络,即NAFNet。SOTA结果在各种具有挑战性的基准上实现,例如GoPro上的33.69 dB PSNR(用于图像去模糊),超过了之前的SOTA 0.38 dB,计算成本仅为其8.4%;在SIDD(用于图像去噪)上的PSNR为40.30 dB,超过了之前的SOTA 0.28 dB,计算成本不到其一半。代码和预训练的模型在github.com/megvii-research/NAFNet上发布。
关键词:图像恢复,图像去噪,图像去模糊
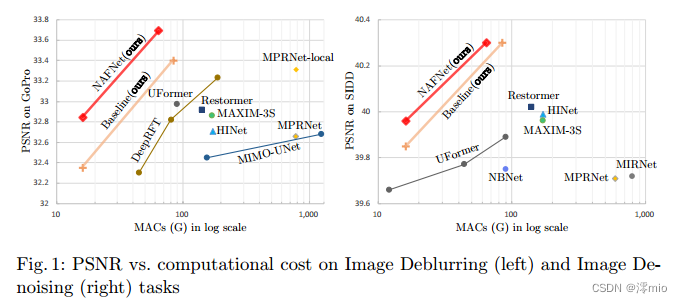
图1:图像去模糊(左)和图像去噪(右)任务上的PSNR与计算成本
1 Introduction
随着深度学习的发展,图像恢复方法的性能有了很大的提高。基于深度学习的方法[5,37,39,36,6,7,32,8,25]已经取得了巨大的成功。例[39]和[8]分别在SIDD[1]/GoPro[26]上实现40.02/33.31 dB的PSNR去噪/去模糊。
尽管这些方法具有良好的性能,但它们的系统复杂性很高。为了便于讨论,我们将系统复杂度分解为两部分:块间复杂度和块内复杂度。首先是块间复杂性,如图2所示。[7,25]引入不同大小的特征映射之间的联系;[5,37]是多阶段网络,后一阶段对前一阶段的结果进行细化。第二,块内复杂性,即块内的各种设计选择。例如[39]中的多Dconv头转置注意模块和门控Dconv前馈网络(如图3a所示),[22]中的Swin变压器块,[5]中的HINBlock等。逐个评估设计选择是不现实的。
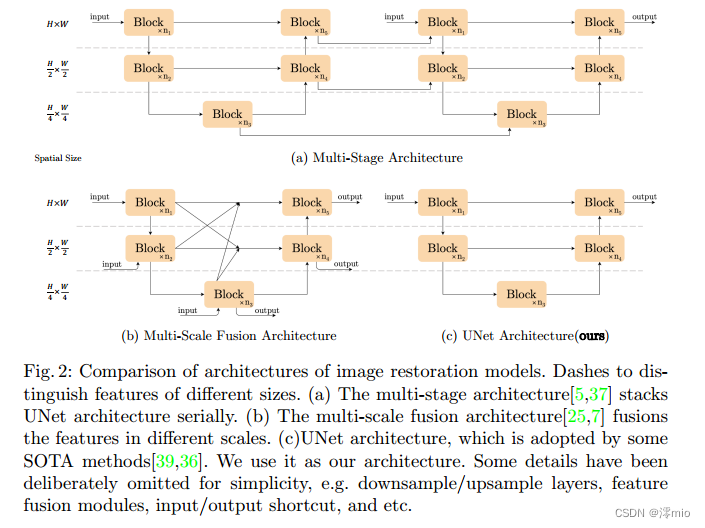
图2:图像恢复模型的架构比较。用破折号来区分不同大小的特征。(a)多阶段架构[5,37]将UNet架构按顺序堆叠。(b)多尺度融合架构[25,7]融合了不同尺度的特征。©UNet架构,一些SOTA方法采用UNet架构[39,36]。我们用它作为我们的架构。为了简单起见,我们故意省略了一些细节,例如下采样/上采样层、特征融合模块、输入/输出快捷方式等。
基于上述事实,一个自然的问题出现了:低块间和低块内复杂度的网络是否有可能实现SOTA性能?为了实现第一个条件(低块间复杂度),本文采用单阶段UNet作为架构(遵循一些SOTA方法[39,36]),重点研究第二个条件。为此,我们从一个包含最常见组件的普通块开始,即卷积、ReLU和快捷方式[14]。从普通块中,我们添加/替换SOTA方法的组件,并验证这些组件带来了多少性能增益。通过广泛的消融研究,我们提出了一个简单的基线,如图3c所示,它超过了SOTA方法,并且计算效率高。它有可能激发新的想法,并使其更容易验证。包含GELU[15]和Channel Attention Module[16] (CA)的基线可以进一步简化:我们发现基线中的GELU可以被视为门控线性单元10的一个特例,并由此经验证明它可以被一个简单的门(即特征映射的元素积)所取代。此外,我们还揭示了CA与GLU在形式上的相似性,并且CA中的非线性激活函数也可以被去除。总之,简单的基线可以进一步简化为一个非线性的无激活网络,称为NAFNet。我们主要在SIDD[1]上进行图像去噪实验,在GoPro[26]上进行图像去模糊实验,依次进行[5,39,37]。主要结果如图1所示,我们提出的基线和NAFNet在达到SOTA结果的同时计算效率很高:在GoPro上33.40/33.69 dB,分别超过之前的SOTA[8] 0.09/0.38 dB,计算成本为其8.4%;在SIDD上40.30 dB,超过[39]0.28 dB,而计算成本不到其一半。进行了大量和高质量的实验来说明我们提出的基线的有效性。
本文的贡献总结如下:
- 通过分解SOTA方法并提取其基本组件,我们形成了一个具有较低系统复杂性的基线(如图3c),它可以超过以前的SOTA方法,并且具有较低的计算成本,如图1所示。它可以方便研究人员激发新的想法并方便地对其进行评价。
- 通过揭示GELU (Channel Attention to Gated Linear Unit)之间的联系,我们通过去除或替换非线性激活函数(如Sigmoid、ReLU和GELU)进一步简化了基线,并提出了一个非线性无激活网络,即NAFNet。虽然经过了简化,但可以达到或超过基线。据我们所知,这是第一个证明非线性激活函数可能不是SOTA计算机视觉方法所必需的工作。这项工作可能有潜力扩大SOTA计算机视觉方法的设计空间。
2 Related Works
2.1 Image Restoration
图像恢复任务的目的是将退化的图像(如噪声、模糊)恢复到干净的图像。最近,基于深度学习的方法[5,37,39,36,6,7,32,8,25]在这些任务上取得了SOTA结果,并且大多数方法可以被视为经典解UNet[29]的变体。它将块堆叠成u型结构,并采用跳接。这些变体带来了性能的提高,以及系统的复杂性,我们将复杂性大致分为块间复杂性和块内复杂性。
Inter-block Complexity:
[37,5]是多阶段网络,即后一阶段对前一阶段的结果进行细化,每一阶段都是一个u型架构。该设计基于这样的假设:将困难的图像恢复任务分解为几个子任务有助于提高性能。不同的是,[7,25]采用单阶段设计,取得了有竞争力的结果,但它们引入了不同大小的特征图之间复杂的联系。有些方法同时采用了以上两种策略,如[32]。其他SOTA方法,例如:[39,36]保持了单级UNet的简单结构,但它们引入了块内复杂性,我们将在下文中讨论。
Intra-block Complexity:有许多不同的块内设计方案,我们在这里挑选一些例子。[39]通过通道注意图而不是空间注意图来降低自我注意的记忆和时间复杂性[34]。此外,前馈网络采用了门控线性单元[10]和深度卷积。[36]引入了基于窗口的多头自我注意,类似于[22]。此外,在其块中引入了局部增强前馈网络,在前馈网络中加入深度卷积,增强了局部信息捕获能力。不同的是,我们揭示了增加系统复杂性并不是提高性能的唯一方法:SOTA性能可以通过简单的基线来实现。
2.2 Gated Linear Units
门控线性单元10可以通过两个线性变换层的元素生成来解释,其中一个是由非线性激活的。GLU及其变体已经在NLP中验证了其有效性[30,10,9],在计算机视觉中也有蓬勃发展的趋势[32,39,17,20]。在本文中,我们揭示了GLU带来的重要改进。与[30]不同的是,我们在GLU中去掉了非线性激活函数而没有性能下降。此外,基于非线性无激活的GLU本身包含非线性(因为两个线性变换的乘积会引起非线性)这一事实,我们的基线可以通过用两个特征映射的乘法替换非线性激活函数来简化。据我们所知,这是第一个在没有非线性激活函数的情况下实现SOTA性能的计算机视觉模型。
3 Build A Simple Baseline
在本节中,我们从头开始为图像恢复任务构建一个简单的基线。为了保持结构简单,我们的原则是不添加不必要的实体。通过对恢复任务的实证评价,验证了恢复任务的必要性。我们主要采用HINet Simple[5]进行模型大小在16 gmac左右的实验,通过空间大小为256 × 256的输入来估计mac。不同容量模型的计算结果见实验部分。我们主要在两个流行的数据集上验证结果(PSNR),用于去噪(即SIDD[1])和去模糊(即GoPro[26]数据集),基于这些任务是低级视觉的基础。设计选择将在以下小节中讨论。
3.1 Architecture
为了降低块间复杂度,我们采用了经典的单级u型架构,并采用了跳过连接,如图2c所示[39,36]。我们相信架构不会成为性能的障碍。实验结果证实了我们的猜想,如表6、7和图1所示。
3.2 A Plain Block
神经网络是按块堆叠的。我们已经确定了如何在上面堆叠块(即在UNet架构中堆叠),但是如何设计块的内部结构仍然是一个问题。我们从一个包含最常见组件的普通块开始,即convolution, ReLU和shortcut[14],这些组件的排列遵循[13,22],如图3b所示。为简单起见,我们将其记为PlainNet。使用卷积网络代替transformer是基于以下考虑。首先,虽然transformer在计算机视觉中表现良好,但一些作品[13,23]声称它们可能不是实现SOTA结果所必需的。其次,深度卷积比自注意机制更简单[34]。第三,本文不打算讨论transformer和卷积神经网络的优缺点,而只是提供一个简单的基线。关于注意机制的讨论将在下一小节中提出。
3.3 Normalization
归一化在高级计算机视觉任务中被广泛采用,在低级视觉中也有流行的趋势。虽然[26]放弃了Batch Normalization[18],因为小批量可能带来不稳定的统计数据[38],[5]重新引入了Instance Normalization[33],避免了小批量问题。然而,[5]表明,添加实例规范化并不总是带来性能提升,需要手动调优。不同的是,在变压器的繁荣下,层归一化[3]被越来越多的方法使用,包括SOTA方法[32,39,36,23,22]。基于这些事实,我们推测层规范化可能对SOTA恢复至关重要,因此我们将层规范化添加到上面描述的普通块中。这种变化可以使训练更加顺利,即使学习率提高了10倍。更大的学习率带来了显著的性能增益:在SIDD[1]上+0.44 dB (39.29 dB至39.73 dB),在GoPro[26]数据集上+3.39 dB (28.51 dB至31.90 dB)。综上所述,我们将图层归一化添加到普通块中,因为它可以稳定训练过程。
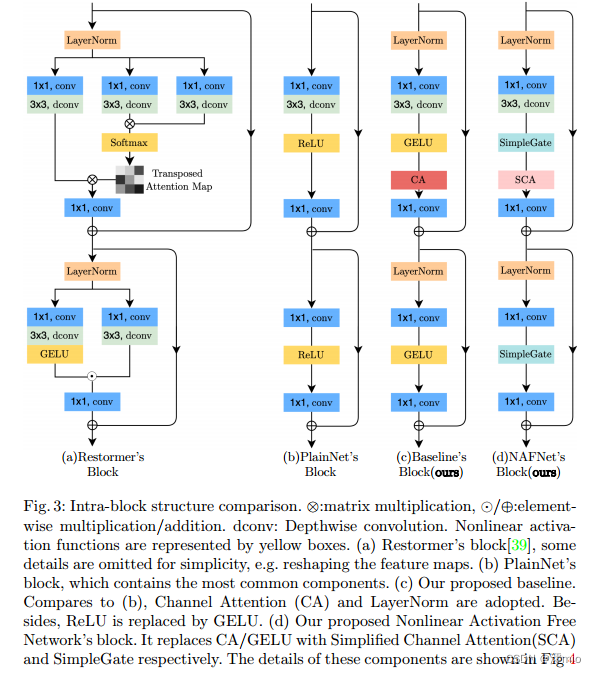
图3:块内结构对比。⊗:矩阵乘法,⊙/⊕:元素乘法/加法。dconv:深度卷积。非线性激活函数用黄色方框表示。(a) Restormer’s block[39],为了简单起见,省略了一些细节,例如重塑特征映射。(b) PlainNet的块,其中包含最常见的组件。©我们建议的基线。与(b)相比,采用了CA (Channel Attention)和LayerNorm。此外,ReLU被GELU取代。(d)我们提出的非线性激活自由网络块。它分别用简化通道注意(SCA)和SimpleGate取代CA/GELU。这些组件的详细信息如图4所示
3.4 Activation
普通块中的激活函数,整流线性单元28,在计算机视觉中被广泛使用。然而,在SOTA方法[23,39,32,22,12]中,有用GELU代替ReLU的趋势[15]。这种替换也在我们的模型中实现。在SIDD上(从39.73 dB到39.71 dB)性能保持相当,这与[23]的结论一致,但在GoPro上带来0.21 dB的性能增益(31.90 dB到32.11 dB)。简而言之,我们在纯块中用GELU代替ReLU,因为它在保持图像去噪性能的同时,在图像去模糊方面带来了不小的增益。
3.5 Attention
鉴于近年来transformer在计算机视觉领域的普及,其注意机制是块体内部结构设计中不可回避的课题。注意机制有很多变体,我们在这里只讨论其中的一些。[12,4]采用的vanilla自注意机制[34]通过将所有特征线性组合生成目标特征,并根据特征之间的相似度进行加权。因此,每个特征都包含全局信息,但其计算复杂度与特征映射的大小呈二次关系。一些图像恢复任务处理的数据是高分辨率的,这使得传统的自关注方法不实用。或者,[22,21,36]仅在固定大小的局部窗口中应用自关注,以减轻计算量增加的问题。虽然它缺乏全球信息。我们不采取基于窗口的关注,因为在普通块中,深度卷积可以很好地捕获局部信息[13,23]。
不同的是,[39]将空间关注改为通道关注,在保持每个特征的全局信息的同时避免了计算问题。它可以被看作是通道注意的一种特殊变体[16]。受[39]的启发,我们意识到香草通道关注满足了计算效率的要求,并为特征映射带来了全局信息。此外,通道关注的有效性已经在图像恢复任务中得到验证[37,8],因此我们将通道关注添加到plain block中。在SIDD[1]数据集(39.71 ~ 39.85 dB)上得到0.14 dB,在GoPro[26]数据集上得到0.24 dB (32.11 ~ 32.35 dB)。
3.6 Summary
到目前为止,我们从头开始构建了一个简单的基线,如表1所示。架构和模块分别如图2c和图3c所示。基线中的每个组件都是微不足道的,例如层归一化,卷积,GELU和通道注意。但是,这些琐碎组件的组合导致了一个强大的基线:它可以超过以前在SIDD和GoPro数据集上的SOTA结果,而计算成本只有一小部分,如图1和表6,7所示。我们相信简单的基线可以帮助研究人员评估他们的想法。
4 Nonlinear Activation Free Network
上面描述的基线是简单且有竞争力的,但是在确保简单性的同时是否有可能进一步提高性能呢?它能在不损失性能的情况下变得更简单吗?我们试图通过寻找一些SOTA方法的共性来回答这些问题[32,39,20,17]。我们发现在这些方法中,采用了门控线性单元10。这意味着GLU可能很有前途。我们接下来再讨论。
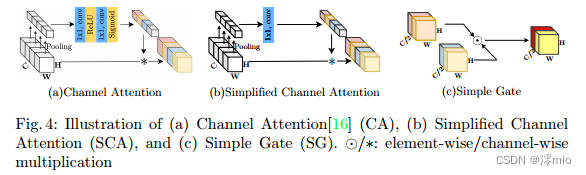
图4:(a)通道注意16、(b)简化通道注意(SCA)和©简单门(SG)的示意图。⊙/ *:元素/通道乘法
Gated Linear Units:门控线性单元可表示为:
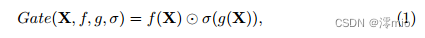
其中X表示特征映射,f和g是线性变压器,σ是非线性激活函数,例如Sigmoid,⊙表示逐元乘法。如上所述,将GLU添加到我们的基线可能会提高性能,但块内复杂性也会增加。这不是我们所期望的。为了解决这个问题,我们重新审视基线中的激活函数,即GELU[15]:

式中Φ为标准正态分布的累积分布函数。基于[15],GELU可以近似实现为:
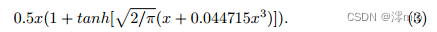
由Eqn. 1和Eqn. 2可知,GELU是GLU的一个特例,即f、g为恒等函数,取σ为Φ。通过相似性,我们从另一个角度推测,GLU可以看作是激活函数的一种推广,它可以代替非线性激活函数。此外,我们注意到GLU本身包含非线性并且不依赖于σ:即使σ被去除,Gate(X) = f(X)⊙g(X)也包含非线性。在此基础上,我们提出了一种简单的GLU变体:直接将特征映射在通道维度上分成两部分,并将它们相乘,如图4c所示,称为SimpleGate。与Eqn.3中GELU的复杂实现相比,我们的SimpleGate可以通过元素智能乘法实现,仅此而已:
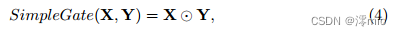
其中X和Y是相同大小的特征图。
通过将基线中的GELU替换为所提出的SimpleGate,图像去噪(在SIDD[1]上)和图像去模糊(在GoPro[26]数据集上)的性能分别提高0.08 dB (39.85 dB至39.93 dB)和0.41 dB (32.35 dB至32.76 dB)。结果表明,我们提出的SimpleGate可以取代GELU。此时,网络中只剩下几种类型的非线性激活:通道注意模块中的Sigmoid和ReLU[16],接下来我们将讨论其简化。
Simplified Channel Attention:在第3节中,我们将通道注意力[16]引入到我们的块中,因为它捕获全局信息并且计算效率高。如图4a所示:它首先将空间信息压缩到通道中,然后对其应用多层感知来计算通道注意力,并将其用于加权特征图。它可以表示为:
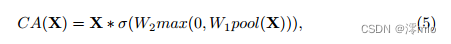
其中,X表示特征图,pool表示将空间信息聚合到通道中的全局平均池化操作。σ为非线性激活函数,Sigmoid、W1、W2为全连通层,全连通层之间采用ReLU。最后,*是一个channel - wise product操作。如果我们将通道注意力计算看作一个函数,记为Ψ,输入为X,则Eqn. 5可以重写为:

可以注意到,Eqn. 6与Eqn. 1非常相似。这启发我们将渠道注意力视为GLU的一个特例,可以像前一小节中的GLU一样简化。通过保留渠道注意的两个最重要的作用,即聚合全局信息和渠道信息交互,我们提出了简化的渠道注意:
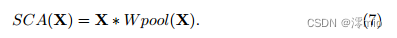
符号遵循公式5。显然,简化通道注意(Eqn. 7)比原始通道注意(Eqn. 5)更简单,如图4a和图4b所示。虽然它更简单,但没有性能损失:在SIDD上+0.03 dB (39.93 dB到39.96 dB),在GoPro上+0.09 dB (32.76 dB到32.85 dB)。
Summary:从第3节中提出的基线开始,我们通过将GELU替换为SimpleGate和简化通道注意来进一步简化它,而不会损失性能。我们强调简化后的网络中不存在非线性激活函数(如ReLU、GELU、Sigmoid等)。所以我们称之为基线非线性激活自由网络,即NAFNet。它可以匹配或超过基线,尽管没有非线性激活函数,如图1和表6,7所示。由于NAFNet的简单性和有效性,我们现在可以回答本节开头的问题
5 Experiments
在本节中,我们将详细分析前几节中描述的NAFNet设计选择的影响。接下来,我们将提出的NAFNet应用于各种图像恢复应用,包括RGB图像去噪、图像去模糊、原始图像去噪和JPEG伪影图像去模糊。

图5基于SIDD的图像去噪方法定性比较[1]
5.1 Ablations
消融研究主要针对图像去噪(SIDD[1])和去模糊(GoPro[26])任务。如果没有指定,我们遵循[5]的实验设置,例如计算预算、梯度剪辑和PSNR损失的16个gmac。我们使用Adam[19]优化器(β1 = 0.9, β2 = 0.9,权重衰减0)训练模型,总迭代次数为200K,初始学习率1e−3逐渐降低到1e−6,采用余弦退火调度[24]。训练补丁大小为256 × 256,批大小为32。通过patch训练和全图像测试会导致性能下降[8],我们采用MPRNet-local[8]之后的TLC[8]来解决这个问题。TLC对GoPro1的影响见表4。我们主要将TLC与[5]、[25]等采用的“贴片检测”策略进行比较。它带来了性能提升,并避免了补丁带来的工件。此外,我们使用skip-init[11]来稳定训练后续[23]。块的默认宽度和数量分别为32和36。如果块的数量发生变化,我们调整宽度以保持计算预算不变。我们在实验中报告了峰值信噪比(PSNR)和结构相似性(SSIM)。在NVIDIA 2080Ti GPU上,以256 × 256的输入大小进行速度/内存/计算复杂度评估。
From PlainNet to the simple baseline: PlainNet在第3节中定义,其模块如图3b所示。我们发现在默认设置下,PlainNet的训练是不稳定的。作为替代方案,我们将学习率(lr)降低了10倍,以使模型可训练。通过引入层归一化(LN)解决了这个问题:学习率可以从1e−4增加到1e−3,并且训练过程更稳定。在PSNR上,LN在SIDD和GoPro上分别带来0.46 dB和3.39 dB。此外,GELU和通道注意(Channel Attention, CA)在表1中也显示了其有效性。
From the simple baseline to NAFNet:
如第3节所述,NAFNet可以通过简化基线来获得。在表2中,我们展示了这种简化没有性能损失。相反,在SIDD和GoPro中,PSNR分别提高0.11 dB和0.50 dB。为了公平的比较,计算复杂度是一致的,详细信息请参见补充材料。提供了与基线相比修改的加速。此外,在推理中,与Baseline相比没有显著的额外内存消耗。

表1:从PlainNet构建一个简单的基线。验证了层归一化(LN)、GELU和信道注意(CA)的有效性。*表示由于学习率(lr)大,训练是不稳定的。
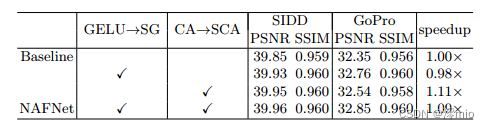
表2:NAFNet来源于基线的简化,即将GELU替换为SimpleGate (SG),将Channel Attention (CA)替换为Simplified Channel Attention (SCA)。
Number of blocks: 我们在表3中验证了区块数量对NAFNet的影响。我们主要考虑720 × 1280空间大小的延迟,因为这是整个GoPro图像的大小。在将区块数量增加到36个的过程中,模型的性能得到了很大的提高,并且延迟没有明显增加(与9个区块相比+14.5%)。当区块数量进一步增加到72个时,模型的性能提升并不明显,但延迟明显增加(与36个区块相比增加了30.0%)。因为36块可以实现更好的性能/延迟平衡,所以我们使用它作为默认选项。
Variants of σ in SimpleGate:
Vanilla门控线性单元(GLU)包含一个非线性激活函数σ,如公式Eqn. 1所示。我们建议的SimpleGate,如图4和图4c所示,将其删除。换句话说,SimpleGate中的σ被设置为恒等函数。我们将单位函数中的σ变量化为表5中不同的非线性激活函数,以判断σ中非线性的重要性。SIDD上的PSNR基本不受影响(从39.96 dB波动到39.99 dB),而GoPro上的PSNR显著下降(从-0.11 dB下降到-0.35 dB),这表明在NAFNet中,SimpleGate中的σ可能不需要。
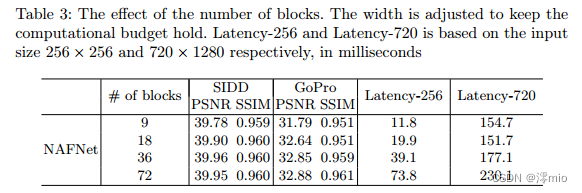
表3:区块数量的影响。调整宽度以保持计算预算保持不变。Latency-256和Latency-720分别基于输入大小256 × 256和720 × 1280,单位为毫秒
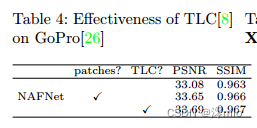
表4:TLC对GoPro的有效性[8][26]
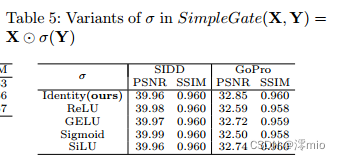
表5:SimpleGate(X, Y) = X⊙σ(Y)中σ的变量
5.2 Applications
我们将NAFNet应用于各种图像恢复任务,如果没有指定,则遵循消融研究的训练设置,除了将其宽度从32增加到64。批大小和总训练迭代数分别为64和400K,如下[5]。应用随机作物增强。我们报告三个实验结果的平均值。为了获得更好的结果,基线被放大,详情见附录。
RGB Image Denoising 我们将RGB图像去噪结果与其他SOTA方法在SIDD上进行比较,如表6所示。Baseline及其简化版本NAFNet,以其计算成本的一小部分超过了之前的最佳结果Restormer 0.28 dB,如图1所示。定性结果如图5所示。与其他方法相比,我们提出的基线可以恢复更精细的细节。此外,我们在在线基准测试中获得了40.15 dB的SOTA结果,超过了之前排名靠前的方法0.23 dB。
Image Deblurring 我们在GoPro[26]数据集上比较SOTA方法的去模糊结果,采用翻转和旋转增强。如表7和图1所示,我们的基线和NAFNet的PSNR分别超过了之前的最佳方法MPRNet-local[8],分别为0.09 dB和0.38 dB,而计算成本仅为其8.4%。可视化结果如图6所示,与其他方法相比,我们的基线可以恢复更清晰的结果。

图6 GoPro上图像去模糊方法的定性比较[26]

表6 SIDD图像去噪结果[1]
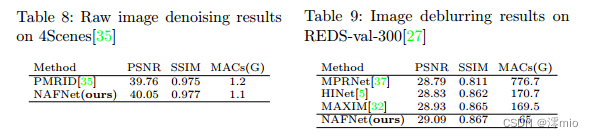
Raw Image Denoising 我们将NAFNet应用于原始图像去噪任务。训练和测试设置遵循PMRID[35],为了简单起见,我们将测试集记为4Scenes(因为数据集包含不同光照条件下4个不同场景的39张原始图像)。此外,我们通过将NAFNet的宽度和块数分别从32块改为16块和36块改为7块进行公平比较,使计算成本低于PMRID。表8和图7所示的结果表明NAFNet可以在数量和质量上超过PMRID。此外,该实验表明我们的NAFNet可以灵活地扩展(从1.1 gmac到65 gmac)。
Image Deblurring with JPEG artifacts 我们在REDS[27]数据集上进行实验,训练集如下[5,32],我们在验证集(记为red -val-300)中的300张图像上评估结果[5,32]。如表9所示,我们的方法优于其他竞争方法,包括之前在NTIRE 2021图像去模糊挑战Track2 JPEG工件的red数据集上的获胜方案(HINet)[27]。

表7 GoPro图像去模糊效果[26]

图7:PMRID[35]和我们的NAFNet的降噪效果的定性比较。放大查看细节
6 Conclusions
通过对SOTA方法进行分解,提取出基本的组件,并将其应用于朴素的PlainNet中。得到的基线在图像去噪和去模糊任务中达到SOTA性能。通过对基线的分析,我们发现它可以进一步简化:可以完全替换或去除其中的非线性激活函数。在此基础上,我们提出了一种非线性无激活网络——NAFNet。虽然简化了,但其性能等于或优于基线。我们提出的基线可能有助于研究人员评估他们的想法。此外,这项工作有可能影响未来的计算机视觉模型设计,因为我们证明了非线性激活函数不是实现SOTA性能所必需的。
致谢:本研究得到国家重点研发计划项目(No. 2017YFA0700800)和北京市人工智能研究院(BAAI)的支持。
Appendix
A Other Details
A.1 Inverted Bottleneck
如下[23],我们在基线和NAFNet中采用了倒瓶颈设计。我们首先讨论消融研究的背景。在基线中,第一个跳跃连接内的通道宽度始终与输入一致,其计算代价可近似为:
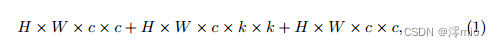
其中H、W为特征映射的空间大小,c为输入维数,k为深度卷积的核大小(我们实验中为3)。在实际中,c比k要高,所以是Eqn。(1)≈2 × H × W × c × c,第二个跳槽连接内隐藏维数为输入维数的2倍,其计算代价为:
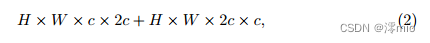
notations following Eqn. (1).因此,一个基线块的总计算代价≈6 × H × W × c × c
至于NAFNet的块,SimpleGate模块将通道宽度缩小了一半。我们将第一个跳跃连接的隐藏维数加倍,其计算代价近似为:
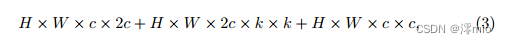
notations following Eqn. (1)…且第二跳接的隐维遵循基线。其计算成本为:
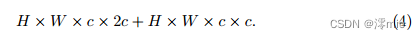
因此,一个NAFNet区块的总计算成本≈6 × H × W ×c×c,与基线的区块一致。这样做的好处是基线和NAFNet可以共享超参数,如块数量、学习率等。
对于应用程序,扩展了基线的第一个跳跃连接的隐藏维度,以获得更好的结果。此外,需要注意的是,上面的讨论省略了一些模块的计算,例如层归一化、GELU、通道注意等,因为它们的计算成本与卷积相比可以忽略不计。

A.2 Channel Attention and Simplified Channel Attention
对于宽度为c的特征图,通道注意模块将其缩小r倍,然后将其投影回c(通过完全连接层)。计算成本可以近似为c × c/r + c/r × c,对于简化的信道注意力模块,其计算成本为c × c,为了公平比较,我们选择r = 2,使它们在实验中的计算成本一致。
A.3 Feature Fusion
从编码器块到解码器块之间存在跳跃式连接,并且有几种方法可以融合编码器/解码器的特性。在[5]中,编码器特征通过卷积变换,然后与解码器特征连接。在[39]中,首先将特征连接起来,然后通过卷积进行变换。不同的是,我们简单地按元素添加编码器和解码器特征作为特征融合方法。
A.4 Downsample/Upsample Layer
对于下样本层,我们使用核大小为2,步长为2的卷积。这种设计选择的灵感来自[2]。对于上采样层,我们首先通过逐点卷积将通道宽度加倍,然后遵循像素洗刷模块[31]。
B More Visualization Results
我们提供了原始图像去噪、图像去模糊、RGB图像去噪任务的额外可视化结果,如图1、2和3所示。与其他方法相比,我们的基线可以恢复更精细的细节。建议放大,对比红色框内的详细信息。
References
-
Abdelhamed, A., Lin, S., Brown, M.S.: A high-quality denoising dataset for smartphone cameras. In: IEEE Conference on Computer Vision and Pattern Recognition
(CVPR) (June 2018) -
Alsallakh, B., Kokhlikyan, N., Miglani, V., Yuan, J., Reblitz-Richardson, O.: Mind
the pad–cnns can develop blind spots. arXiv preprint arXiv:2010.02178 (2020) -
Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint
arXiv:1607.06450 (2016) -
Chen, H., Wang, Y., Guo, T., Xu, C., Deng, Y., Liu, Z., Ma, S., Xu, C., Xu, C., Gao,
W.: Pre-trained image processing transformer. In: Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition. pp. 12299–12310 (2021) -
Chen, L., Lu, X., Zhang, J., Chu, X., Chen, C.: Hinet: Half instance normalization
network for image restoration. In: Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition. pp. 182–192 (2021) -
Cheng, S., Wang, Y., Huang, H., Liu, D., Fan, H., Liu, S.: Nbnet: Noise basis learning for image denoising with subspace projection. In: Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4896–
4906 (2021) -
Cho, S.J., Ji, S.W., Hong, J.P., Jung, S.W., Ko, S.J.: Rethinking coarse-to-fine approach in single image deblurring. In: Proceedings of the IEEE/CVF International
Conference on Computer Vision. pp. 4641–4650 (2021) -
Chu, X., Chen, L., , Chen, C., Lu, X.: Improving image restoration by revisiting
global information aggregation. arXiv preprint arXiv:2112.04491 (2021) -
Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q.V., Salakhutdinov, R.:
Transformer-xl: Attentive language models beyond a fixed-length context. arXiv
preprint arXiv:1901.02860 (2019) -
Dauphin, Y.N., Fan, A., Auli, M., Grangier, D.: Language modeling with gated
convolutional networks. In: International conference on machine learning. pp. 933– -
PMLR (2017)
-
De, S., Smith, S.: Batch normalization biases residual blocks towards the identity
function in deep networks. Advances in Neural Information Processing Systems
33, 19964–19975 (2020) -
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner,
T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is
worth 16x16 words: Transformers for image recognition at scale. arXiv preprint
arXiv:2010.11929 (2020) -
Han, Q., Fan, Z., Dai, Q., Sun, L., Cheng, M.M., Liu, J., Wang, J.: Demystifying
local vision transformer: Sparse connectivity, weight sharing, and dynamic weight.
arXiv preprint arXiv:2106.04263 (2021) -
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In:
Proceedings of the IEEE conference on computer vision and pattern recognition.
pp. 770–778 (2016) -
Hendrycks, D., Gimpel, K.: Gaussian error linear units (gelus). arXiv preprint
arXiv:1606.08415 (2016) -
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the
IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018) -
Hua, W., Dai, Z., Liu, H., Le, Q.V.: Transformer quality in linear time. arXiv
preprint arXiv:2202.10447 (2022) -
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by
reducing internal covariate shift. In: International conference on machine learning.
pp. 448–456. PMLR (2015) -
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint
arXiv:1412.6980 (2014) -
Liang, J., Cao, J., Fan, Y., Zhang, K., Ranjan, R., Li, Y., Timofte, R., Van Gool,
L.: Vrt: A video restoration transformer. arXiv preprint arXiv:2201.12288 (2022) -
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image
restoration using swin transformer. In: Proceedings of the IEEE/CVF International
Conference on Computer Vision. pp. 1833–1844 (2021) -
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin
transformer: Hierarchical vision transformer using shifted windows. In: Proceedings
of the IEEE/CVF International Conference on Computer Vision. pp. 10012–10022
(2021) -
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for
the 2020s. arXiv preprint arXiv:2201.03545 (2022) -
Loshchilov, I., Hutter, F.: Sgdr: Stochastic gradient descent with warm restarts.
arXiv preprint arXiv:1608.03983 (2016) -
Mao, X., Liu, Y., Shen, W., Li, Q., Wang, Y.: Deep residual fourier transformation
for single image deblurring. arXiv preprint arXiv:2111.11745 (2021) -
Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network
for dynamic scene deblurring. In: Proceedings of the IEEE conference on computer
vision and pattern recognition. pp. 3883–3891 (2017) -
Nah, S., Son, S., Lee, S., Timofte, R., Lee, K.M.: Ntire 2021 challenge on image
deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition. pp. 149–165 (2021) -
Nair, V., Hinton, G.E.: Rectified linear units improve restricted boltzmann machines. In: Icml (2010)
-
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing
and computer-assisted intervention. pp. 234–241. Springer (2015) -
Shazeer, N.: Glu variants improve transformer. arXiv preprint arXiv:2002.05202
(2020) -
Shi, W., Caballero, J., Husz´ar, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert,
D., Wang, Z.: Real-time single image and video super-resolution using an efficient
sub-pixel convolutional neural network. In: Proceedings of the IEEE conference on
computer vision and pattern recognition. pp. 1874–1883 (2016) -
Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., Li, Y.: Maxim:
Multi-axis mlp for image processing. arXiv preprint arXiv:2201.02973 (2022) -
Ulyanov, D., Vedaldi, A., Lempitsky, V.: Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:1607.08022 (2016)
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser,
ÙL., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017) -
Wang, Y., Huang, H., Xu, Q., Liu, J., Liu, Y., Wang, J.: Practical deep raw image
denoising on mobile devices. In: European Conference on Computer Vision. pp.
1–16. Springer (2020) -
Wang, Z., Cun, X., Bao, J., Liu, J.: Uformer: A general u-shaped transformer for
image restoration. arXiv preprint arXiv:2106.03106 (2021) -
Waqas Zamir, S., Arora, A., Khan, S., Hayat, M., Shahbaz Khan, F., Yang, M.H.,
Shao, L.: Multi-stage progressive image restoration. arXiv e-prints pp. arXiv–2102
(2021) -
Yan, J., Wan, R., Zhang, X., Zhang, W., Wei, Y., Sun, J.: Towards stabilizing
batch statistics in backward propagation of batch normalization. arXiv preprint
arXiv:2001.06838 (2020) -
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.:
Restormer: Efficient transformer for high-resolution image restoration. arXiv
preprint arXiv:2111.09881 (2021) -
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.:
Learning enriched features for real image restoration and enhancement. In: European Conference on Computer Vision. pp. 492–511. Springer (2020)