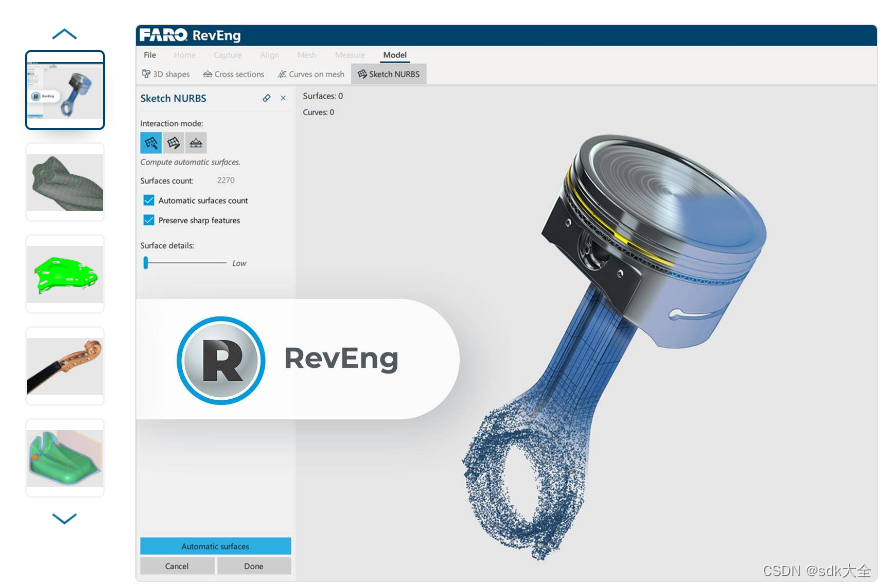
TPU-NNTC 编译部署LPRNet 车牌识别算法
注意: 由于SOPHGO SE5微服务器的CPU是基于ARM架构,以下步骤将在基于x86架构CPU的开发环境中完成
- 初始化开发环境(基于x86架构CPU的开发环境中完成)
- 模型转换 (基于x86架构CPU的开发环境中完成)
处理后的LPRNet 项目文件将被拷贝至 SE5微服务器 上进行推理测试
1. 开发环境配置
-
Linux 开发环境(x86架构CPU的开发环境)
-
一台安装了Ubuntu16.04/18.04/20.04的x86主机,运行内存建议12GB以上
-
下载SophonSDK开发包(v3.0.0)
-

1.1 配置步骤
- 解压SDK压缩包
sudo apt update
sudo apt install unzip
unzip sophonsdk_v3.0.0_<***>.zip
- docker 安装
# 安装docker
sudo apt-get install docker.io
# docker命令免root权限执行
# 创建docker用户组,若已有docker组会报错,没关系可忽略
sudo groupadd docker
# 将当前用户加入docker组
sudo gpasswd -a ${USER} docker
# 重启docker服务
sudo service docker restart
# 切换当前会话到新group或重新登录重启X会话
newgrp docker
提示:需要logout系统然后重新登录,再使用docker就不需要sudo了。
-
下载docker 镜像
- technical center (sophgo.com)

-
解压压缩包,挂载docker 镜像
unzip x86_sophonsdk3_ubuntu18.04_py37_dev_22.06_docker cd x86_sophonsdk3_ubuntu18.04_py37_dev_22.06_docker docker load -i x86_sophonsdk3_ubuntu18.04_py37_dev_22.06.docker -
创建docker容器并进入Docker
cd sophonsdk_v3.0.0_<***> ./docker_run_sophonsdk.sh注意:此时已经进入到docker 中,后续的操作都在docker 中完成
-
在docker 容器内安装依赖库和设置环境变量
cd $REL_TOP/scripts # 安装库 ./install_lib.sh nntc # 设置环境变量,注意此命令只对当前终端有效,重新进入需要重新执行 source envsetup_cmodel.sh # for CMODEL MODE # source envsetup_pcie.sh # for PCIE MODE
2. 模型准备
2.1 模型简介
LPRNet(License Plate Recognition via Deep Neural Networks),是一种轻量级卷积神经网络,可实现无需进行字符分割的端到端车牌识别。
LPRNet的优点可以总结为如下三点:
- LPRNet不需要字符预先分割,车牌识别的准确率高、算法实时性强、支持可变长字符车牌识别。对于字符差异比较大的各国不同车牌均能够端到端进行训练。
- LPRNet是第一个没有使用RNN的实时轻量级OCR算法,能够在各种设备上运行,包括嵌入式设备。
- LPRNet具有足够好的鲁棒性,在视角和摄像畸变、光照条件恶劣、视角变化等复杂的情况下,仍表现出较好的识别效果。
2.2 数据集准备
- CCPD数据集
- 该数据集是由中科大团队构建的一个用于车牌识别的大型国内停车场车牌数据集。该数据集在合肥市的停车场采集得来,采集时间早上7:30到晚上10:00。停车场采集人员手持Android POS机对停车场的车辆拍照并手工标注车牌位置。拍摄的车牌照片涉及多种复杂环境,包括模糊、倾斜、阴雨天、雪天等等。CCPD数据集一共包含将近30万张图片,每种图片大小720x1160x3。
2.3 准备移植例程
-
从github上下载移植好的例程,LPRNet的例程位于examples/simple/lprnet/。
git clone https://github.com/sophon-ai-algo/examples.git cd examples/simple/lprnet

2.4 准备模型与数据
-
进入本例程的工作目录后,可通过运行
scripts/download.sh将相关模型下载至data/models,将数据集下载并解压至data/images/。./scripts/download.sh
- data/image 目录

-
data/model 目录

下载的模型包括:
Final_LPRNet_model.pth: 原始模型
LPRNet_model.torchscript: trace后的JIT模型
lprnet_fp32_1b4b.bmodel: 编译后的FP32模型,包含batch_size=1和batch_size=4
lprnet_int8_1b4b.bmodel: 量化后的INT8模型,包含batch_size=1和batch_size=4
下载的数据包括:
test: 原始测试集
test_md5_lmdb: 用于量化的lmdb数据集
2.5 模型转换
2.5.1 准备模型
| 原始模型 | Final_LPRNet_model.pth |
|---|---|
| 概述 | 基于ctc的车牌识别模型,支持蓝牌、新能源车牌等中国车牌,可识别字符共67个。 |
| 骨干网络 | LPRNet |
| 训练集 | 未说明 |
| 运算量 | 148.75 MFlops |
| 输入数据 | [batch_size, 3, 24, 94], FP32,NCHW |
| 输出数据 | [batch_size, 68, 18], FP32 |
| 前处理 | resize,减均值,除方差,HWC->CHW |
| 后处理 | ctc_decode |
-
导出JIT模型
- SophonSDK中的PyTorch模型编译工具BMNETP只接受PyTorch的JIT模型(TorchScript模型)。本工程可以直接使用下载好的
LPRNet_model.torchscript进行编译,也可以自己在源码上通过以下方法导出JIT模型。
.... # 在CPU上加载网络模型 lprnet.load_state_dict(torch.load("{PATH_TO_PT_MODEL}/Final_LPRNet_model.pth", map_location=torch.device('cpu'))) # jit.trace model = torch.jit.trace(lprnet, torch.rand(1, 3, 24, 94)) # 保存JIT模型 torch.jit.save(model, "{PATH_TO_JIT_MODEL}/LPRNet_model.torchscript") .... - SophonSDK中的PyTorch模型编译工具BMNETP只接受PyTorch的JIT模型(TorchScript模型)。本工程可以直接使用下载好的
注意:LPRNet_model.torchscript 已下载到data/model 目录下,也可直接调用


2.5.2 模型转换
模型转换的过程需要在x86下的docker开发环境中完成。以下操作均在x86下的docker开发环境中完成。
2.5.2.1 生成FP32 BModel
-
在本工程目录下执行以下命令,使用bmnetp编译生成FP32 BModel,请注意修改
gen_fp32bmodel.sh中的JIT模型路径、生成模型目录和输入大小shapes等参数:./scripts/gen_fp32bmodel.sh上述脚本会在
data/models/fp32bmodel/下生成lprnet_fp32_1b4b.bmodel、lprnet_fp32_1b.bmodel、lprnet_fp32_4b.bmodel、文件,即转换好的FP32 BModel,使用bm_model.bin --info {path_of_bmodel}查看lprnet_fp32_1b4b.bmodel具体信息如下:

注意:lprnet_fp32_1b4b.bmodel 已下载到data/model 目录下,也可直接调用
2.5.2.1 生成iint8 BModel
-
不量化模型可跳过本节。
-
INT8 BModel的生成需要先制作lmdb量化数据集,然后经历中间格式UModel,即:原模型→FP32 UModel→INT8 UModel→INT8 BModel。在工程目录下执行以下命令,将生成INT8 BModel:
./scripts/gen_int8bmodel.sh上述脚本会在
data/models/int8bmodel/下生成lprnet_int8_1b4b.bmodel、lprnet_int8_4b.bmodel、lprnet_int8_1b.bmodel文件,即转换好的INT8 BModel,使用bm_model.bin --info {path_of_bmodel}查看lprnet_int8_1b4b.bmodel具体信息如下:

注意:lprnet_int8_1b4b.bmodel 已下载到data/model 目录下,也可直接调用
3. 部署测试
3.1 环境配置
-
SE5 微服务器 是输入 arm SoC 平台, 对于arm SoC平台,内部已经集成了相应的SDK运行库包,位于/system目录下,只需设置环境变量即可。
# 设置环境变量 export PATH=$PATH:/system/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/system/lib/:/system/usr/lib/aarch64-linux-gnu export PYTHONPATH=$PYTHONPATH:/system/lib -
如果您使用的设备是Debian系统,您可能需要安装numpy包,以在Python中使用OpenCV和SAIL:
# 对于Debian9,请指定numpy版本为1.17.2 sudo apt update sudo apt-get install python3-pip sudo pip3 install numpy==1.17.2 -i https://pypi.tuna.tsinghua.edu.cn/simple如果您使用的设备是Ubuntu20.04系统,系统内已经集成了numpy环境,不需要进行额外的安装。
3.2 python例程推理
Python代码无需编译,无论是x86 PCIe平台还是arm SoC平台配置好环境之后就可直接运行。
工程目录下的python目录提供了一系列python例程以供参考使用,具体情况如下:
| # | 例程主文件 | 说明 |
|---|---|---|
| 1 | lprnet_cv_cv_sail.py | 使用OpenCV解码、OpenCV前处理、SAIL推理 |
| 2 | lprnet_sail_bmcv_sail.py | 使用SAIL解码、BMCV前处理、SAIL推理 |
使用bm_opencv解码的注意事项: x86 PCIe平台默认使用原生opencv,arm SoC平台默认使用bm_opencv。使用bm_opencv解码可能会导致推理结果的差异。若要在x86 PCIe平台使用bm_opencv可添加环境变量如下:
export PYTHONPATH=$PYTHONPATH:$REL_TOP/lib/opencv/pcie/opencv-python/
-
lprnet_cv_cv_sail.py 推理示例
-
具体参数说明
usage:lprnet_cv_cv_sail.py [--mode MODE] [--img_path IMG_PATH] [--bmodel BMODEL] [--batch_size] [--tpu_id TPU] --mode:运行模型,可选择test或val,选择test时可将图片的推理结果打印出来,选择val时可将图片的推理结果打印出来并与标签进行对比,计算准确率,val只用于整个文件夹的推理且图片名以车牌标签命令; --img_path:推理图片路径,可输入单张图片的路径,也可输入整个图片文件夹的路径; --bmodel:用于推理的bmodel路径; --batch_size: 模型输入的batch_size,本例程可支持1或4; --tpu_id:用于推理的tpu设备id。 -
测试数据集并保存预测结果的实例如下:
# 测试单张图片 python3 python/lprnet_cv_cv_sail.py --mode test --img_path data/images/test.jpg --bmodel data/models/fp32bmodel/lprnet_fp32_1b4b.bmodel --batch_size 1 --tpu_id 0 # 测试整个文件夹 python3 python/lprnet_cv_cv_sail.py --mode test --img_path data/images/test --bmodel data/models/fp32bmodel/lprnet_fp32_1b4b.bmodel --batch_size 4 --tpu_id 0 # 测试整个文件夹,并计算准确率 python3 python/lprnet_cv_cv_sail.py --mode val --img_path data/images/test --bmodel data/models/fp32bmodel/lprnet_fp32_1b4b.bmodel --batch_size 4 --tpu_id 0 -
执行完成后,会打印预测结果、推理时间、准确率等信息。
...... INFO:root:img:豫RM6396.jpg, res:皖RM6396 INFO:root:img:皖S08407.jpg, res:皖S08407 INFO:root:img:皖SYZ927.jpg, res:皖SYZ927 INFO:root:img:皖SZ788K.jpg, res:皖SZ788K INFO:root:img:皖SZH382.jpg, res:皖SZH382 INFO:root:img:川X90621.jpg, res:川X90621 INFO:root:ACC = 0.9010 INFO:root:------------------ Inference Time Info ---------------------- INFO:root:inference_time(ms): 1.03 INFO:root:total_time(ms): 1371.67, img_num: 1000 INFO:root:average latency time(ms): 1.37, QPS: 729.037181
-



![[模拟电路]集成运算放大器](https://img-blog.csdnimg.cn/28cc38a4d71c44318fe8068c2010fc80.png)