看完题想了一下,就想到了一点,它就是先用1分别乘2,乘3,乘5然后往后加,然后用2分别乘2,乘3,乘5往后加,但是如果这样就是1,2,3,5,4,6,10...所以我想到了用优先队列,乘一个就往里面放一个,他会自动排序,但是没法通过下标或者迭代去获得元素,然后看了一下题解,题解的动态规划的方法挺简单的
class Solution {
public int nthUglyNumber(int n) {
int[] dp = new int[n+1];
dp[1] = 1;
int p2 = 1,p3 = 1, p5 = 1;
for(int i = 2; i<n+1;i++){
dp[i] = Math.min(Math.min(dp[p2]*2, dp[p3]*3), dp[p5]*5);
if(dp[i] == dp[p2]*2){
p2++;
}
if(dp[i] == dp[p3]*3){
p3++;
}
if(dp[i] == dp[p5]*5){
p5++;
}
}
return dp[n];
}
}它用3个指针p2,p3,p5表示下一个要乘2,乘3,乘5的数,他们指向的不是同一个数,一开始都指向1,dp[i]表示第i个丑数,先赋初值dp[1]等于1,然后dp[2]就等于(dp[p2]*2, dp[p3]*3,dp[p5]*5)中最小的一个,然后选中的那个指针就要往下移一位,比如dp[2]=dp[p2]*2,p2就要++,需要注意的是,在if语句中不能用ifelse,因为他们有可能同时成立,加入p2指向3,p3指向2,那他们乘完之后都等于6,那p2,p3都要往下移一位,否则下次p3乘2得6又放进数组了后面就全乱了,最后返回dp[n]即可,还是比较好理解,题解还有一种用优先队列的方法:
class Solution {
public int nthUglyNumber(int n) {
int[] factors = {2, 3, 5};
Set<Long> seen = new HashSet<Long>();
PriorityQueue<Long> heap = new PriorityQueue<Long>();
seen.add(1L);
heap.offer(1L);
int ugly = 0;
for (int i = 0; i < n; i++) {
long curr = heap.poll();
ugly = (int) curr;
for (int factor : factors) {
long next = curr * factor;
if (seen.add(next)) {
heap.offer(next);
}
}
}
return ugly;
}
}
它用了一种非常巧妙的方法,它是按从小到大排列的,每次取出队头这个最小的元素,那么第n次取出就第n个丑数,所以它每次取出队头,还要把队头乘2,乘3,乘5加进队列里面。但是这样也有一个问题,就是会有重复的元素,比如2*3=6,3*2=6,所以它用了一个HashSet去重,队列每次要添加元素的时候都先往HashSet里面放进去,我以为它会调用contains方法判断HashSet里面有没有这个值,但是它却只用了一个add方法,这就让我对HashSet的add方法有点好奇了,然后看了一下Hash的add方法的源码。
HashSet<String> set = new HashSet<>();HashSet的构造方法里面其实是创建了一个HashMap
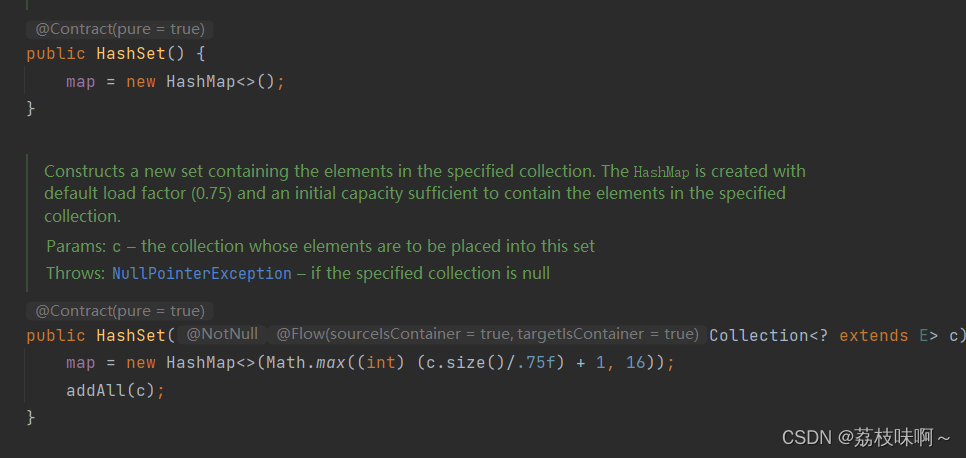
然后HashSet的add方法实际上是调用了这个HashMap的put方法,它的返回值是boolean,如果这个put方法的返回值是null就是true,表示添加成功,add的参数是put进去的key,value是一个全局变量PRESENT,这时map是一个全局变量指向创建HashSet对象时创建的HashMap对象。

然后再看看这个map的put方法,put又调用了putVal方法
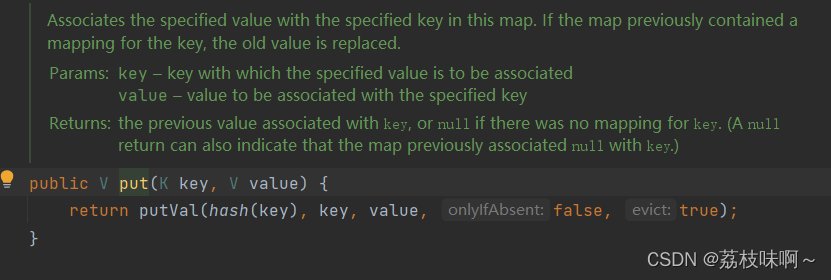
然后再看putVal方法
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}这里看不懂了,搜了篇博客看了:博客链接,以下是博客中的解释:
public class Test {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("Tom");
set.add("Tom");
}
}
他自己写了一个demo来测试分析,两次添加“Tom”。
- 第一次添加元素的过程:set.add(“Tom”);
首先定义Node<K,V>[] tab;意思是创建一个名为tab的Node节点集合,然后if ((tab = table) == null || (n = tab.length) == 0)对比tab和table是否为空,因为table是全局变量所以程序运行开始之前初始值null,判断为true,所以不用判断(n = tab.length) == 0,直接执行 n = (tab = resize()).length;,resize方法打开底层并没有看懂,但是知道是返回值是newTab,其实此时tab已经是被替换了成为长度为16的数组,n等于tab的长度最大值是16,接下来判断p = tab[i = (n - 1) & hash]) == null 其中因为i的范围是0~15,所以n-1来控制防止数组溢出,至于&hash是程序自动编译计算得来的tab的地址(在第三种情况我会详细描述)。这样就执行tab[i] =newNode(hash, key, value, null);不执行else,直接执行图中代码(源代码的最后一段)返回值是null,所以put方法完成返回值null,然后boolean判断是turn,.add方法完成。
- 情况二:添加了相同元素时,set.add(“Tom”);如何执行?
下面讨论第二种情况:如果添加了相同元素时,add方法是如何进行判断的:?
此时已经在set集合中添加了一个tom元素,要再添加一个tom,这是putVal是这么运行的,首先执行 if ((tab = table) == null || (n = tab.length) == 0)此时的table已经被第一次添加元素时赋值所以不是null,tab.length明显也不为0,所以接下来执行if ((p = tab[i = (n - 1) & hash]) == null)由于此时的添加的元素的tab和第一次添加的tab,元素是一样的所以tab也是一样的,其找寻的地址也是一样的,所以第二次找到的地址不是null,那么加下来就要执行else if了,进行判读下面语句
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
p指向第一次的tab[],由于添加的元素相同所以hash、key都相同,所以判断成功,进行下一步e=p;e指向p,p指向tab[i],
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
判断e不等于null,执行V oldValue = e.value;,接下来判断if (!onlyIfAbsent || oldValue == null),onlyIfAbsent 是false,所以!onlyIfAbsent是true,所以返回值是 oldValue,这是put接受到的返回值不是null所以就添加失败。