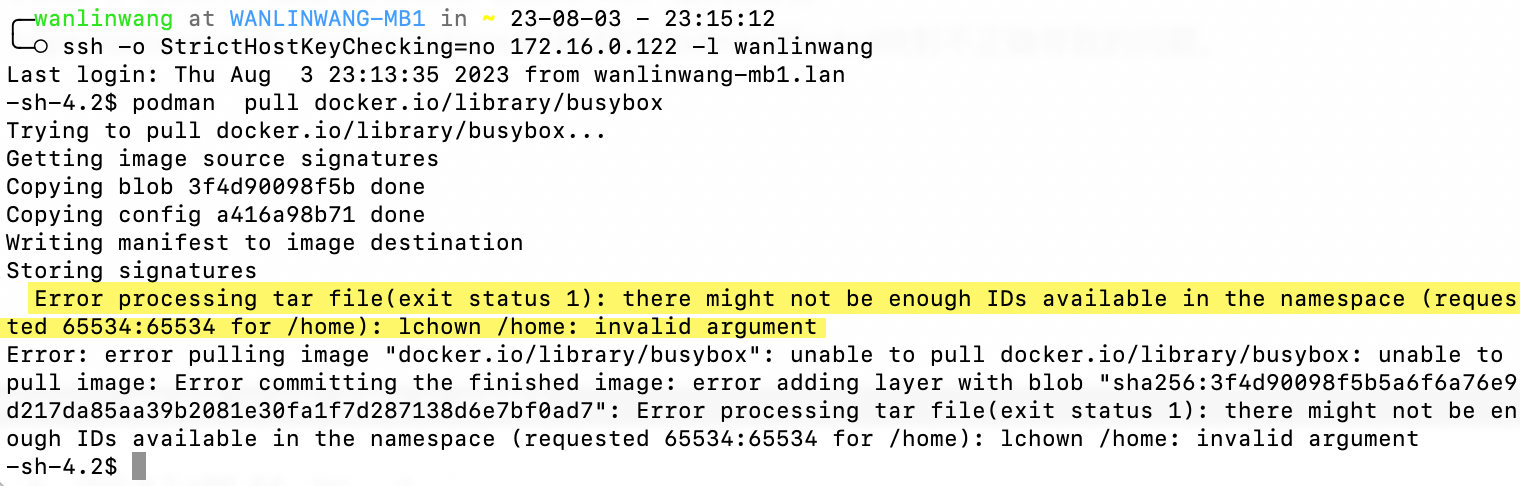
对于语音增强来说,噪声一般可以分为稳态噪声(如白噪声)和瞬态噪声(有的地方也叫非稳态噪声,如键盘声)。如果对语音降噪有一定了解的读者会知道,一般的信号处理方法对稳态噪声比较有效,可以参考WebRTC ANR 流程解析,然而对于瞬态噪声,由于噪声变换较快,噪声估计算法没办法准确跟踪到噪声的变化,因此一般采用基于深度学习的方法对瞬态噪声进行抑制,可以参考DNN单通道语音增强。但是,有没有可能使用信号处理来抑制瞬态噪声呢?答案还真有,废话不多说,先看下效果给你们一点来自信号处理的小小震撼。
瞬态噪声的抑制流程图如下所示,与传统的流程相比,除了噪声谱估计之外还多了一个瞬态谱估计模块。
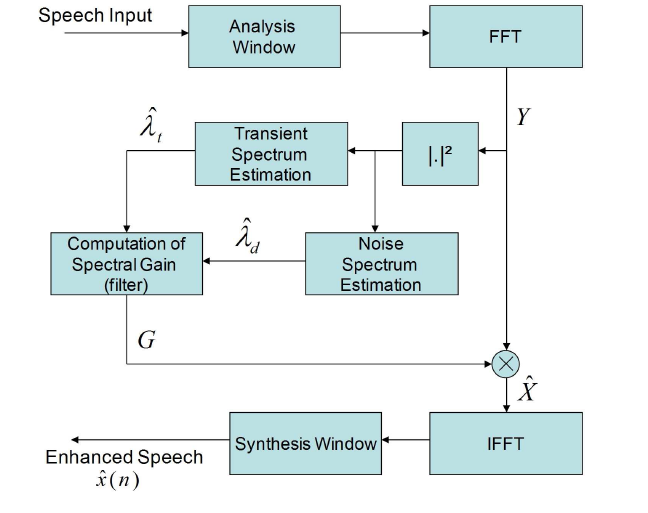
I. 瞬态噪声估计
我们首先假定瞬态噪声与语音和其他噪声相比变化更为快速,然后调整噪声估计算法使得非瞬态的部分(语音和稳态噪声)呈现一种“伪稳态”的特性。即将音频分为瞬态分量和非瞬态分量。然后,基于非瞬态分量的PSD通过OMLSA计算瞬态分量幅度谱的增益,以获得瞬态分量并抑制包含语音和背景噪声的非瞬态分量。
由于是瞬态噪声估计,与一般的噪声估计算法相比,我们使用更短的帧长,因此选取帧长为64个采样点,即在16kHz的采样率下,帧长为4ms。我们首先对非瞬态分量进行估计,采用基于MCRA的算法。噪声PSD估计通过对频谱幅度的时间递归平均得到,即
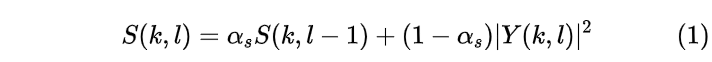
其中alpha_s决定了噪声跟踪的速率,较小的alpha_s给当前帧较大的权重,因此噪声更新会更快,一般选取0.7~0.99。瞬态噪声存在概率由平滑周期的最小值控制,该最小值是从长度为L的有限因果窗口获得的
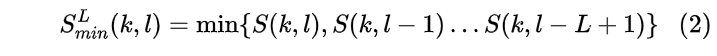
然后,瞬态噪声存在概率通过下式判决
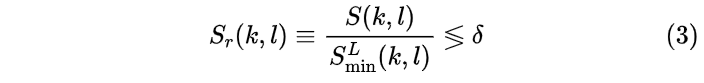
其中delta是个经验值,当结果大于delta时,我们认为当前帧状态是瞬态噪声,记为
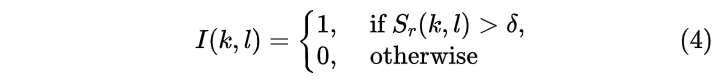
那么瞬态噪声的存在概率可以表示为
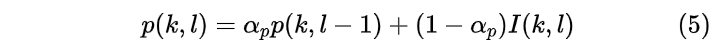
此时,非瞬态分量的功率谱为
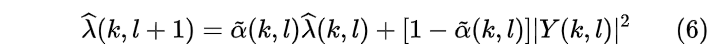
其中
![]()
上述公式可以跟踪非稳态的分量,然而以突然爆发为特征的语音音素起始点不能通过频谱递归平滑来跟踪,这会导致语音音素的起始被错误认为是瞬态噪声。因此我们将“未来”信息加入计算,这样可以区分瞬态和语音的开始。 对于瞬态噪声来说,在短暂的瞬变之后,信号的功率预计会快速衰减,而在语音音素开始后,功率水平预计在音素的持续时间内保持稳定。我们通过如下的方式进行判别
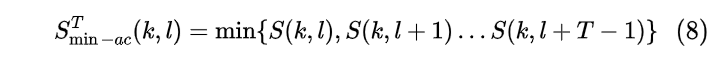
值得注意的是,这是一个非因果的窗,窗长要小于噪声估计的窗长,一般40ms足以覆盖大多数瞬态噪声。此时,非瞬态分量可以表示为
![]()
最后,我们使用基于OMLSA的算法获得瞬态分量,瞬态PSD的估计值如下
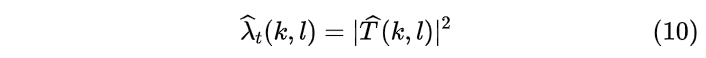
其中T是OMLSA算法计算出来的幅度估计值。
II. 语音增强
在有了以上的信息之后,我们就可以计算对应的增益了。首先总的噪声PSD,为两部分之和即通过MCRA获得的稳态噪声和通过公式(10)获得的瞬态噪声,如下所示
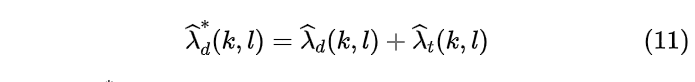
谱增益可以通过如下方式计算
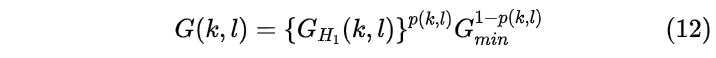
其中Gmin是当语音不存在时的固定常数增益,而GH1为
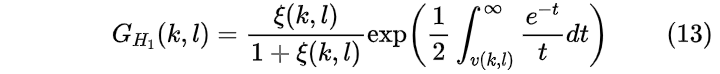
其中
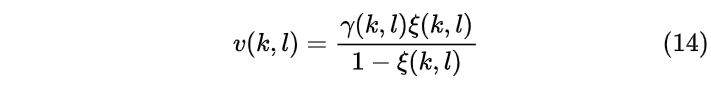
III. 总结
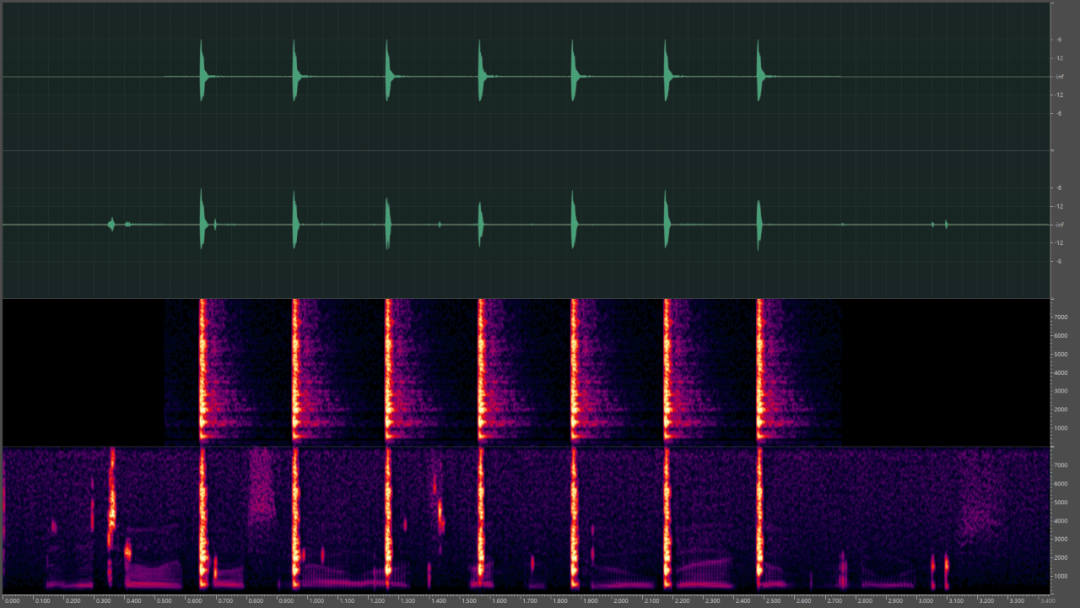
总的来说瞬态噪声的估计,用了一个很trick的方法,将语音和稳态噪声视为“噪声”,然后通过OMLSA去计算增益获得剩余的频率分量,间接的估计出了瞬态噪声的PSD。当有了噪声PSD之后,求对应的增益就轻车熟路了。我们最后看下估计的瞬态噪声,上图是原始的瞬态噪声,下图是估计的瞬态噪声,可以看出估计的还是比较准确的,当然从共振峰也可以看出一些音素被视为了瞬态噪声。
参考文献:
[1]. https://zhuanlan.zhihu.com/p/591219373?utm_id=0
[2]. https://israelcohen.com/wp-content/uploads/2018/05/IWAENC2012_Hirszhorn.pdf