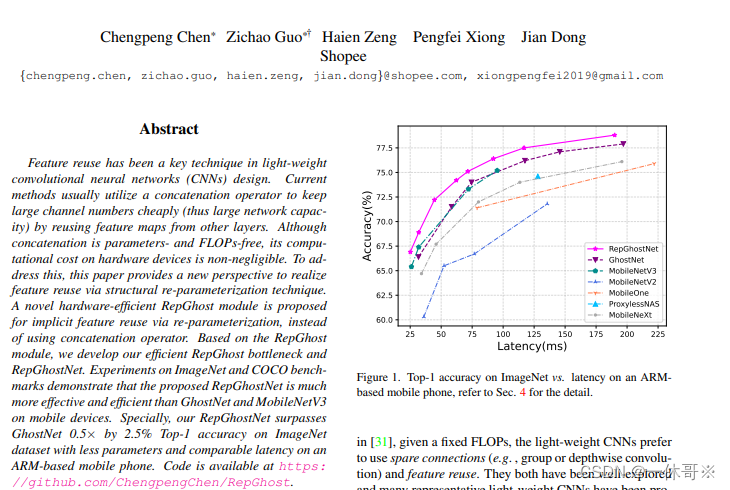
关于Transformer
- Transformer 存在局限。首要的一点,它们有着对于序列长度的二次时间复杂度,这会限制它们的可扩展性并拖累训练和推理阶段的计算资源和时间效率。
- 基于 Transformer的模型在提高窗口大小以优化性能的同时,也带来了相应的计算负担。
- 视觉Transformer(ViT)作为卷积神经网络(CNNs)的一种可行替代方案的出现,源于多头自注意力机制的成功应用。与标准卷积相比,多头自注意力机制提供了全局感受野。虽然ViT在各种视觉识别任务中展示了潜力,但自注意力的计算复杂性在将这些方法应用到资源受限的应用中带来了挑战。
- 现有transformer模型的速度通常受到内存低效操作的限制,特别是MHSA中的张量整形和逐元函数。研究者发现注意力图在头部之间具有高度相似性,导致计算冗余。
Scaling TransNormer to 175 Billion Parametes
线性注意力的Transformer大模型
2023
TransNormerLLM 是首个基于线性注意力的 LLM。
其中值得格外注意的一项改进是将 TransNormer 的 DiagAttention 替换成线性注意力,从而可提升全局的互动性能。研究者还引入了带指数衰减的 LRPE 来解决 dilution 问题。此外,研究者还**引入了 Lightning Attention(闪电注意力)**这种全新技术,并表示其可以将线性注意力在训练时的速度提升两倍,并且其还能通过感知 IO 将内存用量减少 4 倍。不仅如此,他们还简化了 GLU 和归一化方法,而后者将整体的速度提升了 20%。他们还提出了一种稳健的推理算法,可以在不同的序列长度下保证数值稳定和恒定的推理速度,由此能提升模型在训练和推理阶段的效率。
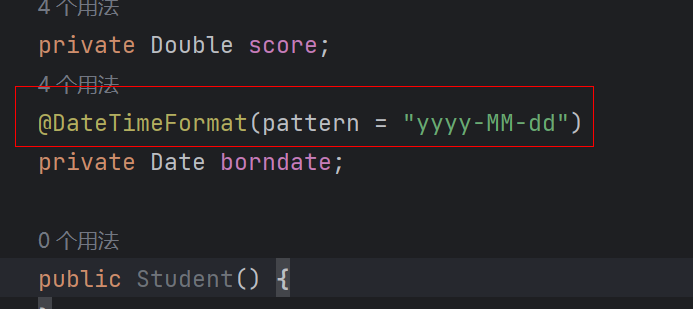
- 改进一:位置编码
TransNormer 中的较低层使用了 DiagAttention 来避免 dilution 问题。但是,这会导致 token 之间缺乏全局互动能力。为了解决这个问题,研究者为 TransNormerLLM 使用了带指数衰减的 LRPE(线性化相对位置编码),从而可在较低层保留完整的注意力。研究者把这种方法称为 LRPE-d。 - 改进二:门控机制
门控可以增强模型的性能并使训练过程平滑。研究者为 TransNormerLLM 使用了来自论文《Transformer quality in linear time》的 Flash 方法并在 token 混合中使用了门控式线性注意力(GLA)的结构。
为了进一步提升模型速度,他们还提出了 Simple GLU(SGLU),其去除了原始 GLU 结构的激活函数,因为门本身就能引入非线性。 - 改进三:张量归一化
研究者使用了 TransNormer 中引入的 NormAttention。在 TransNormerLLM 中,他们使用一种新的简单归一化函数 SimpleRMSNorm(简写为 SRMSNorm)替换了 RMSNorm。
整体结构

在该结构中,输入 X 的更新通过两个连续步骤完成:首先,其通过使用了 SRMSNorm 归一化的门控式线性注意力(GLA)模块。然后,再次通过使用了 SRMSNorm 归一化的简单门控式线性单元(SGLU)模块。这种整体架构有助于提升模型的性能表现。下方给出了这个整体流程的伪代码:
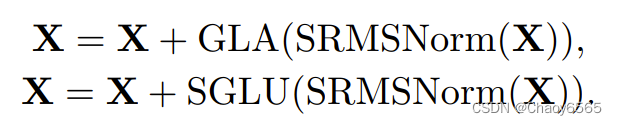
闪电注意力
为了加快注意力计算速度,研究者引入了闪电注意力(Lightning Attention)算法,这能让新提出的线性注意力更适合 IO(输入和输出)处理。
SRFormer: Permuted Self-Attention for Single Image Super-Resolution
ICCV 2023
提出了一种新的置换自注意力(PSA)用于图像超分辨率任务,可以在保持计算成本较低的同时,处理大窗口自注意力,并基于PSA构建了一个新的超分辨率网络,SRFormer,在各项基准测试中取得了最先进的性能。
SR 是计算机视觉中的一个重要任务,目的是从低分辨率的图像恢复出高质量的版本。早期,以 CNNs 为主的方法主导了 SR 领域,通过利用残差学习,密集连接或者通道注意力来构建网络结构。然而,近期的研究显示,基于Transformer的模型在 SR 任务上展现出了更好的表现,其中一个典型的例子就是SwinIR,它采用了Swin Transformer的技术,在多个基准测试中大大提升了SR模型的表现。
置换自注意力:PSA 的设计目标是在大窗口(例如24x24)内建立有效的两两关系,而不增加额外的计算负担。为此,作者在键和值矩阵上减少了通道的维度(压缩),并采用了一种置换操作,将部分空间信息传递到通道维度(置换)。这种方法即使在通道减少的情况下,也不会损失空间信息,并且每个注意力头可以保持适当数量的通道以产生表达力强的注意力图。
SRFormer 的架构

- 像素嵌入层:将低分辨率的RGB图像转换为特征嵌入,这些嵌入会被送入特征编码器进行处理。
- 特征编码器:包含了 N 个排列自注意力组,每个组由 M 个 PAB 和一个 3×3 卷积层构成。
- 高分辨率图像重建层:最后,特征编码器的输出和特征嵌入的残差,会被送入高分辨率图像重建层,从而得到高分辨率图像。
此处,排列自注意块(PAB)是整个模型的核心,它包含了置换注意力层(PSA)和卷积前馈网络(ConvFFN)。这里我们可以简单看下 PSA 和常规的 MHSA 的区别:

PSA 层的主要思想是,它将输入特征图划分成 N 个非重叠的方块窗口,然后通过三个线性层得到 Q,K,V 三组值。这里的 保持与输入 同样的通道维度,而 和 的通道维度被压缩。随后,作者提出了一种将空间信息排列到通道维度的方法,使得每个注意力头能生成更具表现力的注意力图。最后,利用 ,, 来进行自注意力操作。
ConvFFN 则是一个辅助部分,它在自注意之后添加一个 3x3 卷积层以恢复高频信息。 作者发现,这样的操作几乎不增加计算量,但能够补偿自注意操作过程中造成的高频信息的损失。
Lightweight Vision Transformer with Bidirectional Interaction
Light-Weight Vision Transformer with Parallel Local and Global Self-Attention
PLG-ViT 同时具有并行局部和全局自注意力的轻量化视觉Transformer
本文提出了一种轻量级的PLG-ViT(Light-Weight PLG-ViT),它是一种计算效率高但功能强大的特征提取器。
创新包括在Transformer阶段之间进行高效降采样操作以及Transformer层内部的新型、更强大的前向网络。
模型设计



在图上中,展示了原始PLG-ViT的CCF-FFN。在原始FFN的开头,特征按照默认值
α进行了深度增加,其中α默认为4。然后是一个深度可分离的3×3层和一个全连接层(FC),恢复了原始的深度。
本文的CCF-FFN+保留了原始FFN的一般结构,并将来自初始逐点卷积的特征馈送到后续的深度可分离卷积中。然而,这些特征还与从深度可分离的3×3卷积中得到的特征进行了拼接。这种融合可以在减小α值(从4减小到3)的同时实现更丰富的特征,从而减少参数数量。
此外,本文在深度可分离卷积之后利用ConvNeXt-v2的全局响应归一化(GRN)来提高模型的特征表示能力,减少训练的计算成本。
本文的最后一次重新设计针对的是PLG-SA层全局分支中的 Patch 采样。原始的采样通过添加自适应最大池化和平均池化来获得一个全局窗口,为后续的全局自注意力提供了固定数量的 Token。
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention
CVPR 2023
研究者探讨了如何更快地使用Vision transformers,试图找到设计高效transformer架构的原则。基于主流的Vision transformers DeiT和Swin,系统地分析了影响模型推理速度的三个主要因素,包括内存访问、计算冗余和参数使用。特别是,发现transformer模型的速度通常是内存限制的。
基于这些分析和发现,研究者提出了一个新的存储器高效transformer模型家族,命名为EfficientViT。具体来说,设计了一个带有三明治布局的新块来构建模型。三明治布局块在FFN层之间应用单个存储器绑定的MHSA层。它减少了MHSA中内存绑定操作造成的时间成本,并应用了更多的FFN层来允许不同信道之间的通信,这更具内存效率。然后,提出了一种新的级联群注意力(CGA)模块 来提高计算效率。其核心思想是增强输入注意力头部的特征的多样性。与之前对所有头部使用相同特征的自我注意不同,CGA为每个头部提供不同的输入分割,并将输出特征级联到头部之间。该模块不仅减少了多头关注中的计算冗余,而且通过增加网络深度来提高模型容量。

End
以上仅作个人学习记录使用