多模态融合的主要目标是缩小模态间的异质性差异,同时保持各模态特定语义的完整性,并在深度学习模型中取得较优的性能。
一、多模态融合架构
多模态融合架构分为:联合架构,协同架构和编解码器架构。联合架构是将单模态表示投影到一个共享语义子空间中,以便能够融合多模态特征;协同架构包括跨模态相似模型和典型相关分析,其目标是寻找协调子空间中模态间的关联关系;编解码器架构是将一个模态映射到另一个模态的多模态转换任务中。
3种融合架构在视频分类、情感分析、语音识别等领域得到广泛应用,且涉及图像、视频、语音、文本等融合内容。
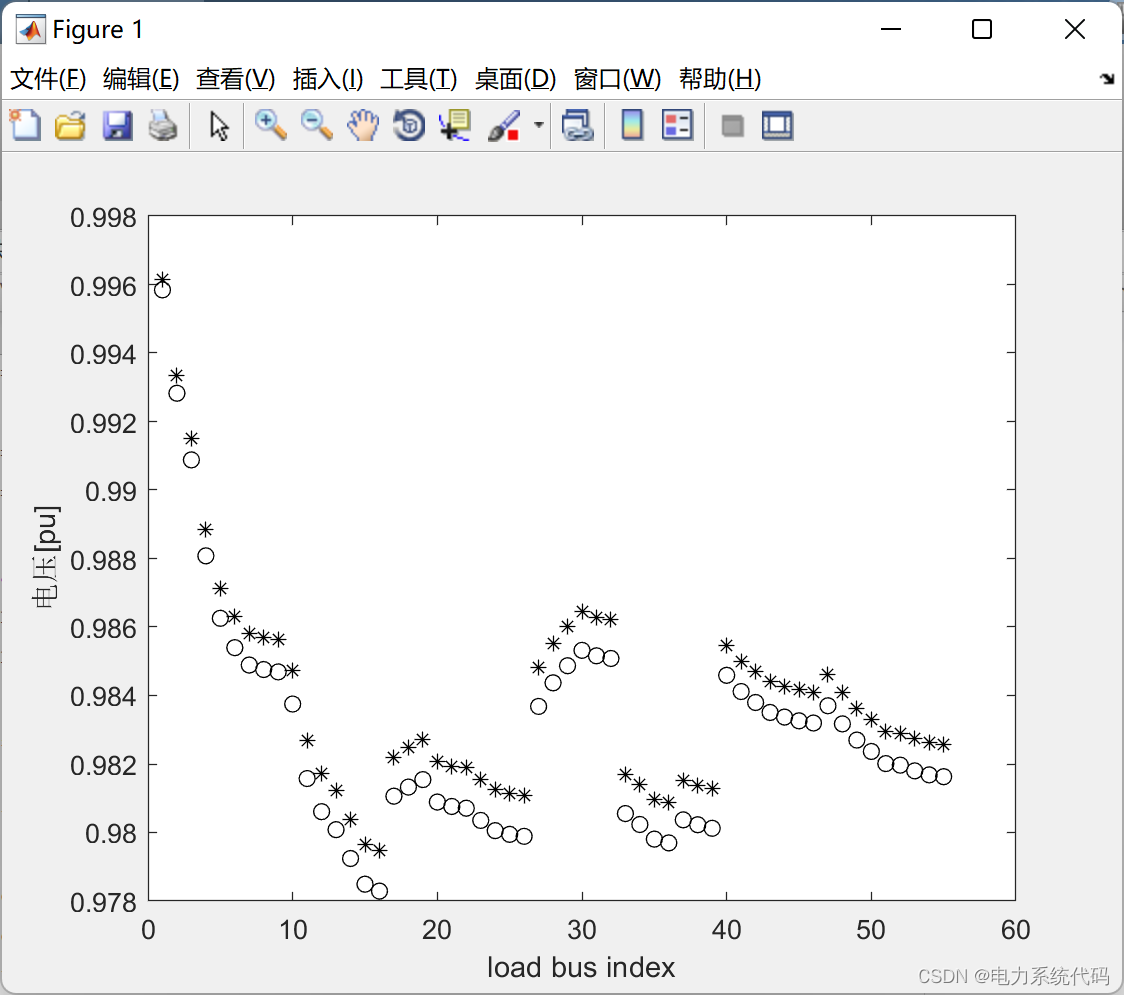
| 架构 | 应用领域 | 融合内容 | |
| 联合架构 | 视频分类 | 语音、视频、文本 | |
| 事件检测 | 语音、视频、文本 | ||
| 情绪分析 | 语音、视频、文本 | ||
| 视觉问答 | 图像、文本 | ||
| 情感分析 | 语音、视频、文本 | ||
| 语音识别 | 语音、视频 | ||
| 协同架构 | 跨模态搜索 | 图像、文本 | |
| 图像标注 | 图像、文本 | ||
| 跨模态嵌入 | 图像、视频、文本 | ||
| 转移学习 | 图像、文本 | ||
| 编解码器架构 | 图像标注 | 图像、文本 | |
| 视频解码 | 视频、文本 | ||
| 图像合成 | 图像、文本 |
1.1 联合架构
联合架构是将多模态空间映射到共享语义子空间中,从而融合多个模态特征,如下图所示。每个单一模态通过单独编码后,将被映射到共享子空间中,遵循该策略,其在视频分类、事件检测、情感分析、视觉问答和语音识别等多模态分类或回归任务中都表现出较优的性能。
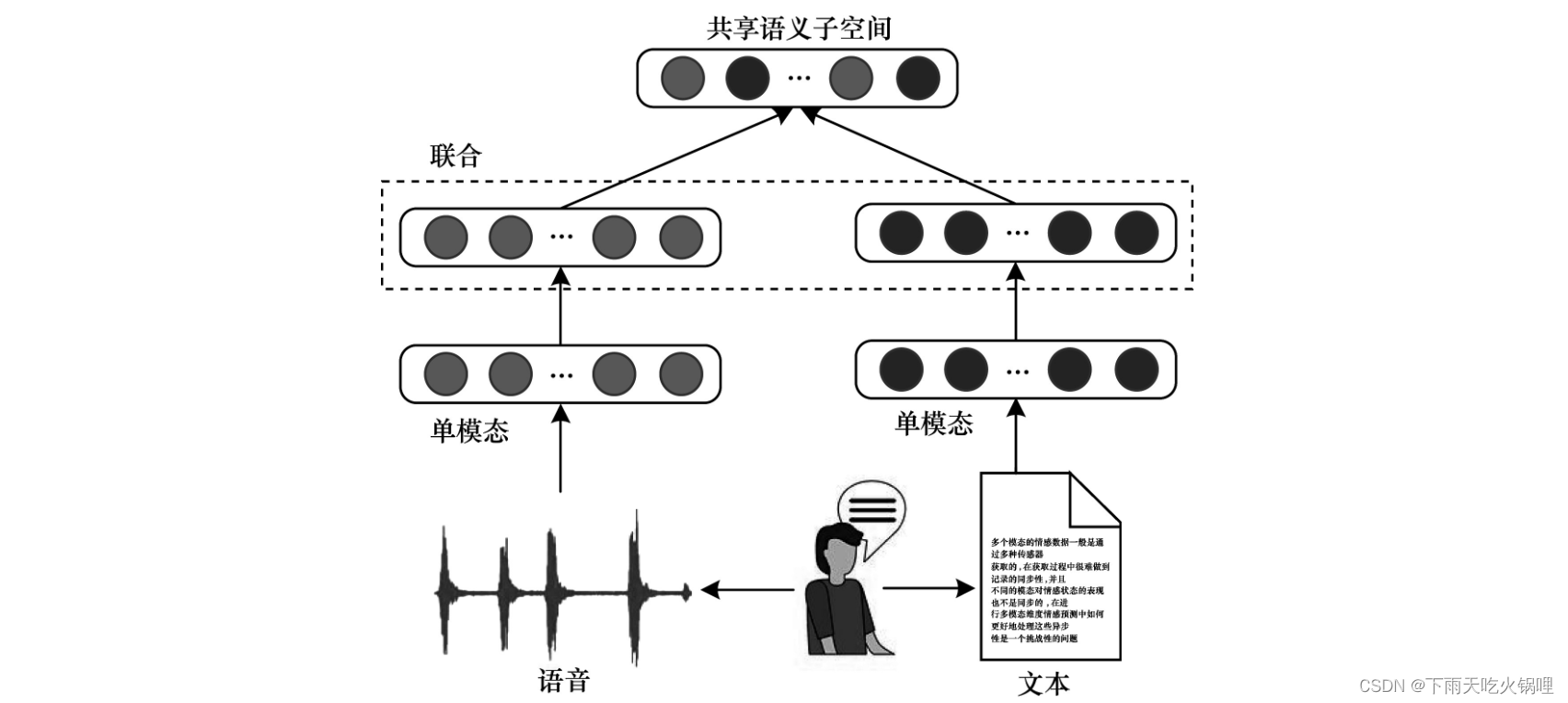
多模态联合架构的关键是实现特征“联合”,一种较简单的方法是直接连接,即“加”联合方法,该方法在不同的隐藏层实现共享语义子空间,将转换后的各个单模态特征向量语义组合在一起,从而实现多模态融合。另一种常用方法是“乘”联合方法。
多模态联合架构的优点是融合方式简单,且共享子空间通常具备语义不变性,有助于在机器学习模型中将知识从一种模态转换到另一种模态。缺点是各单模态语义完整性不易在早期发现和处理。
1.2 协同架构
多模态协同架构是将各种单模态在一些约束的作用下实现相互协同。由于不同模态包含的信息不同,因此协同架构有利于保持各单模态独有的特征和排它性。
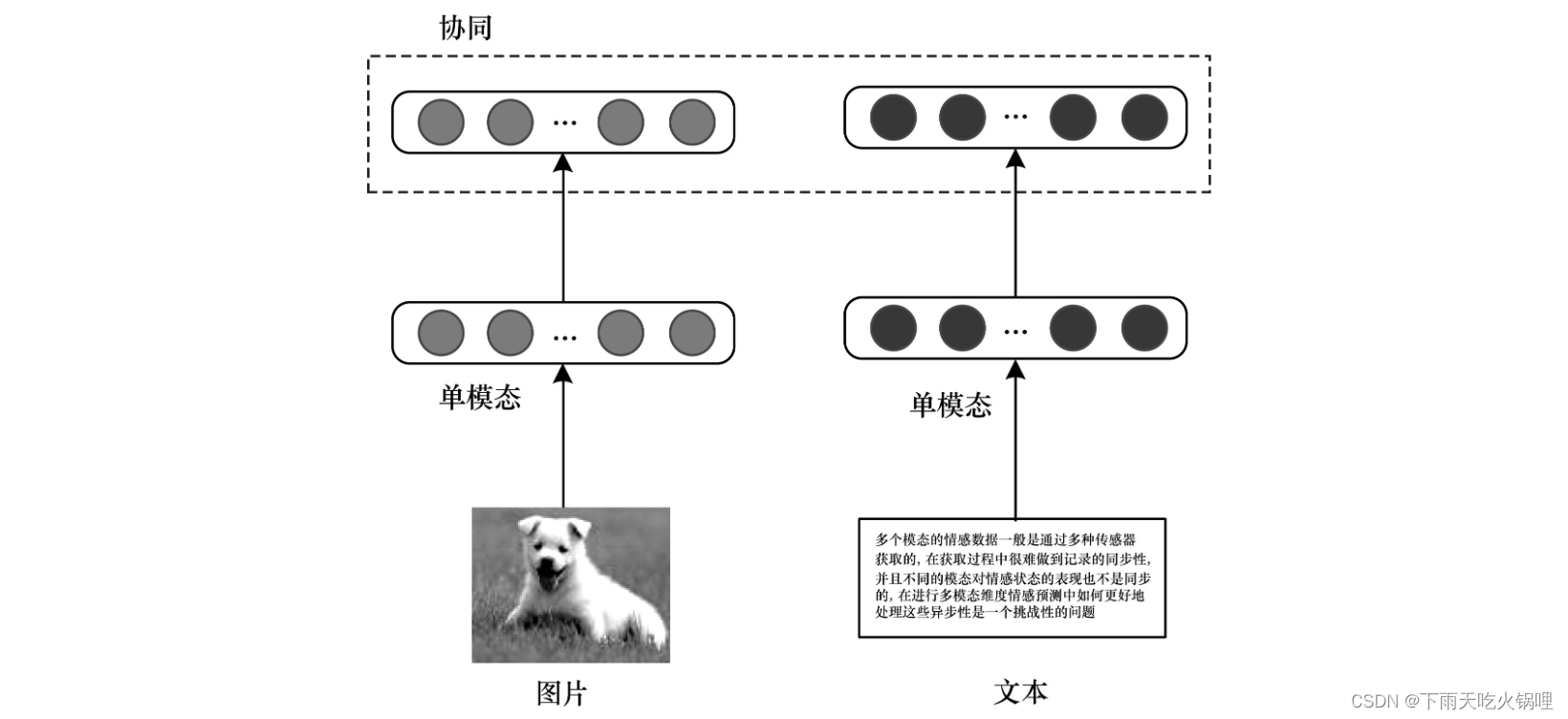
协同架构在跨模态学习中已经得到广泛应用,主流的协同方法是基于交叉模态相似性方法,该方法旨在通过直接测量向量与不同模态的距离来学习公共子空间。基于交叉模态相关性的方法旨在学习一个共享子空间,从而使不同模态表示集的相关性最大化。
协同架构的优点是每个单模态都可以独立运行,这一特性有利于跨模式迁移学习,其目的是在不同模态或领域之间传递知识。其缺点是模态融合难度较大,使跨模态学习模型不容易实现,同时模型很难在两种以上的模态之间实现迁移学习。
1.3 编解码器架构
编解码器架构通常用于将一种模态映射到另一种模态的多模态转换任务中,主要由编码器和解码器两部分组成。编码器将源模态映射到向量v中,解码器基于向量v生成一个新的目标模态样本。该架构在图像标注、图像合成、视频解码等领域有广泛应用。
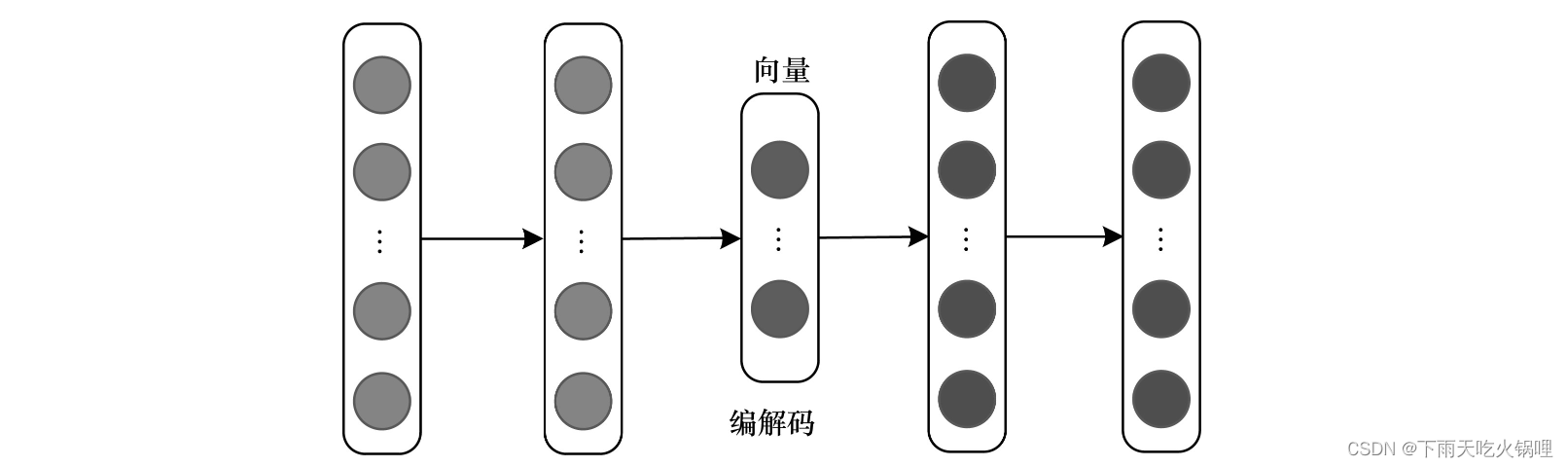
目前,编解码器架构重点关注共享语义捕获和多模序列的编解码问题。为有效捕获源模态和目标模态两种模态的共享语义,主流的解决方案是通过一些正则化术语保持模态之间的语义一致性,需确保编码器能正确检测和编码信息,而解码器能推理高级语义和生成语法,以保证源模态中语义的正确理解和目标模态中新样本的生成。为解决多模序列的编码和解码问题,需训练一个灵活的特征选择模块,而训练序列的编码或解码可以看作顺序决策问题,因此通常需采用决策能力强的模型和方法处理该问题,例如深度强化学习(Deep Reinforcement Learning,DRL),其是一种常用的多模序列编解码工具。 尽管多数编解码器架构只包含编码器和解码器,但也有一些架构是由多个编码器或解码器组成。
编解码器架构的优点是能够在源模态基础上生成新的目标模态样本。其缺点是每个编码器和解码器只能编码其中一种模态,并且决策模块设计复杂。
二、多模态融合方法
| 融合方法 | 融合类型 | 输出 | 时序模型 | 典型应用 | |
模型无关的方法 | 早期融合 | 分类 | 否 | 情感识别 | |
| 晚期融合 | 回归 | 是 | 情感识别 | ||
| 混合融合 | 分类 | 否 | 事件检测 | ||
基于模型的方法 | 多核学习 | 分类 | 否 | 对象分类 | |
| 分类 | 否 | 情感识别 | |||
| 图像模型 | 分类 | 是 | 双模语音 | ||
| 回归 | 是 | 情感识别 | |||
| 分类 | 否 | 媒体分类 | |||
| 神经网络 | 分类 | 是 | 情感识别 | ||
| 分类 | 否 | 双模语音 | |||
| 回归 | 是 | 情感识别 |
将多模态融合方法分为模型无关的方法和基于模型的方法,前者不直接依赖于特定的深度学习方法,后者利用深度学习模型显式地解决多模态融合问题,例如多核学习(Multiple Kernel Learning,MKL)方法、图像模型(Graphical Model,GM)方法和神经网络(Neural Network,NN)方法等。
神经网络是目前应用最广泛的方法之一,已用于各种多模态融合任务中。视觉和听觉双模语音识别(Audio-Visual Speech Recognition,AVSR)是最早使用神经网络方法进行多模态融合的技术,目前神经网络方法已在很多领域得到了应用,例如视觉和媒体问答、手势识别和视频描述生成等,这些应用充分利用了神经网络方法较强的学习能力和分类性能。
神经网络方法通过使用循环神经网络(Recurrent Neural Network,RNN)和长短期记忆网络(Long Short-Term Memory,LSTM)来融合时间多模态信息,例如文献使用LSTM模型进行连续多模态情感识别,相对于MKL和GM方法表现出更优的性能。此外,神经网络多模态融合方法在图像字幕处理任务中表现良好,主要模型包括神经图像字幕模型、多视图模型等。神经网络方法在多模态融合中的优势是具备大数据学习能力,其分层方式有利于不同模态的嵌入,具有较好的可扩展性,但缺点是随着模态的增多,模型可解释性变差。
三、多模态对齐方法
多模态对齐是多模态融合的关键技术之一,指从两个或多个模态中查找实例子组件之间的对应关系。例如,给定一个图像和一个标题,需找到图像区域与标题单词或短语的对应关系。多模态对齐方法分为显式对齐和隐式对齐。显式对齐关注模态之间子组件的对齐问题,而隐式对齐则是在深度学习模型训练期间对数据进行潜在对齐。
| 对齐方法 | 对齐类型 | 模态类型 | |
| 显示对齐 | 无监督方法 | 视频+文本 | |
| 视频+语音 | |||
| 监督方法 | 视频+文本 | ||
| 图像+文本 | |||
隐式对齐 | 图像模型方法 | 语音/文本+文本 | |
| 神经网络方法 | 图像+文本 | ||
| 视频+文本 |
3.1 显式对齐方法
无监督方法在不同模态的实例之间没有用于直接对齐的监督标签。尽管无监督对齐方法无需标注数据,可以节省数据标注成本,但对实例的规范性要求较高,需具备时间一致性且时间上没有较大的跳跃和单调性,否则对齐性能会急剧下降。
监督方法是从无监督的序列对齐技术中得到启发,并通过增强模型的监督信息来获得更好的性能,通常可以将上述无监督方法进行适当优化后直接用于模态对齐。该方法旨在不降低性能的前提下,尽量减少监督信息,即弱监督对齐。
3.2 隐式对齐方法
图像模型方法最早用于对齐多种语言之间的语言机器翻译及语音音素的转录,即将音素映射到声学特征生成语音模型,并在模型训练期间对语音和音素数据进行潜在对齐。构建图像模型需要大量训练数据或手工运行,因此随着深度学习研究的深入及训练数据的有限,该方法已不适用。
神经网络方法是目前解决机器翻译问题的主流方法,无论是使用编解码器模型还是通过跨模态检索都表现出较好的性能。利用神经网络模型进行模态隐式对齐,主要是在模型训练期间引入对齐机制,通常会考虑注意力机制。
Reference:面向深度学习的多模态融合技术研究综述

![[附源码]Python计算机毕业设计大学生心理健康咨询系统Django(程序+LW)](https://img-blog.csdnimg.cn/b41f7b4d4e074188928f7371e709717d.png)





![[附源码]Node.js计算机毕业设计大学生健康系统Express](https://img-blog.csdnimg.cn/853811809f5849c287f8532983d0f29c.png)