文章目录
- 一、MySQL概述
- 1.1 MySQL与redis的区别
- 1.2 数据处理分类
- 1.3 SQL
- 1.4 数据类型
- 二、数据库设计三范式
- 2.1 范式一
- 2.2 范式二
- 2.3 范式三
- 2.4 反范式
- 三、MySQL体系结构
- 3.1 结构组成
- 3.2 连接池
- 四、sql语句执行过程
- 4.1 select语句
- 4.2 CRUD执行过程
一、MySQL概述
1.1 MySQL与redis的区别
所谓的数据库,是指按照数据结构来组织、存储和管理数据的仓库;是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
之前我们了解了redis,本节开始介绍Mysql。MySQL和Redis是两种不同类型的数据库,它们有以下几个主要区别:
1)数据库类型:MySQL是一种关系型数据库(RDBMS),而Redis是一种非关系型数据库(NoSQL)。关系型数据库使用表格来存储数据,而非关系型数据库使用键值对、文档、列族等方式来组织数据。
2)数据模型:MySQL支持复杂的表结构,可以建立表与表之间的关系,进行复杂的查询操作。而Redis采用简单的键值对模型,数据以键值对的形式存储,并且支持多种数据结构,如字符串、列表、集合、哈希和有序集合等。
3)数据持久化:在默认配置下,MySQL将数据持久化到硬盘上,保证数据的长期存储。而Redis可以选择将数据持久化到磁盘上,或者只保存在内存中,根据不同的需求进行配置。
4)数据访问速度:由于Redis将数据存储在内存中,所以具有非常高的读写性能,适合处理大量的实时请求。而MySQL则需要将数据从磁盘读取到内存中进行操作,相对来说读写速度较Redis略慢。
5)数据库功能:MySQL是一种成熟的关系型数据库系统,支持复杂的查询、事务处理、索引等功能,适用于处理复杂的关系数据。而Redis作为缓存数据库和键值存储系统,更适合处理高速读写、低延迟、数据量较小的场景。
综上所述,MySQL适用于需要复杂查询和事务支持的场景,适合存储结构化数据;而Redis适用于高性能、实时性要求高的场景,适合作为缓存、队列或临时数据存储等使用。
1.2 数据处理分类
1)OLTP(On-Line transaction processing):联机事务处理,主要对数据库增删改查。
OLTP 主要用来记录某类业务事件的发生;数据会以增删改的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功。
2)OLAP(On-Line Analytical Processing):联机分析处理,主要对数据库查询。
当数据积累到一定的程度,我们需要对过去发生的事情做一个总结分析时,就需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,这时候就是在做 OLAP 。
1.3 SQL
结构化查询语言(Structured Query Language) 简称 SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL 是关系数据库系统的标准语言。其命令包括:DQL、DML、DDL、DCL以及TCL。
1)DQL(Data Query Language - 数据查询语言)
select :从一个或者多个表中检索特定的记录。
2)DML(Data Manipulate Language - 数据操作语言)
insert :插入记录;
update :更新记录;
delete :删除记录;
3)DDL(Data Define Languge - 数据定义语言)
create :创建一个新的表、表的视图、或者在数据库中的对象;
alter :修改现有的数据库对象,例如修改表的属性或者字段;
drop :删除表、数据库对象或者视图。
4)DCL(Data Control Language - 数据控制语言)
grant :授予用户权限;
revoke :收回用户权限;
5)TCL(Transaction Control Language - 事务控制语言)
commit :事务提交;
rollback :事务回滚
1.4 数据类型
MySQL支持多种数据类型,可以根据需要选择适合的类型。下面是一些常见的MySQL数据类型:
1)数值数据类型:
- INT:整数类型,占用4字节,范围为-2147483648到2147483647。
- BIGINT:大整数类型,占用8字节,范围更大,从-9223372036854775808到9223372036854775807。
- FLOAT(M, D):单精度浮点数,指定总位数M和小数位数D。
- DOUBLE(M, D):双精度浮点数,指定总位数M和小数位数D。
2)字符串数据类型:
- CHAR(N):固定长度字符串,最多可存储N个字符,如果字符数不足,将使用空格填充。
- VARCHAR(N):可变长度字符串,最多可存储N个字符,根据实际字符数分配存储空间。
- TEXT:用于存储大量文本数据的类型。
3)日期和时间数据类型:
- DATE:日期类型,格式为’YYYY-MM-DD’。
- TIME:时间类型,格式为’HH:MM:SS’。
- DATETIME:日期和时间类型,格式为’YYYY-MM-DD HH:MM:SS’。
- TIMESTAMP:自动记录插入或修改操作的日期和时间。
4)布尔数据类型:
- BOOL / BOOLEAN:布尔类型,存储TRUE或FALSE。
5)枚举和集合数据类型:
- ENUM(‘value1’, ‘value2’, …):枚举类型,存储指定的一个值。
- SET(‘value1’, ‘value2’, …):集合类型,可以存储多个指定的值。
还有其他一些复杂的数据类型,如二进制数据类型、JSON数据类型等。
二、数据库设计三范式
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
2.1 范式一
确保每列保持原子性;数据库表中的所有字段都是不可分解的原子值。
例如,表中有一个需要经常访问的地址字段,如果我们设计成:中国浙江省杭州市XXX区XXX号。一般我们分析数据时候,不需要具体地址,只需要知道哪个市哪个区,这个时候需要将该字段拆分,整个操作就很复杂。
2.2 范式二
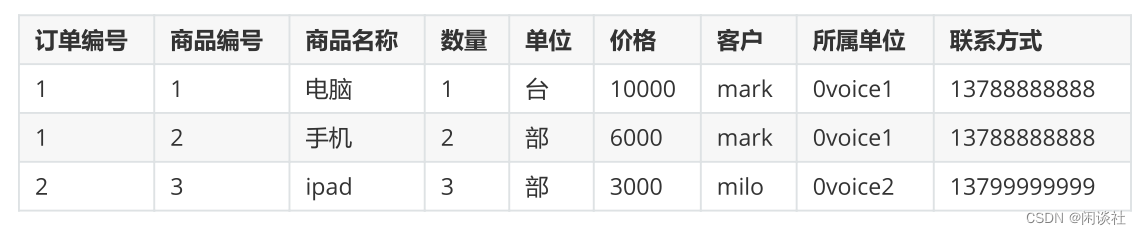
确保表中的每列都和主键相关,而不能只与主键的某一部分相关(组合索引)。
例如下面这张表的设计,有两个主键:订单编号和商品编号,其中{商品名称、数量、单位、价格}只跟商品编号直接相关,{客户、所属单位、联系方式}跟订单编号直接相关。数据少的时候看不出问题,但如果数据量大,整个表格就会很冗余。
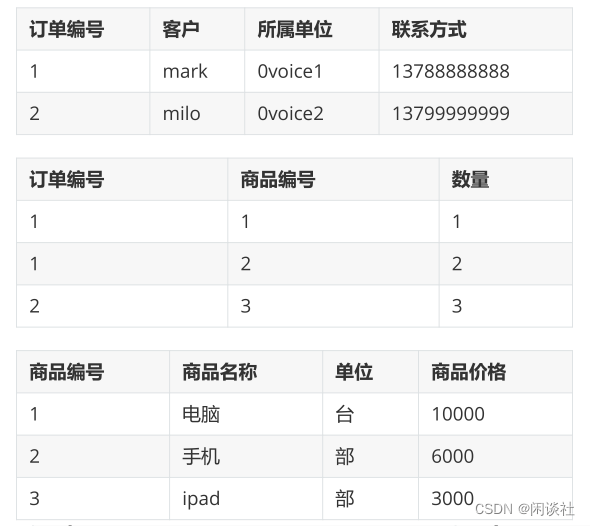
我们可以拆分成三个表,再根据需要联表查询
2.3 范式三
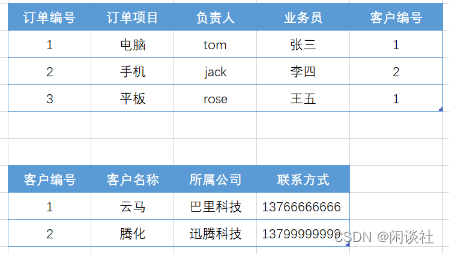
确保每列都和主键直接相关,而不是间接相关;减少数据冗余
例如下面这张表的设计,有一个主键:订单编号。其中{客户名称、所属公司、联系方式}与客户编号直接相关,但与订单编号间接相关。

我们可以拆分成两个表
2.4 反范式
范式可以避免数据冗余,减少数据库的空间,减小维护数据完整性的麻烦;但是采用数据库范式化设计,可能导致数据库业务涉及的表变多,并且造成更多的联表查询,将导致整个系统的性能降低;因此处于性能考虑,可能需要进行反范式设计。
比如用户user表,需要存储很多个人信息,有很多字段确实不符合三范式。比如地址、单位、性别、年龄。但如果都分开,那是很多张表,造成更多的联表查询。
三、MySQL体系结构
3.1 结构组成
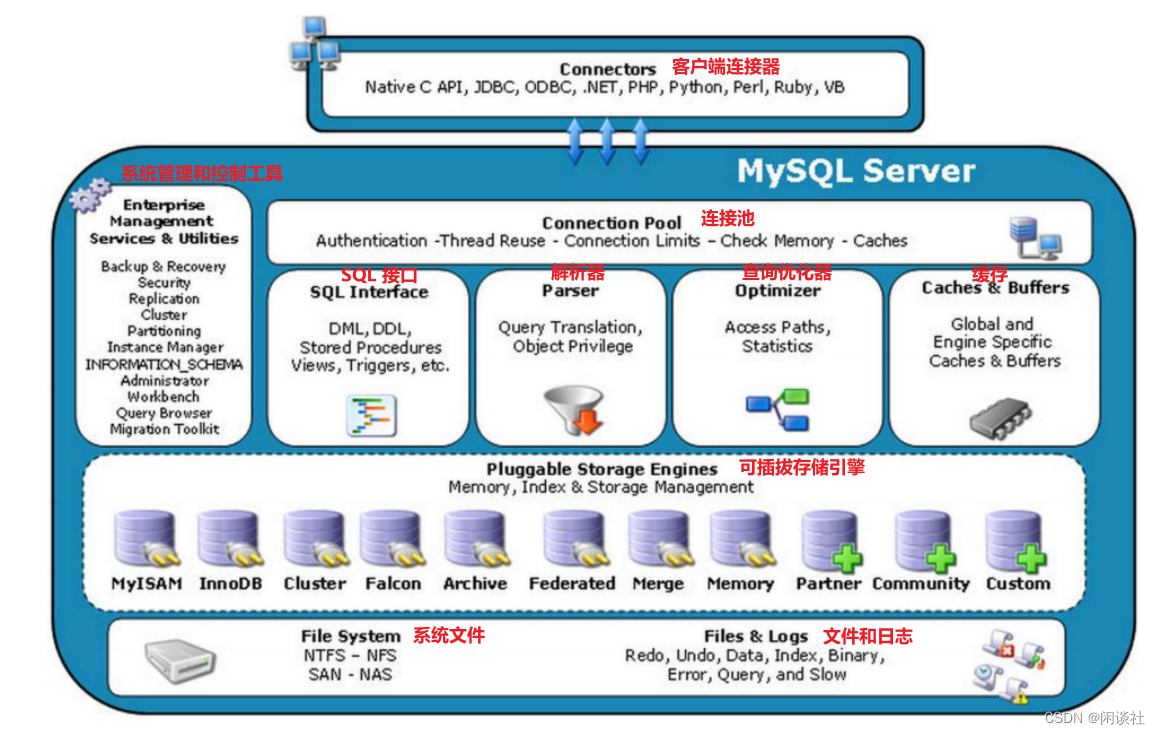
MySQL 由以下几部分组成:
1)连接者
不同语言的代码程序和 MySQL 的交互(SQL交互)
2)连接池
管理缓冲用户连接、用户名、密码、权限校验、线程处理等需要缓存的需求
3)管理服务和工具组件
系统管理和控制工具,例如备份恢复、MySQL 复制、集群等;
4)SQL接口
将 SQL 语句解析生成相应对象;DML,DDL,存储过程,视图,触发器等
5)查询解析器
将 SQL 对象交由解析器验证和解析,并生成语法树
6)查询优化器
SQL 语句执行前使用查询优化器进行优化
7)缓冲组件
是一块内存区域,缓存最近操作的数据,用来弥补磁盘速度较慢对数据库性能的影响
8)插件式存储引擎
9)物理文件
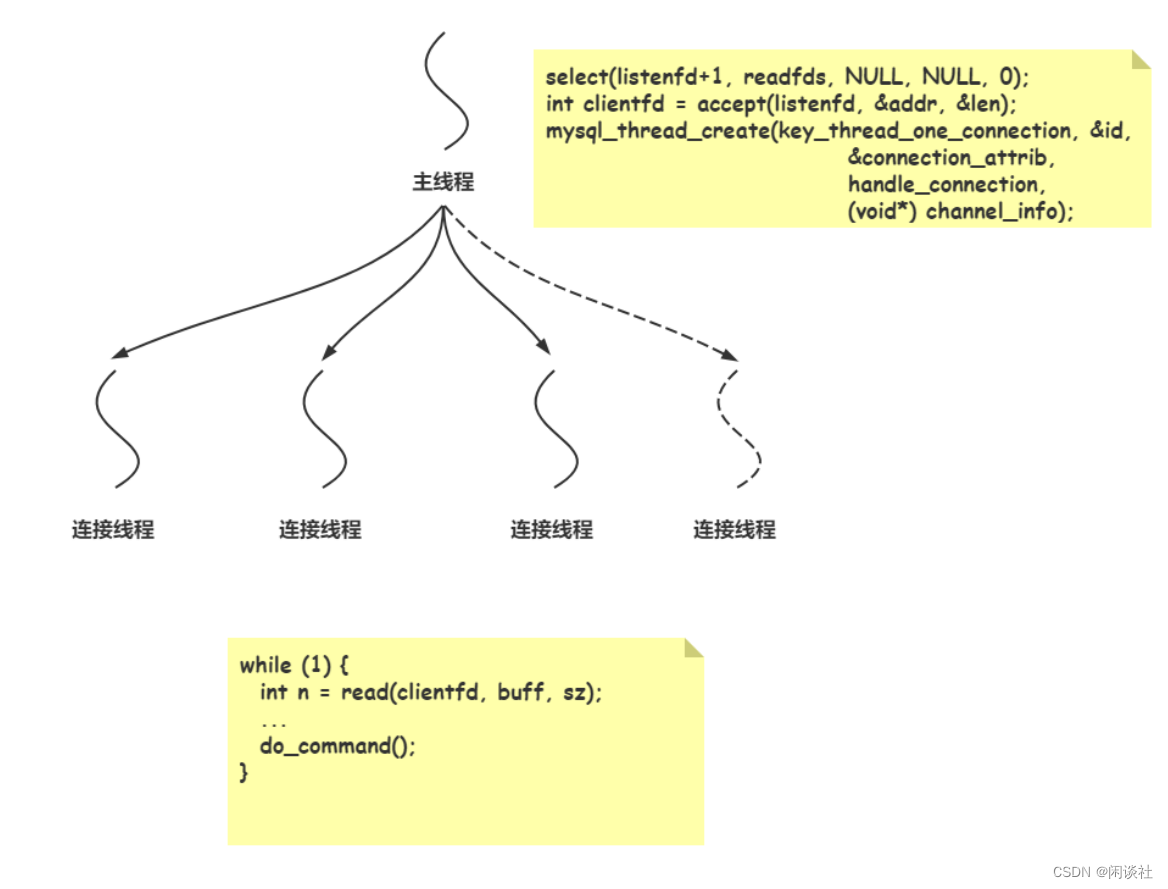
3.2 连接池
MySQL连接池用于管理连接,校验用户信息等。MySQL命令是并发处理的
- 网络处理流程:主线程接收连接,接收连接交由连接池处理
- 主要处理方式:IO多路复用 select + 阻塞的 io
之所以用select 是因为select 是跨平台的IO多路复用。
MySQL命令是并发处理的,主线程负责接收客户端连接,然后为每个客户端 fd 分配一个连接线程,负责处理该客户端的 sql 命令处理。
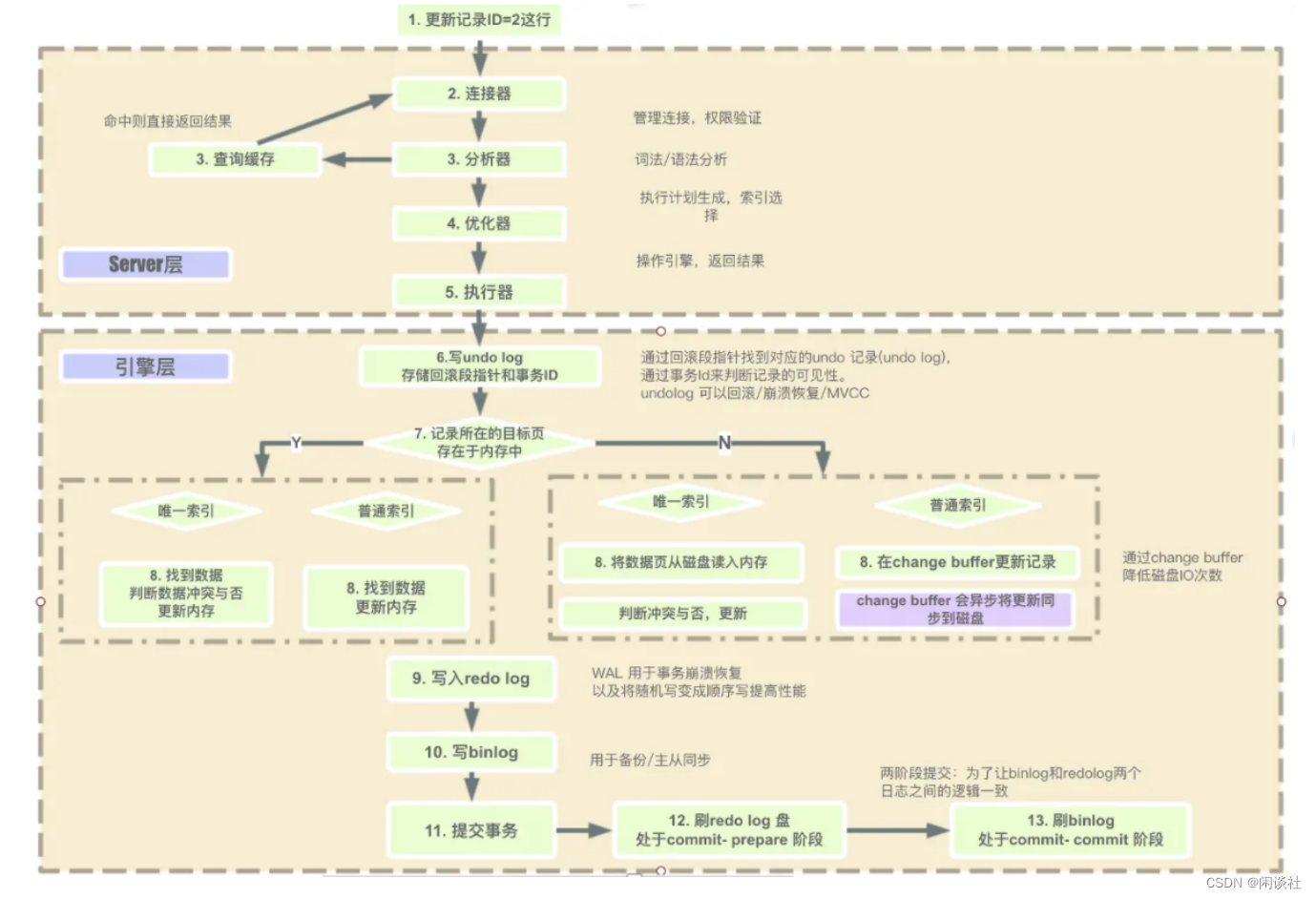
四、sql语句执行过程
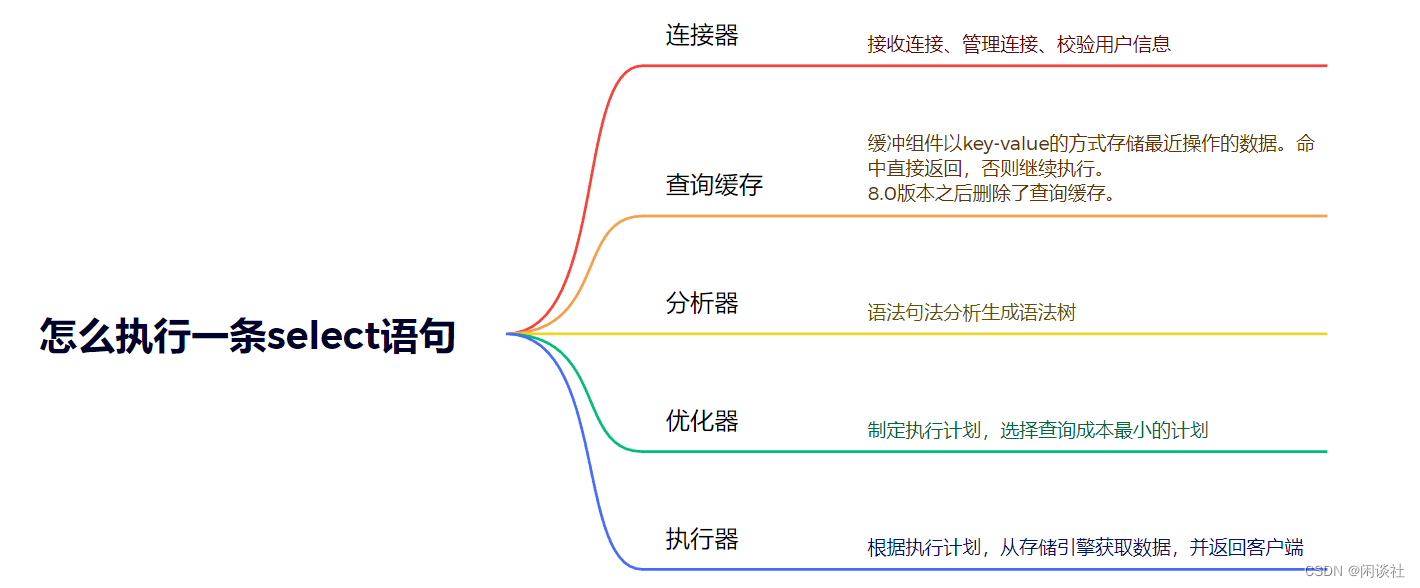
4.1 select语句
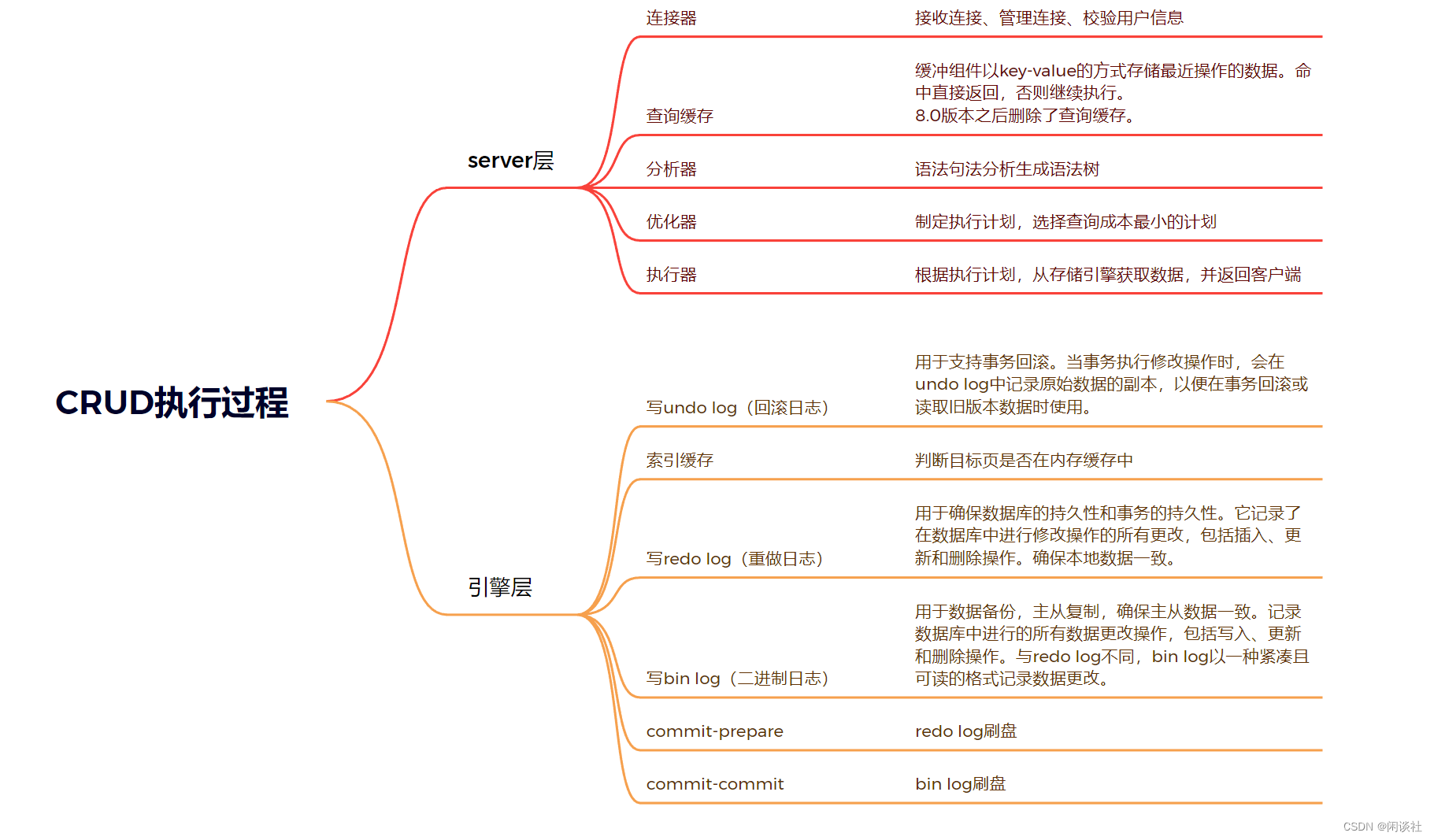
4.2 CRUD执行过程
CRUD操作,即创建(Create)、读取(Read)、更新(Update)和删除(Delete)