yolo训练时可使用的数据集格式为yolo格式以及voc格式, voc格式的数据集在训练时需要先转换为yolo格式,然后根据自己的数据集的位置更改yaml配置文件的文件路径即可。基于目前对Yolo系列训练模型的讲解已经很全面,所以本文主要讲解yolo数据集与voc数据集之间的转换。
两种数据集形式的最大区别就是yolo是直接采用txt文件保存模型的labels标签,如下图,每一行都代表着该图像中的一个标签GT。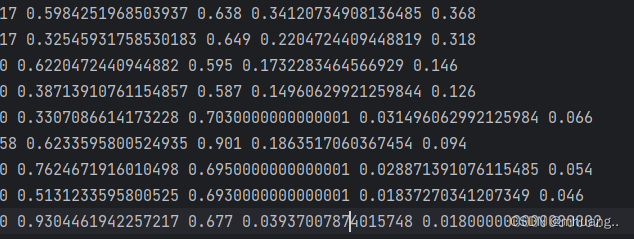
而voc格式的标签是保存在Annotations目录下的xml文件当中,除此之外无差别。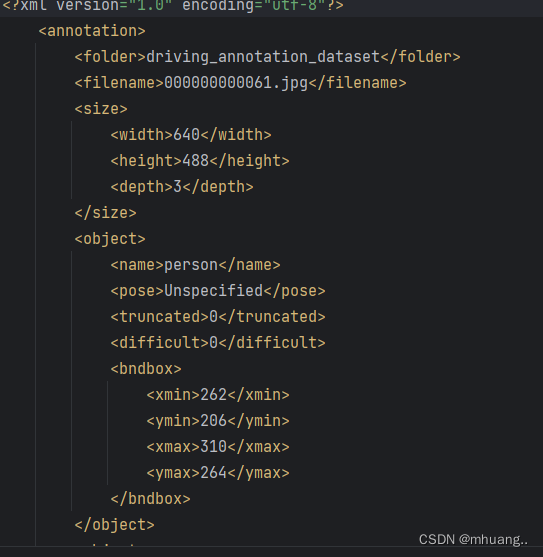
目前大部分数据集的保存都是以voc格式, 在我们训练yolo时需要将voc转换成yolo,说白了就是将基于xml的标签转换为txt保存的标签。
为了深刻理解数据转换的步骤,接下来以coco数据集(yolo格式)为例,实现yolo格式->voc格式->yolo格式的转换。
yolo格式->voc格式
coco数据集:
我们创建一个voc格式的文件目录:
Annotations:存放标签的xml文件
images: 数据集图片.jpg
imageSets: 存放分好的数据集: 训练集,验证集,测试集。
labels: 给yolo模型训练的标签(txt格式)
设置好文件路径:
# coco数据集路径
pre_pic = "../coco128/images/train2017/"
txtPath = "../coco128/labels/train2017/"
# 新voc数据集保存路径
xmlPath = "../my_datasets/Annotations/" # xml标签
after_pic = "../my_datasets/images/" # 训练集图片实现yolo->voc的转换:
# 将标签转换为xml格式
makexml(pre_pic, txtPath, xmlPath)def makexml(picPath, txtPath, xmlPath):
"""
此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
Args:
picPath: 图片所在路径
txtPath: txt格式labels标签
xmlPath: xml文件保存路径
Returns:
"""
dic = config["names"] # 数据集类别字典
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0] if type(oneline[0]) == int else int(oneline[0])])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
print("txt2xml ok!")
注意:xml文件中保存的是标签框的左上角点和右下角点的坐标。
数据集划分
为了让Yolo模型能读取到标签数据,我们需要将voc格式的xml标签转换为txt标签,并且需要对数据集进行划分:
def splitxml(trainval_percent, train_percent):
"""
将数据集分为train,val,test, 并存放在'../my_datasets/ImageSets'这个路径当中
Args:
trainval_percent: 训练集和验证集的比例
train_percent: 训练集比例
Returns:
"""
xmlfilepath = '../my_datasets/Annotations/'
txtsavepath = '../my_datasets/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("split dataset_xml ok!")
这一步会在ImageSets目录下生成:
这几个文件,文件里存放划分后数据集的文件名
voc格式 -> yolo格式
这里有个要注意的地方就是,xml文件里真实框的表示形式是对角点的坐标, Yolo格式标签的预测框表示形式为xywh(中心点坐标和预测框的长宽)并且需要做归一化。
# 将xml格式数据转换为txt
xml2yolo()def xml2yolo():
sets = ['train', 'test', 'val']
classes = list(dic.values())
for image_set in sets:
# 先找labels文件夹如果不存在则创建
if not os.path.exists('../my_datasets/labels/'):
os.makedirs('../my_datasets/labels/')
image_ids = open('../my_datasets/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('../my_datasets/%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write('my_datasets/images/%s.jpg\n' % (image_id))
convert_annotation(image_id, classes)
# 关闭文件
list_file.close()
print("xml2txt ok!")
def convert_annotation(image_id, classes):
# 对应的通过year 找到相应的文件夹,并且打开相应image_id的xml文件,其对应bund文件
# print('my_datasets/Annotations/%s.xml' % (image_id))
in_file = open('../my_datasets/Annotations/%s.xml' % (image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
# <object-class> <x> <y> <width> <height>
out_file = open('../my_datasets/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 如果xml内的标记为空,增加判断条件
if size != None:
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult ??
difficult = obj.find('difficult').text
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过
# if cls not in classes or int(difficult) == 1:
# continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1. / size[0] # 1/w
dh = 1. / size[1] # 1/h
x = (box[0] + box[1]) / 2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3]) / 2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x * dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w * dw # 物体宽度的宽度比(相当于 w/原图w)
y = y * dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h * dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
执行完代码后会在数据集目录下生成
test,train,val三个txt文件,里面存放着各数据集的路径, 训练模型时只需要将这三个txt文件的路径写入my_datasets.yaml里,然后让Yolo模型读取这个yaml文件即可。
完整代码:
# -*- coding: utf-8 -*-
# xml解析包
from xml.dom.minidom import Document
import os
import cv2
import random
import xml.etree.ElementTree as ET
import yaml
import shutil
# 将数据转换为xml格式
def makexml(picPath, txtPath, xmlPath):
"""
此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
Args:
picPath: 图片所在路径
txtPath: txt格式labels标签
xmlPath: xml文件保存路径
Returns:
"""
dic = config["names"] # 数据集类别字典
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0] if type(oneline[0]) == int else int(oneline[0])])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
print("txt2xml ok!")
def moveimage(pre_path, after_path):
path_dir = os.listdir(pre_path)
for file in path_dir:
shutil.copy(pre_path + file, after_path)
# 将数据集分为train,val,test
def splitxml(trainval_percent, train_percent):
"""
将数据集分为train,val,test, 并存放在'../my_datasets/ImageSets'这个路径当中
Args:
trainval_percent: 训练集和验证集的比例
train_percent: 训练集比例
Returns:
"""
xmlfilepath = '../my_datasets/Annotations/'
txtsavepath = '../my_datasets/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + '/trainval.txt', 'w')
ftest = open(txtsavepath + '/test.txt', 'w')
ftrain = open(txtsavepath + '/train.txt', 'w')
fval = open(txtsavepath + '/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("split dataset_xml ok!")
def xml2yolo():
sets = ['train', 'test', 'val']
classes = list(dic.values())
for image_set in sets:
# 先找labels文件夹如果不存在则创建
if not os.path.exists('../my_datasets/labels/'):
os.makedirs('../my_datasets/labels/')
image_ids = open('../my_datasets/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('../my_datasets/%s.txt' % (image_set), 'w')
# 将对应的文件_id以及全路径写进去并换行
for image_id in image_ids:
list_file.write('my_datasets/images/%s.jpg\n' % (image_id))
convert_annotation(image_id, classes)
# 关闭文件
list_file.close()
print("xml2txt ok!")
def convert_annotation(image_id, classes):
# 找到相应的文件夹,并且打开相应image_id的xml文件
# print('my_datasets/Annotations/%s.xml' % (image_id))
in_file = open('../my_datasets/Annotations/%s.xml' % (image_id), encoding='utf-8')
# 准备在对应的image_id 中写入对应的label,分别为
# <object-class> <x> <y> <width> <height>
out_file = open('../my_datasets/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# 解析xml文件
tree = ET.parse(in_file)
# 获得对应的键值对
root = tree.getroot()
# 获得图片的尺寸大小
size = root.find('size')
# 如果xml内的标记为空,增加判断条件
if size != None:
# 获得宽
w = int(size.find('width').text)
# 获得高
h = int(size.find('height').text)
# 遍历目标obj
for obj in root.iter('object'):
# 获得difficult ??
difficult = obj.find('difficult').text
# 获得类别 =string 类型
cls = obj.find('name').text
# 如果类别不是对应在我们预定好的class文件中,或difficult==1则跳过(一般用不到)
# if cls not in classes or int(difficult) == 1:
# continue
# 通过类别名称找到id
cls_id = classes.index(cls)
# 找到bndbox 对象
xmlbox = obj.find('bndbox')
# 获取对应的bndbox的数组 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# print(image_id, cls, b)
# 带入进行归一化操作
# w = 宽, h = 高, b= bndbox的数组 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 对应的是归一化后的(x,y,w,h)
# 生成 calss x y w h 在label文件中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 进行归一化操作
def convert(size, box): # size:(原图w,原图h) , box:(xmin,xmax,ymin,ymax)
dw = 1. / size[0] # 1/w
dh = 1. / size[1] # 1/h
x = (box[0] + box[1]) / 2.0 # 物体在图中的中心点x坐标
y = (box[2] + box[3]) / 2.0 # 物体在图中的中心点y坐标
w = box[1] - box[0] # 物体实际像素宽度
h = box[3] - box[2] # 物体实际像素高度
x = x * dw # 物体中心点x的坐标比(相当于 x/原图w)
w = w * dw # 物体宽度的宽度比(相当于 w/原图w)
y = y * dh # 物体中心点y的坐标比(相当于 y/原图h)
h = h * dh # 物体宽度的宽度比(相当于 h/原图h)
return (x, y, w, h) # 返回 相对于原图的物体中心点的x坐标比,y坐标比,宽度比,高度比,取值范围[0-1]
config_file = "../my_datasets/my_datasets.yaml"
with open(config_file, "r") as file:
config = yaml.safe_load(file)
dic = config["names"] # 类别字典
if __name__ == "__main__":
isyolo = True
if isyolo:
# Yolo格式数据路径
# coco数据集路径
pre_pic = "../coco128/images/train2017/"
txtPath = "../coco128/labels/train2017/"
# 新voc数据集保存路径
xmlPath = "../my_datasets/Annotations/" # xml标签
after_pic = "../my_datasets/images/" # 训练集图片
# 将标签转换为xml格式
makexml(pre_pic, txtPath, xmlPath)
# 将图像移动到images中
moveimage(pre_pic, after_pic)
# 将数据集分为train,val,test
splitxml(0.9, 0.9)
# 将xml格式数据转换为txt
xml2yolo()