目录
1、根据二叉树创建字符串
2、二叉树的层序遍历
3、二叉树的最近公共祖先
4、搜索二叉树与双向链表
5、从前序与中序遍历序列构造二叉树
6、 从中序与后序遍历序列构造二叉树
7、二叉树的前序遍历(非递归实现)
8、二叉树的中序遍历(非递归实现)
9、二叉树的后序遍历(非递归实现)
1、根据二叉树创建字符串
题目要求:给你二叉树的根节点
root,请你采用前序遍历的方式,将二叉树转化为一个由括号和整数组成的字符串,返回构造出的字符串。
例1:
前序遍历完应该是"1(2(3)())(5)",但是2没有右孩子,所以可以省略第一个括号
化简为:"1(2(3))(5)"
例2:
前序遍历完应该是"1(2()(3))(5)",但是2没有左孩子,如果省略第一个括号,会辨别不清是左孩子还是右孩子
所以依旧为:"1(2()(3))(5)"
根据上面的样例,可以明白有这样几种情况:
①左右都不为空,则都不省略括号
②左右都为空,都省略括号
③左不为空,右为空,可以省略右括号
④左为空,右不为空,不能省略左括号
总结就是:如果右不为空,无论左边是否为空,右边都需要加括号
如果左不为空或右不为空,则左边需要加括号代码如下:
class Solution { public: string tree2str(TreeNode* root) { //若root为空,则返回一个string的匿名对象 if(root == nullptr) { return string(); } //1、如果左不为空或右不为空,左边需要加括号 //2、如果右不为空,右边需要加括号 string str; //to_string将val转换为字符变量,以便可以+= str += to_string(root->val); //情况1 if(root->left || root->right) { str += '('; str += tree2str(root->left); str += ')'; } //情况2 if(root->right) { str += '('; str += tree2str(root->right); str += ')'; } return str; } };


2、二叉树的层序遍历
题目要求:给你二叉树的根节点
root,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
思路分析:
我们可以创建一个队列,队列中存的是二叉树的指针,再给一个levelSize,记录每一层的节点数,在循环过程中,创建一个vector<int>的数组,存每一层的结点val值。首先,二叉树若不为空则将root存进队列中,再经过判断将root的左右孩子存进队列中,队列头结点pop前,都将val存入v中,每层结束,都将v的值push_back到vv中,以此类推,具体代码中注释部分有
代码:
class Solution { public: vector<vector<int>> levelOrder(TreeNode* root) { //层序遍历一般会使用队列 queue<TreeNode*> q; //levelSize是每一层的节点数 size_t levelSize = 0; //如果根节点不为空,则队列中插入root,节点数置为1 if(root) { q.push(root); levelSize = 1; } //vv是需要返回的vector<vector<int>> vector<vector<int>> vv; //while循环,直到队列为空 while(!q.empty()) { //创建vector<int> v,存储每一层的结点的val vector<int> v; //for循环保证每次循环一层的结点 for(size_t i = 0;i < levelSize; ++i) { //由于每次都要删除队列的第一个值 //所以front来保留一下指针,以免找不到左右字树 TreeNode* front = q.front(); q.pop(); //每次删除的时候都存进v v.push_back(front->val); //如果删除结点有左右孩子,都存进队列中 if(front->left) q.push(front->left); if(front->right) q.push(front->right); } //每循环完一层,就往vv里存一层的val值 vv.push_back(v); //接着重新赋值levelSize,即下一层数的节点数 levelSize = q.size(); } return vv; } };
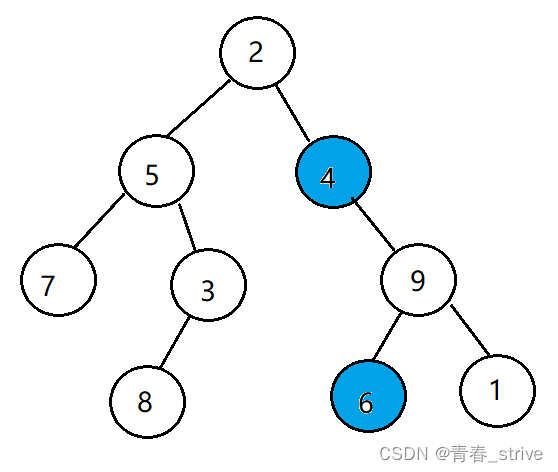
3、二叉树的最近公共祖先
题目要求:给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
方法一例1:
则最近公共祖先是结点2
方法一例2:
则最近公共祖先是结点4
所以方法一我们可以用下面两个思路:
1、如果一个是左子树中的结点,一个是右子树中的结点,那么它就是最近公共祖先
2、如果一个结点A是结点B的祖先,那么公共祖先就是结点A
方法一的代码:(方法一如果遇到公共祖先在二叉树下面的部分,会导致效率比较低)
class Solution { public: bool Find(TreeNode* root, TreeNode* x) { //如果查找的为空,返回nullptr if(root == nullptr) return false; //如果找到了,返回true if(root == x) return true; //如果没找到,则递归进左右字树找 return Find(root->left, x) || Find(root->right, x); } TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { if(root == nullptr) return nullptr; //说明公共祖先是root, if((root == p) || (root == q)) return root; //p/q在一左一右,则说明当前root是公共祖先 //设定4个bool类型变量,与Find结合使用 bool pInLeft,pInRight,qInleft,qInRight; pInLeft = Find(root->left, p); pInRight = !pInLeft; //在左就说明不在右,所以可以用! qInleft = Find(root->left, q); qInRight = !qInleft; //一个在左一个在右,则它是公共祖先 if((pInLeft && qInRight) || (pInRight && qInleft)) return root; //若都在root左或右,则递归进左或右子树中,重新判断上面的条件 else if(pInLeft && qInleft) return lowestCommonAncestor(root->left, p, q); else if(pInRight && qInRight) return lowestCommonAncestor(root->right, p, q); //此题不会进入这里,因为p/q都在二叉树中 else return nullptr; } };方法二思路:(相比方法一效率高点,O(N))
将p和q的从根结点开始的路径放入栈中,将所得两个结点的较长的路径pop到和较短路径一样长为止,然后依次判断栈顶元素是否相同
思路类似链表相交
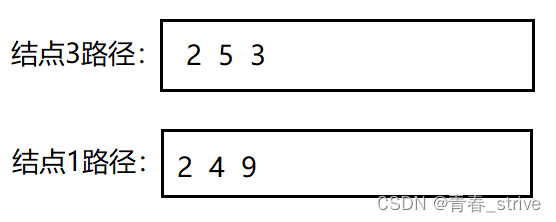
方法二例子:
结点3和结点1的路径放栈里如图:
结点1路径长度大,pop相等后变为:
接着从两个栈顶元素3和9开始判断,不相同,两个都pop,直到遇到2,返回结点2
方法二代码:
class Solution { public: bool FindPath(TreeNode* root, TreeNode* x, stack<TreeNode*>& path) { //是空返回false if(root == nullptr) return false; //不论是不是先入栈,因为后面判断不是路径会pop path.push(root); //如果找到了,返回true if(root == x) return true; //如果没找到,进入左子树找 if(FindPath(root->left,x,path)) return true; //如果左子树没找到,进入右子树找 if(FindPath(root->right,x,path)) return true; //左右字树都没找到,pop掉当前栈顶元素,返回false path.pop(); return false; } TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { //栈的每个元素都是TreeNode*类型 stack<TreeNode*> pPath,qPath; //FindPath中传入的pPath和qPath都是p和q从根结点的路径 FindPath(root, p, pPath); FindPath(root, q, qPath); //p/q结点的路径长度不同,先变为相同路径长度 while(pPath.size() != qPath.size()) { if(pPath.size() > qPath.size()) pPath.pop(); else qPath.pop(); } //相同路径长度一层层判断顶部元素是否相同 while(pPath.top() != qPath.top()) { pPath.pop(); qPath.pop(); } //走到这里说明找到了相同的结点,即最近祖先 return pPath.top(); } };


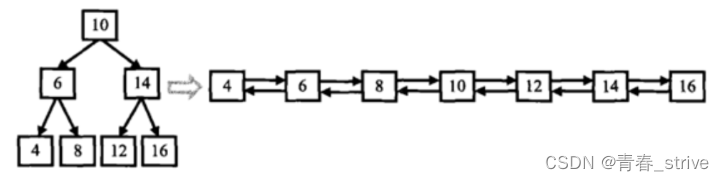
4、搜索二叉树与双向链表
题目要求:输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。如下图所示:
1.要求不能创建任何新的结点,只能调整树中结点指针的指向。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继
2.返回链表中的第一个节点的指针
3.函数返回的TreeNode,有左右指针,其实可以看成一个双向链表的数据结构
思路分析:
由于不能创建新的结点,只能调整树中结点指针的指向,所以我们就不能用先中序排好序以后,再遍历的方法
那么就在中序遍历的过程中,给两个指针,一个prev,一个cur,prev是指向前一个结点,cur是值向当前的结点,每次cur变化前,都将值赋值给prev,然后再将cur->left指向prev,以此类推完成了left指针,当前的prev就是上一个cur,所以prev->right = cur就是相当于上一个cur->right也指向了下一个结点,从而完成了right指针
代码:
class Solution { public: //中序遍历,并在过程中调整结点指针的指向 //cur是当前结点的指针,prev是前一个结点的指针 void Inorder(TreeNode* cur,TreeNode*& prev) { if(cur == nullptr) return; //先左子树 Inorder(cur->left,prev); //cur->left直接给prev,因为prev是前一个结点指针 cur->left = prev; //若prev不为空,且为TreeNode*& prev,是传引用,即: //prev->right就完成了上一个cur结点的right指针指向 if(prev) prev->right = cur; //在cur指向下一个之前,赋值给prev prev = cur; //再右子树 Inorder(cur->right,prev); } TreeNode* Convert(TreeNode* pRootOfTree) { //创建一个prev置空,传入Inorder进行中序排序 TreeNode* prev = nullptr; Inorder(pRootOfTree, prev); //head先指定为题目所给的根结点 TreeNode* head = pRootOfTree; //顺着left指针找到中序遍历的第一个结点 //为了防止pRootOfTree为空,要先判断head while(head && head->left) head = head->left; //返回第一个结点指针 return head; } };
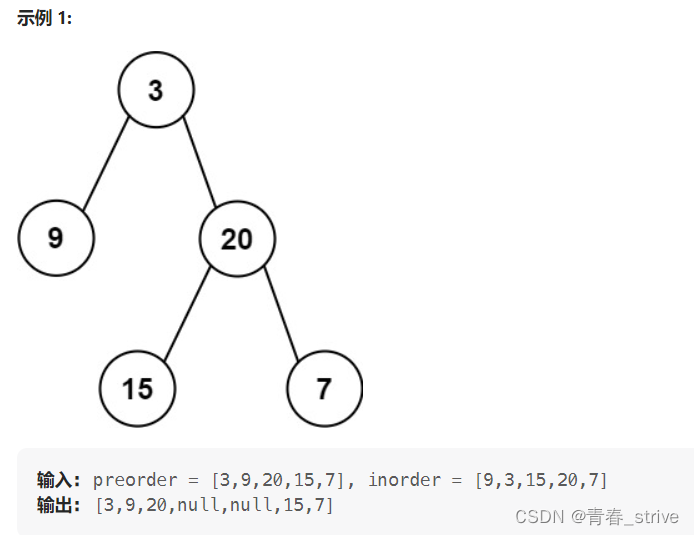
5、从前序与中序遍历序列构造二叉树
题目要求:给定两个整数数组
preorder和inorder,其中preorder是二叉树的先序遍历,inorder是同一棵树的中序遍历,请构造二叉树并返回其根节点。
思路:
通过前序遍历确定根,通过中序遍历确定左右字树
子树区间确认是否继续递归创建子树,不存在区间则是空树
代码:
class Solution { public: //创建_buildTree函数进行递归调用 //prei是前序遍历结果的首元素下标,inbegin、inend是中序遍历结果首尾元素的下标 TreeNode* _buildTree(vector<int>& preorder, vector<int>& inorder, int& prei, int inbegin, int inend) { //如果在前序遍历的结果中找, if(inbegin > inend) return nullptr; //每次递归通过前序遍历结果创建根结点 TreeNode* root = new TreeNode(preorder[prei++]); //while循环找到中序遍历的该结点的位置 int cur = inbegin; while(cur <= inend) { if(inorder[cur] == root->val) break; else cur++; } //中序遍历的结果中,分成了三个部分,[左子树]根[右子树] //[inbegin, cur-1] cur [cur+1,inend] //所以接下来递归时,传入这两个区间 root->left = _buildTree(preorder,inorder,prei,inbegin,cur-1); root->right = _buildTree(preorder,inorder,prei,cur+1,inend); return root; } TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) { //前序遍历首元素下标为0 int prei = 0; //中序遍历结果首尾元素的下标为0和inorder.size()-1 TreeNode* root = _buildTree(preorder,inorder,prei,0,inorder.size()-1); return root; } };
6、 从中序与后序遍历序列构造二叉树
题目要求:给定两个整数数组
inorder和postorder,其中inorder是二叉树的中序遍历,postorder是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
这个题和上面的从前序与中序遍历序列构造二叉树大体思路一样,但是由于是后序确定根结点,所以给定后序遍历结果的下标posi,每次都会posi--,并且是先递归右子树,再递归左子树,因为后序遍历顺序是左子树,右子树,根结点,反过来就是根结点,右子树,左子树
所以代码如下:
class Solution { public: TreeNode* _buildTree(vector<int>& inorder, vector<int>& postorder,int& posi,int inbegin,int inend) { if(inbegin > inend) return nullptr; TreeNode* root = new TreeNode(postorder[posi--]); int cur = inbegin; while(cur <= inend) { if(root->val == inorder[cur]) break; else cur++; } //[inbegin,cur-1] cur [cur+1,inend] root->right = _buildTree(inorder,postorder,posi,cur+1,inend); root->left = _buildTree(inorder,postorder,posi,inbegin,cur-1); return root; } TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { int posi = postorder.size()-1; return _buildTree(inorder,postorder,posi,0,inorder.size()-1); } };
7、二叉树的前序遍历(非递归实现)
题目要求:给你二叉树的根节点
root,返回它节点值的 前序 遍历。
思路分析:
采用非递归实现该问题,能提高效率,并且递归调用需要建立栈帧,如果深度比较深会容易崩溃,所以需要掌握非递归的方法
前序遍历中,我们可以将所有结点分为左路结点,以及左路结点的右子树
那么我们第一步就是将左路结点都保存下来,并且存在栈中,接着将存入栈的结点一个一个出栈,并访问右子树,然后重复上面的步骤(左路结点保存,入栈,全部入栈后,然后出栈,访问该出栈结点的右子树)
当左路结点从栈中出来时,表示左子树以及访问过了,该访问该结点和它的右子树了
就相当于转换为了子问题,将所有结点分为左路结点,以及左路结点的右子树,接着将左路结点的右子树又分为:左路结点,以及左路结点的右子树以此类推,从而实现非递归的方法完成前序遍历
代码如下:
class Solution { public: vector<int> preorderTraversal(TreeNode* root) { vector<int> v; stack<TreeNode*> st; TreeNode* cur = root; //循环条件有两个都不符合才结束循环 //一是栈里空,表明初始的左路结点的右子树都已访问 //二是cur为空,表明访问的栈中的结点的右子树为空 while(cur || !st.empty()) { //1、左路结点 while(cur) { v.push_back(cur->val); st.push(cur); cur = cur->left; } //2、左树结点的右子树 TreeNode* top = st.top(); st.pop(); //将左路结点以外的数转化为上面两条的子问题 //转换为子问题从而访问栈中结点的右子树 cur = top->right; } return v; } };
8、二叉树的中序遍历(非递归实现)
题目要求:给定一个二叉树的根节点
root,返回 它的 中序 遍历 。
中序遍历和前序遍历思路大体相同,但是由于中序遍历是:左子树,根,右子树。所以中序遍历的结果需要在左路结点都入栈后,再依次push_back进数组中,剩下思路和前序遍历相同
代码如下:
class Solution { public: vector<int> inorderTraversal(TreeNode* root) { vector<int> v; stack<TreeNode*> st; TreeNode* cur = root; while(cur || !st.empty()) { while(cur) { st.push(cur); cur = cur->left; } //左路结点都入栈后,再尾插栈顶元素到数组中 //依次取栈顶元素,再pop,转换为子问题循环 TreeNode* top = st.top(); st.pop(); v.push_back(top->val); cur = top->right; } return v; } };
9、二叉树的后序遍历(非递归实现)
题目要求:给你一棵二叉树的根节点
root,返回其节点值的 后序遍历 。
思路分析:
后序遍历和前序/中序有一点区别,因为后序是左子树,右子树,根,我们先找到左路结点后,无法确认该结点的右子树有没有访问,所以就这一问题可以分类讨论
设定一个prev结点,让他指向cur结点的前一个结点,即每次尾插入数组时都记录当前的结点值,赋值给prev,这样在cur = cur->right以后,prev就是cur所访问的前一个结点。
将所有左路结点全部插入到栈以后,分为两种情况:
第一:该结点的右子树为空或该结点的右子树已经访问过了,第二:该结点的右子树没有被访问过
第一种情况就可以访问这个栈顶结点,否则先访问该结点的右子树,转换为了子问题
代码:
class Solution { public: vector<int> postorderTraversal(TreeNode* root) { vector<int> v; stack<TreeNode*> st; TreeNode* cur = root; TreeNode* prev = nullptr; while(cur || !st.empty()) { //左路结点入栈 while(cur) { st.push(cur); cur = cur->left; } TreeNode* top = st.top(); //右子树为空或上一个访问的就是该结点的右子树的根 //说明右子树已经访问过了 if(top->right == nullptr || top->right == prev) { v.push_back(top->val); prev = top; cur = nullptr; st.pop(); } //否则先访问栈顶结点的右子树 else { cur = top->right; } } return v; } };
相关题目列举这些