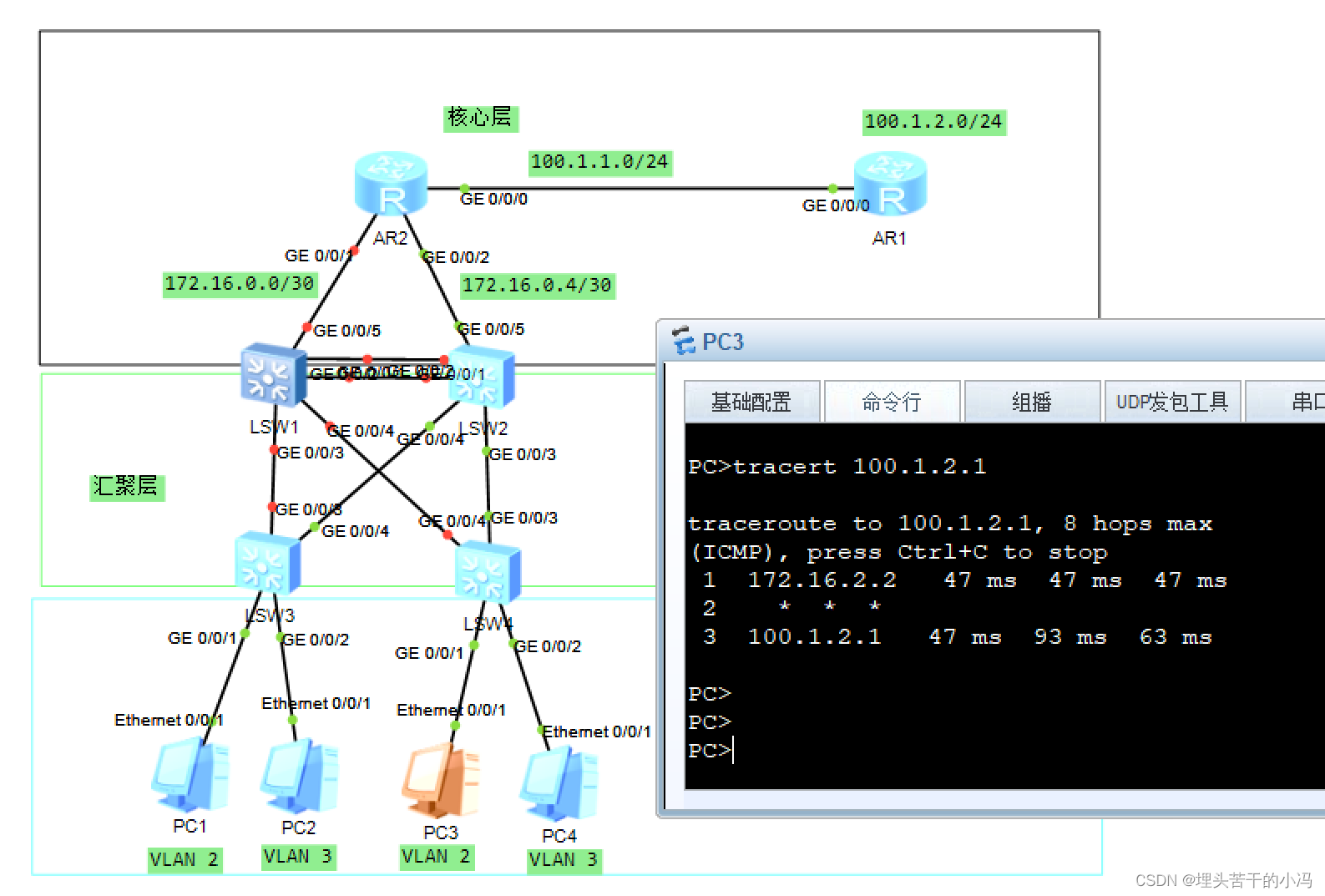
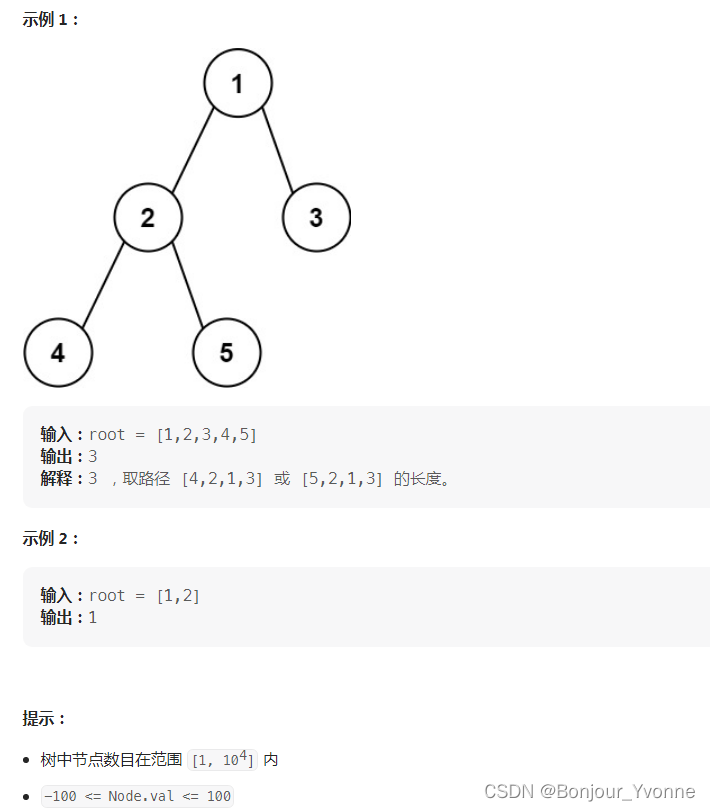
为什么去西藏的人都会感觉很治愈
拉萨的老中医是这么说的
缺氧脑子短路,很多事想不起来,就会感觉很幸福
一、卷积层
解释:卷积层通过卷积操作对输入数据进行处理。它使用一组可学习的滤波器(也称为卷积核或特征检测器),将滤波器与输入数据进行逐元素的乘法累加操作,从而生成输出特征图。这种滤波器的操作类似于图像处理中的卷积操作,因此得名卷积层。
主要作用:
-
特征提取:卷积层通过滤波器的卷积操作,可以有效地提取输入数据中的局部特征。滤波器可以学习到不同的特征,例如边缘、纹理、形状等,这些特征对于图像识别和分类等任务非常重要。
-
参数共享:卷积层的滤波器在整个输入数据上共享参数。这意味着在不同位置上使用相同的滤波器,从而减少了需要学习的参数数量。这种参数共享的特性使得卷积层具有一定的平移不变性,即对于输入数据的平移操作具有不变性。
-
减少参数数量:相比全连接层(每个神经元与上一层的所有神经元相连),卷积层的参数数量较少。这是因为卷积层的滤波器在空间上共享参数,并且每个滤波器只与输入数据的局部区域进行卷积操作。这种参数共享和局部连接的方式大大减少了需要学习的参数数量,提高了模型的效率和泛化能力。
-
空间结构保持:卷积层在进行卷积操作时,保持了输入数据的空间结构。这意味着输出特征图的每个元素对应于输入数据的相应局部区域,从而保留了输入数据的空间信息。这对于图像处理任务非常重要,因为图像中的相邻像素之间存在一定的关联性。
使用示例:

代码示例:
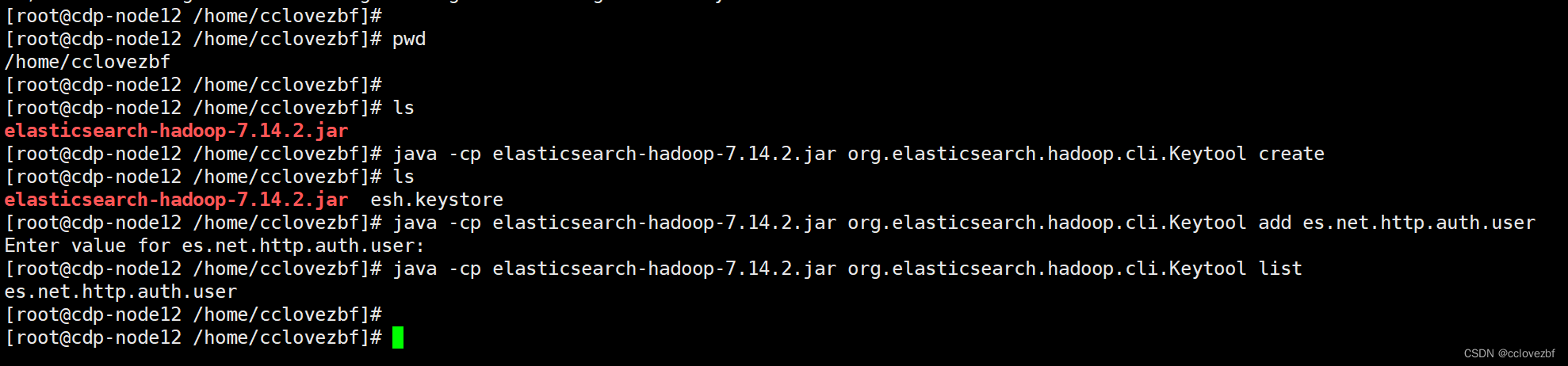
import torch
import torch.nn.functional as F
# 模拟图像
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 模拟卷积核
kernal = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 参数结构转化
input = torch.reshape(input, (1, 1, 5, 5))
kernal = torch.reshape(kernal, (1, 1, 3, 3))
print(input.shape)
print(kernal.shape)
# 输入经过卷积操作
output = F.conv2d(input, kernal, stride=2, padding=1)
print(output)输出
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[ 1, 4, 8],
[ 7, 16, 8],
[14, 9, 4]]]])图片数据集经过卷积层输出:
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.nn import Conv2d
from torch import nn
from torch.utils.tensorboard import SummaryWriter
# 加载数据集并加载到神经网络中
dataset = torchvision.datasets.CIFAR10("./cifar10", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class Lh(nn.Module):
def __init__(self):
super(Lh, self).__init__()
self.conv1 = Conv2d(3, 6, 3, 1)
def forward(self, x):
x = self.conv1(x)
return x
lh = Lh()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data
output = lh(imgs)
writer.add_images("input", imgs, step)
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
通过tensorboard展示

二、最大池化层
解释:它将输入数据划分为不重叠的矩形区域(通常是2x2的窗口),然后在每个区域中选择最大值作为输出。这样,最大池化层通过取每个区域中的最大值来减少数据的维度。
主要作用:
-
特征减少:最大池化层可以减少输入数据的空间尺寸,从而降低了模型的计算复杂度。通过减少特征图的尺寸,最大池化层能够在保留重要特征的同时,减少需要处理的数据量,提高模型的效率。
-
平移不变性:最大池化层具有一定的平移不变性,即对于输入数据的平移操作具有不变性。这是因为在最大池化操作中,只选择每个区域中的最大值,而不考虑其位置信息。这种平移不变性使得神经网络对于输入数据的位置变化具有一定的鲁棒性。
-
特征提取:最大池化层可以帮助提取输入数据中的主要特征。通过选择每个区域中的最大值作为输出,最大池化层能够保留输入数据中的重要特征,并且对于噪声和不重要的细节具有一定的鲁棒性。
最大池化层在神经网络中起到了减少数据维度、提取关键特征和增强模型的鲁棒性等作用(简单来说就是把1080p的视频变成720p的)。它通常与卷积层交替使用,帮助神经网络有效地处理输入数据,提高模型的性能和泛化能力。
使用示例:
import torch
from torch.nn import MaxPool2d
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10('./cifar10', train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, 64, False)
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (1, 1, 5, 5))
class Lh(nn.Module):
def __init__(self):
super(Lh, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, x):
x = self.maxpool(x)
return x
lh = Lh()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, tagerts = data
writer.add_images("input", imgs, step)
output = lh(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
使用torchboard打卡

三、非线性激活函数
解释:神经网络的非线性激活函数是在神经网络的每个神经元上引入非线性变换的函数。它的作用是为神经网络引入非线性能力,从而使网络能够学习和表示更加复杂的函数关系。
主要作用:
-
引入非线性:线性变换的组合只能表示线性关系,而神经网络的层级结构和参数学习能力使其具备了更强大的函数逼近能力。非线性激活函数的引入打破了线性关系的限制,使得神经网络可以学习和表示非线性的函数关系,从而更好地适应复杂的数据模式。
-
增强模型的表达能力:非线性激活函数可以增强神经网络的表达能力,使其能够学习和表示更加复杂的特征和模式。通过引入非线性变换,激活函数可以对输入信号进行非线性映射,从而提取和表示更多种类的特征,帮助网络更好地理解输入数据。
-
解决分类问题的非线性可分性:在处理分类问题时,输入数据通常是非线性可分的。非线性激活函数可以帮助神经网络学习并表示类别之间的非线性边界,从而提高分类准确性。例如,常用的激活函数如ReLU、Sigmoid和Tanh等都是非线性的,它们可以帮助神经网络学习并表示复杂的决策边界。
-
缓解梯度消失问题:在深层神经网络中,反向传播算法需要通过链式法则计算梯度并更新参数。线性激活函数(如恒等映射)会导致梯度的乘积变得非常小,从而导致梯度消失问题。而非线性激活函数可以通过引入非线性变换,使得梯度能够在网络中传播并保持较大的幅度,从而缓解了梯度消失问题,有助于更好地训练深层网络。
使用示例:
import torch
import torchvision.datasets
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
dataset = torchvision.datasets.CIFAR10("./cifar10", False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, 64)
class Lh(nn.Module):
def __init__(self):
super(Lh, self).__init__()
self.relu1 = ReLU()
self.sigmoid = Sigmoid()
def forward(self, input):
return self.sigmoid(input)
lh = Lh()
step = 0
writer = SummaryWriter("logs")
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = lh(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
print("end")
使用torchboard打开

四、其它层与神经网络模型
查看pytorch的官方文档可以看到,神经网络中不同层及其使用
你可以创建自己的神经网络,然后自由搭配里面的网络层进行模型的训练。但是一般情况下我们不用手动去一层一层构建,因为官网提供了很多已经搭配好的神经网络模型,这些模型的训练效果都非常不错,我们只需要选择构建好的模型使用即可。
如 torchvision.models
五、神经网络搭建小实战
crfar10 model structure

根据上图,以input为 3@32 * 32为例,可更据公式计算pandding

代码示例:
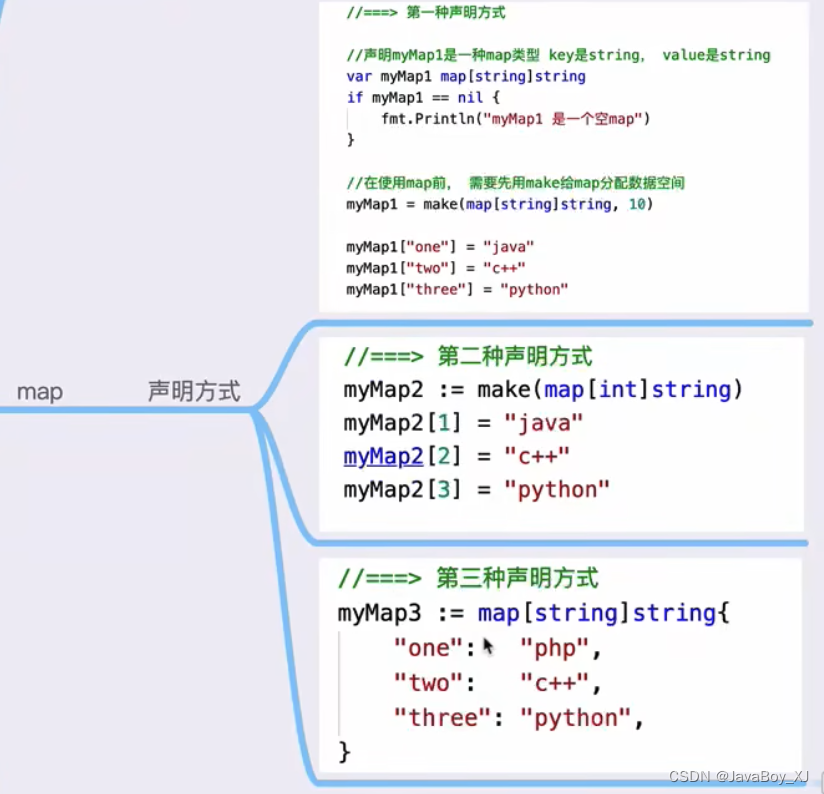
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
import torch
class Lh(nn.Module):
def __init__(self):
super(Lh, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
lh = Lh()
input = torch.ones((64,3,32,32))
print(input.shape)
output = lh(input)
print(output.shape)
可以使用tensorboard绘制神经网络流程图
writer = SummaryWriter('logs')
writer.add_graph(lh, input)
writer.close()六、损失函数
损失函数用于衡量模型的预测输出与真实标签之间的差异,并且在训练过程中用于优化模型的参数。
常用的损失函数及其简单使用方法:
1. 均方误差损失(Mean Squared Error, MSE):
均方误差损失函数用于回归问题,计算预测值与真实值之间的平均平方差。它可以通过torch.nn.MSELoss()来创建。
import torch
import torch.nn as nn
loss_fn = nn.MSELoss()
predictions = torch.tensor([0.5, 0.8, 1.2])
targets = torch.tensor([1.0, 1.0, 1.0])
loss = loss_fn(predictions, targets)
print(loss)
2. 交叉熵损失(Cross Entropy Loss):
交叉熵损失函数常用于分类问题,特别是多分类问题。它计算预测概率分布与真实标签之间的交叉熵。在PyTorch中,可以使用torch.nn.CrossEntropyLoss()来创建交叉熵损失函数。
import torch
import torch.nn as nn
loss_fn = nn.CrossEntropyLoss()
predictions = torch.tensor([[0.2, 0.3, 0.5], [0.8, 0.1, 0.1]])
targets = torch.tensor([2, 0]) # 真实标签
loss = loss_fn(predictions, targets)
print(loss)
3. 二分类交叉熵损失(Binary Cross Entropy Loss):
二分类交叉熵损失函数适用于二分类问题,计算预测概率与真实标签之间的交叉熵。在PyTorch中,可以使用torch.nn.BCELoss()来创建二分类交叉熵损失函数。
import torch
import torch.nn as nn
loss_fn = nn.BCELoss()
predictions = torch.tensor([0.2, 0.8])
targets = torch.tensor([0.0, 1.0]) # 真实标签
loss = loss_fn(predictions, targets)
print(loss)
将损失函数运用到前面的神经网络模型中:
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10('./cifar10', False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Lh(nn.Module):
def __init__(self):
super(Lh, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
lh=Lh()
for data in dataloader:
imgs, targets = data
outputs = lh(imgs)
result_loss = loss(outputs, targets)
result_loss.backward()
print(result_loss)
七、优化器
优化器用于更新模型的参数以最小化损失函数。
常用的优化器及其简单使用方法:
1. 随机梯度下降(Stochastic Gradient Descent, SGD):
随机梯度下降是最基本的优化算法之一,它通过计算损失函数关于参数的梯度来更新参数。在PyTorch中,可以使用torch.optim.SGD来创建SGD优化器。
import torch
import torch.optim as optim
model = MyModel() # 自定义模型
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 在训练循环中使用优化器
optimizer.zero_grad() # 清零梯度
loss = compute_loss() # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
2. Adam优化器:
Adam是一种自适应学习率优化算法,它结合了动量(momentum)和自适应学习率调整。在PyTorch中,可以使用torch.optim.Adam来创建Adam优化器。
import torch
import torch.optim as optim
model = MyModel() # 自定义模型
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 在训练循环中使用优化器
optimizer.zero_grad() # 清零梯度
loss = compute_loss() # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
3. 其他优化器:
PyTorch还提供了其他优化器,如Adagrad、RMSprop等。这些优化器都可以在torch.optim模块中找到,并使用类似的方式进行使用。
结合前面的神经网络模型代码示例:
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
import torch
dataset = torchvision.datasets.CIFAR10('./cifar10', False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Lh(nn.Module):
def __init__(self):
super(Lh, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
lh=Lh()
optis = torch.optim.SGD(lh.parameters(), lr=0.1)
for epoch in range(10):
running_loss = 0
for data in dataloader:
imgs, targets = data
outputs = lh(imgs)
result_loss = loss(outputs, targets)
optis.zero_grad()
result_loss.backward() # 设置对应的梯度
optis.step()
running_loss += result_loss
print(running_loss)