目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
用到的知识点:
1、requests
2、pytest
3、Excel表格操作
4、发邮件
5、日志功能
6、项目开发规范的目录应用
7、allure
①title知识点
②description知识点
企业项目框架需求
1、从Excel中读取记录行(每一行就是一个API(url,请求类型,名称,描述,参数,预期值))
2、使用参数化对每一次的请求,要使用requests发请求,获取请求结果,从结果中提取字段,跟预期值做断言。
3、使用allure生成测试报告
①为每一个请求用例添加title和description
4、将测试报告发邮件
将allure报告文件夹打包成zip、发送zip文件
5、关键点添加上log日志
①请求的时候
②断言的时候
③可选打包的时候
④读Excel的时候
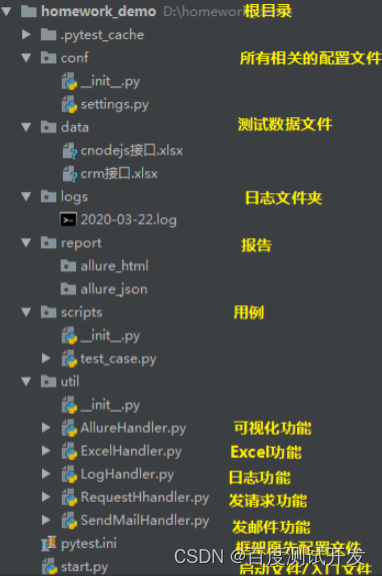
6、为了解耦合,需要遵循软件开发规范
①数据文件夹
②配置文件夹
③脚本文件夹
自动化框架分析
首先考虑把pytest脚本跑起来,在这个基础上,加功能
1、加log日志
2、Excel表格操作,注意,需要把预期值的json串,loads成字典
3、requests操作,从Excel表格中,获取到每一行数据,发请求
①请求的预期值有可能是多个,我们进行循环判断
②请求的响应结果类型可能是多种,我们从response.headers[“Content-Type”]去判断,到底是什么类型的响应,然后进行反射
4、执行终端命令:
①subprocess
②os.popen
5、压缩文件、发送邮件、删除report文件夹
自动化框架完成
1、配置ini文件
pytest.ini文件中不要有中文,哪怕是注释的部分有中文也不行
[pytest]
addopts = -s -v -p no:warnings --alluredir ./report/allure_json
testpaths = ./scripts
python_files = test_*.py
python_classes = Test*
python_functions = test_*
2、建立目录结构
3、建立入口文件
import pytest
if __name__ == '__main__':
pytest.main()
4、配置文件settings(日志相关、Excel相关、Allure相关、邮件相关)
import os
import sys
import datetime
# 根目录:
BASE_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
# ---------------- 日志相关 --------------------
# 日志级别:
LOG_LEVEL = 'debug'
LOG_STREAM_LEVEL = 'debug' # 屏幕输出流
LOG_FILE_LEVEL = 'info' # 文件输出流
# 日志文件夹命名:
LOG_FILE_NAME = os.path.join(BASE_PATH, 'logs', datetime.datetime.now().strftime('%Y-%m-%d') + '.log')
# ---------------- Excel相关 --------------------
# Excel数据文件夹命名:
DATA_PATH = os.path.join(BASE_PATH, 'data')
# 切换data文件时,只需要更改文件名即可:
EXCEL_FILE_NAME = 'cnodejs接口.xlsx'
EXCEL_FILE_PATH = os.path.join(DATA_PATH, EXCEL_FILE_NAME)
if __name__ == '__main__':
# 添加顶级目录:
sys.path.insert(0, BASE_PATH)
print(sys.path)
# ---------------- Allure相关 ----------------------
# 报告路径:
REPORT_PATH = os.path.join(BASE_PATH, 'report')
# Allure的json文件夹命名:
ALLURE_JSON_DIR_NAME = 'allure_json'
# Allure的json文件路径:
ALLURE_JSON_DIR_PATH = os.path.join(REPORT_PATH, ALLURE_JSON_DIR_NAME)
# allure的html文件夹命名:
ALLURE_REPORT_DIR_NAME = os.path.join(REPORT_PATH, 'allure_report')
# allure的html报告路径
ALLURE_REPORT_DIR_PATH = os.path.join(REPORT_PATH, ALLURE_REPORT_DIR_NAME)
# 压缩包路径:
ZIP_FILE_PATH = os.path.join(REPORT_PATH, 'report.zip')
# 生成报告命令:
ALLURE_COMMAND = "allure generate {} -o {}".format(ALLURE_JSON_DIR_PATH, ALLURE_REPORT_DIR_PATH)
# ------------------- 邮件相关 -----------------
# 第三方 SMTP 服务:
MAIL_HOST = "smtp.qq.com"
MAIL_USERNAME = "xxxx@qq.com"
MAIL_TOKEN = "mpaocydzpzfjidge"
# 收件人,收件人可以有多个,以列表形式存放:
RECEIVERS = ['xxxx1@qq.com', 'xxxx2@qq.com']
# 邮件主题、收件人、发件人:
MAIL_SUBJECT = 'Python通过第三方发邮件'
# 可修改:设置收件人和发件人
SENDER = 'xxxx1@qq.com' # 发件人
# 邮件正文
MAIN_CONTENT = 'hi man:\r这是今日的{excel_file_name}的测试报告\r详情下载附件\r查看方法,终端执行 allure open report\r测试人:{execute_tests_name},联系电话:{execute_tests_phone} \r{execute_tests_date}'.format(
excel_file_name=EXCEL_FILE_NAME,
execute_tests_name="张达",
execute_tests_phone=1733813xxxx,
execute_tests_date=datetime.datetime.date(datetime.datetime.now())
)
5、测试用例test_case(输出日志、动态加参、发邮件)
import pytest
import allure
# 引入配置文件:
from conf import settings
# 引入日志功能:
from util.LogHandler import logger
# 引用Excel表操作功能:
from util.ExcelHandler import ExcelHandler
# 引入发请求功能:
from util.RequestHhandler import RequestHandler
# 引入报告功能:
from util.AllureHandler import AllureHandler
# 引入发邮件功能:
from util.SendMailHandler import SendMailHandler
class TestCase(object):
@pytest.mark.parametrize("item", ExcelHandler().get_excel_data(settings.EXCEL_FILE_PATH))
def test_case(self, item):
# 调用日志功能的info级别:
# logger().info(item)
# 获取每一行数并且发请求:
response = RequestHandler().get_response(item)
# 行为驱动标记:
allure.dynamic.feature(item['case_title'])
allure.dynamic.story(item['case_description'])
# 动态加参:
allure.dynamic.title(item['case_title'])
allure.dynamic.description(
"<b style='color:red;'>描述:</b>{}<br />"
"<b style='color:red;'>请求的url:</b>{}<br />"
"<b style='color:red;'>预期值:</b>{}<br />"
"<b style='color:red;'>实际执行结果:</b>{}<br />".format(
item['case_description'],
item['case_url'],
response[0],
response[1]
))
assert response[0] == response[1]
def teardown_class(self):
# 参数化用例都执行完毕才执行的操作:
logger().info('teardown_class')
# 执行allure命令,生成allure报告
AllureHandler().execute_command()
# 将测试报告打包并发送邮件:
SendMailHandler().send_mail_msg()
6、Allure功能(执行终端命令)
# 执行终端命令、subprocess要代替一些老旧的模块命令:
from subprocess import Popen, call
from conf import settings
from util.LogHandler import logger
class AllureHandler(object):
# 读取json文件,生成allure报告:
def execute_command(self):
# Python执行终端命令:shell=True:将['allure', 'generate', '-o', 'xxxx']替换为'allure generate -o'
try:
call(settings.ALLURE_COMMAND, shell=True)
logger().info('执行allure命令成功')
except Exception as e:
logger().error("执行allure命令失败,详情参考: {}".format(e))
7、日志功能(设置日志级别、格式化输出日志)
import logging
from conf import settings
class LoggerHandler:
# 日志操作
_logger_level = {
'debug': logging.DEBUG,
'info': logging.INFO,
'warning': logging.WARNING,
'error': logging.ERROR,
'critical': logging.CRITICAL
}
def __init__(self, log_name, file_name, logger_level, stream_level='info', file_level='warning'):
self.log_name = log_name
self.file_name = file_name
self.logger_level = self._logger_level.get(logger_level, 'debug')
self.stream_level = self._logger_level.get(stream_level, 'info')
self.file_level = self._logger_level.get(file_level, 'warning')
# 创建日志对象
self.logger = logging.getLogger(self.log_name)
# 设置日志级别
self.logger.setLevel(self.logger_level)
if not self.logger.handlers:
# 设置日志输出流
f_stream = logging.StreamHandler()
f_file = logging.FileHandler(self.file_name)
# 设置输出流级别
f_stream.setLevel(self.stream_level)
f_file.setLevel(self.file_level)
# 设置日志输出格式
formatter = logging.Formatter(
"%(asctime)s %(name)s %(levelname)s %(message)s"
)
f_stream.setFormatter(formatter)
f_file.setFormatter(formatter)
self.logger.addHandler(f_stream)
self.logger.addHandler(f_file)
@property
def get_logger(self):
return self.logger
def logger(log_name='接口测试'):
return LoggerHandler(
log_name=log_name,
logger_level=settings.LOG_LEVEL,
file_name=settings.LOG_FILE_NAME,
stream_level=settings.LOG_STREAM_LEVEL,
file_level=settings.LOG_FILE_LEVEL
).get_logger
if __name__ == '__main__':
logger().debug('aaaa')
logger().info('aaaa')
logger().warning('aaaa')
8、Excel功能(for循环添加/列表解析)
import xlrd
from conf import settings
class ExcelHandler(object):
# Excel功能:
def __init__(self, excel_file_path=None):
self.excel_file_path = excel_file_path
def get_excel_data(self, excel_file_path):
# 读取Excel表格:
book = xlrd.open_workbook(excel_file_path)
# 根据sheet名称获取sheet对象:
sheet = book.sheet_by_name('自动化测试')
# 获取标题:
title = sheet.row_values(0)
# l = []
# 方式一循环添加返回列表:
# for row in range(1, sheet.nrows):
# l.append(dict(zip(title, sheet.row_values(row))))
# return l
# 方式二列表解析式返回:
return [dict(zip(title, sheet.row_values(row))) for row in range(1, sheet.nrows)]
def write_excel(self):
# 写入Excel表格:
pass
if __name__ == '__main__':
ExcelHandler().get_excel_data(settings.EXCEL_FILE_PATH)
9、发请求功能(bs解析、定义私有方法、分不同的json返回类型处理)
import json
import requests
# 导入解析功能:
from bs4 import BeautifulSoup
# 引入日志功能:
from util.LogHandler import logger
class RequestHandler(object):
# 发请求功能:
def get_response(self, item):
# 获得请求结果:
# logger().info(item)
return self._send_msg(item)
def _send_msg(self, item):
# 发请求的操作(私有的):
response = requests.request(
# 请求类型:
method=item['case_method'],
# 请求url:
url=item['case_url'],
# 处理请求中携带的data数据(私有的)
data=self._check_data_msg(item),
# 处理请求中的请求头(私有的)
headers=self._check_headers_msg(item)
)
# 分不同的json返回类型处理:
Content_Type = response.headers['Content-Type'].split('/')[0]
# 反射:
if hasattr(self, '_check_{}_response'.format(Content_Type)):
obj = getattr(self, '_check_{}_response'.format(Content_Type))
res = obj(response, item)
else:
pass
return res
def _check_application_response(self, response, item):
# 处理json类型的响应:
response = response.json()
expect = json.loads(item['case_expect'])
for key, value in expect.items():
# 意味着预期值的字段跟实际请求结果的字段不一致:断言失败
if value != response.get(key, None):
logger().info('请求:{} 断言失败,预期值是:[{}] 实际执行结果:[{}], 相关参数:{}'.format(
item['case_url'],
value,
response.get(key, None),
item
))
return (value, response.get(key, None))
else:
# 断言成功
return (value, response.get(key, None))
def _check_text_response(self, response, item):
# 处理文本类型的响应:
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
return (title, item['case_expect'])
def _check_image_response(self, response, item):
# 处理jpeg图片类型的响应:
pass
def _check_data_msg(self, item):
# 处理请求中携带的data数据(私有的):
if item.get('case_data', None):
# 如果请求中有data参数:
pass
else:
return {}
def _check_headers_msg(self, item):
# 处理请求中的请求头(私有的)、预留接口负责处理,请求头相关的逻辑
# 自定义一些固定的请求头,也可以将Excel表格中的特殊请求头更新到这个字典中
headers = {}
if item.get('case_headers', None):
headers.update(json.loads(item['case_headers']))
return headers
if __name__ == '__main__':
pass
10、发邮件功能(压缩文件、发邮件配置、发邮件、自动删除临时文件)
import os
# 导入删除文件夹/文件模块:
import shutil
# 导入压缩模块:
import zipfile
# 导入日期模块:
import datetime
# 导入发邮件模块:
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
# 导入配置文件:
from conf import settings
from util.LogHandler import logger
class SendMailHandler(object):
# 将测试报告压缩并发送邮件
def _check_zip_file(self):
# 将测试报告压缩:
base_dir = settings.ALLURE_REPORT_DIR_PATH
# 压缩包路径:
zip_file_path = settings.ZIP_FILE_PATH
f = zipfile.ZipFile(zip_file_path, 'w', zipfile.ZIP_DEFLATED)
for dir_path, dir_name, file_names in os.walk(base_dir):
# 要是不replace,就从根目录开始复制:
file_path = dir_path.replace(base_dir, '')
# 实现当前文件夹以及包含的所有文件:
file_path = file_path and file_path + os.sep or ''
for file_name in file_names:
f.write(os.path.join(dir_path, file_name), file_path + file_name)
f.close()
def send_mail_msg(self):
# 调用压缩功能:
self._check_zip_file()
# 调用发邮件操作:
self._send_mail()
# 调用删除临时文件:
self._del_temp_file()
def _send_mail(self):
# 发邮件操作:
# 第三方 SMTP 服务:
mail_host = settings.MAIL_HOST
# 下面两个,可修改:
mail_user = settings.MAIL_USERNAME
mail_pass = settings.MAIL_TOKEN
# 可修改:设置收件人和发件人:
sender = settings.SENDER
# 收件人,收件人可以有多个,以列表形式存放:
receivers = settings.RECEIVERS
# 创建一个带附件的实例对象:
message = MIMEMultipart()
# 可修改邮件主题、收件人、发件人:
subject = settings.MAIL_SUBJECT
# 下面三行不用修改:
message['Subject'] = Header(subject, 'utf-8')
# 发件人:
message['From'] = Header("{}".format(sender), 'utf-8')
# 收件人:
message['To'] = Header("{}".format(';'.join(receivers)), 'utf-8')
# 邮件正文内容 html 形式邮件:相当于是一个报告预览:
# 可修改:send_content
content = settings.MAIN_CONTENT
# 第一个参数为邮件正文内容:
html = MIMEText(_text=content, _subtype='plain', _charset='utf-8')
# 构造附件:
send_content = open(settings.ZIP_FILE_PATH, 'rb').read()
# 只允许修改第一个参数,后面两个保持默认:
att = MIMEText(_text=send_content, _subtype='base64', _charset='utf-8')
# 不要改:
att["Content-Type"] = 'application/octet-stream'
# 页面中,附件位置展示的附件名称:
file_name = 'report.zip'
# 下面3行不要改、filename 为邮件附件中显示什么名字:
att["Content-Disposition"] = 'attachment; filename="{}"'.format(file_name)
message.attach(html)
message.attach(att)
try:
smtp_obj = smtplib.SMTP()
smtp_obj.connect(mail_host, 25)
smtp_obj.login(mail_user, mail_pass)
smtp_obj.sendmail(sender, receivers, message.as_string())
smtp_obj.quit()
logger().info("邮件发送成功")
except smtplib.SMTPException as e:
logger().error("Error: 邮件发送失败,详情:{}".format(e))
def _del_temp_file(self):
# 清空report目录:
logger().info('删除临时目录')
shutil.rmtree(settings.REPORT_PATH)
logger().info('删除临时目录成功')
if __name__ == '__main__':
# 在当前py文件测试:
SendMailHandler().send_mail_msg()
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
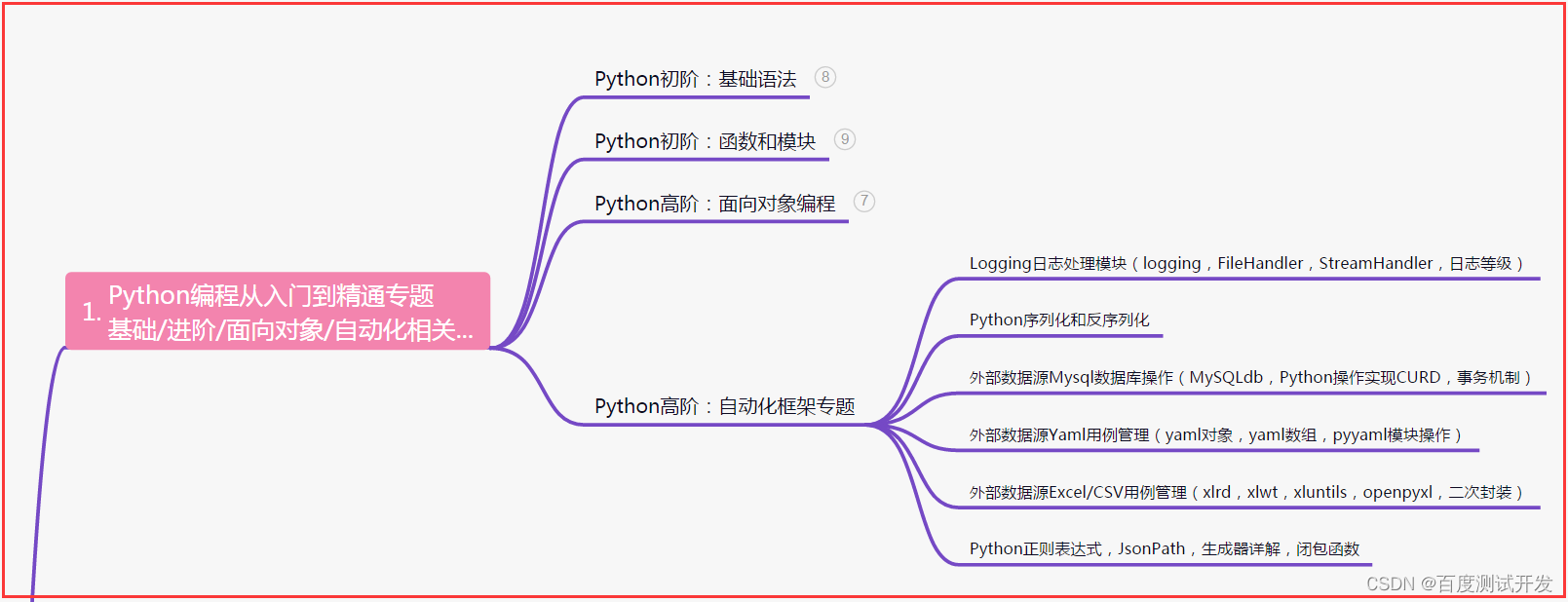
一、Python编程入门到精通
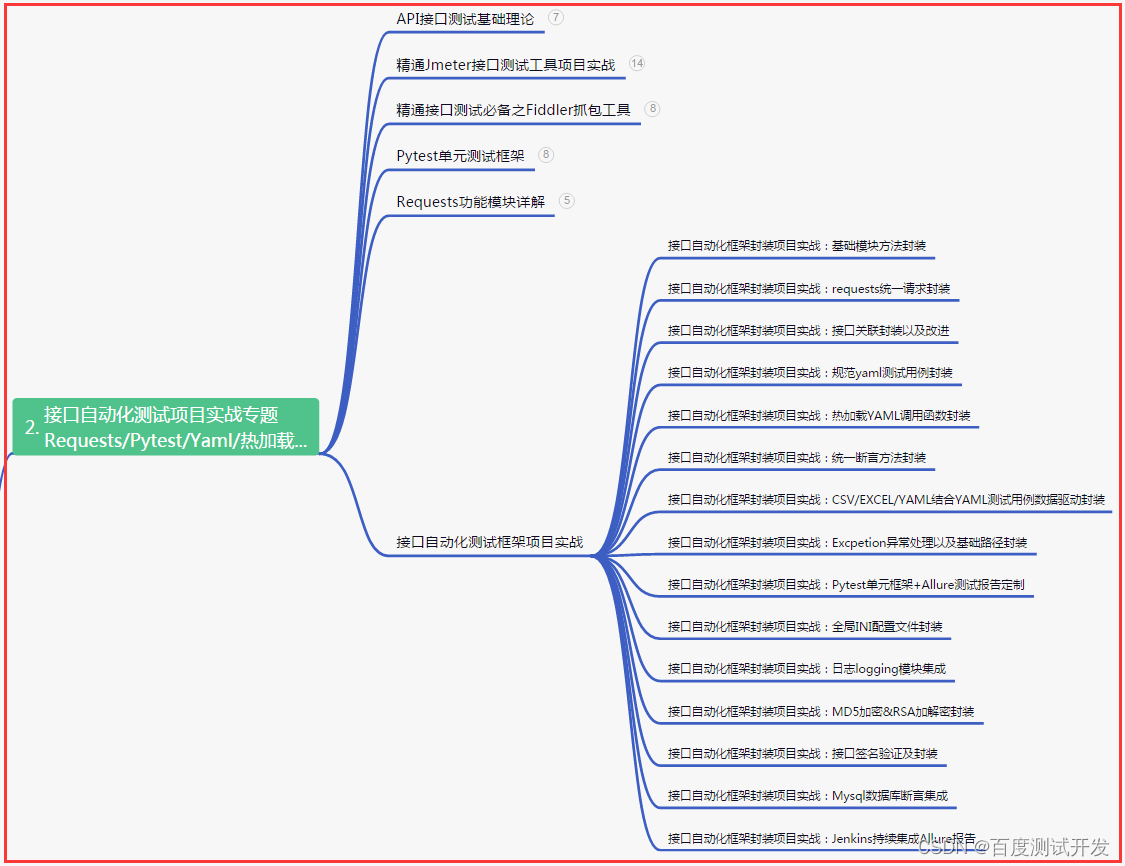
二、接口自动化项目实战
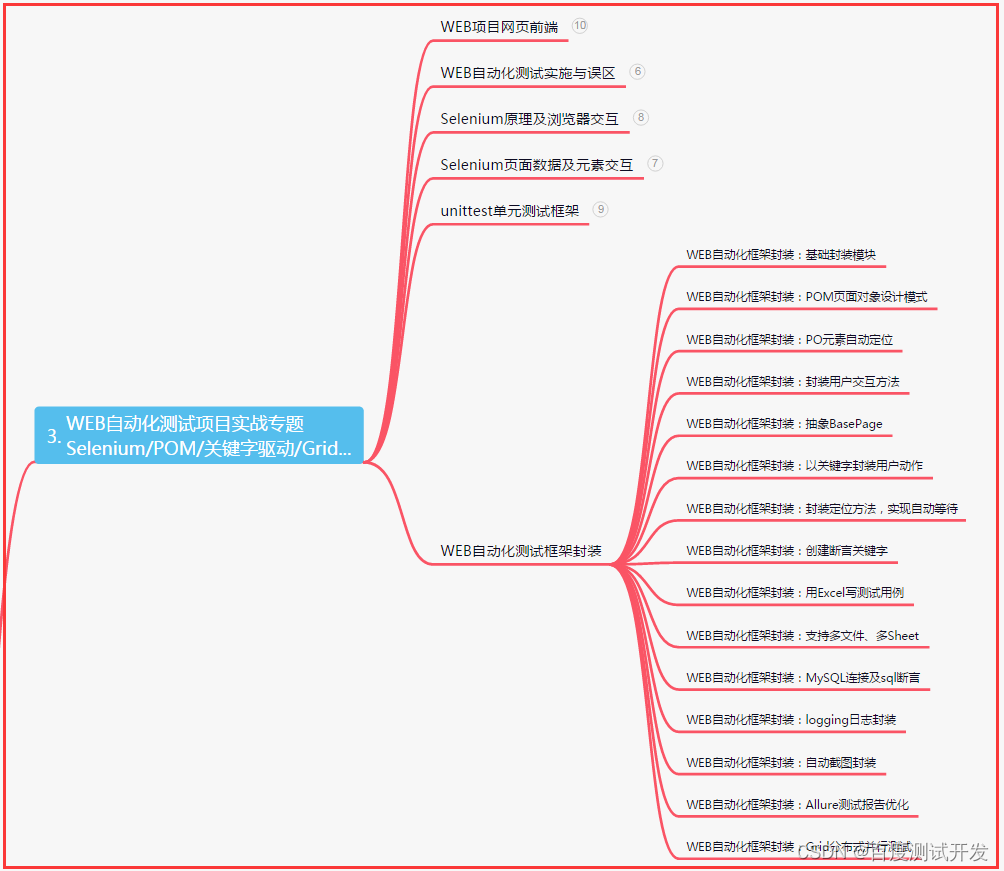
三、Web自动化项目实战
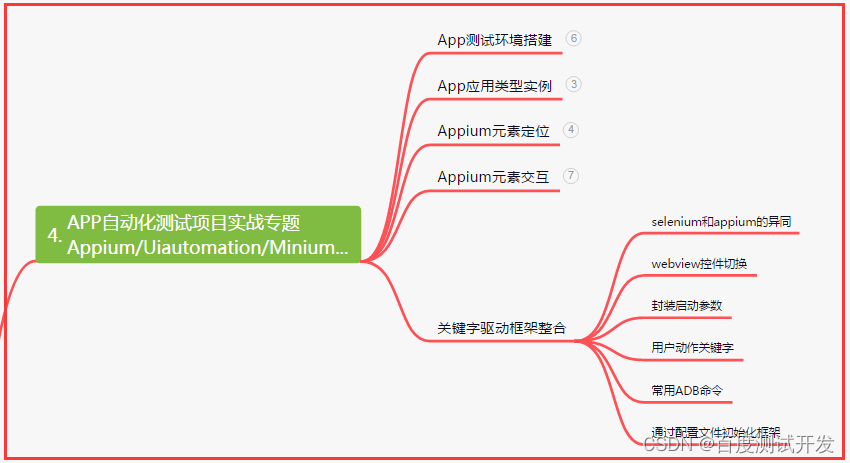
四、App自动化项目实战
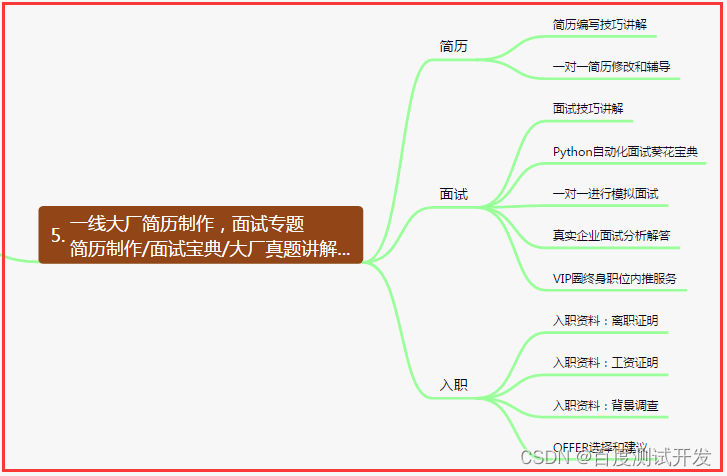
五、一线大厂简历
六、测试开发DevOps体系

七、常用自动化测试工具

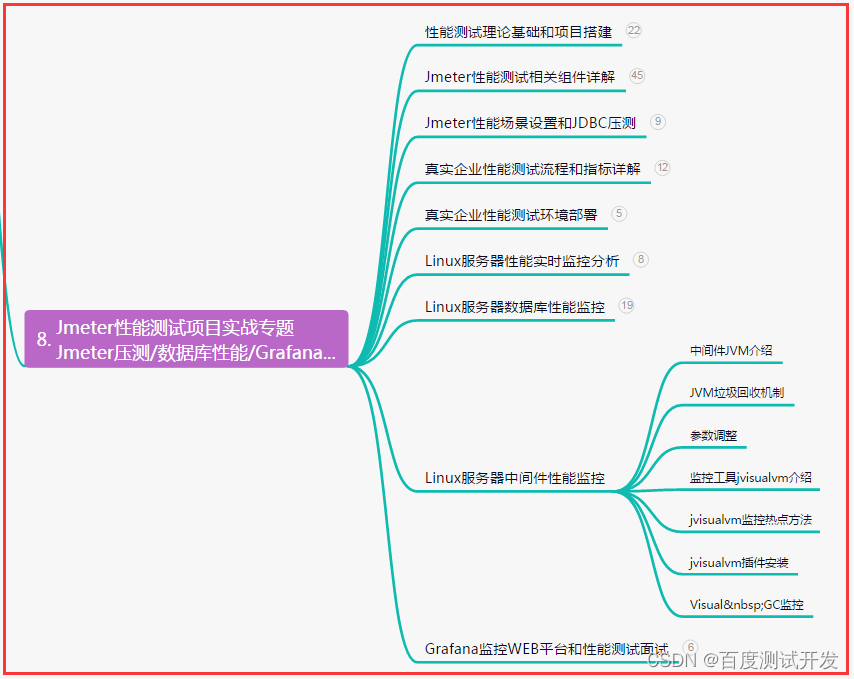
八、JMeter性能测试
九、总结(尾部小惊喜)
奋斗是燃烧的火焰,坚持是通向成功的道路。不论前路多曲折,都要心怀勇气与激情,为梦想奋斗不息。相信自己的力量,超越极限,踏上辉煌的征程!
执着追逐,拼搏奋斗,勇敢向未知挑战。困难是跳板,挫折是试金石,每一次坚持都离成功更近一步。激情燃烧心灵,信念驱使前行,用汗水书写属于自己的绚丽篇章!
不畏艰辛,追求卓越;拼尽全力,无惧失败。奋斗的道路上,付出与收获共舞,成功与坚持相伴。相信自己的能力,勇往直前,创造属于自己的辉煌人生!