requests库
什么是Requests ?Requests 是⽤Python语⾔编写,基于urllib,采⽤Apache2 Licensed开源协议的 HTTP 库。它⽐ urllib 更加⽅便,可以节约我们⼤量的⼯作,完全满⾜HTTP测试需求。
安装:cmd命令行执行pip install requests
HTTP 请求方法
HTTP 协议 (Hyper Text Transfer Protocol),一个基于TCP/IP通信协议来传递数据,包括html文件、图像、结果等,即是一个客户端和服务器端请求和应答的标准。根据HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP 0.9:只有基本的文本GET请求,没有固定的版本号,不支持请求头。
HTTP 1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法:GET,POST和HEAD方法。
HTTP 1.1:在1.0的基础上进行更新,新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE和CONNECT方法。
HTTP 2.0(未普及):请求/响应首部的定义基本没有改变,只是所有首部键必须全部小写,而且请求行要独立
为:method、:scheme、:host、:path这些键值对。
HTTP请求常用的Get和Post两种方法:
GET是从服务器上获取数据,POST是向服务器传送数据
GET请求参数都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,也就是说GET请求的参数是URL的一部分。
POST请求参数是在请求体当中,消息长度没有限制且以隐式的方式进行传送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码
发送GET请求
关键代码:requests.get(url)
参数说明:若需要传请求参数,可直接在 url 后面添加,也可以在调用get()方法时通过关键字params传入,需要注意的是params需要传入dict(字典)类型。
下面以请求百度为例,发送get请求:
import requests
# 通过url直接加上请求参数,与通过params传参效果是一样的
response = requests.get(url='http://www.baidu.com/s?wd=requests模块')
# 通过params传参
response2 = requests.get(url='http://www.baidu.com/s', params={"wd": "requests模块"})
print(response.status_code) # 打印状态码
# print(response.text) # 获取响应内容
运行结果:
C:\software\python\python.exe D:/learn/test.py
200
Process finished with exit code 0
发送POST请求
关键代码:requests.post(url, data)
参数说明:可传dict类型也可传json类型,dict类型使用关键字data传参,json类型则为使用关键字json传参。若无需传参可不传。
register_url = "http://127.0.0.1:666/index/register"
# 添加请求头,需要就传
header = {
"Content-Type": "application/json"
}
# json类型的参数
json = {
"mobile_phone": "15612345678",
"pwd": "Test1234",
"type": 0
}
# 发送post请求
response = requests.post(url=register_url, json=json, headers=header)
print(response.json())
# 打印结果:{'code': 200, 'msg': 'success', 'password': '321', 'username': '123'}
上面举例为json类型的传参,json和dict类型的数据结构表面上看有点相似,那怎么判断什么时候用json什么时候用dict呢?只要查看请求头,需要哪种就传哪种,表单类型的参数,即"Content-Type: application/x-www-form-urlencoded"就使用关键字data去传dcit类型的参数,像上面举例的"Content-Type": "application/json"json类型的参数一定要使用关键字json去传递。
获取响应数据
常见的属性:
response.status_code:获取响应状态码
response.cookies:获取cookies
response.headers:获取头部信息
response.url:获取url
response.text:自动识别文本中的编码格式进行解码,但有时候不准确,会出现乱码
response.content.decode(‘utf-8’):response.content,获取字节流的数据,进行decode解码,默认是utf8
response.json():json方法可以将json字符串转换成对应的python类型的数据,接口返回的数据99%都是json类型的
import requests
response = requests.get(url='http://www.baidu.com/s?wd=requests模块')
# response = requests.get(url='http://www.baidu.com/s', params={"wd": "requests模块"})
print("这是status_code:{}\n".format(response.status_code))
print("这是cookies:.{}\n".format(response.cookies))
print("这是headers:.{}\n".format(response.headers))
print("这是url:.{}\n".format(response.url))
# print("这是响应页面文本信息:.{}\n".format(response.text)) # 因为返回数据太长,不作运行
# print("这是获取的字节流数据decode解码:.{}\n".format(response.content.decode()))
运行结果:
C:\software\python\python.exe D:/learn/test.py
这是status_code:200
这是cookies:.<RequestsCookieJar[<Cookie BAIDUID=6EC84DD4DE623D1500B3D0E771D1D3FA:FG=1 for .baidu.com/>, <Cookie BIDUPSID=6EC84DD4DE623D15C087081CA8B7A6D9 for .baidu.com/>, <Cookie H_PS_PSSID=32292_1441_32355_32328_31253_32348_32046_32394_32429_32115_32437 for .baidu.com/>, <Cookie PSINO=6 for .baidu.com/>, <Cookie PSTM=1596554477 for .baidu.com/>, <Cookie delPer=0 for .baidu.com/>, <Cookie BDSVRTM=11 for www.baidu.com/>, <Cookie BD_CK_SAM=1 for www.baidu.com/>]>
这是headers:.{'Bdpagetype': '3', 'Bdqid': '0xf2cd9ccf00070e08', 'Cache-Control': 'private', 'Ckpacknum': '2', 'Ckrndstr': 'f00070e08', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html;charset=utf-8', 'Date': 'Tue, 04 Aug 2020 15:21:17 GMT', 'P3p': 'CP=" OTI DSP COR IVA OUR IND COM ", CP=" OTI DSP COR IVA OUR IND COM "', 'Server': 'BWS/1.1', 'Set-Cookie': 'BAIDUID=6EC84DD4DE623D15C087081CA8B7A6D9:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BIDUPSID=6EC84DD4DE623D15C087081CA8B7A6D9; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, PSTM=1596554477; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BAIDUID=6EC84DD4DE623D1500B3D0E771D1D3FA:FG=1; max-age=31536000; expires=Wed, 04-Aug-21 15:21:17 GMT; domain=.baidu.com; path=/; version=1; comment=bd, delPer=0; path=/; domain=.baidu.com, BD_CK_SAM=1;path=/, PSINO=6; domain=.baidu.com; path=/, BDSVRTM=11; path=/, H_PS_PSSID=32292_1441_32355_32328_31253_32348_32046_32394_32429_32115_32437; path=/; domain=.baidu.com', 'Traceid': '1596554477018818305017495812540276870664', 'Vary': 'Accept-Encoding', 'X-Ua-Compatible': 'IE=Edge,chrome=1', 'Transfer-Encoding': 'chunked'}
这是url:.http://www.baidu.com/s?wd=requests%E6%A8%A1%E5%9D%97
Process finished with exit code 0
高级操作
在上面我们基本了解了requests库的基本用法,如GET、POST请求以及response的属性,接下来我们再看下requests库的一些高级用法,如下载/上传文件、Cookies设置、代理设置等
文件下载
与发送请求区别无二,只是保存时需要处理一下,如下载图片,把获取图片的二进制数据然后用二进制写入文件即可。
import requests
response = requests.get('https://github.com/favicon.ico')
# 获取二进制数据,然后写入文件
with open('favicon.ico','wb')as f:
f.write(response.content)
f.close
文件上传
关键代码:requests.post(utl, files=files)
import requests
file = {'file':open('favicon.ico','rb')} # 将之前抓取的github图标以二进制格式读取
response = requests.post('http://httpbin.org/post', files = file)
print(response.text)
SSL证书验证
为什么会有SSL证书验证,SSL是什么?
SSL协议是网络层和传输层的协议。SSL(Secure Sockets Layer 安全套接层)协议,及其继任者TLS(Transport Layer Security传输层安全)协议,是为网络通信提供安全及数据完整性的一种安全协议。
HTTPS是兼容HTTP的,可以把HTTPS理解为’HTTP over TSL’,即HTTPS是HTTP协议和TSL协议的组合。HTTPS在传输数据时,同样会先建立TCP连接,建立起TCP连接后,会建立TSL连接。请求可以为HTTPS请求验证SSL证书,就像我们使用的浏览器一样,SSL验证默认是开启的,如果证书验证失败,请求会抛出一个SSLError,如下图:
碰到请求SSL验证的,我们是可以直接跳过不验证的,通过设置verify=False就可关闭错误提示,跳过SSL验证,这里只是忽略了SSL验证,并不是没有了SSL验证,它仍然会存在一个警告信息InsecureRequestWarning。
import requests
#通过一下两行代码即可把警报消除,即使verify=False,报警还是存在的
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify = False)
print(response.status_code)
保持会话
在requests中,如果直接使用get()或post()等方法是可以做到模拟网页的接口请求,但是每次发起请求结束后它就结束了,并不会保存相关的验证信息,如cookies/token;比如第一次使用post()请求登录了某个网站,第二次想获取成功登录后的用户个人信息,再一次发起post()请求时它会要求你需求先登录,明明第一次请求时已经登录了,为什么第二次还提示要先登录呢?实际上两次请求相当于使用了两个浏览器去访问,是两个完全不相关的会话,因此第二次请求是拿不到用户信息的。
requests中的session对象能够让我们跨http请求保持某些参数,即让同一个session对象发送的请求头携带某个指定的参数。当然,最常见的应用是它可以让cookie保持在后续的一串请求中。
# 创建一个session对象,使它能够自动记录上一次请求中的cookie信息
se = requests.session()
# 登录接口
login_url = "http://www.test.com/api/member/login"
login_data = {
"mobilephone": "15612345678",
"pwd": "Test1234"
}
res = se.post(url=login_url, data=login_data)
# 登录后查询用户最近的订单记录
order_record_url = "http://www.test.com/api/member/order"
record_data = {
"beginTime": "2020-08-01",
"endTime": "2020-08-15"
}
res2 = se.post(url=order_record_url, data=record_data)
print(res2.json())
requests封装
凡是需要重复使用的,我们都可以对它进行二次封装,写成我们自己的版本,还可以在封装过程中加入我们想要的内容,使用的时候直接调用即可。
python
import requests
class SendSessionRequest:
“”“使用session鉴权的接口,记录cookies/token”“”
def __init__(self):
self.session = requests.session()
def requests(self, url, method, params=None, data=None, json=None, headers=None):
method = method.lower()
if method == "post":
return self.session.post(url=url, json=json, data=data, headers=headers)
elif method == "patch":
return self.session.patch(url=url, json=json, data=data, headers=headers)
elif method == "get":
return self.session.get(url=url, params=params)
【下面是我整理的2023年最全的软件测试工程师学习知识架构体系图】
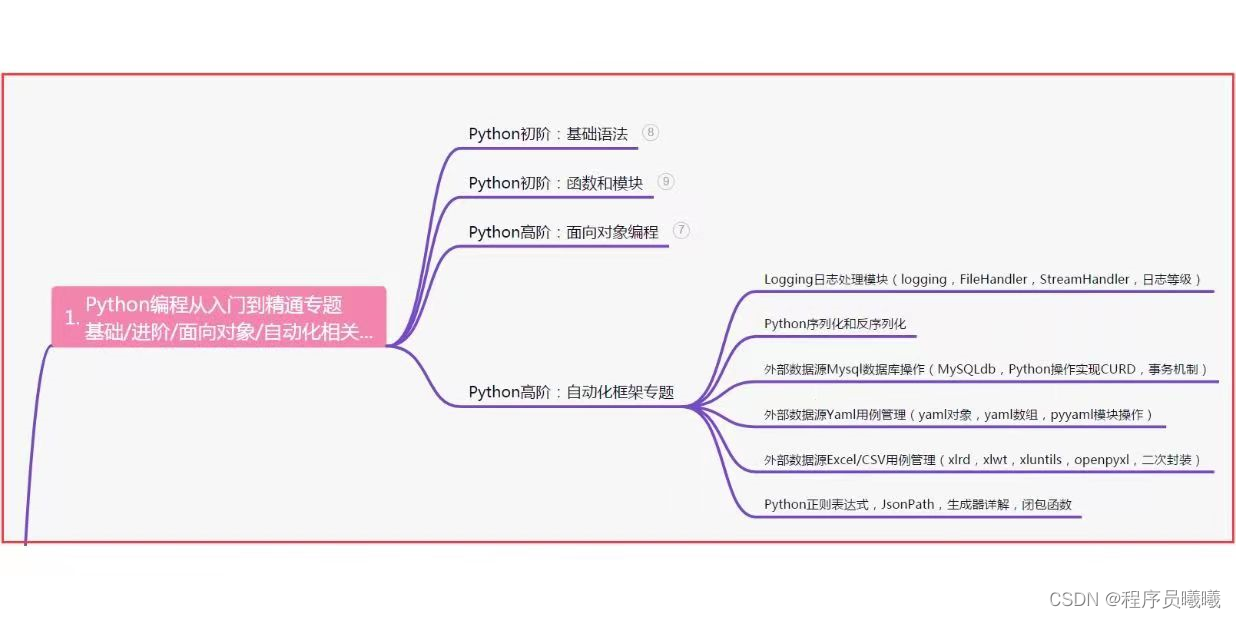
一、Python编程入门到精通
二、接口自动化项目实战

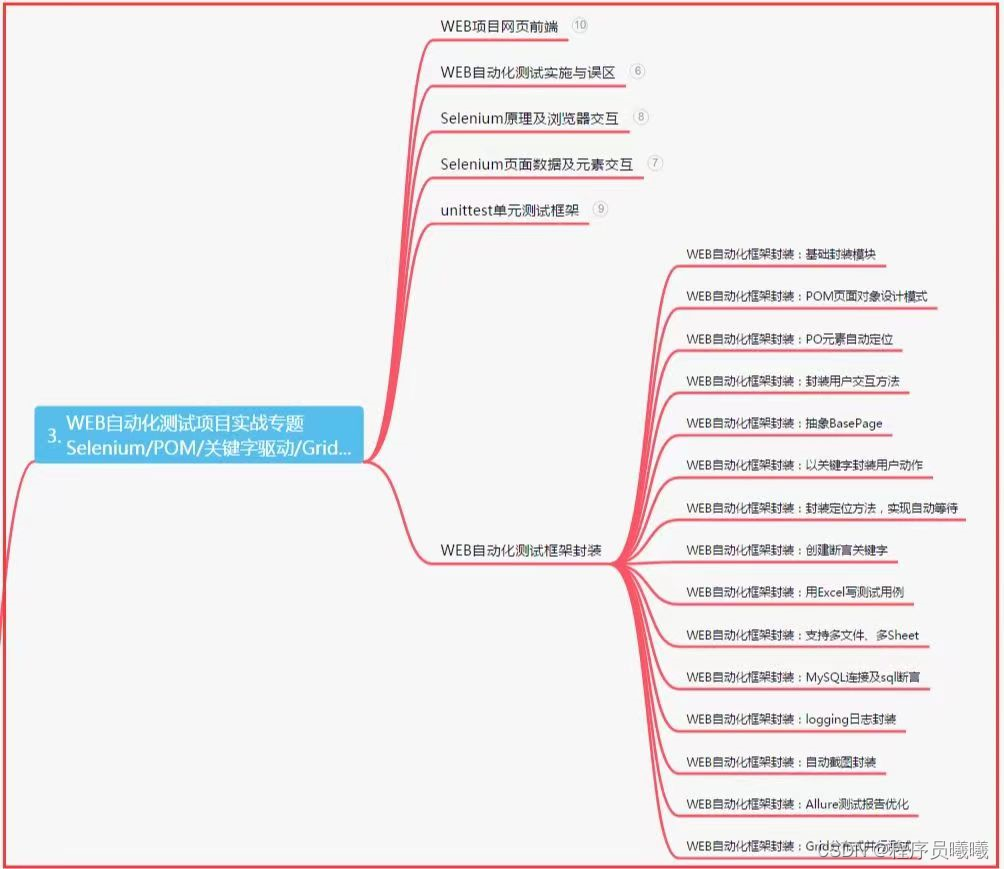
三、Web自动化项目实战
四、App自动化项目实战

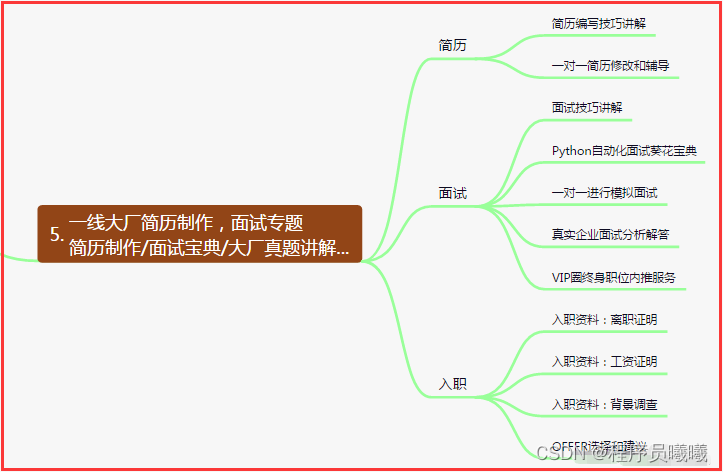
五、一线大厂简历
六、测试开发DevOps体系

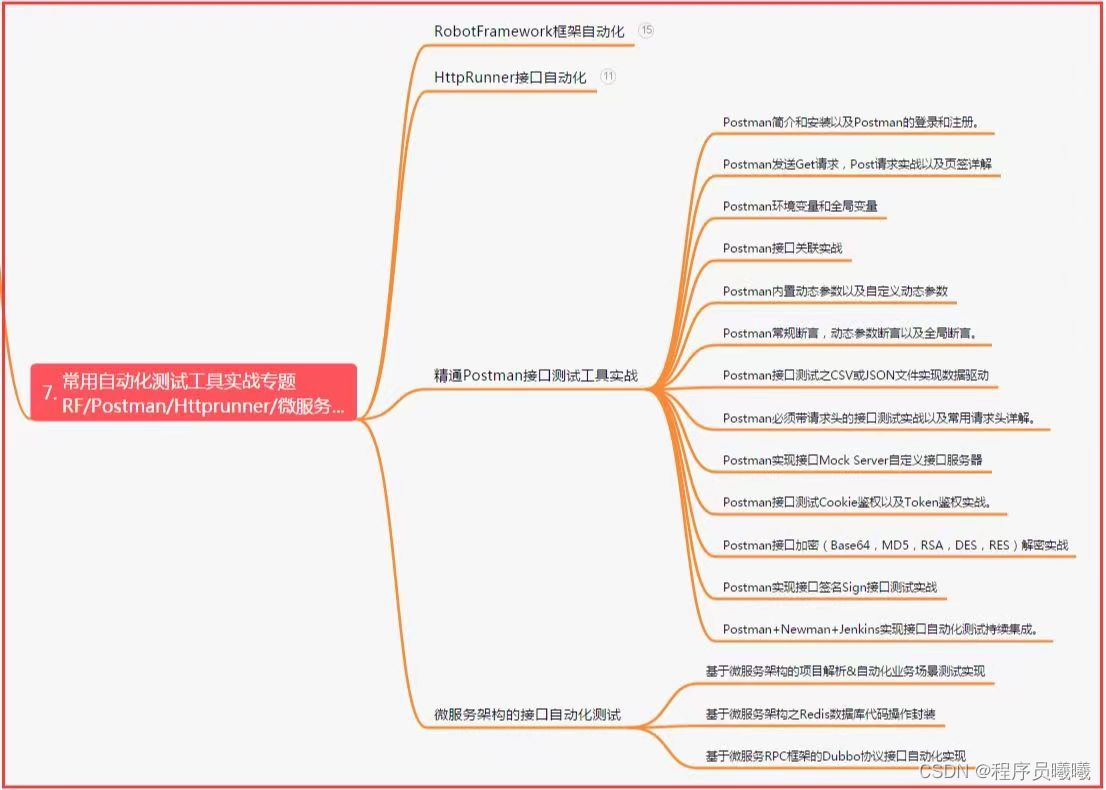
七、常用自动化测试工具
八、JMeter性能测试
九、总结(尾部小惊喜)
生命不息,奋斗不止。每一份努力都不会被辜负,只要坚持不懈,终究会有回报。珍惜时间,追求梦想。不忘初心,砥砺前行。你的未来,由你掌握!
生命短暂,时间宝贵,我们无法预知未来会发生什么,但我们可以掌握当下。珍惜每一天,努力奋斗,让自己变得更加强大和优秀。坚定信念,执着追求,成功终将属于你!
只有不断地挑战自己,才能不断地超越自己。坚持追求梦想,勇敢前行,你就会发现奋斗的过程是如此美好而值得。相信自己,你一定可以做到!