0- 前言
爬虫是一门需要实战的学问。 而对于初学者来说,要想学好反爬,js逆向则是敲门砖。今天给大家带来一个js逆向入门实例,接下来我们一步一步来感受下入门的逆向是什么样的。该案例选自猿人学练习题。猿人学第一题
1- 拿到需求
进入页面拿到需求我们先不要急着看源码, 没事多点点喝杯茶。需求为抓取页面上所有机票的平均值。
2- 参数分析
1- 打开无痕浏览器, 免得上班刷题被网管查到记录。 然后可以放心的多一点看一](https://img-blog.csdnimg.cn/b576674b03fc4d04a2a2add6242ae611.png)
前三页都挺正常的, 看起来就是普普通通的AJAX请求
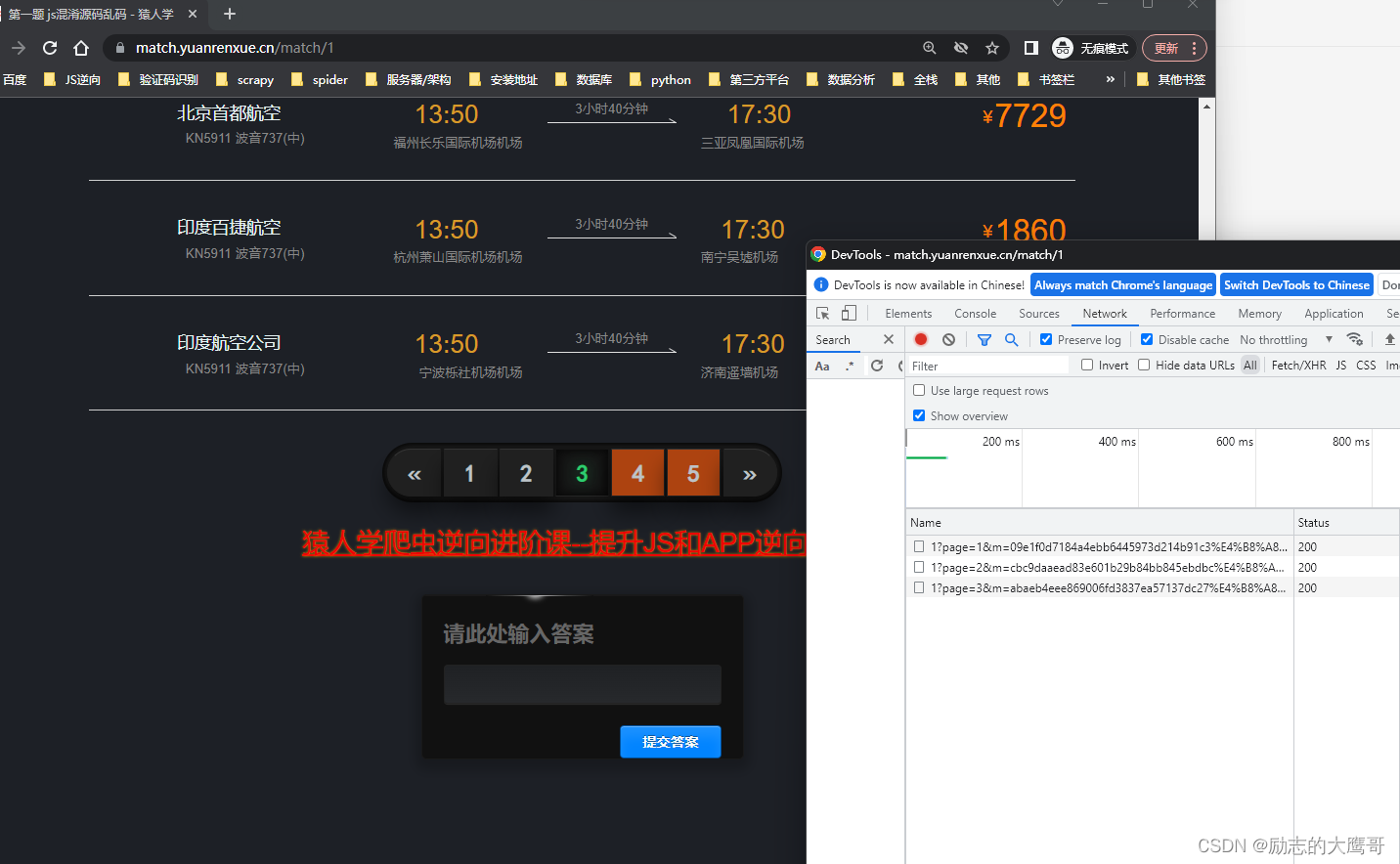
2- 第四页第五页画风突变,不让看了。一想也是, 防止你手动计算, 只能逆了js才能访问。 好吧, 我们现在来构建一下请求。
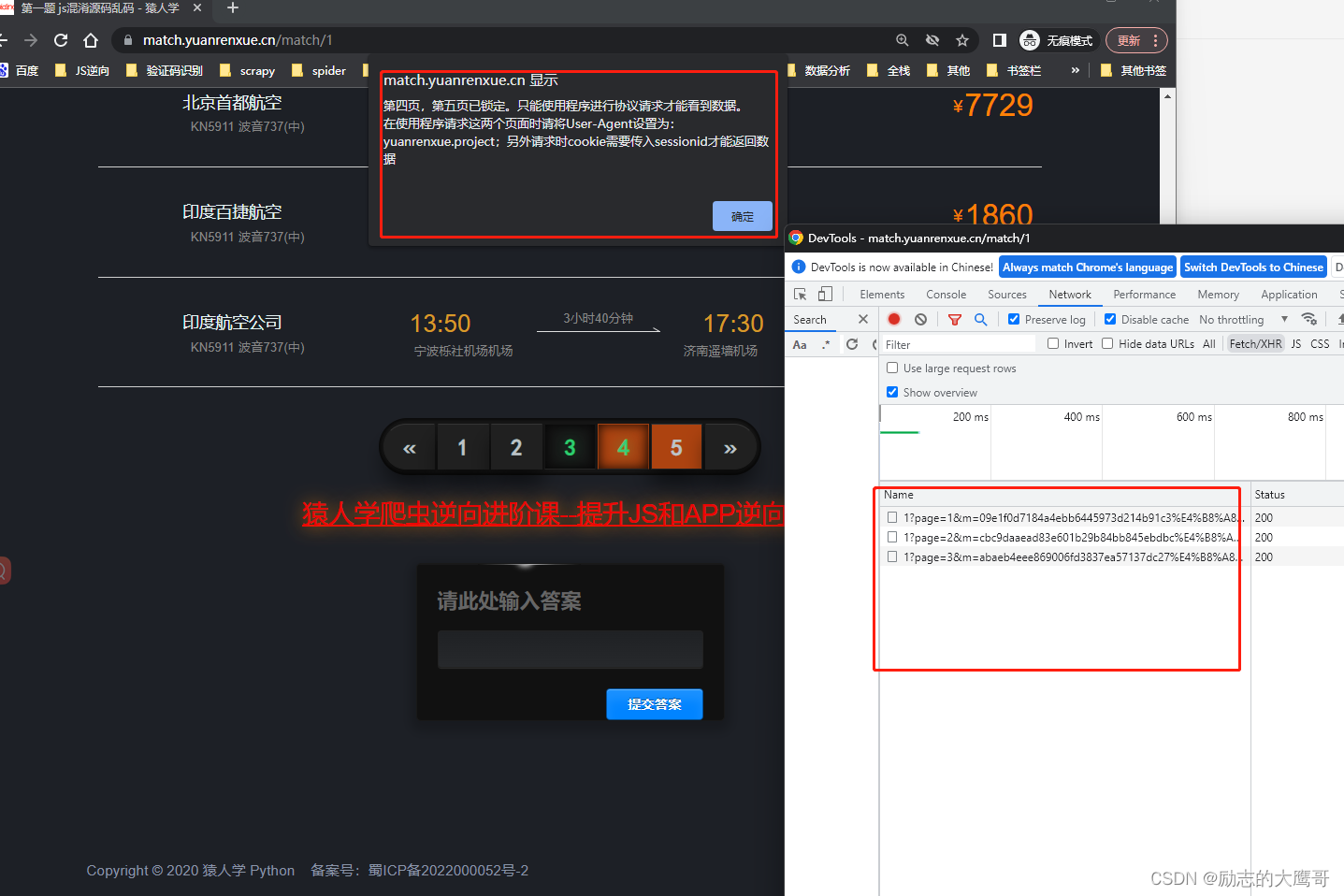
3- 复制请求到postman, 可以正常访问。
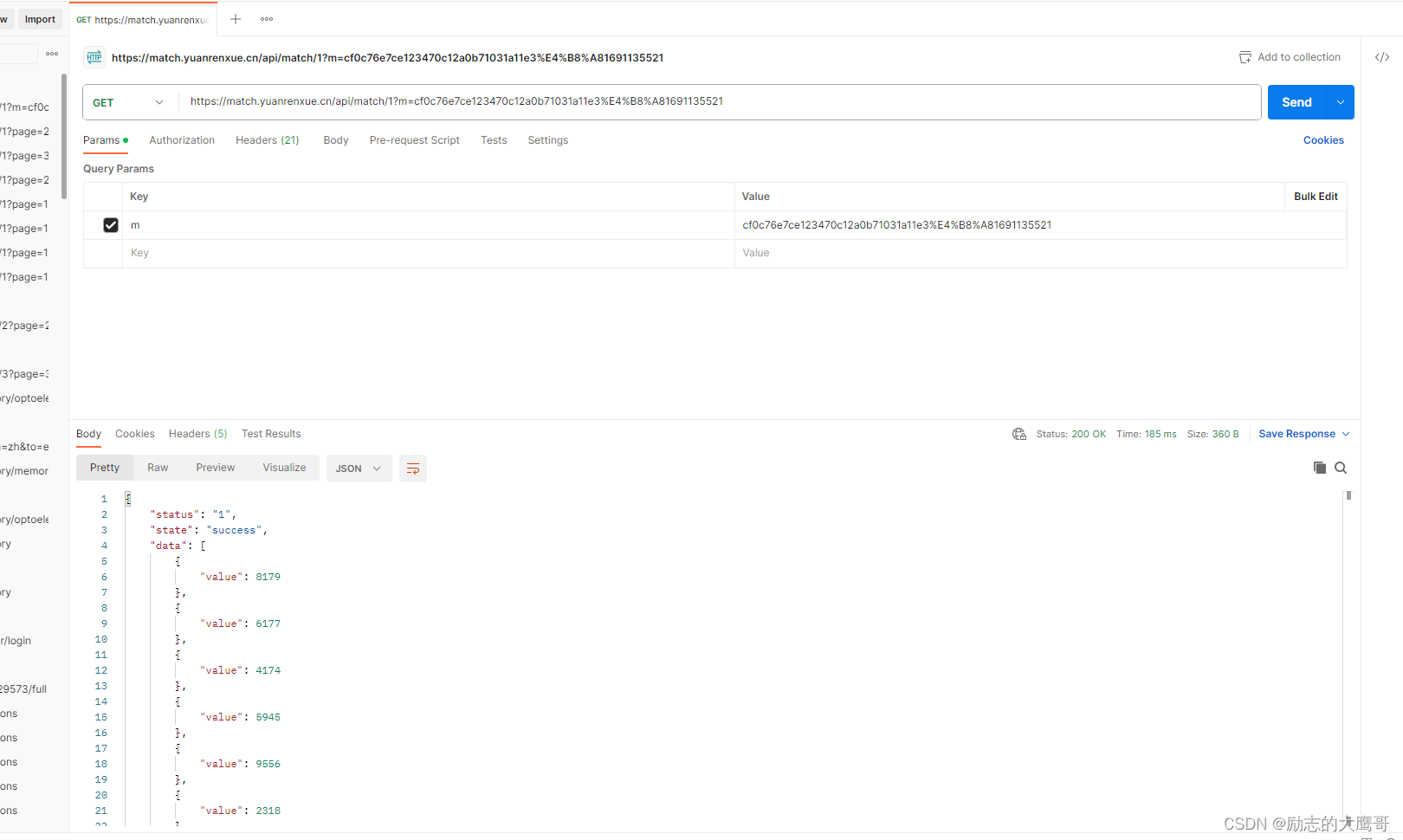
将代码复制到python, 亦可以正常访问。 哇, 感觉还行啊
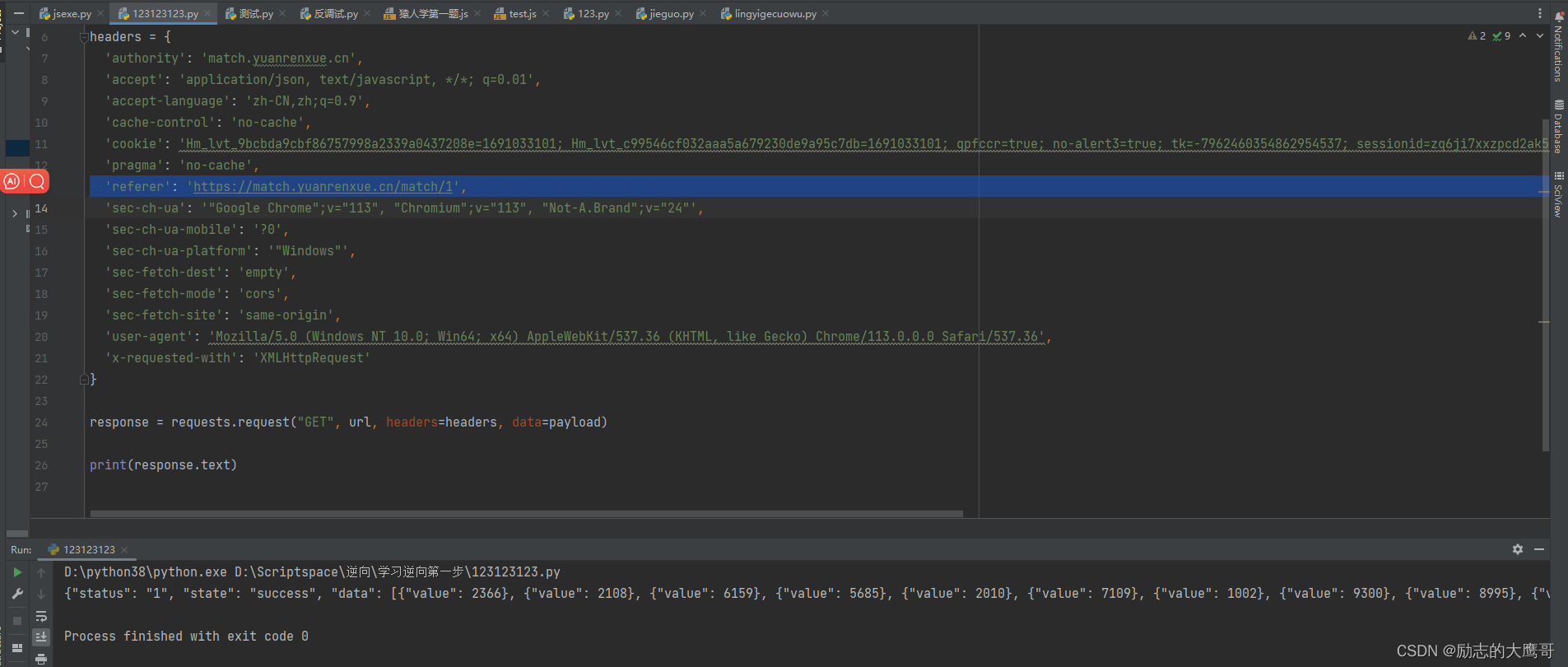
再运行一下, 报错了, 看下postman, 也报错了。 看样子是有时效性的参数。 那我们来看看参数吧。
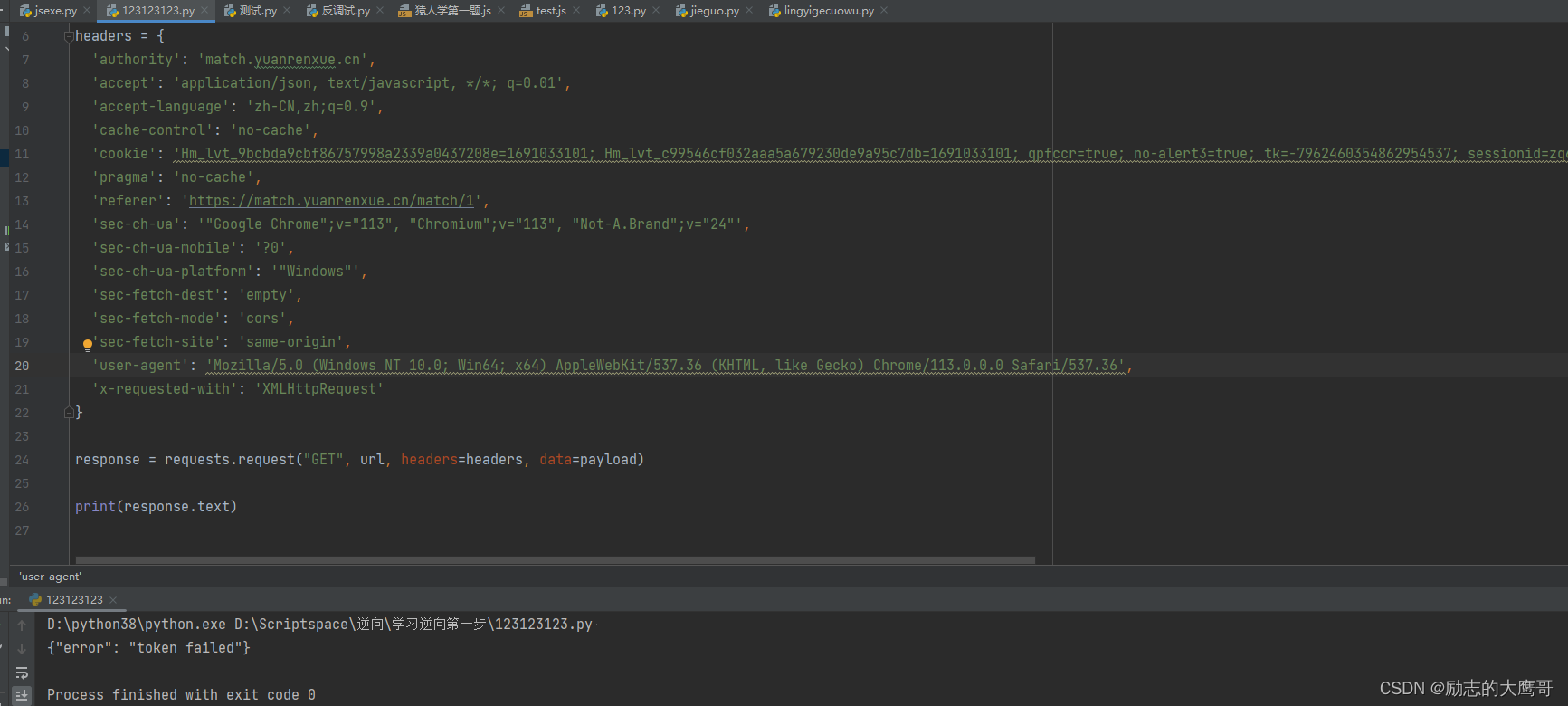
就是这个了, 多抓几次包, 确定page是页数,还有一个m是变动的。 瞅着后面像是个时间戳。前面是一段类似加密参数。 那我们的目标明确了, 就是这个m。 破解了, 就可以正常获取到页面了吧。
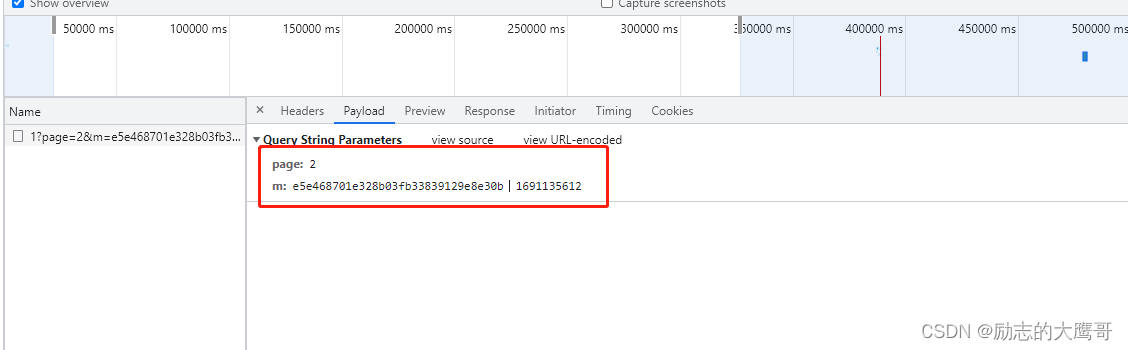
3- 逆向过程
1- 首先我们要知道一个参数如何加密的,需要先找到加密代码。 以下提供两个方法:
方法一:从Initiator中进入
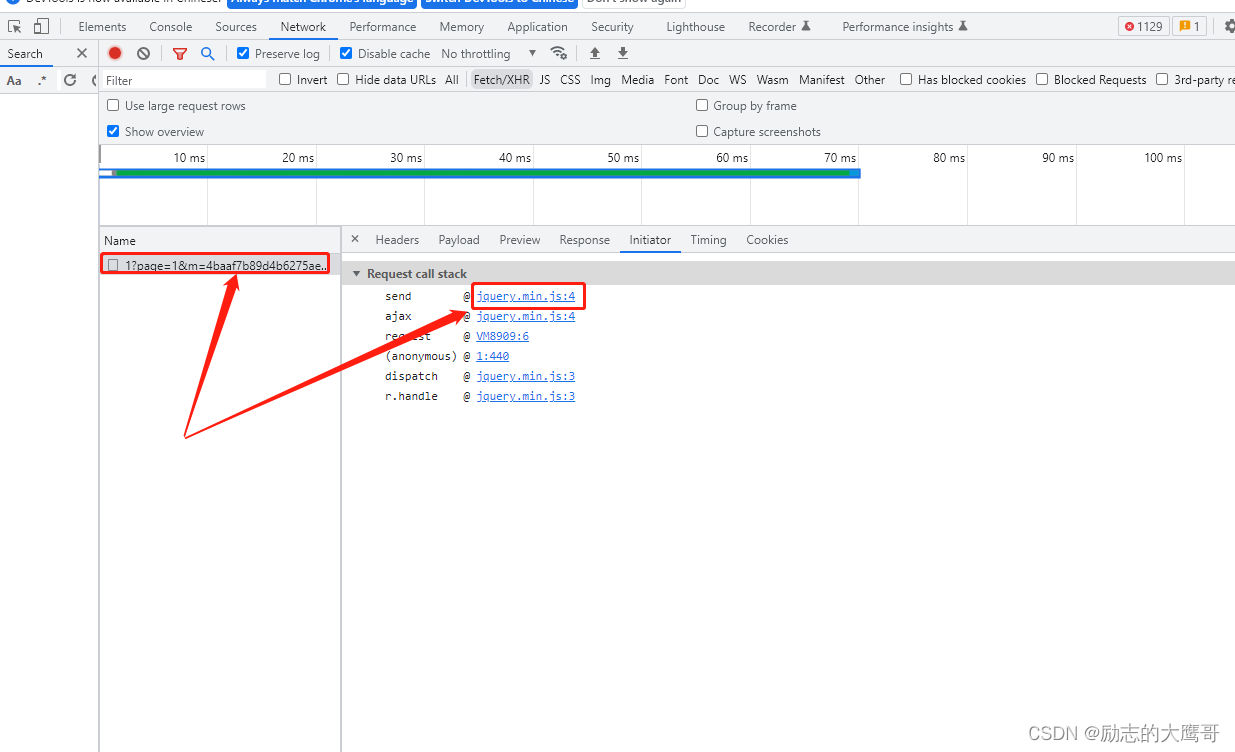
最后一个请求在此发出。 我们在此处打上断点, 即为发送请求时所有参数在此以全部加载完。那我们重新请求, 既可以看到参数的变化,从call stack中寻找, 或者search中搜索关键词都行。 慢慢找到参数 m 的生成地方
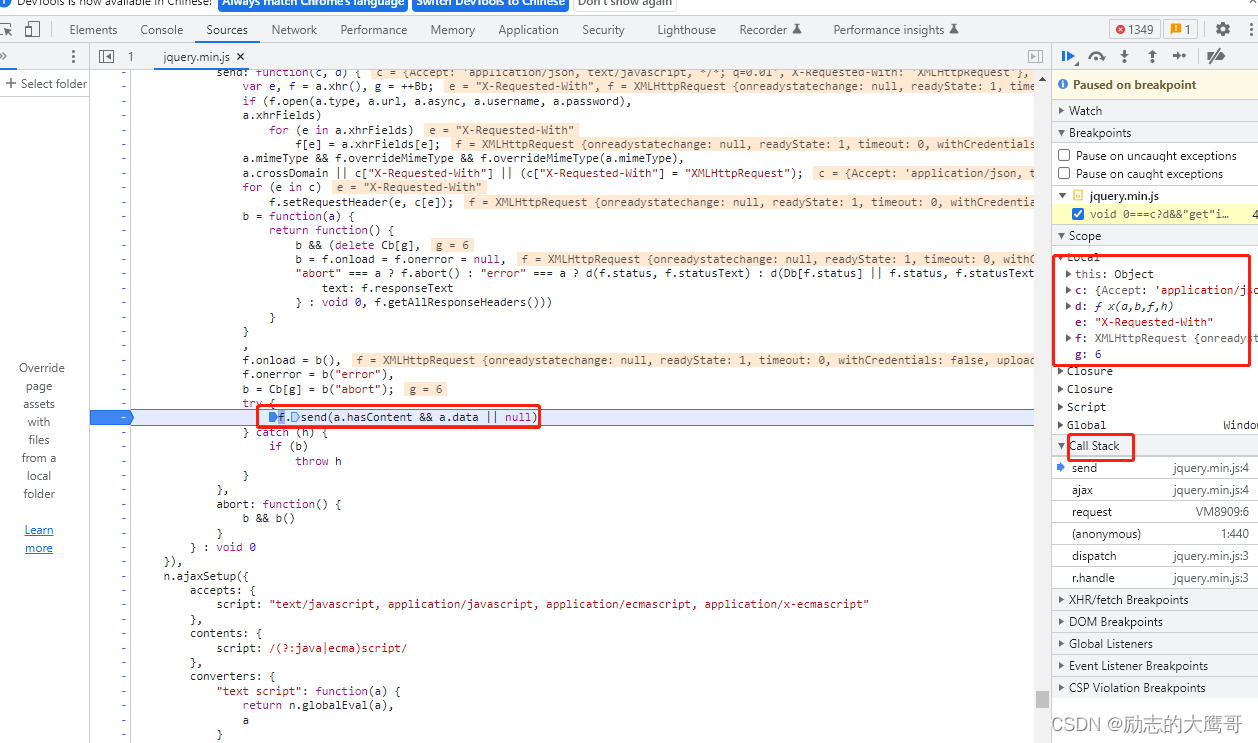
最终我们在request中找到了m的生成地方, 查看m参数是如何生成的
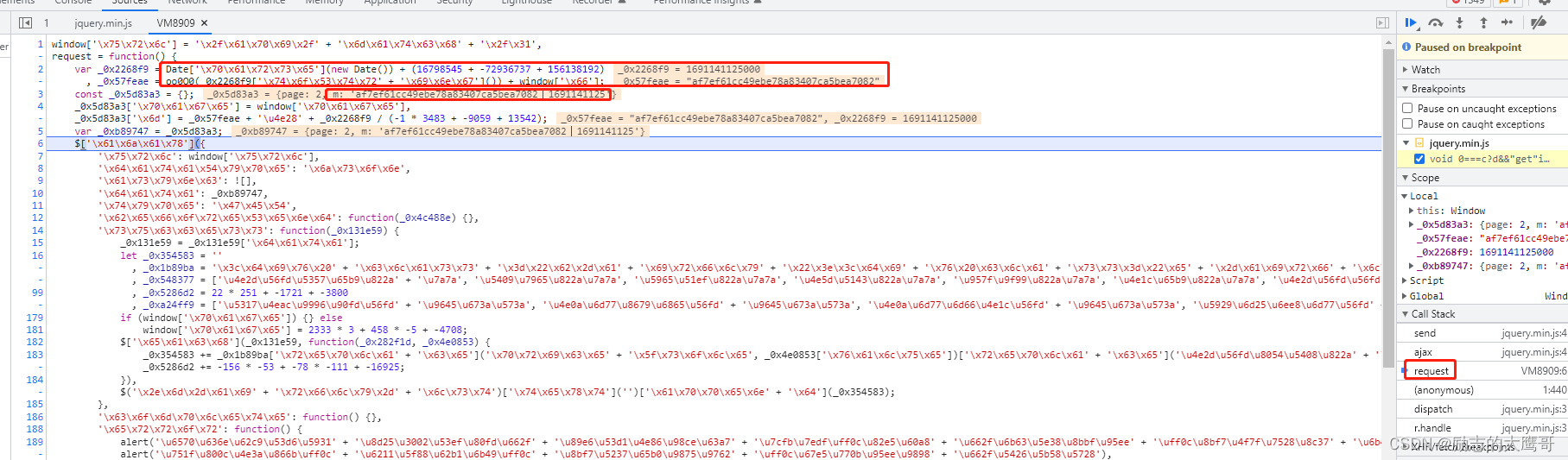
我们看到参数m 是有 window[‘\x66’] 这个值生成。很明显这个js文件中并没有该值的生成逻辑。 那如何找到 window[‘\x66’] 的加载地方呢。 我们继续往上一个堆栈找, 即anonymous。

进入后我们发现这里有一大段未格式化的js代码。 写的不规范,十有八九就是不想让你看。 如果一个网站js代码不想让别人读,那它一定有问题, 我们把这段代码拿出来格式化一下
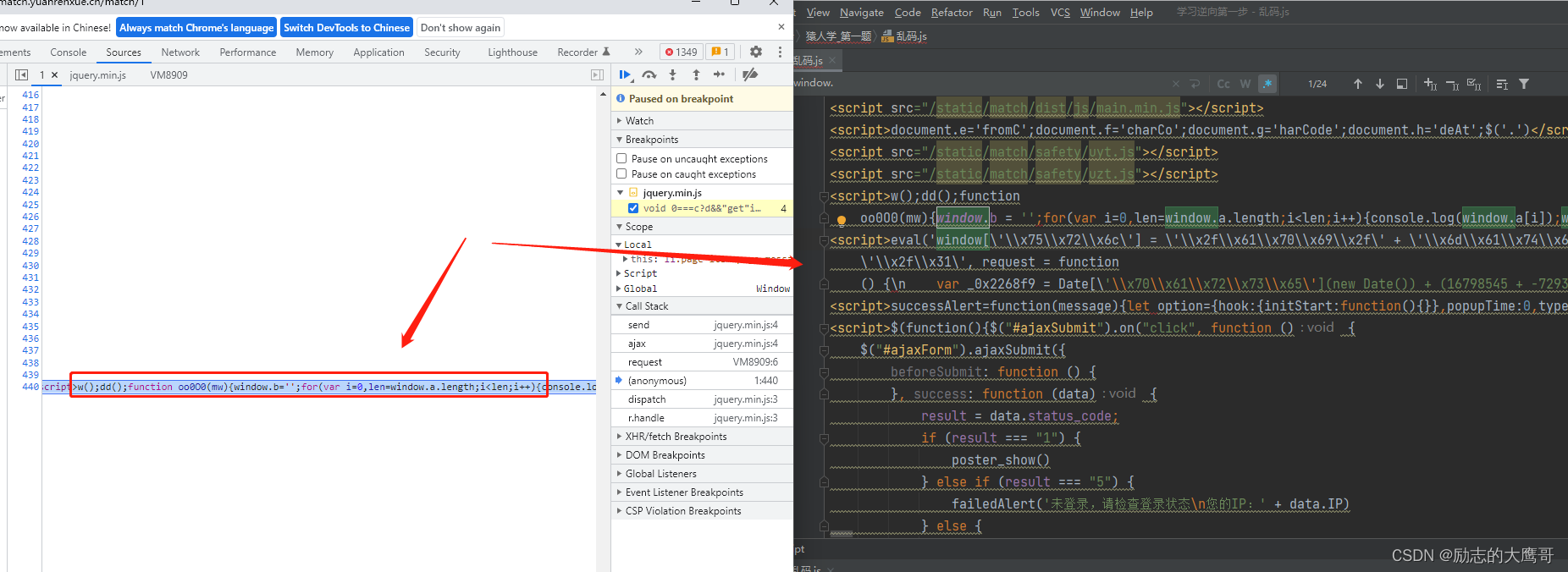
去掉一些没有什么卵用的东西, 剩下了两段js代码。
一段是我们在上一个js中看到的oo0O0(mw)函数,
另一段是window的相关属性。

咱们都展开看一下,运行一下, 发现报错。 缺少w函数, 我们缺啥补啥,一个个给他找齐
D:\Scriptspace\逆向\学习逆向第一步\猿人学_第一题\第一段js.js:1
w();
^
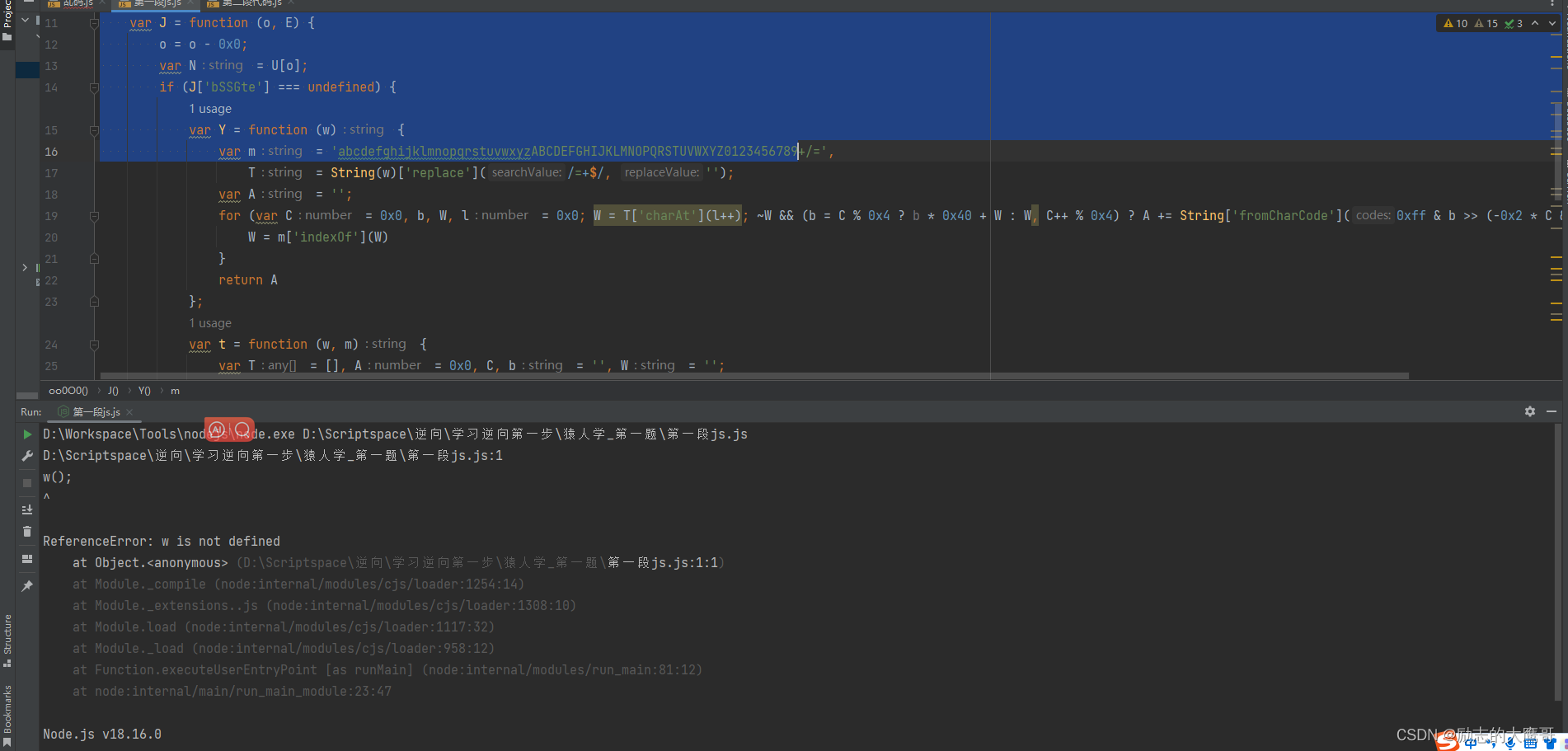
只用补齐w() 和 D()两个函数, 再次运行即正常了, 我们拿到参数 mw, 传入oo0O0(mw) 试试效果
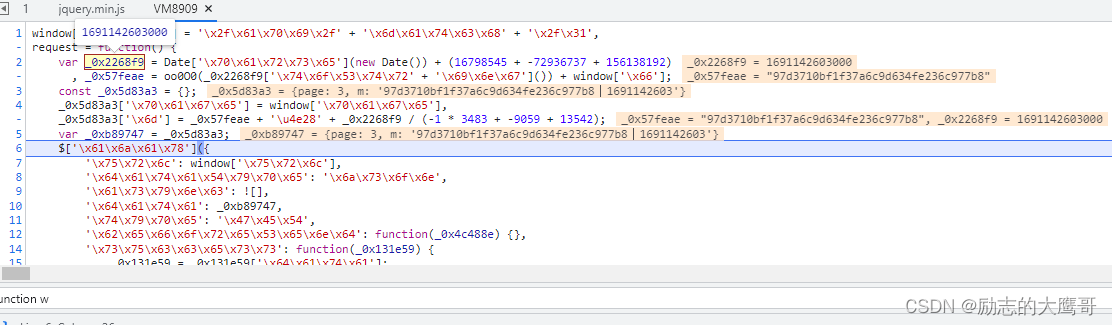
结果如下, 又去少了window.a, 继续补, 补到运行不报错为止。
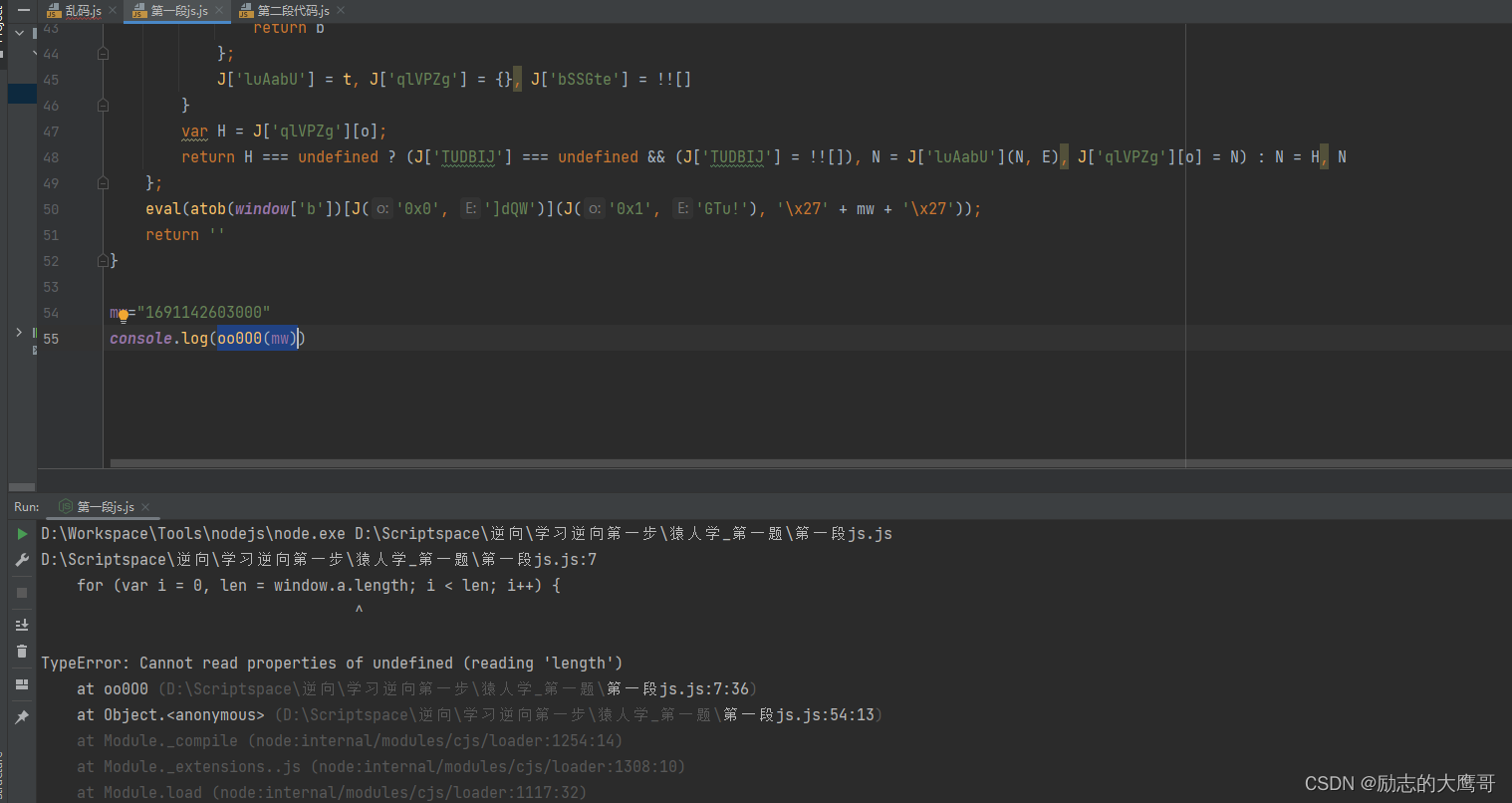
参数全部补齐后, 又报了一个如下错误。
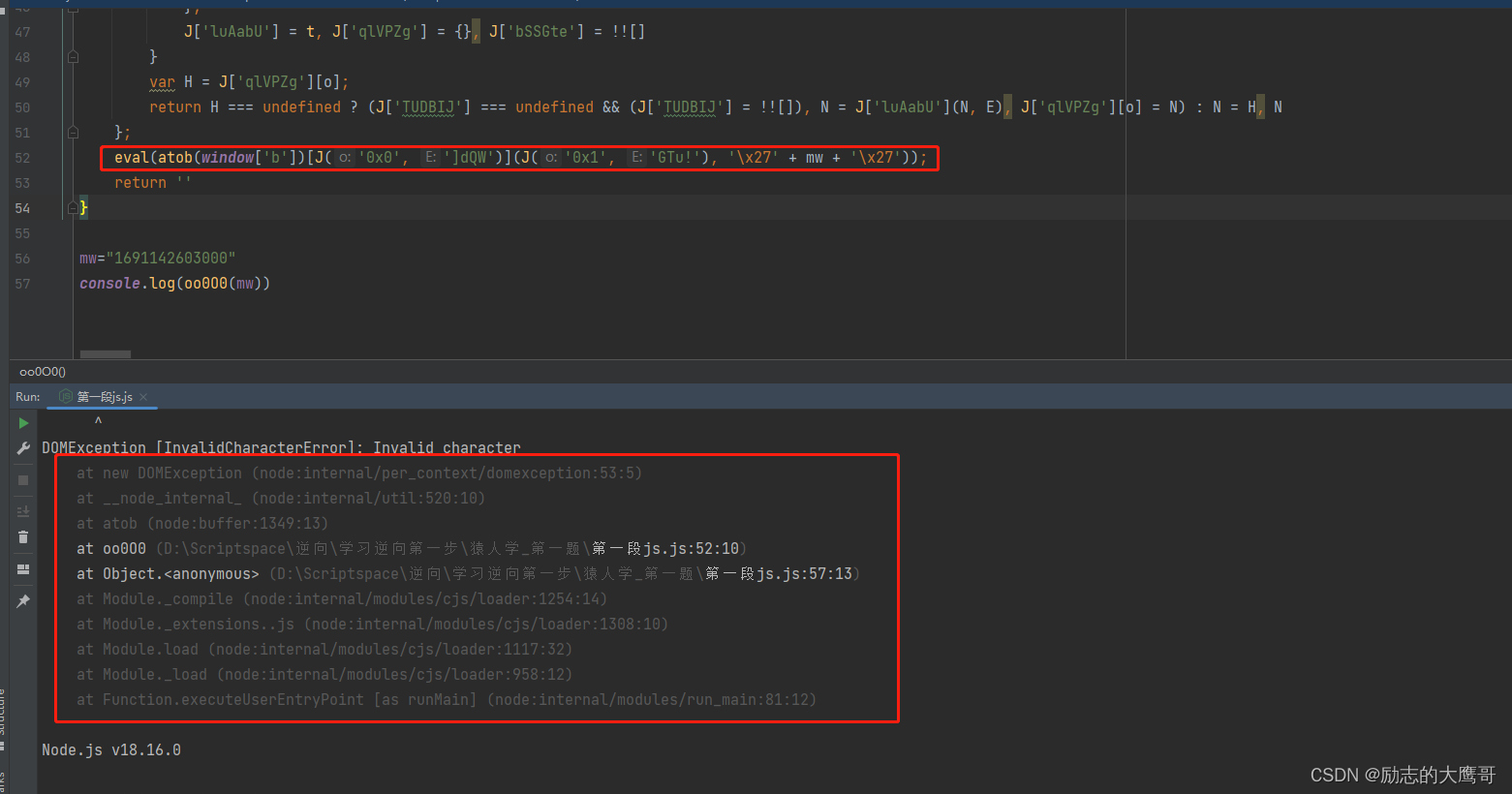
node:buffer:1349
throw lazyDOMException(‘Invalid character’, ‘InvalidCharacterError’);
^
DOMException [InvalidCharacterError]: Invalid character
at new DOMException (node:internal/per_context/domexception:53:5)
at _node_internal (node:internal/util:520:10)
at atob (node:buffer:1349:13)
at oo0O0 (D:\Scriptspace\逆向\学习逆向第一步\猿人学_第一题\第一段js.js:52:10)
at Object. (D:\Scriptspace\逆向\学习逆向第一步\猿人学_第一题\第一段js.js:57:13)
at Module._compile (node:internal/modules/cjs/loader:1254:14)
at Module._extensions…js (node:internal/modules/cjs/loader:1308:10)
at Module.load (node:internal/modules/cjs/loader:1117:32)
at Module._load (node:internal/modules/cjs/loader:958:12)
at Function.executeUserEntryPoint [as runMain] (node:internal/modules/run_main:81:12)
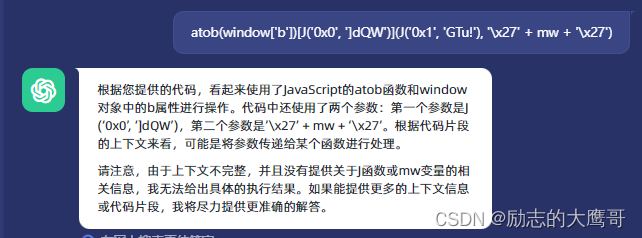
没办法一个个去打印查看一下,并随手chatgpt一下, 经过gpt的解析, 代码应该是如下这样。
其中mw是个变量, 估计是传入的mw的值。目测这就是一个函数啊
atob(window['b'])[J('0x0', ']dQW')](J('0x1', 'GTu!'), "mw" )
我们在控制台将函数打印一下,并提取出来
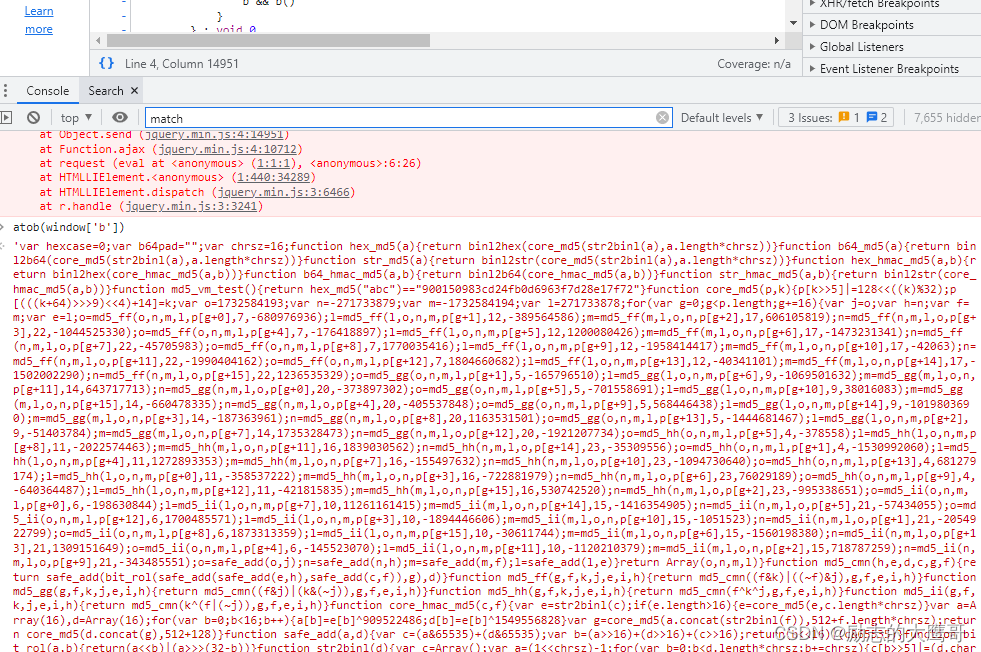
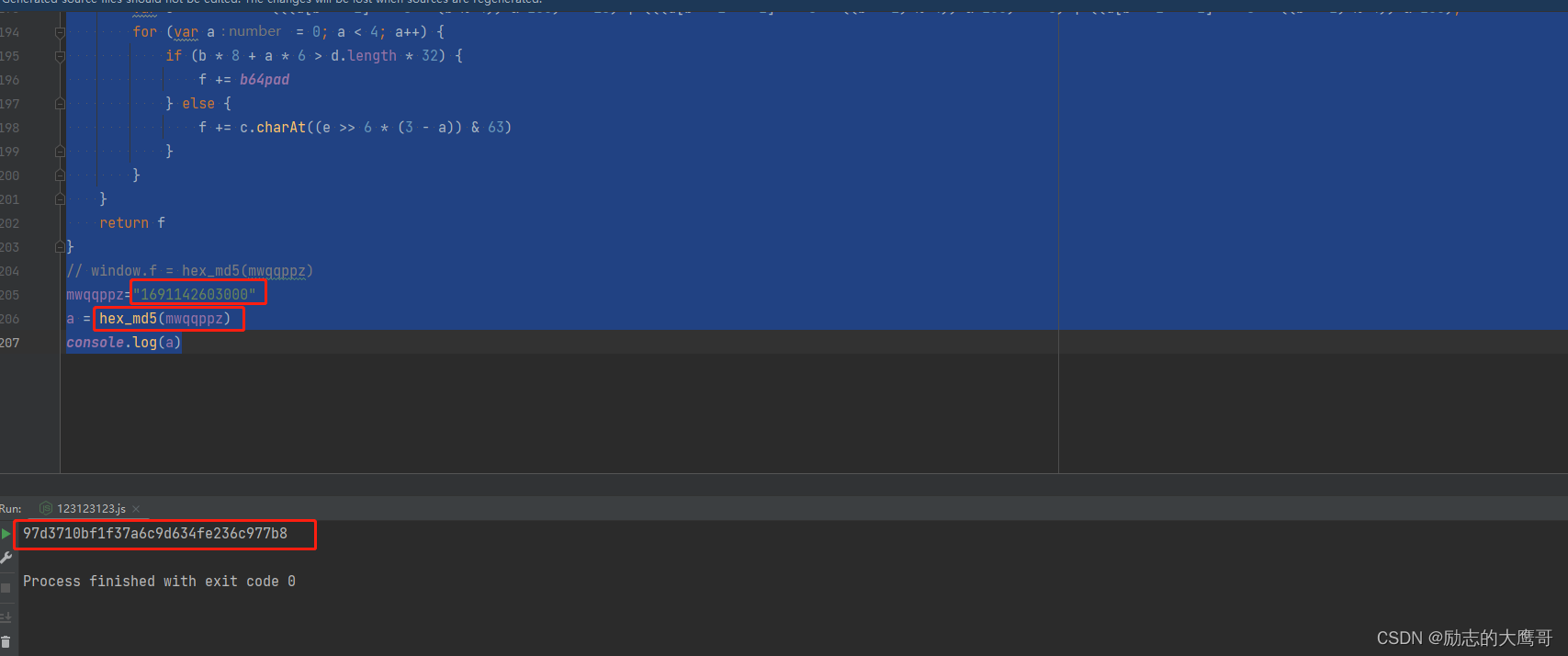
格式化一整理, 这就是个函数啊, 我们将参数传入。一运行, 成功了。 多次校验, 这个值就是参数m的加密值。 还准备打持久战,怎么稀里糊涂就已经拿到值了。
总结
按照我们原本的思路, 我们的处理逻辑是
1- 我们多次请求, 对页面进行抓包, 分析其参数。
猜想为: 加密参数外加cookie中其他参数
案例中: 只有一个m参数为必须参数
2- 对js进行断点调试, 找到m参数生成的地方
猜想为: 一段js加密, 或许会有混淆。
案例中: 加密逻辑为一段未格式化的<script>脚本,格式化后就能正常调用。
3- 对加密代码进行解析
猜想为: 生成出有一段 oo0O0(mw) 的代码, 和一段window的参数代码。 需要复现两段代码逻辑, 整合后进行解密。
案例中: 只处理了 oo0O0(mw) 函数, 并在函数中找到了eval(atob(window['b'])[J('0x0', ']dQW')](J('0x1', 'GTu!'), '\x27' + mw + '\x27')); 这段数据, 在找不到window['b']的生成处后,直接打印了atob(window['b'])得到一段js代码。 解析js代码, 确认直接为加密逻辑
4- 校验, 通过读传参时的js确定参数为时间戳, 并将时间戳传入加密逻辑, 成功获取参数m的值。
js逆向需要我们有一定的js功底, 不同的js逆向难易程度都有所不同。 针对于本案例是属于比较简单的js逆向。有种还未还是解析就已经拿到了加密逻辑的感觉。 适合练手
补充
在前面说到有几个断点调试的方法,在之前的爬虫文章中也提到了, 针对这个案例,补充一下查找断点的方法
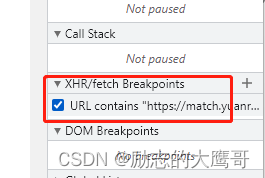
第一个:添加 xhr断点, 因为本案例中为ajax请求, 获取到了接口, 可以直接在这里打上断点
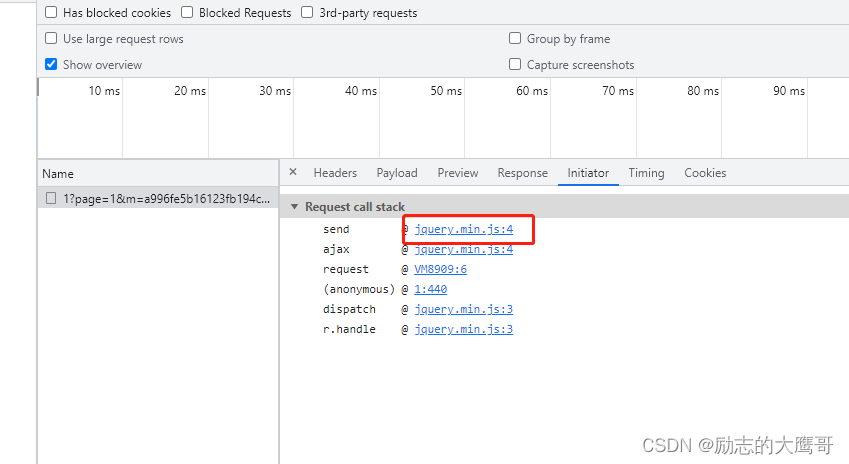
第二个:就是本案例中用到的, 直接callstack中断点
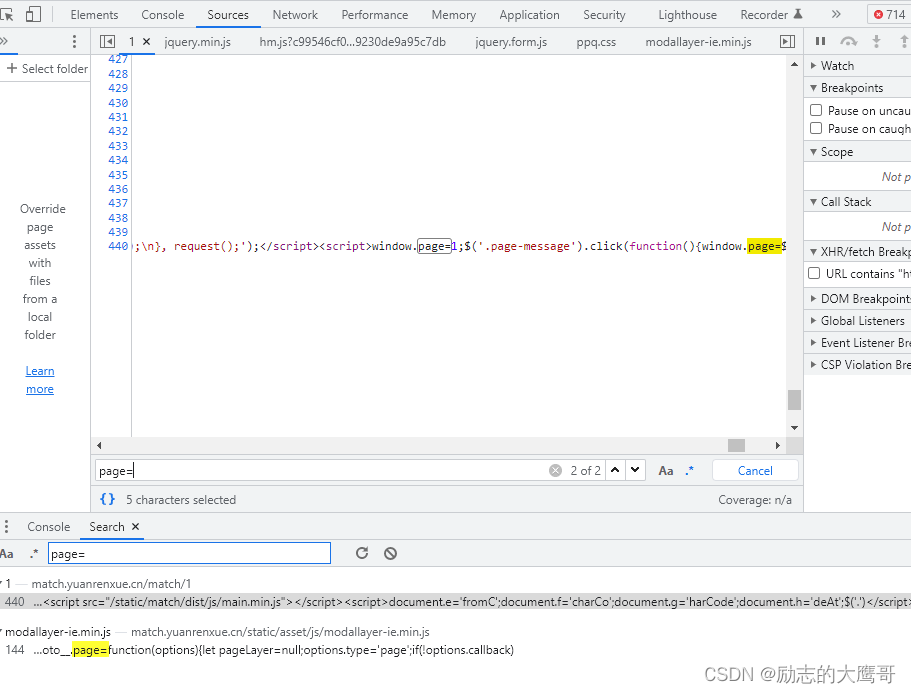
第三个: 直接搜索参数中的page, 直接找到加密逻辑。(这个方法有一定的随机性, 谨慎使用)
代码
加密逻辑大家自己搞定, 我这里只放python代码了。将加密逻辑抠出来, 运行这段python直接获取结果。
import execjs, time, urllib.parse
def get_param_m():
timestamp = int(time.time()) * 1000 + (16798545 + -72936737 + 156138192)
M_time = int(timestamp/1000)
mwqqppz = str(timestamp)
with open ('猿人学第一题.js',encoding='utf-8') as f:
js_data = f.read()
js = execjs.compile(js_data)
js_result = js.call('hex_md5', mwqqppz)
param_m = "{}丨{}".format(js_result, M_time)
return param_m
def get_info(page, param_m):
import requests
url = "https://match.yuanrenxue.cn/api/match/1?page={}&m={}".format(page, param_m)
url = urllib.parse.quote(url, safe=':/?=&')
print(url)
headers = {
'authority': 'match.yuanrenxue.cn',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'cookie': 'Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1690184377,1690941596,1690969392,1690971468; Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1690184376,1690941595,1690969392,1690971468; Hm_lvt_434c501fe98c1a8ec74b813751d4e3e3=1690971476; Hm_lpvt_434c501fe98c1a8ec74b813751d4e3e3=1690971476; tk=-7962460354862954537; sessionid=1mcld1cz4z54nrnhkuxfq7wtysc7vdds; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1691027865; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1691027869',
'pragma': 'no-cache',
'referer': 'https://match.yuanrenxue.cn/match/1',
'sec-ch-ua': '"Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',
'x-requested-with': 'XMLHttpRequest'
}
response = requests.request("GET", url, headers=headers).json()
print(response['data'])
sum = 0
for val in response['data']:
sum += val['value']
mean_num = sum/len(response['data'])
return mean_num
if __name__ == '__main__':
sum_num = 0
for page in range(1, 6):
param_m = get_param_m()
print(param_m)
res = get_info(page ,param_m)
print(res)
sum_num += res
result = sum_num/5
print(result)