星光下的赶路人star的个人主页
积一勺以成江河,累微尘以崇峻极
文章目录
- 1、SQL操作
- 1.1 Insert
- 1.2 Update 和 Delete
- 1.3 查询操作
- 1.4 alter操作
- 1.5 导出数据
- 2、副本
- 2.1 副本写入流程
- 2.2 配置步骤
1、SQL操作
基本上来说传统关系型数据库(以 MySQL 为例)的 SQL 语句,ClickHouse 基本都支持,
这里不会从头讲解 SQL 语法只介绍 ClickHouse 与标准 SQL(MySQL)不一致的地方。
1.1 Insert
基本与标准 SQL(MySQL)基本一致
(1)标准
insert into [table_name] values(…),(….)
(2)从表到表的插入
insert into [table_name] select a,b,c from [table_name_2]
1.2 Update 和 Delete
ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,它可以看
做 Alter 的一种。
虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很
“重”的操作,而且不支持事务。
“重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。
所以尽量做批量的变更,不要进行频繁小数据的操作。
(1)删除操作
alter table t_order_smt delete where sku_id ='sku_001';
(2)修改操作
alter table t_order_smt update total_amount=toDecimal32(2000.00,2) where id
=102;
由于操作比较“重”,所以 Mutation 语句分两步执行,同步执行的部分其实只是进行
新增数据新增分区和并把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删
除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
1.3 查询操作
ClickHouse 基本上与标准 SQL 差别不大
支持子查询
支持 CTE(Common Table Expression 公用表表达式 with 子句)
支持各种 JOIN,但是 JOIN 操作无法使用缓存,所以即使是两次相同的 JOIN 语句,
ClickHouse 也会视为两条新 SQL
窗口函数(官方正在测试中…)
不支持自定义函数
GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计。
(1)插入数据
hadoop102 :) alter table t_order_mt delete where 1=1;
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(101,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00'),
(106,'sku_001',1000.00,'2020-06-04 12:00:00'),
(107,'sku_002',2000.00,'2020-06-04 12:00:00'),
(108,'sku_004',2500.00,'2020-06-04 12:00:00'),
(109,'sku_002',2000.00,'2020-06-04 12:00:00'),
(110,'sku_003',600.00,'2020-06-01 12:00:00');
(2)with rollup:从右至左去掉维度进行小计
hadoop102 :) select id , sku_id,sum(total_amount) from t_order_mt group by
id,sku_id with rollup;
(3)with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计
hadoop102 :) select id , sku_id,sum(total_amount) from t_order_mt group by
id,sku_id with cube;
(4)with totals: 只计算合计
hadoop102 :) select id , sku_id,sum(total_amount) from t_order_mt group by
id,sku_id with totals;
1.4 alter操作
同 MySQL 的修改字段基本一致
1、新增字段
alter table tableName add column newcolname String after col1;
2、修改字段类型
alter table tableName modify column newcolname String;
3、删除字段
alter table tableName drop column newcolname;
1.5 导出数据
clickhouse-client --query "select * from t_order_mt where
create_time='2020-06-01 12:00:00'" --format CSVWithNames>
/opt/module/data/rs1.csv
更多支持格式参照:https://clickhouse.tech/docs/en/interfaces/formats/
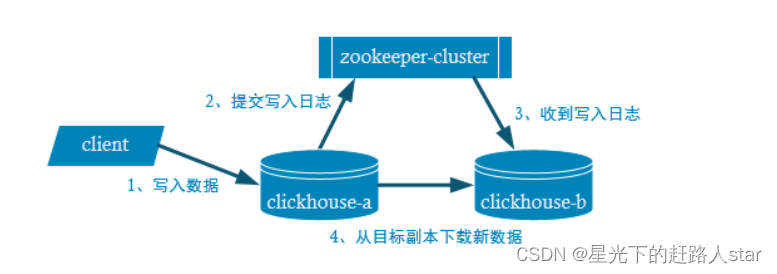
2、副本
副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从
其他服务器获得相同的数据。
2.1 副本写入流程
2.2 配置步骤
1、启动 zookeeper 集群
2、在 hadoop102 的/etc/clickhouse-server/config.d 目录下创建一个名为 metrika.xml
的配置文件,内容如下:
注::也可以不创建外部文件,直接在 config.xml 中指定
<?xml version="1.0"?>
<yandex>
<zookeeper-servers>
<node index="1">
<host>hadoop102</host>
<port>2181</port>
</node>
<node index="2">
<host>hadoop103</host>
<port>2181</port>
</node>
<node index="3">
<host>hadoop104</host>
<port>2181</port>
</node>
</zookeeper-servers>
</yandex>
3、同步到hadoop103和hadoop104上
4、在 hadoop102 的/etc/clickhouse-server/config.xml 中增加
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
5、同步到 hadoop103 和 hadoop104 上
(1)分别在 hadoop102 和 hadoop103 上启动 ClickHouse 服务
注意:因为修改了配置文件,如果以前启动了服务需要重启
注意:我们演示副本操作只需要在 hadoop102 和 hadoop103 两台服务器即可,上面的
操作,我们 hadoop104 可以你不用同步,我们这里为了保证集群中资源的一致性,做了同
步。
6、在 hadoop102 和 hadoop103 上分别建表
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美