Linux运维面试题(三)之数据库管理
- 1. SQL语句
- 2.集群
- 主从服务器原理
- 主从故障切换
- 单台Mysql达到性能瓶颈时,如何处理
- 3.索引(软优化)
- 什么是索引
- 索引的分类
- 劣势(优点:效率和减少数据表内排序和随机查询——>顺序查询(已经过排序和去重(合并)))
- 什么时候需要创建索引
- 什么时候不需要创建索引
- 误操作drop语句导致数据库数据破坏,请给出恢复的实际大体步骤
- 4.Redis
- 工作原理
- redis持久化-RDB
- 如何利用redis对mysql进行性能优化
- 主主服务器(分摊写压力)
- 主主备份方式(主主从模式)
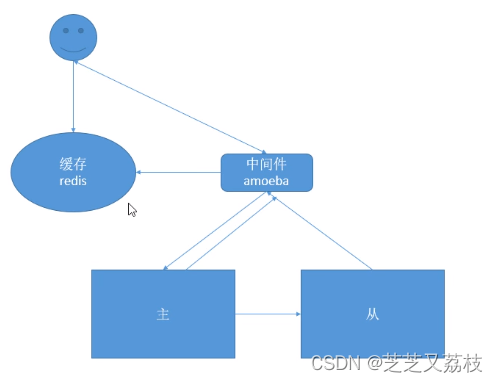
- Amoeba模式
- Amoeba的配置
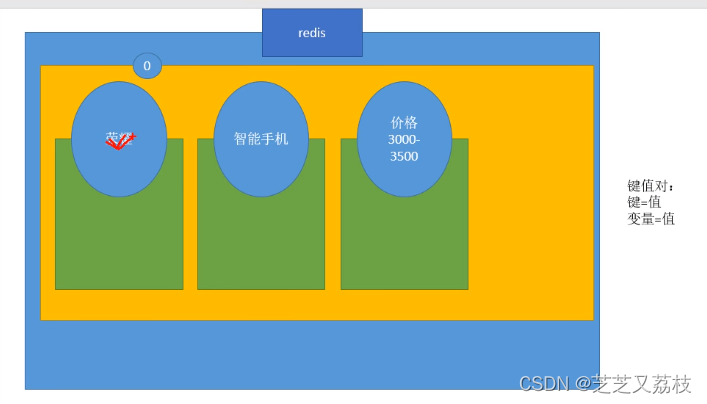
- Redis的处理方式(做交集)
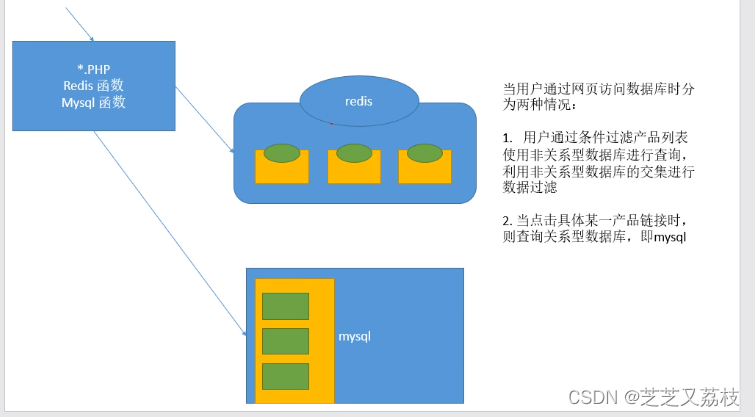
- Redis和mysql模式
1. SQL语句

- count(*)返回指定匹配条件的行数,like匹配李
- order by排序方式,desc降序
- limit2取前两行

- @后登陆数据库的方式,本地登陆(localhost)、远程登录(具体、泛指@),密码
- 声明两个字段,并对类型做约束。name字符串长度不能超过30
- 往字段的某一位置插入哪些值

- 2.3.停止服务、提前备份

- 查看,改变字段类型,查看表的结构信息

- 字段类型


- 但凡指定用户,必须指明用户类型;授权用户所有权限给at管理aa表的al字段

2.集群
- (1)MYSQL 一主多从,主库宕机,如何合理切换到从库,其他从库如何处理?
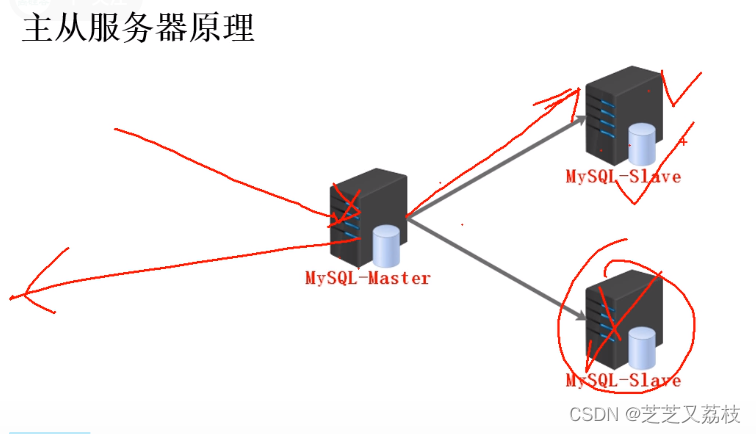
主从服务器原理
技术点:bin-log二进制日志
开启主服务器的bin-log日志记录(数据增删改授权等,对数据库进行数据修改)功能,将主服务器的bin-log日志传到从服务器,从服务器根据日志内容(均执行一遍)将数据还原到本地。
主从(身份声明,授权允许)服务器:
主服务器负责接收用户的写入和用户的查询,从服务器备份主服务器的数据。
从服务器主动把主服务器上的数据同步到本地(备份备用)
- 连接线程、解析线程。
- 一主一从、一主多从
主从故障切换
- MYSQL一主多从,主库宕机,如何合理切换到从库,其它从库如何处理
- 登陆所有从库查看post信息,使用POST最大(从主同步的数据更多更完整)的做为新的主库,然后将从库提升为新的主库,登陆从库(新的主库)执行stop slave
修改my.cnf配置文件,开启bin-log并重新启动数据库服务,登录数据库执行reset master,show master status\G;查看主库信息,最后创建授权同步用户与权限和网站使用数据库的用户与权限,最后修改对应服务器的IP地址等信息
登录其他从库,执行change master操作,查看同步状态。 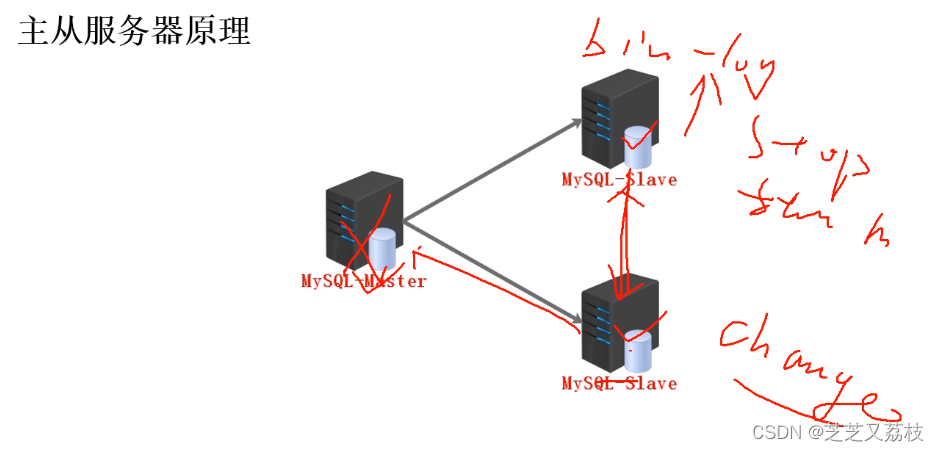
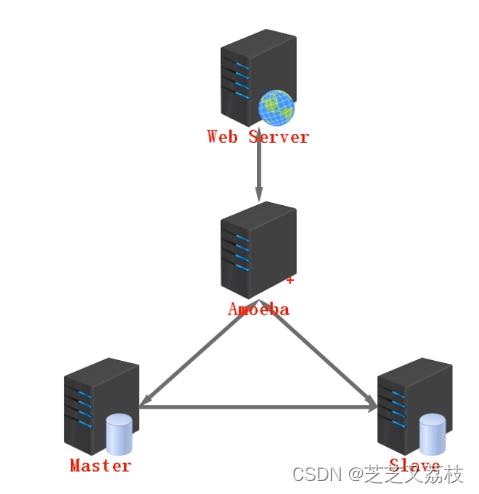
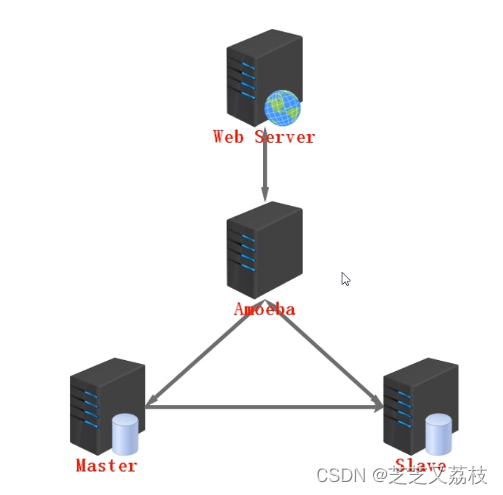
单台Mysql达到性能瓶颈时,如何处理
- 数据库代理工具:Amoeba(反向代理、转发中间件)
Amoeba致力于MySQL的分布式数据库前端代理层,它主要在应用层访问Mysql的时候充当sql路由功能,专注于分布式数据库代理层(Database Proxy)开发。具有负载均衡(分配主从服务器任务分配算法)、高可用性、SQL、过滤、读写分离(主:插入更新,从:查询操作,降低主服务器负载)、可路由相关的到目标数据库、可并发请求多台数据库合并结果。通过Amoeba你能够完成多数据源的高可用、负载均衡、数据切片的功能。 - 横纵向扩展。纵向扩展:增加配件来提升单台服务器性能;横向扩展:一台——》多台(较好)
3.索引(软优化)
- MYSQL什么时候创建索引
什么是索引
- 索引本质是数据结构,(创建好新表)排好序的快速查找数据结构,可以提高查找效率
(词典目录)
数据分身之外,数据库还维护着一个满足特定查找算法的数据结构,这些数据结构可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引
索引的分类
- 主键索引
- 单值索引 一个索引只包含单个列,一个表可以有多个单列索引。如果字段会被经常用来检索就可以用单值索引
- 复合索引 一个索引包含多个列,如电话簿上姓+名字。最好不超过5个字段
- 唯一索引 所有列的值必须唯一,但是允许有空值
- 普通索引和唯一索引可以称为辅助索引
劣势(优点:效率和减少数据表内排序和随机查询——>顺序查询(已经过排序和去重(合并)))
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,索引列也要是占用空间的。

- 虽然索引大大提高了查询速度,但是会降低更新表的速度,如对表进行INSERT,UPDATE,DELETE。因为更新表示,Mysql不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
索引只是提高效率的一个因素,如果Mysql有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询。
什么时候需要创建索引
- 主键自动建立唯一索引
频繁作为查询条件的字段应该创建索引
查询中与其他表关联的字段,外键关系建立索引
频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索引
where条件里用不到的字段不创建索引
单键/组合索引的选择问题,在高并发下倾向创建组合索引
查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
查询中统计或者分组字段(group by)
什么时候不需要创建索引

误操作drop语句导致数据库数据破坏,请给出恢复的实际大体步骤
- 手动切割bin-log日志并记好切割好的bin-log日志文件位置,这里假设为009,备份全部bin-log日志
- 找到之前全备份数据最后备份到的bin-log文件位置并记好位置,这里假设为005
- 用mysqladmin命令将005到008bin-log文件中的SQL语句分离出来,并找到drop库的语句将其删掉
- 将之前全备数据导入mysql服务器(005+(005-008)+009)
- 将步骤3中分离出的SQL语句导入mysql服务器
- 将009bin-log文件删除,再次刷新bin-log日志,到此数据库已恢复成功
4.Redis
- 如何保证Redis能永久保存数据(持久化)
工作原理
- Redis是一个key-value存储系统,它支持的value类型相对较多,包括string、list、set和zset,这些数据都支持push/pop/add/remove及交并补等操作,而且这些操作都是原子性的,在此基础上,redis支持各种不同方式的排序。为了保证效率,数据是缓存在内存中的,redis会周期性的把数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave同步。
- 与mysql的库表结构不一样
- 原子性,总核不变,事件修改完整

- 回滚,红递明未接,拿回,保证原子性。
- 主从备份,保障完整性。
redis持久化-RDB
- 在Redis运行时,RDB程序将当前内存中的数据库快照保存到磁盘中,当redis需要重启时,RDB程序会通过重载RDB文件来还原数据库。


- AOF——>mysql的bin-log



- 对数据进行修改时的操作,避免记录对数据进行重复修改的操作(覆盖式,保留最新一次)。
如何利用redis对mysql进行性能优化
- 互补关系
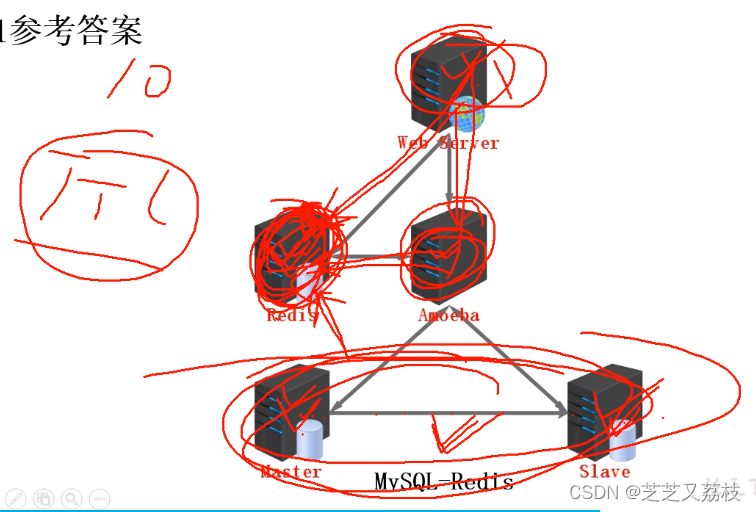
- if语句是否有符合相应条件的语句,Redis没有则向Amoeba发送请求,由于Amoeba是关系型数据库的代理服务器,A发起查询操作,找到结果后,A将结果返回给用户并向redis插入一份,并设置TTL值——有效时间值:redis用来做mysql的缓存,原始关系数据库更新,若无更新,用户优先查缓存而查不到原始数据,以此使缓存和关系数据库数据保持一致性。
主主服务器(分摊写压力)

主主备份方式(主主从模式)
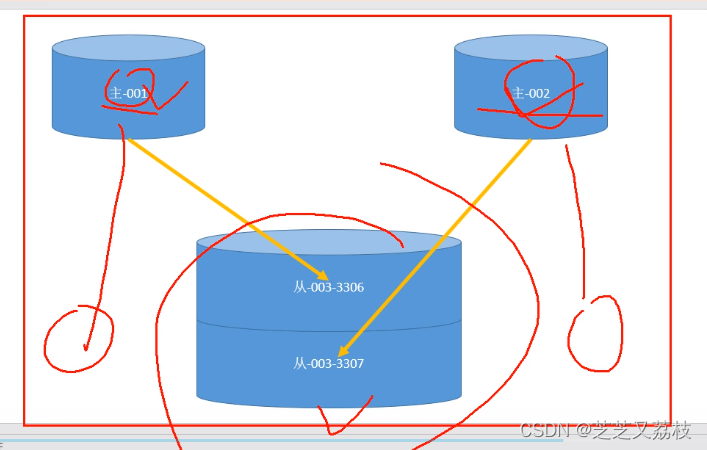
- 在同一个设备启用两个不同的mysql程序
Amoeba模式
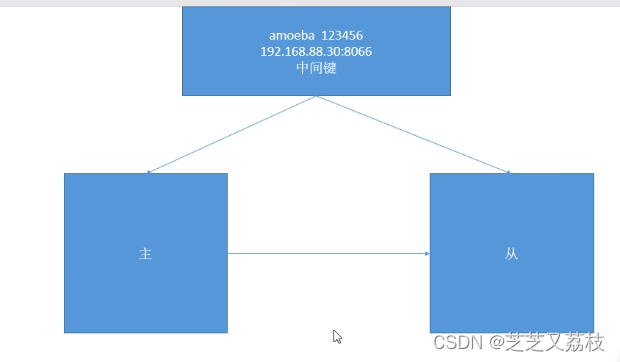
Amoeba的配置
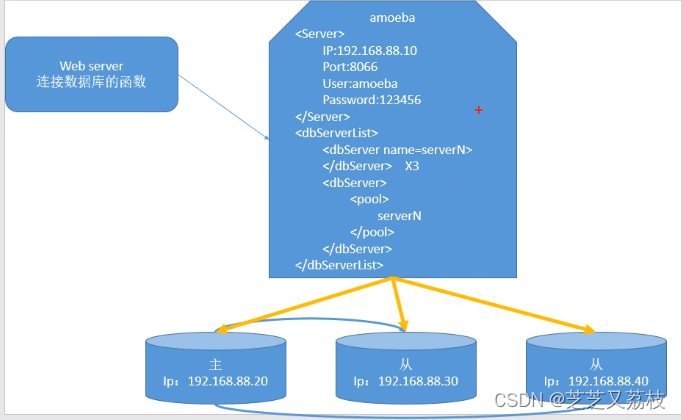
- 上为A信息,下为连接的资源池信息