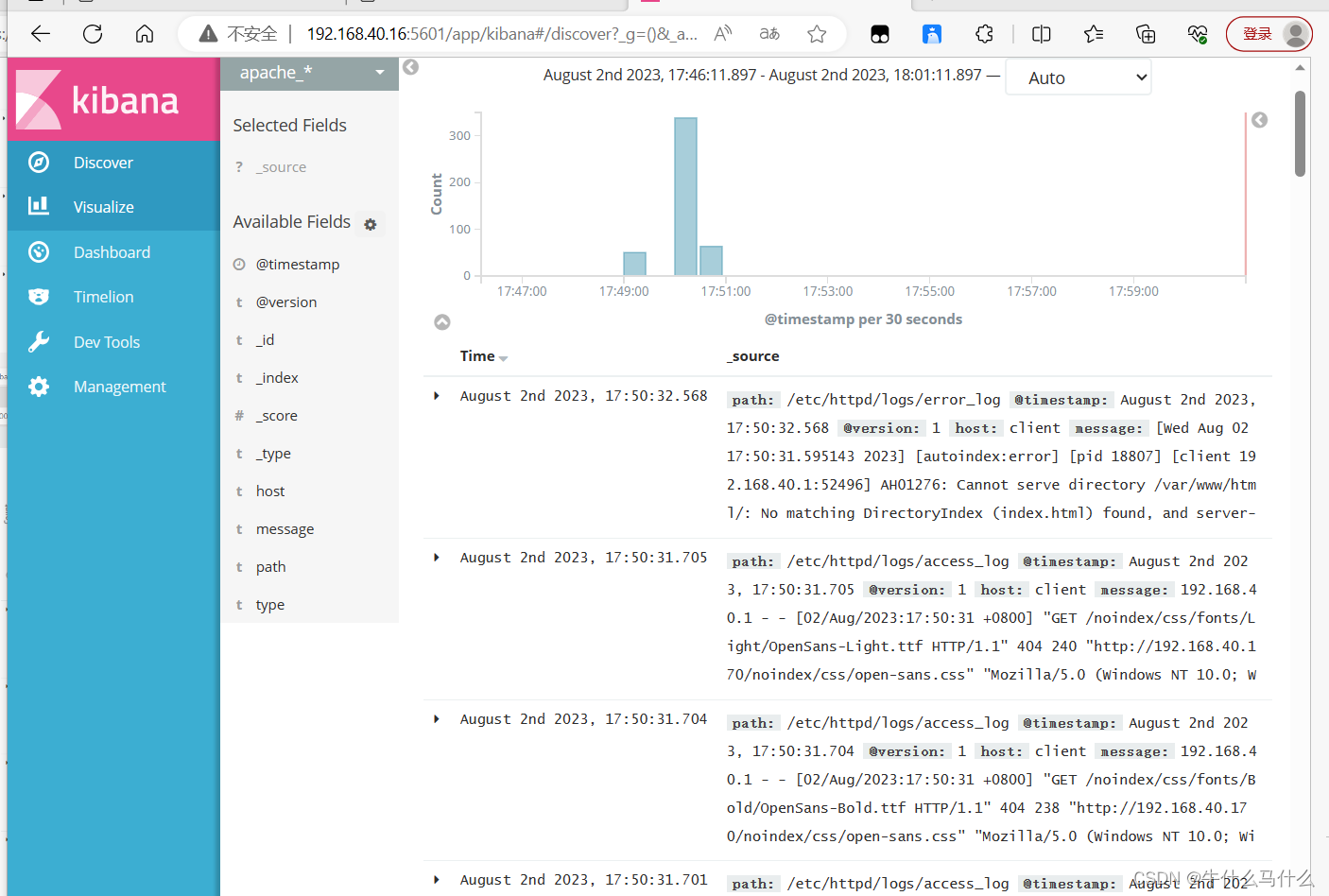
设想我们有如下一个excel文件
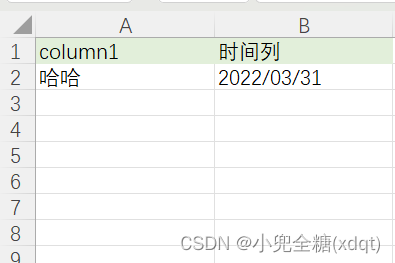
我们都知道上面那个时间列其实是string类型,因此在用pandas做时间校验的时候会不通过,我们可以在read_excel的时候,指定这一列做转换
import pandas as pd
from datetime import datetime, timedelta
import numpy as np
from dateutil.parser import parse
def indexes(iterable, obj):
return (index for index, elem in enumerate(iterable) if elem == obj)
def func1(args):
try:
return parse(str(args))
except:
return np.nan
excel = pd.read_excel(r'C:\Users\84977\Desktop\test.xlsx',sheet_name=None,converters={"时间列":func1})#converters={"时间列":datetime})
errordata = set()
for sheet_name, df in excel.items():
m = df['时间列'].apply(lambda v: isinstance(v, datetime))
datacolumn = pd.to_datetime(np.where(m, df['时间列'].astype(str), np.NaN))
idxs = indexes(list(datacolumn.isnull()), True)
nulldata = list(idxs)
for index,item in enumerate(datacolumn):
if index not in nulldata:
if item.strftime('%Y-%m')!='2022-03':
errordata.add(index)
elif index in nulldata:
errordata.add(index)
print(list(errordata))