文章目录
- 1. 平衡二叉树、红黑树、Hash结构、B树和B+树的区别是什么?
- 2. 一个B+树中大概能存放多少条索引记录?
- 3. 使用B+树存储的索引crud执行效率如何?
- 4. 什么是自适应哈希索引?
- 5. 什么是2-3树 2-3-4树?
- 6. 为什么官方建议使用自增长主键作为索引?
- 7. 使用int自增主键后 最大id是10,删除id 10和9,再添加一条记录,最后添加的id是几?删除后重启mysql然后添加一条记录最后id是几?
- 8. 索引的优缺点是什么?
- 9. 使用索引一定能提升效率吗?
- 10. 如果是大段文本内容,如何创建(优化)索引?
- 11. 什么是聚簇索引?
- 12. 一个表中可以有多个(非)聚簇索引吗?
- 13. CRUD时聚簇索引与非聚簇索引的区别是什么?
- 14. 非聚簇索引为什么不存数据地址值而存储主键?
1. 平衡二叉树、红黑树、Hash结构、B树和B+树的区别是什么?
- 普通树的问题
- 左子树全部为空,从形式上看,更像一个单链表(
树的高度太高,不适合做索引),不能发挥BST(二叉搜索树)的优势。解决方案:平衡二叉树(AVL)
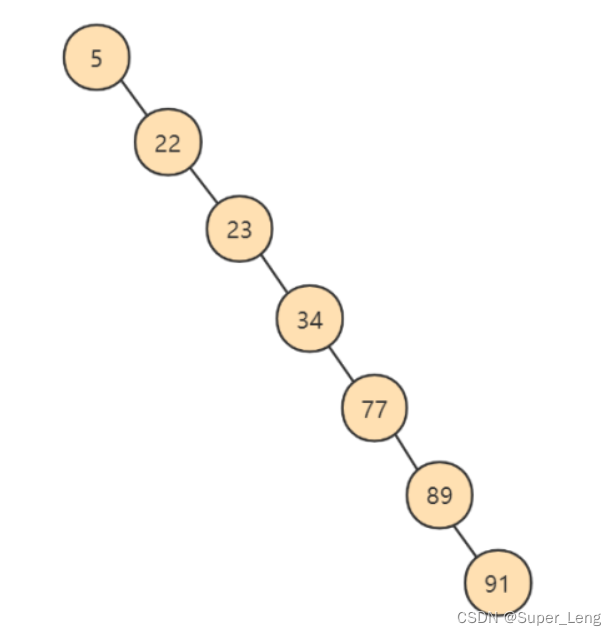
- 平衡二叉树(AVL)
AVL树全称G.M. Adelson-Velsky和E.M. Landis,这是两个人的人名。
平衡二叉树也叫平衡二叉搜索树(Self-balancing binary search tree)又被称为AVL树, 可以保证查询效率较高。
- 左右平衡,并且左右两个子树都是一棵平衡二叉树
- 它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,高度差大于1会自旋
- 每个节点记录一个数据(
每个节点记录的数据太少,造成树的高度太高,不适合做索引)
AVL的生成演示:https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
AVL的问题
众所周知,IO操作的效率很低,在大量数据存储中,查询时我们不能一下子将所有数据加载到内存中,只能逐节点加载(一个节点一次IO)。如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。平衡二叉树由于树深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。
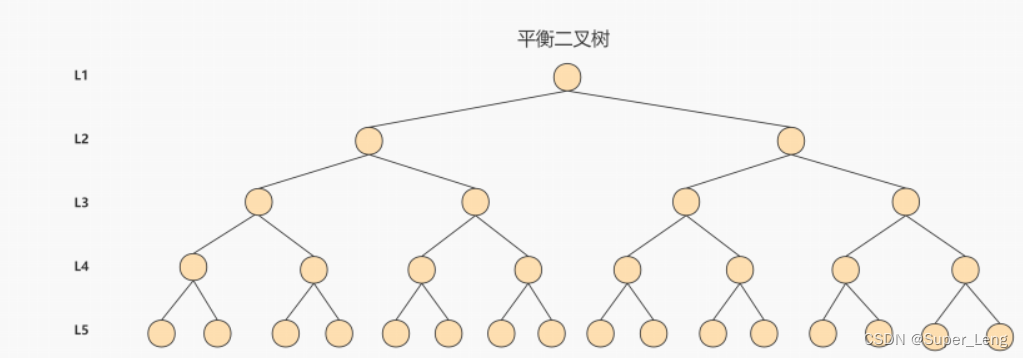
为了提高查询效率,就需要减少磁盘IO数 。
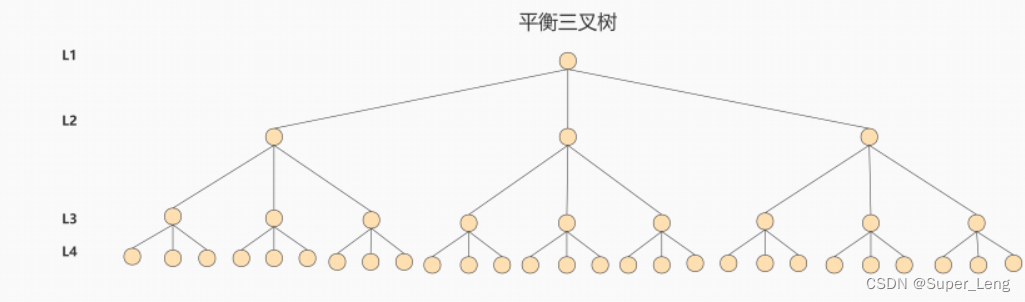
为了减少磁盘IO的次数,就需要尽量降低树的高度,需要把原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。针对同样的数据,如果我们把二叉树改成 三叉树:
上面的例子中,我们将二叉树变成了三叉树,降低了树的高度。如果能够在一个节点中存放更多的数据,我们还可以进一步减少节点的数量,从而进一步降低树的高度。这就是多叉树。
- 红黑树
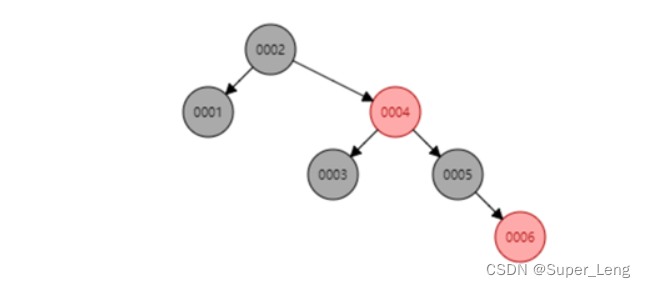
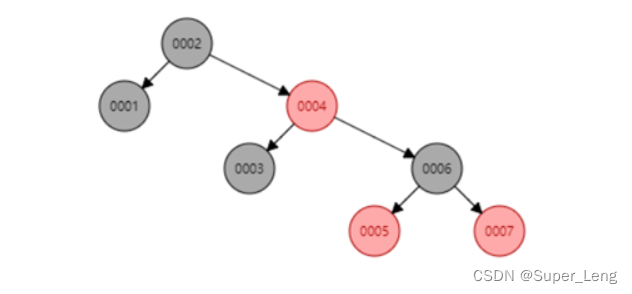
红黑树是一种自平衡二叉查找树。
它的左右子树高差有可能大于 1,红黑树的长子树只要不超过短子树的两倍即可,所以红黑树不是严格意义上的平衡二叉树(AVL)。
- hashmap存储
- 两次旋转达到平衡
- 分为红黑节点
当再次插入7的时候,这棵树就会发生旋转
数据多时,树的高度太高,不适合做索引
- Hash结构
- 对索引的key进行一次hash计算就能定位出数据存储的位置
- 很多时候Hash索引比B+树索引更高效
因为不是按顺序存储的,所以仅能满足 “=”,“IN”的条件查询,不支持范围查询,不适合做索引
- B树
- 叶子节点具有相同的深度,叶子节点的指针为空
- 所有节点中存放的索引不重复
- B树没有双向指针,不容易进行范围查找
- 由于每个节点都存放了数据,会占用一定内存,所以每层存放的数据变少,造成树的高度增加,查找时影响效率
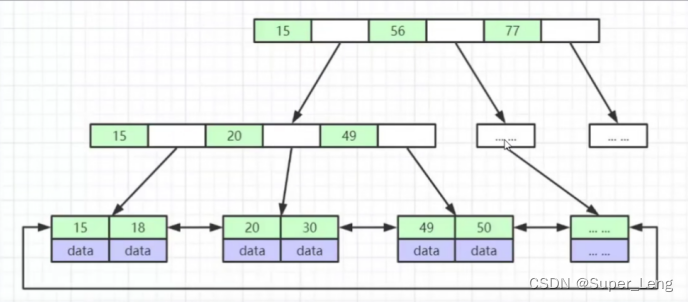
- B+树
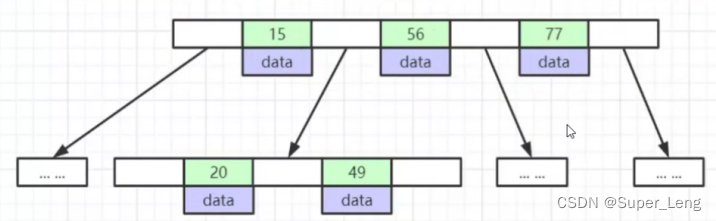
- B+树中非叶子节点的关键字也会同时存在子节点中,并且是在子节点中所有关键字的最大值(或最小)。
- B+树中非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而B树中, 非叶子节点既保存索引,也保存数据记录 。
- B+树中所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序连接,提高区间访问性能。
- 所有数据放叶子节点,每个节点的第一个节点作为冗余索引构建B+树,每层的节点中的数据都是从左到右排好序的
- 上图中空白格存放的是磁盘文件地址,分配的内存空间是6个字节
- 每个叶子结点还会存放相邻叶子节点的磁盘文件地址,这样就可以通过双向链表的指针查找相邻结点的数据
- 首先将根节点加载到内存中,再通过折半查找确定索引的范围,根据范围地址去磁盘加载文件到内存再进行比较,也就是非叶子节点加载到内存,找到叶子节点的位置后,再通过I/O读取
2. 一个B+树中大概能存放多少条索引记录?
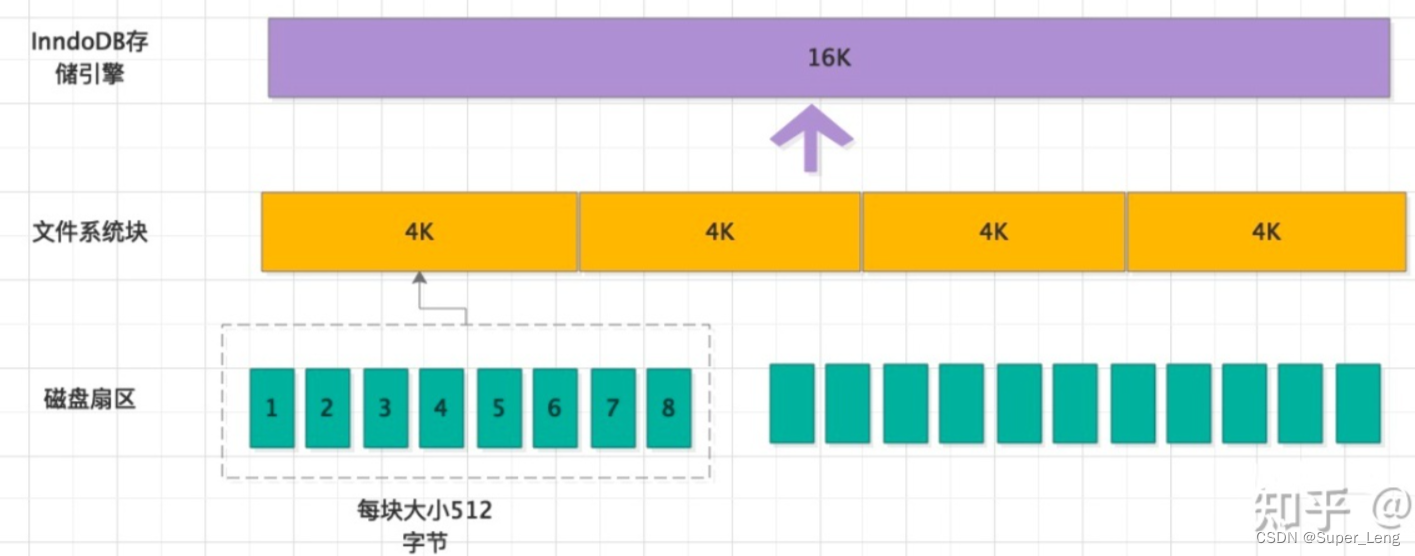
- 数据持久化存储到磁盘里,磁盘的最小单元是扇区,一个扇区的大小是 512个字节
- 文件系统的最小单元是块,一个块的大小是 4K
- InnoDB存储引擎,有自己的最小单元,称之为页,一个页的大小是16K
真实环境中一个页存放的记录数量是非常大的(默认16KB)
- 假设一个页节点存放的指针+键值+其他信息大约10个字节,数据占 1 KB 的空间:
- 如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放 16 条记录。
- 如果B+树有2层,则第一层可以存放大约
16KB/10=1600个指针,最多能存放1600×16=25600条记录。- 如果B+树有3层,最多能存放
1600×1600×16=40960000条记录。所以存储千万级别的数据,只需要三层就够了
B+树的非叶子节点不存储用户记录,只存储目录记录,相对B树每个节点可以存储更多的记录,树的高度会更矮胖,IO次数也会更少。
3. 使用B+树存储的索引crud执行效率如何?
新增 O(lognN),N = 高度
4. 什么是自适应哈希索引?
自适应哈希索引是Innodb引擎的一个特殊功能,当它注意到某些索引值被使用的非常频繁时,会在内存中基于B-Tree索引之上再创建一个哈希索引,这就让B-Tree索引也具有哈希索引的一些优点,比如快速哈希查找。这是一个完全自动的内部行为,用户无法控制或配置。
通过命令 SHOW ENGINE INNODB STATUS \G ;可以看到当前自适应哈希索引的使用状况。
查看INSERT BUFFER AND ADAPTIVE HASH INDEX
5. 什么是2-3树 2-3-4树?
多叉树(multiway tree)允许
每个节点可以有更多的数据项和更多的子节点。2-3树,2-3-4树就是多叉树,多叉树通过重新组织节点,减少节点数量,增加分叉,减少树的高度,能对二叉树进行优化。
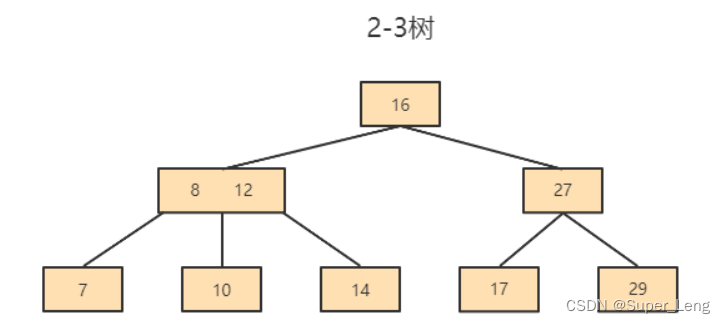
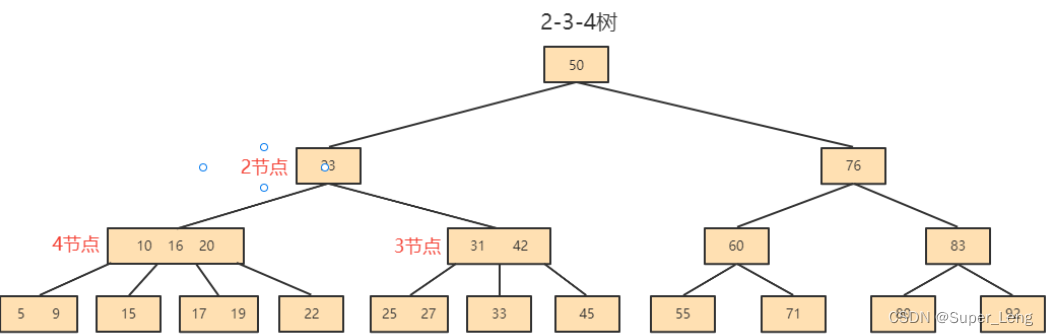
2-3树具有如下特点:
- 2-3树的所有叶子节点都在同一层。
- 有两个子节点的节点叫二节点,二节点要么没有子节点,要么有两个子节点。
- 有三个子节点的节点叫三节点,三节点要么没有子节点,要么有三个子节点。
- 2-3树是由二节点和三节点构成的树。
- 对于三节点的子树的值大小仍然遵守 BST 二叉排序树的规则。
6. 为什么官方建议使用自增长主键作为索引?
- 自增主键能够维持底层数据顺序写入
- 读取可以由B+树的二分查找定位
- 支持范围查找,范围数据自带顺序
字符串无法完成以上操作
7. 使用int自增主键后 最大id是10,删除id 10和9,再添加一条记录,最后添加的id是几?删除后重启mysql然后添加一条记录最后id是几?
删除之后
- 如果重启,会从最大的id开始递增
- 如果没重启,会延续删除之前最大的id开始递增
8. 索引的优缺点是什么?
优点
聚簇(主键)索引:
- 顺序读写
- 范围快速查找
- 范围查找自带顺序
非聚簇索引:
- 条件查询避免全表扫描
- 范围,排序,分组查询返回行id,排序分组后,再回表查询完整数据,有可能利用顺序读写
- 覆盖索引不需要回表操作
索引的代价
索引是个好东西,可不能乱建,它在空间和时间上都会有消耗:
空间上的代价
每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用 16KB 的存储空间,一棵很大的B+树由许多数据页组成,那就是很大的一片存储空间。
时间上的代价
每次对表中的数据进行 增、删、改 操作时,都需要去修改各个B+树索引。而增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位、页面分裂、页面回收等操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+树都要进行相关的维护操作,会给性能拖后腿。
B 树和 B+ 树都可以作为索引的数据结构,在 MySQL 中采用的是 B+ 树。
但B树和B+树各有自己的应用场景,不能说B+树完全比B树好,反之亦然。
9. 使用索引一定能提升效率吗?
不一定
- 少量数据全表扫描也很快,可以直接获取到全量数据
- 唯一索引会影响插入速度,但建议使用
- 索引过多会影响更新,插入,删除数据速度
10. 如果是大段文本内容,如何创建(优化)索引?
第一种方式是分表存储,然后创建索引
第一种方式是使用es为大文本创建索引
11. 什么是聚簇索引?
聚簇索引数据和索引存放在一起组成一个B+树
12. 一个表中可以有多个(非)聚簇索引吗?
聚簇索引只能有一个
非聚簇索引可以有多个
13. CRUD时聚簇索引与非聚簇索引的区别是什么?
- 聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复
- 聚簇索引范围,排序查找效率高,因为是有序的
- 非聚簇索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
14. 非聚簇索引为什么不存数据地址值而存储主键?
因为聚簇索引中有时会引发分页操作、重排操作数据有可能会移动