目录
专栏导读
1 正则表达式概述
2 正则表达式语法
2.1 正则表达式语法元素
2.2 正则表达式的分组操作
3 re 模块详解与示例
4 正则表达式修饰符
专栏导读

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html

1 正则表达式概述
python 的正则表达式是什么,有哪些内容,有什么功能,怎么用?
Python的正则表达式是一种用于处理字符串的强大工具,由re模块提供支持。正则表达式允许你根据特定模式来匹配、搜索、替换和提取文本数据。
正则表达式的基本组成包括:
- 字面字符:普通的字符,例如'a'、'b'等,它们直接匹配相应的字符。
- 元字符:具有特殊含义的字符,例如'.'匹配任意字符、'\d'匹配数字等。
- 限定符:用于指定模式的匹配次数,例如'*'匹配0次或多次、'+'匹配1次或多次等。
- 字符类:用于匹配一组字符中的任意一个字符,例如'[abc]'匹配'a'、'b'或'c'。
- 排除字符:在字符类中使用'^'来排除指定的字符。
- 转义字符:用于匹配特殊字符本身,例如使用'.'匹配实际的点号。
正则表达式在文本处理中有很多功能:
- 模式匹配:查找字符串中是否包含特定的模式。
- 文本搜索:在字符串中搜索匹配模式的第一个出现。
- 查找所有:查找字符串中所有匹配模式的出现,并返回所有匹配结果的列表。
- 分割:根据模式将字符串分割成多个部分。
- 替换:将匹配模式的部分替换为指定的字符串。
以下是一个简单的使用正则表达式的示例:
import re
pattern = r'\d+' # 匹配一个或多个数字
text = "There are 123 apples and 456 oranges."
# 搜索
search_result = re.search(pattern, text)
if search_result:
print("Found:", search_result.group())
# 查找所有
findall_result = re.findall(pattern, text)
print(findall_result) # Output: ['123', '456']
上述代码中,
re.search()函数搜索第一个匹配的数字,而re.findall()函数查找字符串中所有匹配的数字。使用正则表达式时,应当确保模式能够正确匹配目标文本,同时注意处理可能出现的异常情况。熟练掌握正则表达式,可以在文本处理中实现高效和灵活的匹配、搜索和替换操作
2 正则表达式语法
2.1 正则表达式语法元素
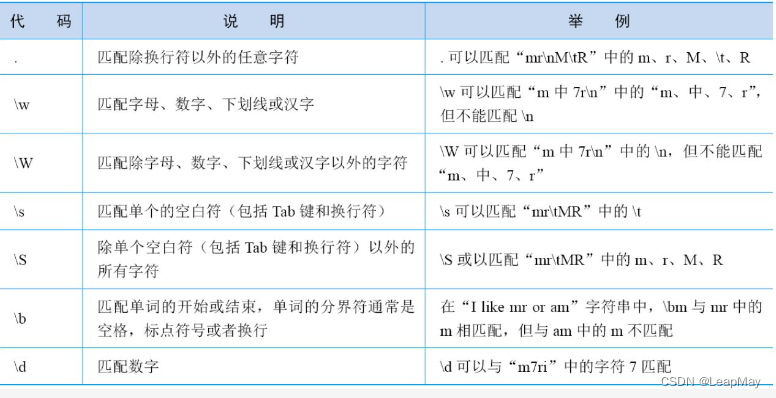
行定位符、元字符、限定符、字符类、排除字符、选择字符和转义字符是正则表达式的基本组成部分,它们用于描述和匹配字符串的模式。
行定位符:
"^":匹配字符串的开头。"$":匹配字符串的结尾。元字符:
".":匹配任意字符(除了换行符)。"\d":匹配任意数字字符,等同于[0-9]。"\D":匹配任意非数字字符,等同于[^0-9]。"\w":匹配任意字母、数字或下划线字符,等同于[a-zA-Z0-9_]。"\W":匹配任意非字母、数字或下划线字符,等同于[^a-zA-Z0-9_]。"\s":匹配任意空白字符,包括空格、制表符、换行符等。"\S":匹配任意非空白字符。限定符:
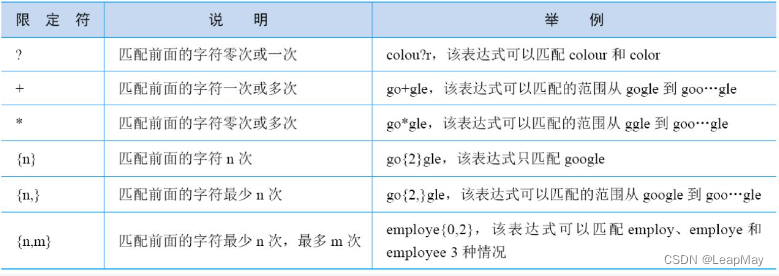
"*":匹配前一个字符零次或多次。"+":匹配前一个字符一次或多次。"?":匹配前一个字符零次或一次。"{n}":匹配前一个字符恰好n次。"{n,}":匹配前一个字符至少n次。"{n, m}":匹配前一个字符至少n次,但不超过m次。字符类:
"[...]":匹配方括号内的任意一个字符。"[^...]":匹配除方括号内的字符之外的任意一个字符。排除字符:
"^":在字符类内使用,表示排除指定字符。选择字符:
"|":逻辑或,匹配两个模式之一。转义字符:
"\":用于转义特殊字符,使其失去特殊含义,例如\.匹配实际的点号这些元字符和特殊符号组合形成了正则表达式的模式,使得正则表达式可以描述非常复杂的字符串匹配规则。要使用正则表达式,你可以使用Python的
re模块提供的函数进行匹配、搜索、替换等操作。熟悉这些基本元素有助于编写更加强大和灵活的正则表达式。
示例:
import re
# 行定位符
pattern1 = r'^Hello' # 匹配以"Hello"开头的字符串
print(re.match(pattern1, "Hello, World!")) # Output: <re.Match object; span=(0, 5), match='Hello'>
pattern2 = r'World$' # 匹配以"World"结尾的字符串
print(re.search(pattern2, "Hello, World!")) # Output: <re.Match object; span=(7, 12), match='World'>
# 元字符
pattern3 = r'a.c' # 匹配"a"、任意字符、"c"
print(re.search(pattern3, "abc")) # Output: <re.Match object; span=(0, 3), match='abc'>
print(re.search(pattern3, "adc")) # Output: <re.Match object; span=(0, 3), match='adc'>
print(re.search(pattern3, "a,c")) # Output: <re.Match object; span=(0, 3), match='a,c'>
pattern4 = r'ab*' # 匹配"a"、"b"出现0次或多次
print(re.search(pattern4, "abbb")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern4, "ac")) # Output: <re.Match object; span=(0, 0), match=''>
pattern5 = r'ab+' # 匹配"a"、"b"出现1次或多次
print(re.search(pattern5, "abbb")) # Output: <re.Match object; span=(0, 4), match='abbb'>
print(re.search(pattern5, "ac")) # Output: None
pattern6 = r'ab?' # 匹配"a"、"b"出现0次或1次
print(re.search(pattern6, "abbb")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern6, "ac")) # Output: <re.Match object; span=(0, 0), match=''>
# 限定符
pattern7 = r'a{3}' # 匹配"a"出现3次
print(re.search(pattern7, "aaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern7, "aaaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern7, "aa")) # Output: None
pattern8 = r'a{3,5}' # 匹配"a"出现3次到5次
print(re.search(pattern8, "aaa")) # Output: <re.Match object; span=(0, 3), match='aaa'>
print(re.search(pattern8, "aaaaa")) # Output: <re.Match object; span=(0, 5), match='aaaaa'>
print(re.search(pattern8, "aaaaaa")) # Output: <re.Match object; span=(0, 5), match='aaaaa'>
# 字符类和排除字符
pattern9 = r'[aeiou]' # 匹配任意一个小写元音字母
print(re.search(pattern9, "apple")) # Output: <re.Match object; span=(0, 1), match='a'>
print(re.search(pattern9, "banana")) # Output: <re.Match object; span=(1, 2), match='a'>
print(re.search(pattern9, "xyz")) # Output: None
pattern10 = r'[^0-9]' # 匹配任意一个非数字字符
print(re.search(pattern10, "hello")) # Output: <re.Match object; span=(0, 1), match='h'>
print(re.search(pattern10, "123")) # Output: None
# 转义字符
pattern11 = r'\.' # 匹配句号
print(re.search(pattern11, "www.example.com")) # Output: <re.Match object; span=(3, 4), match='.'>
# 分组
pattern12 = r'(ab)+' # 匹配"ab"出现1次或多次作为一个整体
print(re.search(pattern12, "ababab")) # Output: <re.Match object; span=(0, 6), match='ababab'>
输出结果显示了匹配的子字符串的起始位置和结束位置,以及匹配的实际字符串内容。
常用元字符
常用限定符
2.2 正则表达式的分组操作
在正则表达式中,分组是一种将多个子模式组合在一起并对其进行单独处理的机制。通过使用括号()来创建分组,可以实现更复杂的匹配和提取操作。
分组的作用包括:
-
优先级控制:可以使用分组来改变子模式的优先级,确保正确的匹配顺序。
-
子模式重用:可以对某个子模式进行命名,并在后续的正则表达式中引用这个名称,实现对同一模式的重用。
-
子模式提取:可以通过分组来提取匹配的子串,方便对其中的内容进行进一步处理。
示例:
import re
text = "John has 3 cats and Mary has 2 dogs."
# 使用分组提取匹配的数字和动物名称
pattern = r'(\d+)\s+(\w+)' # 使用括号创建两个分组:一个用于匹配数字,另一个用于匹配动物名称
matches = re.findall(pattern, text) # 查找所有匹配的结果并返回一个列表
for match in matches:
count, animal = match # 将匹配结果拆分为两个部分:数字和动物名称
print(f"{count} {animal}")
# 使用命名分组
pattern_with_name = r'(?P<Count>\d+)\s+(?P<Animal>\w+)' # 使用命名分组,给子模式指定名称Count和Animal
matches_with_name = re.findall(pattern_with_name, text) # 查找所有匹配的结果并返回一个列表
for match in matches_with_name:
count = match['Count'] # 通过名称获取匹配结果中的数字部分
animal = match['Animal'] # 通过名称获取匹配结果中的动物名称部分
print(f"{count} {animal}")
以上代码演示了如何使用分组提取正则表达式中匹配的子串。第一个正则表达式使用了普通分组,通过括号将数字和动物名称分别提取出来。第二个正则表达式使用了命名分组,通过
(?P<Name>...)的语法形式给子模式指定了名称,从而在匹配结果中可以通过名称获取对应的子串。这样可以使代码更具可读性,方便后续对匹配结果的处理和使用。
3 re 模块详解与示例
re模块是Python中用于处理正则表达式的内置模块,提供了一系列函数来进行字符串匹配、搜索、替换和分割等操作。以下是re模块的主要函数:
re.compile(pattern, flags=0): 编译正则表达式模式,返回一个正则表达式对象。如果要多次使用相同的正则表达式,可以使用这个函数预编译,提高性能。
re.match(pattern, string, flags=0): 尝试从字符串的开头开始匹配模式,如果匹配成功,则返回匹配对象;否则返回None。
re.search(pattern, string, flags=0): 在整个字符串中搜索匹配模式的第一个出现,如果匹配成功,则返回匹配对象;否则返回None。
re.findall(pattern, string, flags=0): 查找字符串中所有匹配模式的出现,返回所有匹配结果的列表。
re.finditer(pattern, string, flags=0): 查找字符串中所有匹配模式的出现,返回一个迭代器,可以通过迭代器获取匹配对象。
re.split(pattern, string, maxsplit=0, flags=0): 根据模式将字符串分割成多个部分,并返回一个列表。
re.sub(pattern, replacement, string, count=0, flags=0): 将匹配模式的部分替换为指定的字符串,并返回替换后的字符串。
在上述函数中,pattern是正则表达式的模式,string是要进行匹配或处理的字符串,flags是可选参数,用于指定正则表达式的修饰符。其中,flags参数可以使用多个修饰符进行组合,例如使用re.IGNORECASE | re.MULTILINE来指定忽略大小写和多行匹配。
以下示例展示了re模块中各种函数的使用,并涵盖了匹配、搜索、替换、分割、命名分组等功能:
import re
text = "John has 3 cats, Mary has 2 dogs."
# 使用re.search()搜索匹配模式的第一个出现
pattern_search = r'\d+\s+\w+'
search_result = re.search(pattern_search, text)
if search_result:
print("Search result:", search_result.group()) # Output: "3 cats"
# 使用re.findall()查找所有匹配模式的出现,并返回一个列表
pattern_findall = r'\d+'
findall_result = re.findall(pattern_findall, text)
print("Find all result:", findall_result) # Output: ['3', '2']
# 使用re.sub()将匹配模式的部分替换为指定的字符串
pattern_sub = r'\d+'
replacement = "X"
sub_result = re.sub(pattern_sub, replacement, text)
print("Sub result:", sub_result) # Output: "John has X cats, Mary has X dogs."
# 使用re.split()根据模式将字符串分割成多个部分
pattern_split = r'\s*,\s*' # 匹配逗号并去除前后空格
split_result = re.split(pattern_split, text)
print("Split result:", split_result) # Output: ['John has 3 cats', 'Mary has 2 dogs.']
# 使用命名分组
pattern_named_group = r'(?P<Name>\w+)\s+has\s+(?P<Count>\d+)\s+(?P<Animal>\w+)'
matches_with_name = re.finditer(pattern_named_group, text)
for match in matches_with_name:
name = match.group('Name')
count = match.group('Count')
animal = match.group('Animal')
print(f"{name} has {count} {animal}")
# 使用re.compile()预编译正则表达式
pattern_compile = re.compile(r'\d+')
matches_compiled = pattern_compile.findall(text)
print("Compiled findall result:", matches_compiled) # Output: ['3', '2']
上述示例展示了使用
re模块进行正则表达式的匹配、搜索、替换、分割和命名分组的功能。注释说明了每个步骤的作用和预期输出,通过合理使用正则表达式,可以快速实现对字符串的复杂处理需求。
4 正则表达式修饰符
在Python的正则表达式中,修饰符(也称为标志或模式标志)是一些可选参数,它们可以在编译正则表达式时传递给re.compile()函数或直接在正则表达式字符串中使用,用于改变匹配的行为。
以下是常用的正则表达式修饰符:
re.IGNORECASE或re.I: 忽略大小写匹配。使用该修饰符后,可以在匹配时忽略大小写的差异。
re.MULTILINE或re.M: 多行匹配。使用该修饰符后,^和$分别匹配字符串的开头和结尾,还可以匹配字符串中每一行的开头和结尾(每行以换行符分隔)。
re.DOTALL或re.S: 单行匹配。使用该修饰符后,.将匹配包括换行符在内的任意字符。
re.ASCII或re.A: 使非ASCII字符只匹配其对应的ASCII字符。例如,\w将只匹配ASCII字母、数字和下划线,而不匹配非ASCII字符。
re.UNICODE或re.U: 使用Unicode匹配。在Python 3中,默认情况下正则表达式使用Unicode匹配。
re.VERBOSE或re.X: 使用“可读性更好”的正则表达式。可以在表达式中添加注释和空格,这样可以使正则表达式更易读。
在Python中,正则表达式修饰符(也称为标志)是可选的参数,用于调整正则表达式的匹配行为。修饰符可以在正则表达式模式的末尾添加,以影响模式的匹配方式。以下是常用的正则表达式修饰符:
下面通过示例来演示这些修饰符的用法:
import re
# 不区分大小写匹配
pattern1 = r'apple'
text1 = "Apple is a fruit."
match1 = re.search(pattern1, text1, re.I)
print(match1.group()) # Output: "Apple"
# 多行匹配
pattern2 = r'^fruit'
text2 = "Fruit is sweet.\nFruit is healthy."
match2 = re.search(pattern2, text2, re.M)
print(match2.group()) # Output: "Fruit"
# 点号匹配所有字符
pattern3 = r'apple.*orange'
text3 = "apple is a fruit.\noranges are fruits."
match3 = re.search(pattern3, text3, re.S)
print(match3.group()) # Output: "apple is a fruit.\noranges"
# 忽略空白和注释
pattern4 = r'''apple # This is a fruit
\s+ # Match one or more whitespace characters
is # followed by "is"
\s+ # Match one or more whitespace characters
a # followed by "a"
\s+ # Match one or more whitespace characters
fruit # followed by "fruit"'''
text4 = "Apple is a fruit."
match4 = re.search(pattern4, text4, re.X)
print(match4.group()) # Output: "apple is a fruit"