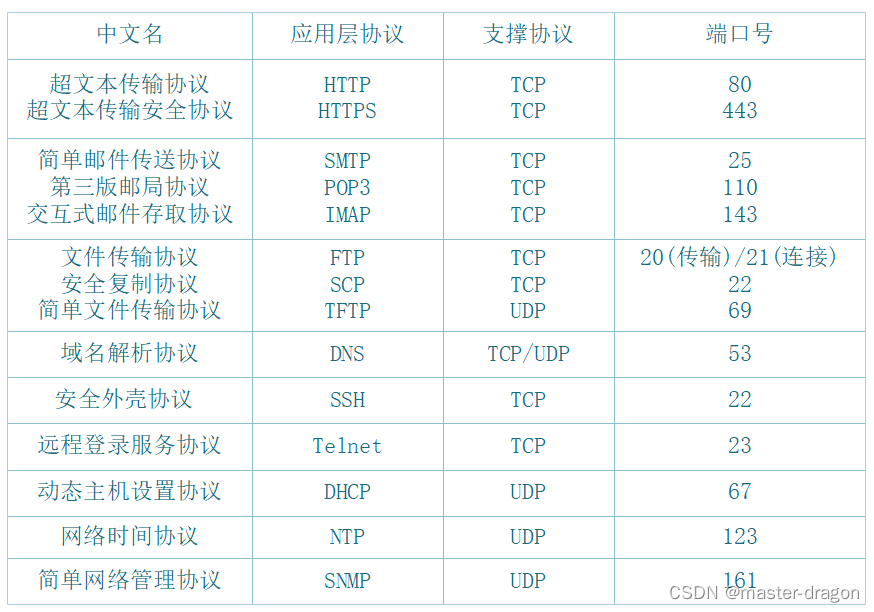
我的代码可以在我的Github找到
GIthub地址
https://github.com/QinghongShao-sqh/Pytorch_Study
因为最近有同学问我如何Nerf入门,这里就简单给出一些我的建议:
(1)基本的pytorch,机器学习,深度学习知识,本文介绍的pytorch知识掌握也差不多. 机器学习、深度学习零基础的话B站吴恩达、李飞飞老师的课都可以看一看。
(2)上面这些掌握后,你就可以直接开始看Nerf论文了,就是2020最早介绍Nerf算法那篇,尝试努力去读吧,包括每个数学公式(大部分公式现在都可以在中文搜索引擎找到其解释),然后通过PaperCode Or Github找到社区同学开源的复现代码,获取(Git or 下载)下来,自己读代码,可以由总到分(先看代码框架,有哪些.py文件,再看哪些类,哪些函数以及各自的功能),然后代码再和论文里面的数学公式、表示去联合理解。到这里你就大概知道Nerf的代码的一个实现流程了。
(3)你在流程2之后,如果你对某一个具体的点不理解的,比如论文不会对模型的方方面面都介绍地很详细(这是不可能的),并且你十分感兴趣这个点or十分倔强一定要搞懂,你就可以针对这个不理解的点,去谷歌等地方多搜索一些资料。 比如NDC空间坐标转换(我前面有篇文章就介绍了,其坐标矩阵是如何转换转换,以及编程的),等等。
(4)在流程3之后,你会有自己更加深刻的理解,包括你在寻找知识过程中,这个探索过程的收获。流程2之后当然也可以,你可以在Papercode上多看几篇nerf相关论文,个人建议20篇(代码都开源的,可以参考star比较多,方便你复现的),这20篇你就可以简单看,看看他们的摘要,介绍,工作结果,图片,以及他们的ProjectWebsite,以及Github代码中对某个模块是如何构造等等。你知道大概Nerf方向有什么工作是在进行,并且进行到哪一步。
(5)最近ICCV2023 CVPR2023应该都出来了,有能力的话也可以在上面找找Nerf相关的,也可以关注一些图形学顶会,然后自己做做总结。后面具体如何基于Nerf展开研究,就是每个实验室的工作了。
(6)最后,现在已经是2023年8月份了,从Nerf2020年出来后到今天,Nerf应该算比较流行并且基本的一个模型了,类似CNN,ResNet等等,对研究生甚至本科生来说,应该不会是比较难学的一个算法模型,因为很多资料(视频、文章)、Github代码块都有其相关的工作,入门介绍等等。所以看到这里,新手不应该畏难,应该感到有幸运(谁知道当时csdn关于他的介绍都是一些第三方机构的付费课,还不是nerf相关的),如果你掌握了Nerf,也不用太骄傲,最近几年的Nerf相关论文工作也是真的爆炸增长,(论文投稿某顶会多次被拒( Ĭ ^ Ĭ )) 看到这里,祝大家学习之路加油!
本文将回答下面的几个问题:
(1)不构建计算图、手动实现梯度计算、手动SGD更新参数
(2)数据张量和参数张量不分离、自动计算梯度、手动SGD更新参数
(3)数据张量和参数张量不分离、自动计算梯度、手动SGD更新参数
(4)数据张量和参数张量不分离、自动计算梯度、使用Adam优化算法自动更新参数
(5)自定义操作(需手动实现前向传播、反向传播)
(6)自定义Module
(7)control flow + weight sharing
参考地址:Pytorch官方教程,强烈推荐
https://link.zhihu.com/?target=https%3A//pytorch.org/tutorials/beginner/pytorch_with_examples.html
(1)使用Numpy来编写神经网络
# Define the dimensions and sizes of the data. N represents the batch size, H represents the dimension of the hidden layer, D_in represents the input dimension, and D_out represents the output dimension
N, H, D_in, D_out= 64, 100, 1000, 10
#Generate random input data with N rows and D_in columns.
x = np.random.randn(N,D_in)
#Generate random input data with N rows and D_out columns.
y = np.random.randn(N,D_out)
#Randomly initialize the weights of the first layer, setting its dimensions to D_in rows and H columns.
w1 = np.random.randn(D_in,H)
#Randomly initialize the weights of the second layer, setting its dimensions to H rows and D_out columns.
w2 = np.random.randn(H,D_out)
# Set the learning rate
learning_rate =1e-6
# Start the iterative training process for 500 iterations.
for t in range(500):
# Compute the output of the first layer by multiplying the input data x with the weights w1 using matrix multiplication.
# 计算第一层的输出,使用矩阵乘法将输入数据x与第一层权重w1相乘
h =x.dot(w1)
# Apply the ReLU activation function, setting negative values to zero.
h_relu = np.maximum(h,0)
# Compute the predictions of the output layer by multiplying the output of the first layer, h_relu, with the weights of the second layer, w2.
y_pred = h_relu.dot(w2)
#Calculate the loss function using the sum of squared differences between the predictions and the true values.
loss = np.square(y_pred - y).sum()
print(t,loss)
# Compute the gradients of the loss function with respect to the predictions, multiplied by 2 for convenience.
grad_y_pred = 2.0 * (y_pred - y)
# Compute the gradients of the loss function with respect to the weights of the second layer using transposed matrix multiplication
grad_w2 = h_relu.T.dot(grad_y_pred)
# Compute the gradients of the loss function with respect to the output of the first layer using transposed matrix multiplication.
grad_h_relu = grad_y_pred.dot(w2.T)
# Make a copy of the gradients of the output of this first layer
grad_h = grad_h_relu.copy()
#Set the gradients of the output of the first layer to zero where the output is less than zero, effectively applying the derivative of the ReLU function
grad_h[h < 0] = 0
#Compute the gradients of the loss function with respect to the weights of the first layer using transposed matrix multiplication.
grad_w1 = x.T.dot(grad_h)
#Update the weights of the first layer using gradient descent
w1 -= learning_rate * grad_w1
#Update the weights of the second layer using gradient descent.
w2 -= learning_rate * grad_w2
''' Chinese explaination
import numpy as np:导入NumPy库,用于进行数值计算。
N, H, D_in, D_out = 64, 100, 1000, 10:定义了数据的维度和大小。N表示批处理的大小,H表示隐藏层的维度,D_in表示输入的维度,D_out表示输出的维度。
x = np.random.randn(N, D_in):生成一个N行D_in列的随机输入数据。
y = np.random.randn(N, D_out):生成一个N行D_out列的随机输出数据。
w1 = np.random.randn(D_in, H):随机初始化第一层权重,将其维度设置为D_in行H列。
w2 = np.random.randn(H, D_out):随机初始化第二层权重,将其维度设置为H行D_out列。
learning_rate = 1e-6:设置学习率。
for t in range(500)::开始进行迭代训练,共进行500次。
h = x.dot(w1):计算第一层的输出,使用矩阵乘法将输入数据x与第一层权重w1相乘。
h_relu = np.maximum(h, 0):激活函数ReLU,将负值变为0。
y_pred = h_relu.dot(w2):计算输出层的预测结果,将第一层的输出h_relu与第二层的权重w2相乘。
loss = np.square(y_pred - y).sum():计算损失函数,使用均方差来度量预测结果与真实结果之间的差异。
grad_y_pred = 2.0 * (y_pred - y):计算损失函数对预测结果的梯度,乘以2是为了方便后续计算。
grad_w2 = h_relu.T.dot(grad_y_pred):计算损失函数对第二层权重的梯度,使用转置矩阵乘法。
grad_h_relu = grad_y_pred.dot(w2.T):计算损失函数对第一层输出的梯度,使用转置矩阵乘法。
grad_h = grad_h_relu.copy():将第一层输出的梯度复制一份。
grad_h[h < 0] = 0:将第一层输出小于0的梯度置为0,相当于ReLU的导数。
grad_w1 = x.T.dot(grad_h):计算损失函数对第一层权重的梯度,使用转置矩阵乘法。
w1 -= learning_rate * grad_w1:更新第一层权重,使用梯度下降法进行更新。
w2 -= learning_rate * grad_w2:更新第二层权重,同样使用梯度下降法进行更新。
(2)用Pytorch实现神经网络
import torch
#Sets the data type to float.
dtype = torch.float
#Sets the computation device to CPU
device = torch.device("cpu")
#Defines the dimensions and sizes of the data. N represents the batch size, H represents the dimension of the hidden layer, D_in represents the input dimension, and D_out represents the output dimension.
N, H, D_in, D_out= 64, 100, 1000, 10
#Generates a random input tensor of size N rows and D_in columns
x = torch.randn(N,D_in,device =device,dtype=dtype)
#Generates a random output tensor of size N rows and D_out columns
y = torch.randn(N,D_out,device=device,dtype=dtype)
#Randomly initializes the weights tensor of the first layer with dimensions D_in rows and H columns.
w1 = torch.randn(D_in,H,device=device,dtype=dtype)
#Randomly initializes the weights tensor of the first layer with dimensions D_in rows and H columns.
w2 = torch.randn(N,D_out,device=device,dtype=dtype)
#Sets the learning rate.
learning_rate = 1e-6
#Starts the training iteration for 500 iterations.
for t in range(500):
#Performs matrix multiplication between the input tensor x and the weights tensor w1 to compute the output tensor h of the first layer.
h =x.mm(w1)
#Applies the clamp function to set all elements in tensor h that are less than 0 to 0, implementing the ReLU activation function.
h_relu = h.clamp(min = 0)
#Performs matrix multiplication between the output tensor h_relu of the first layer and the weights tensor w2 to compute the predicted output tensor y_pred
y_pred = h_relu.mm(w2)
#Computes the loss function using mean squared error to measure the difference between the predicted output and the true output.
loss = (y_pred - y).pow(2).sum().item()
#Prints the current iteration number and loss value every 100 iterations.
if t % 100 == 99:
print(t , loss)
#Computes the gradient of the loss function with respect to the predicted output tensor. Multiplying by 2.0 is for convenience in the subsequent calculations
grad_y_pred = 2.0* (y_pred -y)
#Computes the gradient of the loss function with respect to the weights tensor w2 of the second layer using transpose matrix multiplication
grad_w2 = h_relu.t().mm(grad_y_pred)
#Computes the gradient of the loss function with respect to the output tensor h_relu of the first layer using transpose matrix multiplication.
grad_h_relu = grad_y_pred.mm(w2.t())
#Creates a copy of the gradient of the output tensor of the first layer
grad_h = grad_h_relu.clone()
#Sets the gradients in the output tensor of the first layer that are less than 0 to 0, implementing the derivative of the ReLU function
grad_h[h<0] = 0
#Computes the gradient of the loss function with respect to the weights tensor w1 of the first layer using transpose matrix multiplication
grad_w1 = x.t().mm(grad_h)
#Updates the weights tensor of the first layer using gradient descent.
w1 -= learning_rate * grad_w1
#Updates the weights tensor of the second layer using gradient descent
w2 -=learning_rate *grad_w2
'''
import torch:导入PyTorch库。
dtype = torch.float:设置数据类型为浮点型。
device = torch.device("cpu"):将计算设备设置为CPU。
N, H, D_in, D_out = 64, 100, 1000, 10:定义了数据的维度和大小。N表示批处理的大小,H表示隐藏层的维度,D_in表示输入的维度,D_out表示输出的维度。
x = torch.randn(N, D_in, device=device, dtype=dtype):生成一个N行D_in列的随机输入张量。
y = torch.randn(N, D_out, device=device, dtype=dtype):生成一个N行D_out列的随机输出张量。
w1 = torch.randn(D_in, H, device=device, dtype=dtype):随机初始化第一层权重张量,将其维度设置为D_in行H列。
w2 = torch.randn(H, D_out, device=device, dtype=dtype):随机初始化第二层权重张量,将其维度设置为H行D_out列。
learning_rate = 1e-6:设置学习率。
for t in range(500)::开始进行迭代训练,共进行500次。
h = x.mm(w1):使用矩阵乘法将输入张量x与第一层权重张量w1相乘,计算第一层的输出张量h。
h_relu = h.clamp(min=0):使用clamp函数将张量h中小于0的元素设置为0,实现ReLU激活函数。
y_pred = h_relu.mm(w2):使用矩阵乘法将第一层的输出张量h_relu与第二层权重张量w2相乘,计算输出层的预测结果张量y_pred。
loss = (y_pred - y).pow(2).sum().item():计算损失函数,使用均方差来度量预测结果与真实结果之间的差异。
if t % 100 == 99::每100个迭代打印一次当前迭代的编号和损失值。
grad_y_pred = 2.0 * (y_pred - y):计算损失函数对预测结果张量的梯度,乘以2是为了方便后续计算。
grad_w2 = h_relu.t().mm(grad_y_pred):计算损失函数对第二层权重张量的梯度,使用转置矩阵乘法。
grad_h_relu = grad_y_pred.mm(w2.t()):计算损失函数对第一层输出张量的梯度,使用转置矩阵乘法。
grad_h = grad_h_relu.clone():复制第一层输出张量的梯度。
grad_h[h < 0] = 0:将第一层输出张量中小于0的梯度置为0,实现ReLU函数的导数。
grad_w1 = x.t().mm(grad_h):计算损失函数对第一层权重张量的梯度,使用转置矩阵乘法。
w1 -= learning_rate * grad_w1:使用梯度下降法更新第一层权重张量。
w2 -= learning_rate * grad_w2:使用梯度下降法更新第二层权重张量。
在每次迭代中,计算前向传播,计算损失函数,然后进行反向传播来更新权重,以此来训练神经网络模型。
'''
(3)AutoGrad 自动求导
这段代码实现了一个简单的两层全连接神经网络的训练过程,包括前向传播、计算损失、反向传播更新权重
import torch
dtype = torch.float
device = torch.device("cpu")
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
#Perform the forward pass calculation. First, multiply the input tensor x with the weight tensor w1 using matrix multiplication. Then, use the clamp function to set any values less than 0 to 0. Finally, perform matrix multiplication with the weight tensor w2 to obtain the predicted output tensor y_pred.
y_pred = x.mm(w1).clamp(min=0).mm(w2)
#Calculate the loss function, using mean square error to measure the difference between the predicted output and the true output.
loss = (y_pred - y).pow(2).sum()
#Print the current iteration number and the loss value every 100 iterations
if t % 100 == 99:
print(t, loss.item())
#Enter the context of no gradient calculation to update the weights without calculating gradients.
with torch.no_grad():
#Update the weight tensor for the first layer using gradient descent
w1 -= learning_rate * w1.grad
#Update the weight tensor for the second layer using gradient descent.
w2 -= learning_rate * w2.grad
#Reset the gradient tensor for the weights of the first layer to zero.
w1.grad.zero_()
#Reset the gradient tensor for the weights of the second layer to zero.
w2.grad.zero_()
'''
import torch:导入PyTorch库。
dtype = torch.float:将数据类型设置为float。
device = torch.device("cpu"):将计算设备设置为CPU。
N, D_in, H, D_out = 64, 1000, 100, 10:定义数据的维度和大小。N表示批量大小,D_in表示输入维度,H表示隐藏层维度,D_out表示输出维度。
x = torch.randn(N, D_in, device=device, dtype=dtype):生成一个大小为N行D_in列的随机输入张量。
y = torch.randn(N, D_out, device=device, dtype=dtype):生成一个大小为N行D_out列的随机输出张量。
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True):随机初始化第一层的权重张量,大小为D_in行H列,并设置requires_grad=True以便计算梯度。
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True):随机初始化第二层的权重张量,大小为H行D_out列,并设置requires_grad=True以便计算梯度。
learning_rate = 1e-6:设置学习率。
for t in range(500)::开始进行500次训练迭代。
y_pred = x.mm(w1).clamp(min=0).mm(w2):进行前向传播计算。首先,通过矩阵乘法将输入张量x与第一层的权重张量w1相乘,然后使用clamp函数将结果中小于0的元素设置为0,最后再与第二层的权重张量w2进行矩阵乘法运算,得到预测的输出张量y_pred。
loss = (y_pred - y).pow(2).sum():计算损失函数,使用均方差衡量预测输出与真实输出之间的差异。
if t % 100 == 99::每100次迭代打印当前迭代次数和损失值。
with torch.no_grad()::进入无梯度计算的上下文,以便更新权重时不计算梯度。
w1 -= learning_rate * w1.grad:使用梯度下降法更新第一层的权重张量。
w2 -= learning_rate * w2.grad:使用梯度下降法更新第二层的权重张量。
w1.grad.zero_():将第一层的权重梯度张量重置为零。
w2.grad.zero_():将第二层的权重梯度张量重置为零。
这段代码实现了一个简单的两层全连接神经网络的训练过程,包括前向传播、计算损失、反向传播更新权重。
'''
(4)定义自动求导的AutoGrad函数
以下代码自定义了autograd操作ReLU非线性层,并使用它实现我们的2层神经网络:
#以下代码自定义了autograd操作ReLU非线性层,并使用它实现我们的2层神经网络:
import torch
class MyReLU(torch.autograd.Function):
#Indicates that the following function is a static method, which can be called without creating an instance.
@staticmethod
#Forward propagation function that takes input and returns the output.
def forward(ctx,input):
#Saves the input tensor in the context for later use in backward propagation.
ctx.save_for_backward(input)
#Applies the ReLU operation to the input tensor, setting values less than 0 to 0, and returns the result.
return input.clamp(min=0)
@staticmethod
# Backward propagation function that takes the gradient output and returns the gradient input.
def backward(ctx,grad_output):
#Retrieves the input tensor from the saved context.
input, = ctx.saved_tensors
#Clones the gradient output to modify it.
grad_input = grad_output.clone()
#Sets the gradient to 0 for positions where the input is less than 0.
grad_input[input < 0] = 0
#Returns the modified gradient input.
return grad_input
dtype = torch.float
device = torch.device("cpu")
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
#Creates an instance of the ReLU function.
relu = MyReLU.apply
#Performs forward propagation. First, it performs matrix multiplication between the input tensor x and the first layer weight tensor w1, and passes the result through the ReLU function. Then, it performs matrix multiplication between the output of the ReLU function and the second layer weight tensor w2, resulting in the predicted output tensor y_pred.
y_pred = relu(x.mm(w1)).mm(w2)
#Calculates the loss function, which measures the squared difference between the predicted output and the true output.
loss = (y_pred).pow(2).sum()
if t % 100 == 99:
print(t, loss.item())
#Performs backward propagation to calculate gradients.
loss.backward()
#Enters a context where gradients are not computed, allowing for updating the weights without gradient calculations.
with torch.no_grad():
#Updates the first layer weight tensor using gradient descent.
w1 -= learning_rate* w1.grad
#Updates the second layer weight tensor using gradient descent.
w2 -= learning_rate * w2.requires_grad
#Sets the gradient of the first layer weight tensor to zero.
w1.grad.zero_()
#Sets the gradient of the second layer weight tensor to zero
w1.grad.zero_()
'''
class MyReLU(torch.autograd.Function): 声明一个自定义的ReLU函数类,继承自torch.autograd.Function。
@staticmethod: 表示下面的函数是静态方法,可以在没有创建实例的情况下调用。
def forward(ctx, input): 前向传播函数,接受输入并返回结果。
ctx.save_for_backward(input): 在上下文中保存输入张量,以便在反向传播时使用。
return input.clamp(min=0): 对输入张量进行ReLU操作,将小于0的值设为0,返回结果。
def backward(ctx, grad_output): 反向传播函数,接受梯度输出并返回梯度输入。
input, = ctx.saved_tensors: 从保存的上下文中提取输入张量。
grad_input = grad_output.clone(): 克隆梯度输出,以便对其进行修改。
grad_input[input < 0] = 0: 将小于0的输入位置的梯度设为0。
return grad_input: 返回修改后的梯度输入。
dtype = torch.float: 设置张量的数据类型为浮点型。
device = torch.device("cpu"): 设置计算设备为CPU。
N, D_in, H, D_out = 64, 1000, 100, 10: 定义数据的维度和大小。
x = torch.randn(N, D_in, device=device, dtype=dtype): 生成一个随机输入张量。
y = torch.randn(N, D_out, device=device, dtype=dtype): 生成一个随机输出张量。
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True): 随机初始化第一层权重张量,并设置requires_grad=True以便计算梯度。
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True): 随机初始化第二层权重张量,并设置requires_grad=True以便计算梯度。
learning_rate = 1e-6: 设置学习率。
for t in range(500):: 开始训练循环,执行500次迭代。
relu = MyReLU.apply: 创建一个ReLU函数的实例。
y_pred = relu(x.mm(w1)).mm(w2): 执行前向传播计算。首先,使用输入张量x和第一层权重张量w1进行矩阵乘法,并将结果传递给ReLU函数。然后,将ReLU函数的输出和第二层权重张量w2进行矩阵乘法,得到预测的输出张量y_pred。
loss = (y_pred).pow(2).sum(): 计算损失函数,使用平方差来衡量预测输出和真实输出之间的差异。
if t % 100 == 99:: 每100次迭代打印当前迭代次数和损失值。
loss.backward(): 执行反向传播,计算梯度。
with torch.no_grad():: 进入上下文,不计算梯度,以便在更新权重时不进行梯度计算。
w1 -= learning_rate * w1.grad: 使用梯度下降更新第一层权重张量。
w2 -= learning_rate * w2.requires_grad: 使用梯度下降更新第二层权重张量。
w1.grad.zero_(): 将第一层权重张量的梯度设为零。
w1.grad.zero_(): 将第二层权重张量的梯度设为零。
'''
(5)Pytorch.nn 构建神经网络
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
#Create a Sequential model that sequentially contains a linear layer, ReLU activation function, and another linear layer.
model = torch.nn.Sequential(
#Define a linear layer that maps the input dimension D_in to the hidden layer dimension H.
torch.nn.Linear(D_in,H),
#Define a ReLU activation function.
torch.nn.ReLU(),
#Define a linear layer that maps the hidden layer dimension H to the output dimension D_out.
torch.nn.Linear(H,D_out),
)
#Define a mean squared error loss function to compute the difference between predicted output and true output.
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
for t in range(500):
#Perform forward propagation by passing the input tensor x to the model to get the predicted output tensor y_pred.
y_pred = model(x)
#Compute the loss function using mean squared error to measure the difference between predicted output and true output.
loss = loss_fn(y_pred,y)
if t%100 == 99:
print(t,loss.item)
# Clear all gradients of the model.
model.zero_grad()
#Perform backward propagation to compute gradients.
loss.backward()
#Perform backward propagation to compute gradients.
with torch.no_grad():
#Iterate over each parameter of the model.
for param in model.parameters():
# Update the parameters using gradient descent.
param -= learning_rate * param.grad
'''
import torch: 导入PyTorch库。
N, D_in, H, D_out = 64, 1000, 100, 10: 定义数据的维度和大小。
x = torch.randn(N, D_in): 生成一个随机输入张量x。
y = torch.randn(N, D_out): 生成一个随机输出张量y。
model = torch.nn.Sequential(...): 创建一个Sequential模型,按顺序包含线性层、ReLU激活函数和线性层。
torch.nn.Linear(D_in,H): 定义一个线性层,将输入维度D_in映射到隐藏层维度H。
torch.nn.ReLU(): 定义一个ReLU激活函数。
torch.nn.Linear(H,D_out): 定义一个线性层,将隐藏层维度H映射到输出维度D_out。
loss_fn = torch.nn.MSELoss(reduction='sum'): 定义一个均方误差损失函数,用于计算预测输出和真实输出之间的差异。
learning_rate = 1e-4: 设置学习率。
for t in range(500):: 开始训练循环,执行500次迭代。
y_pred = model(x): 执行前向传播计算,将输入张量x传递给模型,得到预测输出张量y_pred。
loss = loss_fn(y_pred,y): 计算损失函数,使用均方误差来衡量预测输出和真实输出之间的差异。
if t%100 == 99:: 每100次迭代打印当前迭代次数和损失值。
model.zero_grad(): 清空模型的所有梯度。
loss.backward(): 执行反向传播,计算梯度。
with torch.no_grad():: 进入上下文,不计算梯度,以便在更新参数时不进行梯度计算。
for param in model.parameters():: 对模型的每个参数进行迭代。
param -= learning_rate * param.grad: 使用梯度下降更新参数。
'''
(6)优化器,Optim
这段代码使用了PyTorch的神经网络库(torch.nn)和损失函数库(torch.nn.functional),以及优化器(torch.optim)来自动更新模型参数。新加入的部分是优化器的定义和在训练循环中使用优化器的zero_grad()、backward()和step()函数来执行梯度清零、反向传播和参数更新的步骤
import torch
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
#Define an Adam optimizer to update the model parameters.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
'''
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad'''
for t in range(500):
y_pred = model(x)
# Compute and print loss.
loss = loss_fn(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''
import torch: 导入PyTorch库。
N, D_in, H, D_out = 64, 1000, 100, 10: 定义数据的维度和大小。
x = torch.randn(N, D_in): 生成一个随机输入张量x。
y = torch.randn(N, D_out): 生成一个随机输出张量y。
model = torch.nn.Sequential(...): 创建一个Sequential模型,按顺序包含线性层、ReLU激活函数和线性层。
torch.nn.Linear(D_in, H): 定义一个线性层,将输入维度D_in映射到隐藏层维度H。
torch.nn.ReLU(): 定义一个ReLU激活函数。
torch.nn.Linear(H, D_out): 定义一个线性层,将隐藏层维度H映射到输出维度D_out。
loss_fn = torch.nn.MSELoss(reduction='sum'): 定义一个均方误差损失函数,用于计算预测输出和真实输出之间的差异。
learning_rate = 1e-4: 设置学习率。
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate): 定义一个Adam优化器,用于更新模型参数。
for t in range(500):: 开始训练循环,执行500次迭代。
y_pred = model(x): 执行前向传播计算,将输入张量x传递给模型,得到预测输出张量y_pred。
loss = loss_fn(y_pred, y): 计算损失函数,使用均方误差来衡量预测输出和真实输出之间的差异。
if t % 100 == 99:: 每100次迭代打印当前迭代次数和损失值。
optimizer.zero_grad(): 清空优化器的梯度。
loss.backward(): 执行反向传播,计算梯度。
optimizer.step(): 使用优化器来更新模型参数。
这段代码使用了PyTorch的神经网络库(torch.nn)和损失函数库(torch.nn.functional),以及优化器(torch.optim)来自动更新模型参数。新加入的部分是优化器的定义和在训练循环中使用优化器的zero_grad()、backward()和step()函数来执行梯度清零、反向传播和参数更新的步骤。
'''
(7)PyTorch: Custom nn Modules
这段代码定义了一个简单的两层神经网络模型,使用自定义的TwoLayerNet类继承了torch.nn.Module类,并通过重写forward函数实现了前向传播逻辑。训练循环中的步骤与前面的代码相似,包括前向传播、计算损失、梯度清零、反向传播和参数更新。不同之处在于使用的模型、损失函数和优化器
import torch
class TwoLayerNet(torch.nn.Module):
#Defines the initialization function of the TwoLayerNet class, which takes input dimension D_in, hidden layer dimension H, and output dimension D_out as parameters.
def __init__(self, D_in, H, D_out):
#Calls the initialization function of the parent class (torch.nn.Module).
super(TwoLayerNet, self).__init__()
#Creates a linear layer within the TwoLayerNet class that maps the input dimension D_in to the hidden layer dimension H.
self.linear1 = torch.nn.Linear(D_in, H)
# Creates another linear layer within the TwoLayerNet class that maps the hidden layer dimension H to the output dimension D_out.
self.linear2 = torch.nn.Linear(H, D_out)
#Defines the forward propagation function of the TwoLayerNet class, which takes input tensor x as a parameter.
def forward(self, x):
#Performs forward propagation of the first linear layer and then applies the clamp function to clip its output to non-negative values
h_relu = self.linear1(x).clamp(min=0)
#Performs forward propagation of the second linear layer, taking the output of the first linear layer as input.
y_pred = self.linear2(h_relu)
#Returns the predicted output tensor y_pred.
return y_pred
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
#Creates an instance of the TwoLayerNet class, i.e., a model object.
model = TwoLayerNet(D_in, H, D_out)
#Defines a mean squared error loss function to compute the difference between the predicted output and the true output.
criterion = torch.nn.MSELoss(reduction='sum')
#Defines a stochastic gradient descent (SGD) optimizer to update the model parameters.
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
for t in range(500):
y_pred = model(x)
#Computes the loss function, using mean squared error to measure the difference between the predicted output and the true output.
loss = criterion(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''
class TwoLayerNet(torch.nn.Module):: 定义一个名为TwoLayerNet的自定义神经网络类,继承自torch.nn.Module。
def __init__(self, D_in, H, D_out):: 定义TwoLayerNet类的初始化函数,接收输入维度D_in、隐藏层维度H和输出维度D_out作为参数。
super(TwoLayerNet, self).__init__(): 调用父类(torch.nn.Module)的初始化函数。
self.linear1 = torch.nn.Linear(D_in, H): 在TwoLayerNet类中创建一个线性层,将输入维度D_in映射到隐藏层维度H。
self.linear2 = torch.nn.Linear(H, D_out): 在TwoLayerNet类中创建另一个线性层,将隐藏层维度H映射到输出维度D_out。
def forward(self, x):: 定义TwoLayerNet类的前向传播函数,接收输入张量x作为参数。
h_relu = self.linear1(x).clamp(min=0): 执行第一个线性层的前向传播,然后使用clamp函数将其结果裁剪为非负值。
y_pred = self.linear2(h_relu): 执行第二个线性层的前向传播,将第一个线性层的输出作为输入。
return y_pred: 返回预测输出张量y_pred。
N, D_in, H, D_out = 64, 1000, 100, 10: 定义数据的维度和大小。
x = torch.randn(N, D_in): 生成一个随机输入张量x。
y = torch.randn(N, D_out): 生成一个随机输出张量y。
model = TwoLayerNet(D_in, H, D_out): 创建一个TwoLayerNet类的实例,即一个模型对象。
criterion = torch.nn.MSELoss(reduction='sum'): 定义一个均方误差损失函数,用于计算预测输出和真实输出之间的差异。
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4): 定义一个随机梯度下降(SGD)优化器,用于更新模型参数。
for t in range(500):: 开始训练循环,执行500次迭代。
y_pred = model(x): 执行模型的前向传播计算,将输入张量x传递给模型,得到预测输出张量y_pred。
loss = criterion(y_pred, y): 计算损失函数,使用均方误差来衡量预测输出和真实输出之间的差异。
if t % 100 == 99:: 每100次迭代打印当前迭代次数和损失值。
optimizer.zero_grad(): 清空优化器的梯度。
loss.backward(): 执行反向传播,计算梯度。
optimizer.step(): 使用优化器来更新模型参数。
这段代码定义了一个简单的两层神经网络模型,使用自定义的TwoLayerNet类继承了torch.nn.Module类,并通过重写forward函数实现了前向传播逻辑。训练循环中的步骤与前面的代码相似,包括前向传播、计算损失、梯度清零、反向传播和参数更新。不同之处在于使用的模型、损失函数和优化器'''
(8)一个动态的神经网络模型,
使用自定义的DynamicNet类继承了torch.nn.Module类,并通过重写forward函数实现了前向传播逻辑。训练循环中的步骤与前面的代码相似,包括前向传播、计算损失、梯度清零、反向传播和参数更新。不同之处在于使用的模型、损失函数、优化器以及引入了随机循环的隐藏层。
import random
import torch
'''
一个全连接ReLU网络,每次前向传播都选取一个1-4之间的随机数n,
我们将hidden layers的数量设置为n,也就是重复调用一个中间层n次,复用它的参数。'''
"""
For the forward pass of the model, we randomly choose either 0, 1, 2, or 3
and reuse the middle_linear Module that many times to compute hidden layer
representations.
Since each forward pass builds a dynamic computation graph, we can use normal
Python control-flow operators like loops or conditional statements when
defining the forward pass of the model.
Here we also see that it is perfectly safe to reuse the same Module many
times when defining a computational graph. This is a big improvement from Lua
Torch, where each Module could be used only once.
"""
class DynamicNet(torch.nn.Module):
#Defines the initialization function of the DynamicNet class, which takes input dimension D_in, hidden dimension H, and output dimension D_out as parameters.
def __init__(self, D_in, H, D_out):
#Calls the initialization function of the parent class (torch.nn.Module).
super(DynamicNet, self).__init__()
#creates a linear layer within the DynamicNet class that maps the input dimension D_in to the hidden dimension H.
self.input_linear = torch.nn.Linear(D_in, H)
#ates a linear layer within the DynamicNet class that maps the input dimension D_in to the hidden dimension H.
self.middle_linear = torch.nn.Linear(H, H)
#Creates another linear layer within the DynamicNet class that maps the hidden dimension H to the output dimension D_out.
self.output_linear = torch.nn.Linear(H, D_out)
#Creates another linear layer within the DynamicNet class that maps the hidden dimension H to the output dimension D_out.
def forward(self, x):
#Creates another linear layer within the DynamicNet class that maps the hidden dimension H to the output dimension D_out.
h_relu = self.input_linear(x).clamp(min=0)
#Performs a random number of iterations between hidden layers, where each iteration performs a forward propagation of a hidden layer.
for _ in range(random.randint(0, 3)):
#Performs the forward propagation of the hidden layer linear layer and then applies the clamp function to clip its result to non-negative values.
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
#Performs the forward propagation of the output linear layer, taking the output of the last hidden layer as input.
return y_pred
N, D_in, H, D_out = 64, 1000, 100, 10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = DynamicNet(D_in, H, D_out)
#Defines a mean squared error loss function to compute the difference between the predicted output and the true output.
criterion = torch.nn.MSELoss(reduction='sum')
#Defines a stochastic gradient descent (SGD) optimizer with momentum to update the model parameters.
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
for t in range(500):
y_pred = model(x)
#Computes the loss function, using mean squared error to measure the difference between the predicted output and the true output
loss = criterion(y_pred, y)
if t % 100 == 99:
print(t, loss.item())
#Clears the gradients of the optimizer.
optimizer.zero_grad()
#Performs the backward propagation to compute the gradients.
loss.backward()
#Updates the model parameters using the optimizer.
optimizer.step()
'''
class DynamicNet(torch.nn.Module):: 定义一个名为DynamicNet的自定义神经网络类,继承自torch.nn.Module。
def __init__(self, D_in, H, D_out):: 定义DynamicNet类的初始化函数,接收输入维度D_in、隐藏层维度H和输出维度D_out作为参数。
super(DynamicNet, self).__init__(): 调用父类(torch.nn.Module)的初始化函数。
self.input_linear = torch.nn.Linear(D_in, H): 在DynamicNet类中创建一个线性层,将输入维度D_in映射到隐藏层维度H。
self.middle_linear = torch.nn.Linear(H, H): 在DynamicNet类中创建另一个线性层,将隐藏层维度H映射到隐藏层维度H。
self.output_linear = torch.nn.Linear(H, D_out): 在DynamicNet类中创建另一个线性层,将隐藏层维度H映射到输出维度D_out。
def forward(self, x):: 定义DynamicNet类的前向传播函数,接收输入张量x作为参数。
h_relu = self.input_linear(x).clamp(min=0): 执行输入线性层的前向传播,然后使用clamp函数将其结果裁剪为非负值。
for _ in range(random.randint(0, 3)):: 在隐藏层之间进行随机次数的循环,每次循环执行一个隐藏层的前向传播。
h_relu = self.middle_linear(h_relu).clamp(min=0): 执行隐藏层线性层的前向传播,然后使用clamp函数将其结果裁剪为非负值。
y_pred = self.output_linear(h_relu): 执行输出线性层的前向传播,将最后一个隐藏层的输出作为输入。
return y_pred: 返回预测输出张量y_pred。
N, D_in, H, D_out = 64, 1000, 100, 10: 定义数据的维度和大小。
x = torch.randn(N, D_in): 生成一个随机输入张量x。
y = torch.randn(N, D_out): 生成一个随机输出张量y。
model = DynamicNet(D_in, H, D_out): 创建一个DynamicNet类的实例,即一个模型对象。
criterion = torch.nn.MSELoss(reduction='sum'): 定义一个均方误差损失函数,用于计算预测输出和真实输出之间的差异。
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9): 定义一个具有动量的随机梯度下降(SGD)优化器,用于更新模型参数。
for t in range(500):: 开始训练循环,执行500次迭代。
y_pred = model(x): 执行模型的前向传播计算,将输入张量x传递给模型,得到预测输出张量y_pred。
loss = criterion(y_pred, y): 计算损失函数,使用均方误差来衡量预测输出和真实输出之间的差异。
if t % 100 == 99:: 每100次迭代打印当前迭代次数和损失值。
optimizer.zero_grad(): 清空优化器的梯度。
loss.backward(): 执行反向传播,计算梯度。
optimizer.step(): 使用优化器来更新模型参数。
这段代码定义了一个动态的神经网络模型,使用自定义的DynamicNet类继承了torch.nn.Module类,并通过重写forward函数实现了前向传播逻辑。训练循环中的步骤与前面的代码相似,包括前向传播、计算损失、梯度清零、反向传播和参数更新。不同之处在于使用的模型、损失函数、优化器以及引入了随机循环的隐藏层。
'''