之前我已经完成了使用langchain与你自己的数据对话的前三篇博客,还没有阅读这三篇博客的朋友可以先阅读一下:
- 使用langchain与你自己的数据对话(一):文档加载与切割
- 使用langchain与你自己的数据对话(二):向量存储与嵌入
- 使用langchain与你自己的数据对话(三):检索(Retrieval)
今天我们来继续讲解deepleaning.AI的在线课程“LangChain: Chat with Your Data”的第五门课:问答(question answering)
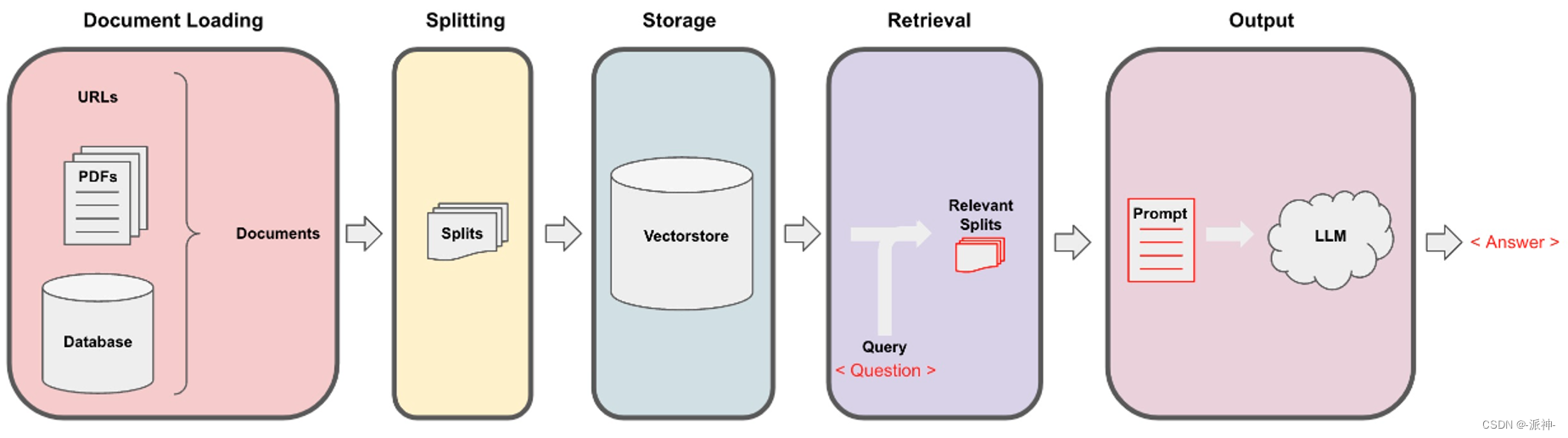
Langchain在实现与外部数据对话的功能时需要经历下面的5个阶段,它们分别是:Document Loading->Splitting->Storage->Retrieval->Output,如下图所示:
在上一篇博客:检索(Retrieval) 中我们介绍了基本语义相似度(Basic semantic similarity),最大边际相关性(Maximum marginal relevance,MMR), 过滤元数据, LLM辅助检索等内容,接下来就来到了最后一个环节:output
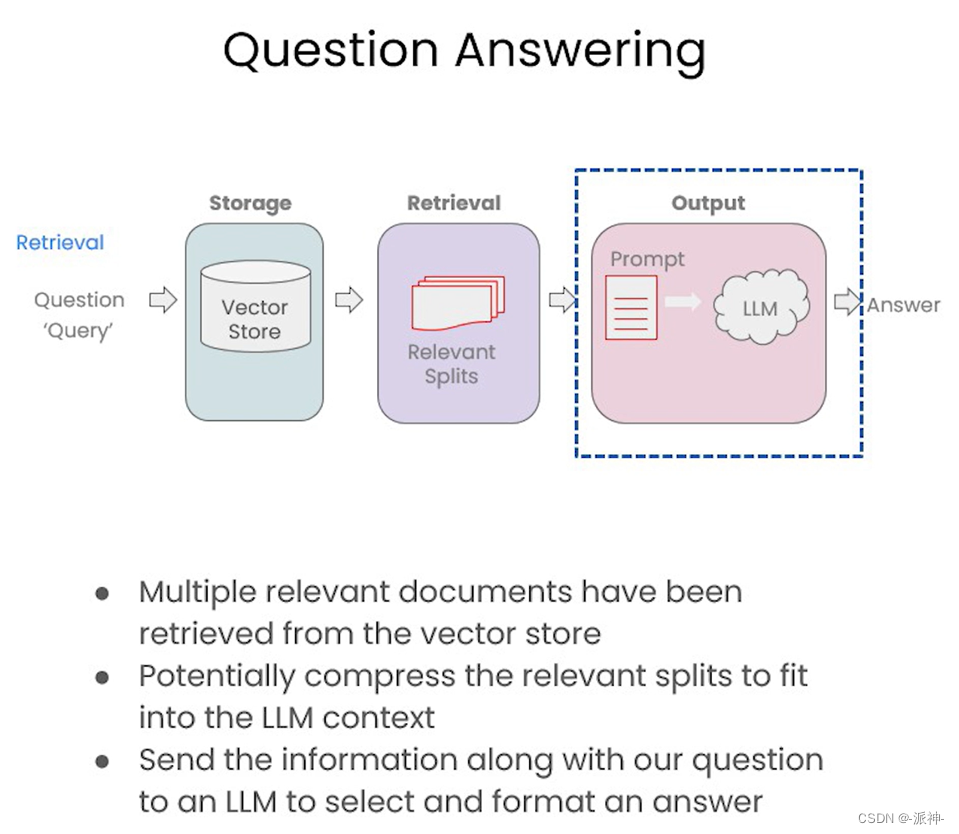
在最后的输出环节中,我们会将前一阶段检索(Retrieval)的结果,也就是与用户问题相关的文档块(可能会存在多个相关的文档块),连同用户的问题一起喂给LLM,最后LLM返回给我们所需要的答案:
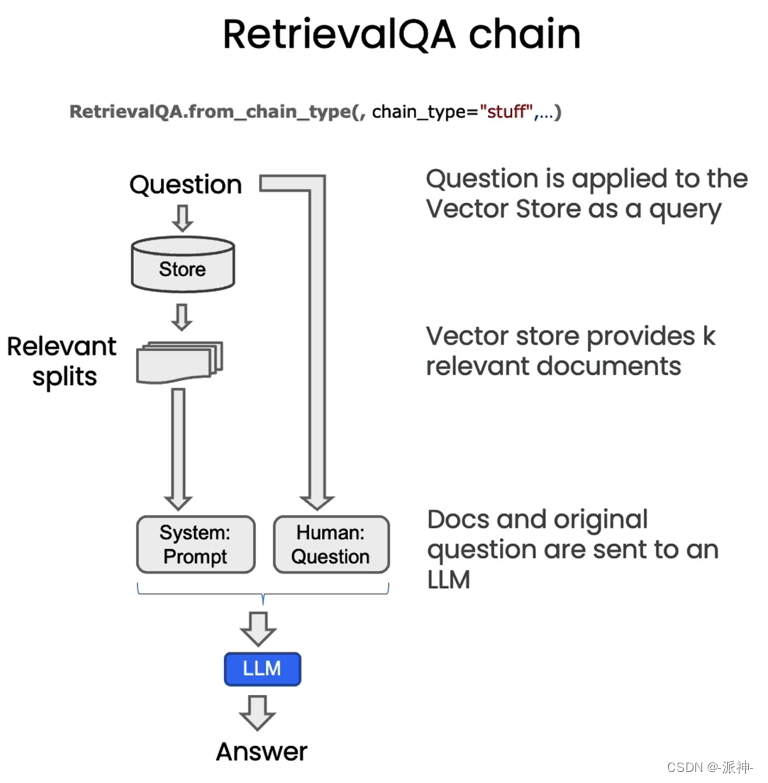
在默认的情况下,我们会将所有的相关文档一次性的全部传给LLM,即所谓的“stuff”的chain type方式。这在我之前写的博客中有详细的说明,stuff方式虽然很方便,但是也存在缺点,就是当检索出来的相关文档很多时,就会报超出最大 token 限制的错。除了stuff方式还有如下几种chain type的方式如下图所示:
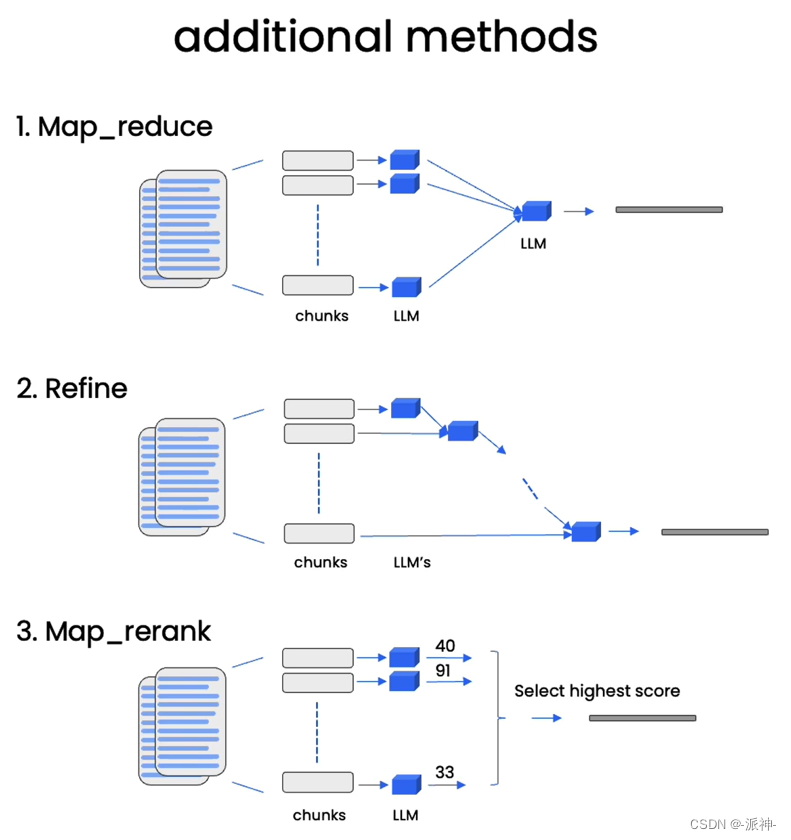
关于map_reduce,refine, map_rerank等方式基本原理在我之前写的博客:LangChain大型语言模型(LLM)应用开发(四):Q&A over Documents中都有说明,这里不再赘述,不过在本文后续的代码演示中我会涉及到这几种方式。
加载向量数据库
在讨论这些新技术之前,先让我们完成一些基础性工作,比如设置一下openai的api key:
import os
import openai
import sys
sys.path.append('../..')
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
openai.api_key = os.environ['OPENAI_API_KEY']接下来我们需要先加载一下在之前的博客中我们在本地创建的关于吴恩达老师的机器学习课程cs229课程讲义(pdf)的向量数据库:
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
persist_directory = 'docs/chroma/'
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=persist_directory,
embedding_function=embedding)
#打印向量数据库中的文档数量
print(vectordb._collection.count())
这里我们加载了之前保存在本地的向量数据库,并查询了数据库中的文档数量为209,这与我们之前创建该数据库时候的文档数量是一致的,接下来我们提出一个问题:“What are major topics for this class?”,即“ 这门课的主要主题是什么?” 然后用similarity_search方法来查询一下与该问题相关的文档块:
question = "What are major topics for this class?"
docs = vectordb.similarity_search(question,k=3)
len(docs)
这里我们看到similarity_search方法搜索到了3给与该问题相关的文档块。接下来我们查看一下这3个文档:
docs
这里我们看到similarity_search返回的3给文档中,第一,第二篇文档的内容是相同的,这是因为我们在创建这个向量数据库时重复加载了一篇文档(pdf),这导致similarity_search搜索出来文档存在重复的可能性,要解决这个问题,可以使用max_marginal_relevance_search方法,该方法可以让结果的相关性和多样性保持均衡,关于具体实现的原理可以参考我之前写的博客。
RetrievalQA chain
接下来我们要创建一个检索问答链(RetrievalQA),然后将相关文档的搜索结果以及用户的问题喂给RetrievalQA,让它来产生最终的答案,不过首先我们需要创建一个openai的LLM:
from langchain.chat_models import ChatOpenAI
#创建llm
llm = ChatOpenAI(temperature=0)
llm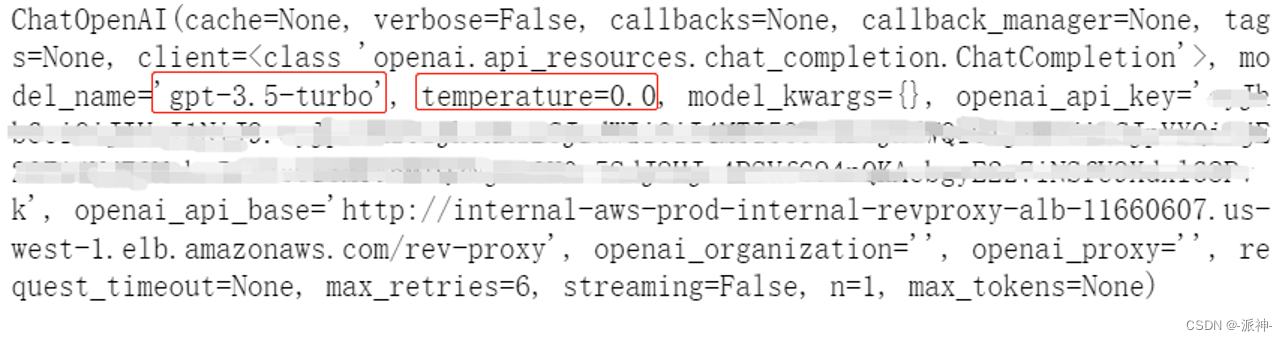
这里我们创建的openai的llm默认使用了“gpt-3.5-turbo”模型,同时我们还设置了temperature参数为0,这样做是为了降低llm给出答案的随机性。下面我们来创建一个检索问答链(RetrievalQA),然后我们将llm和检索器(retriever)作为参数传给RetrievalQA,这样RetrievalQA就可以根据之前的问题,给出最终的答案了。
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
question = "What are major topics for this class?"
result = qa_chain({"query": question})
result["result"] 
这里我们看到,RetrievalQA给出了一个答案,该答案是在对向量数据库检索到的3给文档的基础上总结出来的。为了让RetrievalQA给出一个格式化的答案,我们还可以创建一个prompt,在这个prompt中我们将会告诉llm,它应该给出一个怎样的答案,以及答案的格式是怎么样的:
from langchain.prompts import PromptTemplate
# Build prompt
template = """Use the following pieces of context to answer the question at the end. \
If you don't know the answer, just say that you don't know, don't try to make up an answer. \
Use three sentences maximum. Keep the answer as concise as possible. Always say "thanks for asking!" \
at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)我们把这个prompt翻译成中文,这样便于大家理解:

在这个prompt中的{context}变量中会保存检索器搜索出来的相关文档的内容,而{question}变量保存的是用户的问题。
下面我们来测试一下加入了prompt的RetrievalQA的返回结果,不过首先我们还是需要重新定义一个RetrievalQA,并将prompt作为参数传给它,同时设置return_source_documents=True,这样RetrievalQA在回答问题的时候会同时返回与问题相关的文档块。
# Run chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)下面我们让RetrievalQA来回答一下问题:
question = "What are major topics for this class?"
result = qa_chain({"query": question})
result["result"]![]()
这里我们看到qa_chain根据模板的要求给出了一个简洁的答案,并在最后加上了 “thanks for asking!”。接下来我们查看一下qa_chain返回的相关文档:
result["source_documents"]
这里我们看到qa_chain返回的相关文档和我们之前用向量数据库的similarity_search方法搜索的相关文档基本是一致的,只不过在similarity_search方法中我们设置了k=3,所以similarity_search方法只返回3给相关文档,而RetrievalQA方法默认使用的是“stuff”方式,因此它会让向量数据库检索所有相关文档,所以最后检索到了4篇文档,其中第一第二篇,第三第四篇文档都是相同的,这是因为我们在创建向量数据库时将第一个文档(Lecture01.pdf)加载了两篇,导致向量数据库最后会搜索出内容重复的文档。接下来我们再让qa_chain回答一个问题:
question = "Is probability a class topic?"
result = qa_chain({"query": question})
result["result"]![]()
下面我们查看一下该问题的相关文档:
result["source_documents"]
同样,对于该问题,qa_chain也返回了4给相关文档,并且也是重复的,从元数据中可以看到它们来自于Lecture01.pdf 和Lecture03.pdf 这个原始的pdf文件。
RetrievalQA chain types
接下来我们来更改一下RetrievalQA的chain_type参数,将原来默认的“stuff”改成“map_reduce”:
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="map_reduce"
)
question = "Is probability a class topic?"
result = qa_chain_mr({"query": question})
result["result"]
这里我们看到针对前面的同一个问题:"Is probability a class topic?",这次由于我们设置了chain_type=map_reduce, qa_chain_mr却没有给出肯定的答案。这个主要的原因是由于map_reduce的机制所导致的,map_reduce在执行过程中会让LLM对向量数据库中的每个文档块做一次总结,最后把所有文档块的总结汇总在一起再做一次最终的总结,因此它不像“stuff”那样,直接搜索所有文档块,只输出相关文档块,抛弃掉不相关的文档块,因此map_reduce在做最终总结的时候它的输入仍然包含了大量的不相关文档的总结内容,最终导致焦点被模糊了,无法给出正确的答案。下面我们再尝试一下refine,map_rerank这两种方式:
qa_chain_refine = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="refine"
)
question = "Is probability a class topic?"
result = qa_chain_refine({"query": question})
result["result"]
这里我们看到refine方式给出的答案也类似map_reduce的结果,它也没有给出肯定的答案,主要原因也是由于refine的工作机制也类似于map_reduce,llm会对每一个文档块进行总结,并且逐步汇总一个总结,这使得最终总结中也包含了大量不相关的总结内容,最终导致焦点被模糊了,没有给出正确的答案。
qa_chain_mr = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever(),
chain_type="map_rerank"
)
question = "Is probability a class topic?"
result = qa_chain_mr({"query": question})
result["result"]
我们看到map_rerank方式的给出来肯定的结果,这是因为在执行map_rerank时LLM会对每一个文档块进行打分,那么与问题相关的文档块自然会得到高分,而那些和问题不相关的文档块则会得到低分,那么在做最终总结时LLM只选取分数高的文档块,而那些分数低的文档块会被丢弃,所以它能得到肯定的答案。
总结
今天我们介绍了如何通过答链RetrievalQA,来检索向量数据库并回答用户的问题。其中我们介绍了几种RetrievalQA检索向量数据库的工作方式,也就是chain type方式,其实默认方式是stuff,除此之外还有map_reduce,refine, map_rerank等几种方式,它们都有各自的优缺点。同时我们还介绍了通过使用prompt模板,可以让LLM返回格式化的结果。希望今天的内容对大家学习langchain有所帮助!
参考资料
Stuff | 🦜️🔗 Langchain
Refine | 🦜️🔗 Langchain
Map reduce | 🦜️🔗 Langchain
Map re-rank | 🦜️🔗 Langchain
DLAI - Learning Platform Beta