背景
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
小结
- 好的模型应该是简单的模型,能防止过拟合。 简单性的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。
- 加入噪声能在输入-输出映射上增强平滑性。
- 在暂退法(Drop out )中增加噪声的方式是:在前向传播过程中,计算每一内部层的同时注入噪声。将概率p的值置为0, 其他值修改为 h/(1-p),保证期望前后不变。

- 实践中的暂退法为:

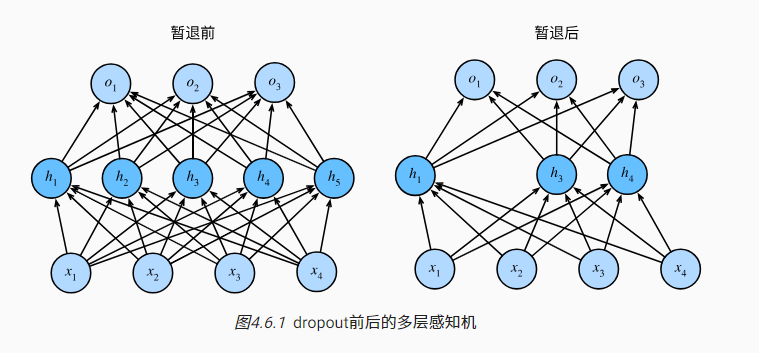
5. 在测试时不用使用dropout. 我们在测试时不用暂退法。 给定一个训练好的模型和一个新的样本,我们不会丢弃任何节点,因此不需要标准化
6. 实现:
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)