前言
我们先来回顾下之前介绍过的三种Committer:FileOutputCommitter V1、FileOutputCommitter V2、S3A Committer,其基本代表了整体的演进趋势。
核心代码讲解详细参照:Spark CommitCoordinator 保证数据一致性 OutputCommitter commitTask commitJob mapreduce.fileoutputcommitter.algorithm.version | 技术世界 | committask,commitjob,spark 一致性,mapreduce.fileoutputcommitter.algorithm.version,spark,大数据,集群,消息系统,郭俊 Jason,spark 优化,大数据架构,技术世界
FileOutputCommitter V1,采用两次Commit的方式来保证较强的一致性,每次Commit都对应一次文件的Rename。每个Task先将数据写入到Task的临时目录下,写完后将其Rename到Job的临时目录下;所有Task都完成后,由Job负责将其临时目录下的所有文件Rename到正式目录下,此时文件对外可见。对于HDFS而已,Rename是一个十分高效的操作,然而对于S3这样的对象存储来说,则有着很大的代价。原因在于,S3本身并不是文件系统,不存在Rename操作,一个Rename操作需要分解为List + Copy + Delete操作。因此,对于S3而言,两次Rename有着非常大的性能开销。我们经常发现,Spark UI上看到各个Task已经结束了,但是Job就是迟迟不结束,有点像hang住了,其实就是在做第二次Rename。
Rename机制
首先来看看Spark写文件的执行方式和可能存在的问题。通常情况下,我们在单机上写文件时,都会生成一个指定文件名的文件,而调用Spark DataFrame的write接口来写文件时,所得到的结果却与此不同。如下图右侧所示,其写入了3个数据文件在指定的路径下。为什么会这样呢?这与Spark的执行方式有关。Spark是分布式计算系统,其RDD中的数据是分散在多个Partition中的,而每个Partiton对应一个Task来执行,这些Task会根据vcores个数来并行执行。在下图的示例中,笔者分配了3个Partition,所以生成了part-00000、part-00001、part-00002三个文件(文件名中间的一段UUID是在job中生成的)。按照这样的执行方式,假设我们直接把数据写入到指定的路径下,会出现哪些问题?
由于是多个Task并行写文件,如何保证所有Task写的所有文件要么同时对外可见,要么同时不可见?在下图示例中,三个Task的写入速度是不同的,那就会导致不同时刻看到的文件个数是不一样的。另外,如果有一个Task执行失败了,就会导致有2个文件残留在这个路径下。
同一个Task可能因为Speculation或者其他极端原因导致某一时刻有多个Task Attempt同时执行,即同一个Task有多个实例同时写相同的数据到相同的文件中,势必会造成冲突。如何保证最终只有一个是成功的并且数据是正确的?

为了应对这些问题,尽可能保证数据一致性,Hadoop FileOutputCommitter设计了Rename机制(Spark写文件还是调用Hadoop的相关库来完成的)。Rename机制先后有两个版本:v1和v2,二者在性能和保证数据一致性的粒度上有所区别。
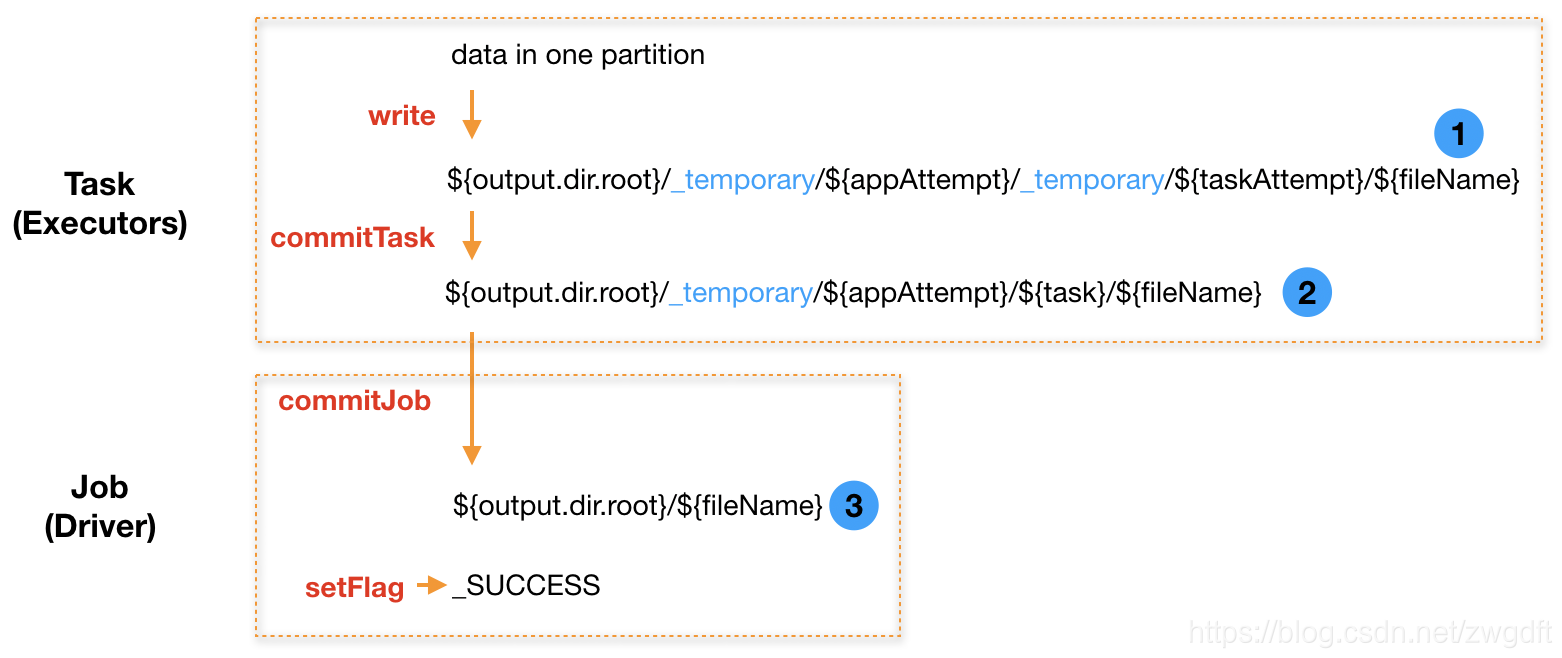
下图所示为v1的思想,其需要经历两次Rename。每个Task首先将数据写入如下临时路径:
${output.dir.root}/_temporary/${appAttempt}/_temporary/${taskAttempt}/${fileName}
示例:
hdfs:///data/_temporary/0/_temporary/attempt_20190219101232_0003_m_000005_0/part-00000-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
Task写入完成后,执行commitTask做第一次Rename,将文件从Task Attempt的临时目录中移动到Task的临时目录中。
${output.dir.root}/_temporary/${appAttempt}/${task}/${fileName}
示例:
hdfs:///data/_temporary/0/task_20190219101232_0003_m_000005/part-00000-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
最后,当所有Task都完成上述操作后,由Driver负责执行commitJob做第二次Rename,依次将文件从每个Task的临时目录中移动到真实目录中,并写入_SUCCESS标识。
${output.dir.root}/${fileName}
示例:
hdfs:///data/part-00000-936a4f3b-8f71-48ce-960a-e60d3cf4488f.c000.snappy.parquet
v1的思想较好的解决了前面提到的问题,基于此,只有在Rename的过程中出问题才可能导致数据一致性问题,然而这种概率相比之前提到的情况要低很多。但是,两次Rename也带来了性能问题,主要表现在:当有大量Task写入时,即使所有Task都完成了,还需要等待很长一段时间Job才能结束,这个时间主要花在Driver端做第二次Rename。例如,在笔者的系统中,每次需要写入1200个文件到S3,平均每个需要花费0.5~1.5秒的时间来做第二次Rename,整体需要花费10-30分钟。
FileOutputCommitter V2,在V1的基础上减去了第二次Rename,即每个Task先将数据写入到Task的临时目录下,写完后直接将其Rename到正式目录中;所有Task都完成后,Job只是写入一个_SUCCESS文件来标识已完成。显然,V2是牺牲一定的一致性来换取性能。因为,如果Spark Job在执行过程中失败了,就会出现部分成功的Task写入的文件对外可见,成为脏数据。S3A Committer,最初由Netflix贡献给社区,采用S3 Multipart Upload机制替换了Rename机制。原因在于,对于S3而言,Rename不仅仅会带来性能问题,还可能因为S3的“最终一致性”特性而失败。社区版的这个Committer,会在每个Task中将数据先写入到本地磁盘,然后采用Multipart Upload方式上传到S3;所有Task都完成后,由Job统一向S3发送Complete信号,此时文件对外可见。


综合来看,使用Spark往S3写入文件时,应该尽量选择基于S3 Multipart Upload机制的Committer。在我们的系统中,主要采用AWS EMR来构建Spark集群,数据写入S3存储。EMR在5.19.0之后引入了EMRFS S3-optimized Committer,同样采用S3 Multipart Upload机制,因此我们会优先使用这个Committer。
V1和V2 commiter版本比较
mapreduce.fileoutputcommitter.algorithm.version 参数对文件输出有很大的影响,下面总结一下两种版本在各方面的优缺点。
1、性能方面
v1在task结束后只是将输出文件拷到临时目录,然后在job结束后才由Driver把这些文件再拷到输出目录。如果文件数量很多,Driver就需要不断的和NameNode做交互,而且这个过程是单线程的,因此势必会增加耗时。如果我们碰到有spark任务所有task结束了但是任务还没结束,很可能就是Driver还在不断的拷文件。
v2在task结束后立马将输出文件拷贝到输出目录,后面Job结束后Driver就不用再去拷贝了。
因此,在性能方面,v2完胜v1。
2、数据一致性方面
v1在Job结束后才批量拷文件,其实就是两阶段提交,它可以保证数据要么全部展示给用户,要么都没展示(当然,在拷贝过程中也无法保证完全的数据一致性,但是这个时间一般来说不会太长)。如果任务失败,也可以直接删了_temporary目录,可以较好的保证数据一致性。
v2在task结束后就拷文件,就会造成spark任务还未完成就让用户看到一部分输出,这样就完全没办法保证数据一致性了。另外,如果任务在输出过程中失败,就会有一部分数据成功输出,一部分没输出的情况。
因此在数据一致性方面,v1完胜v2。
Spark任务写数据到s3,执行时间特别长
场景
目前使用s3替代hdfs作为hive表数据存储,使用spark sql insert数据到hive表,发现一个简单的查询+插入任务,查询+insert的动作显示已经执行完,任务还在跑,直到跑了两个小时后才执行结束。
原因
s3对spark默认的commit操作兼容性不强,spark有两种commit操作,一种是commit task,在executor上执行,一种是commit job,在driver上执行。默认commit策略下,spark在输出数据的时,会先输出到临时目录上,临时目录分task临时目录和job临时目录,默认的commit task操作是将执行成功的task的输出数据从task的临时目录rename到job的临时目录task目录,commit job操作则是driver单线程遍历所有job临时目录下所有task目录并rename到用户指定的输出目录下。driver运行时间长在于单线程rename所有task目录,最后在最终输出的目录加上SUCCESS文件,而s3的rename操作是mv=cp+rm,和hdfs的rename操作不同,效率低下。
解决
一般情况下,我们使用的committer是FileOutputCommitter,在hadoop2.7后,支持新的commit算法,将mapreduce.fileoutputcommitter.algorithm.version设置为2,默认是1,新的commit算法对commit task做了一下改动,不再将task临时目录mv到job的临时目录下,而是直接移动到最终目录下,不需要driver最后再单线程移动一次,commit job操作是在最终目录下直接加上SUCCESS文件即可。简单概括就是单线程mv变多线程mv,新的commit算法提高了性能,但是降低了数据一致性。
spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2
AWS EMRFS S3-optimized Committer
EMRFS S3-optimized Committer,如AWS官方博客所言,其思想来自于S3A Committer,但是就目前的实现来看,坦白说,个人感觉比较鸡肋。一方面,这是官方出品,虽然不开源,但是相信其内部做了很多跟EMR集成的东西,因此我们通常会默认选择使用;另一方面,它有两个比较大的缺陷。
目前只能对部分符合条件的语法代码生效,比如只能是写Parquet文件,具体可以参考官方文档
它只是在FileOutputCommitter V2的基础上进行了改进,即将V2中的Rename机制替换为了S3 Multipart Upload机制,因此V2存在的数据一致性问题它也存在。

S3 Multipart Upload机制,原本是S3用于支持大文件上传的方法。其将一次文件上传分解为三个动作:
第一步,初始化,向S3申请用于本次上传的Upload ID;
第二步,将大文件分解为多个Part进行上传,此过程中文件对外是不可见的;
第三步,全部Part上传完成后,向S3发送完成信号,S3内部会将多个Part的文件进行合并,之后文件对外可见;又或者发送取消信号,S3会将已上传的文件删除。

基于S3 Multipart Upload机制的Committer便是充分利用这个特性来保证数据的一致性。每个Task都利用Multipart Upload来上传文件,但是有两点不同:第一,只做前两步,即初始化和多Part上传;第二,通常只有1个Part文件。所有Task都成功后,由Driver在Job中统一做第三步,即发送完成信号,之后所有文件对外可见。

对于第一个缺陷,我们在使用中经常战战兢兢,需要确认是否有效触发了这个Committer。以下面代码为例,我们在Spark Streaming中,每10分钟一个Batch,对数据进行加工处理后写入到S3中。该代码是否触发到了这个Committer呢?通过INFO Log分析来看,是有触发到的。下图上半部分是一个Executor的Log,下半部分是Driver的Log,读者可以参考这个来判断是否有效触发。
df.write.mode("append")\
.partitionBy("ts_interval", "schema_version") \
.option("path", s3_path)\
.saveAsTable(table)

3. Job失败带来的数据不一致问题
这里重点探讨一下第二个缺陷,即Job失败带来的数据不一致问题,也是FileOutputCommitter V2存在的问题。如下图,假设一个Job有12个Task,执行过程中Task 0~2成功了,而其他失败了,进而导致Job失败了。此时,在S3上就可以看到前面三个Task写入的文件,当这个Job重做一次时,已经写入的文件的数据就会成为重复的数据。

针对这个问题,有哪些解法呢?目前,就我们接触到的而言,主要有三种方法,可以分别应用在不同的业务场景。
第一种,每次写入的目录都带有一个UUID,在整体文件写入成功后,将这个目录分发出去,给下游的Reader使用。比如下面的代码中,seq就扮演着这样的角色。但是,这样做还是会有数据残留在S3中的,只是暂时不会被下游Reader读到而已。
path = "s3://{bucket}/type={type}/ts_interval={ts_interval}/seq={uuid}" \
.format(bucket=args["bucket"],
type=log_type,
ts_interval=ts_interval,
uuid=uuid.uuid1())
df.write.parquet(path)
第二种,采用overwrite写入的方式,该方式需要有一个UUID来标识某一批数据,保证该批数据在多次写入时UUID是不变的,而不同批次的数据的UUID是不同的。比如,在Spark Streaming中,每个Batch的数据,就可以使用Batch Timestamp来作为这个UUID。在下面的代码中,就可以达到这个效果,然而遗憾的是,AWS官方文档明确提出了目前这种写法无法触发到EMRFS S3-optimized Committer。
df.write.mode("overwrite")\
.partitionBy("ts_interval", "schema_version", "ts_batch") \
.option("path", s3_path)\
.option("partitionOverwriteMode", "dynamic")
.saveAsTable(table)
第三种,保持写文件的方式不变,但是在Job失败后,捕获其异常,然后进行一次补偿,即删除掉多余的文件。我们知道,每次commitJob成功后,都会写入一个_SUCCESS文件来标识整体写入成功。如果在这个文件的Last Modified Time之后又有一些新的文件残留在S3上,我们就认为其是脏数据,将其删除。当然,随着数据量的积累,我们不可能检测所有的数据,不过对于数据实时上传的业务而言,只要检测最近一段时间内的数据文件就好了。
df.write.mode("append")\
.partitionBy("ts_interval", "schema_version") \
.option("path", s3_path)\
.saveAsTable(table)
4. 残留数据问题
除了上述的问题之外,采用S3 Multipart Upload机制实现的Committer还会存在一些共性的数据残留问题,需要在实践中有所注意。残留的数据主要来自两方面:
每个Task的数据会先写入到本地磁盘,比如上面的“/mnt/s3/emrfs-4425809305170904769/0000000000”,如果Task中断,有可能会有数据残留在本地
S3 Multipart Upload会先将上传的多个Part的文件放在S3的cache隐藏目录,如果Task中断,有可能会有数据残留在S3
对于第一方面,通过脚本监控相应的本地目录的磁盘大小并定期清理掉历史悠久的数据即可,避免磁盘被用爆了。
对于第二方面,残留在S3上的数据虽然对外不可见,但是会被收取存储费用的,因此需要进行相关清理,目前有两种方式:
设置Spark参数fs.s3.multipart.clean.enabled,该方式会启动一个异步进程来定期清理,会有一定的负载压力
在S3中配置相关Policy Lifecyle的属性即可,我们更倾向于这种方式,由S3来负责解决,没有额外开销
<LifecycleConfiguration>
<Rule>
<ID>sample-rule</ID>
<Prefix></Prefix>
<Status>Enabled</Status>
<AbortIncompleteMultipartUpload>
<DaysAfterInitiation>7</DaysAfterInitiation>
</AbortIncompleteMultipartUpload>
</Rule>
</LifecycleConfiguration>
以上便是当前我们在AWS EMRFS S3-optimized Committer,虽然存在诸多问题,我们还是尽量优先选择使用,毕竟是官方出品的。
结束语
以上便是Spark写文件的机制,更多细节可以参考阅读源码。至于文章开头提到的失败情况,因为笔者公司的Spark相关业务都部署在AWS EMR上,目前计划通过升级AWS EMR版本来解决。EMR在其5.20.0之后的版本中,默认采用EMRFS S3-optimized Committer,其采用了上述的S3 Multipart Upload机制,当然目前仅支持从DataFrame、SQL中写Parquet文件,不过应该能满足需求了。
参考文献
Spark任务输出文件过程详解_疯狂哈丘的博客-CSDN博客
[1] Hadoop FileOutputCommitter Source Code
[2] Committing work to S3 with the “S3A Committers”
[3] Introducing the S3A Committers
[4] Introduction to S3Guard
[5] Spark 2.0.0 Cluster Takes a Longer Time to Append Data