一、论文&代码
论文链接:An Efficient Training Approach for Very Large Scale Face Recognition
应用&代码:
https://modelscope.cn/models/damo/cv_ir50_face-recognition_arcface/summary
https://modelscope.cn/models/damo/cv_resnet_face-recognition_facemask/summary
二、背景
图像分类是当前AI最为成功的实际应用技术之一,它已经融入了人们的日常生活。它被广泛的应用到了计算机视觉的大部分任务中,比如图像分类、图像搜索、OCR、内容审核、识别认证等领域。目前已形成一个普遍共识:“当数据集越大ID越多时,只要训练得当,相应分类任务的效果就会越好”。但是面对千万ID甚至上亿ID,当下流行的DL框架下,很难低成本的直接进行如此超大规模的分类训练。
解决该问题最直观的方式是通过集群的方式消耗更多的显卡资源,但即便如此,海量ID下的分类问题,依然会有如下几个问题:
1.)成本问题:分布式训练框架 + 海量数据情况下,内存开销、多机通信、数据存储与加载都会消耗更多的资源。
2.)长尾问题:实际场景中,当数据集达到上亿ID时,往往其绝大部分ID内的图片样本数量会很少,数据长尾分布非常明显,直接训练难以获得较好效果。
本文余下章节将重点介绍超大规模分类框架现有解决方案,以及低成本分类框架FFC的相应原理及trick介绍。
三、方法
在介绍方法之前,首先回顾下超大规模分类当前存在的主要挑战点:
挑战点1:成本居高不下
ID数目越大分类器显存需求越大,如下示意图所示:
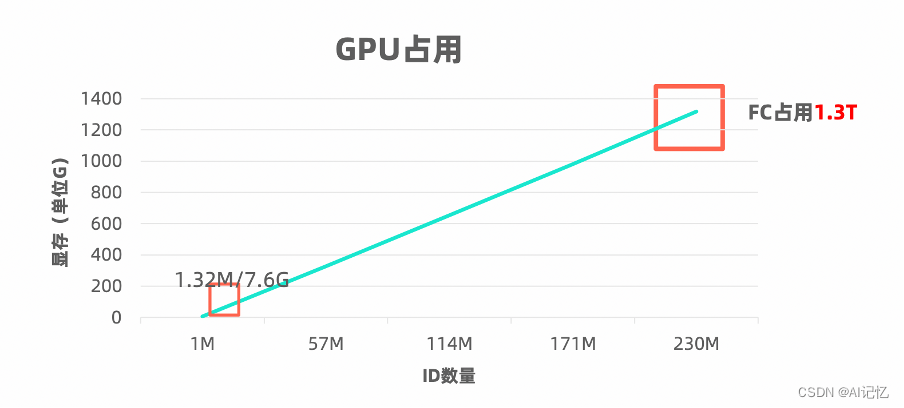
显存越大所需机器卡数越多,成本也就越高,相应多机协同的硬件基础设施成本也越高。与此同时,当分类 ID数目达到极超大规模的时候,主要计算量将浪费在最后一层分类器上,骨架网络消耗的时间可忽略不计。
挑战点2:长尾学习困难
实际场景下,上亿ID中的绝大部分ID内的图片样本数量会很少,长尾数据分布非常明显,直接训练难以收敛。如果按照同等权重训练,则长尾样本会被淹没学习不充分。此时,一般采用imbalanced sample,在这个研究课题上,有非常多的方法可以借鉴,采取怎样的方式融入到简易超大规模分类框架上较为合适呢?
带着上述两个挑战点,首先来看下现有可行的方案有哪些,是否能很好的解决上述两个挑战。
可行方法1:度量学习

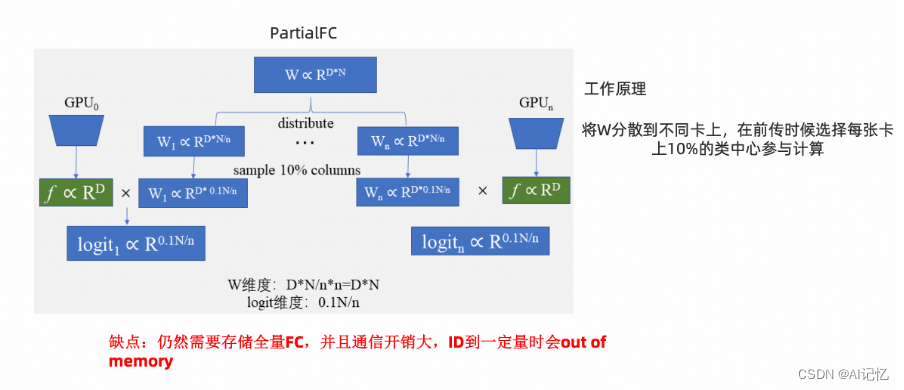
可行方法2:PFC框架
可行方法3:VFC框架
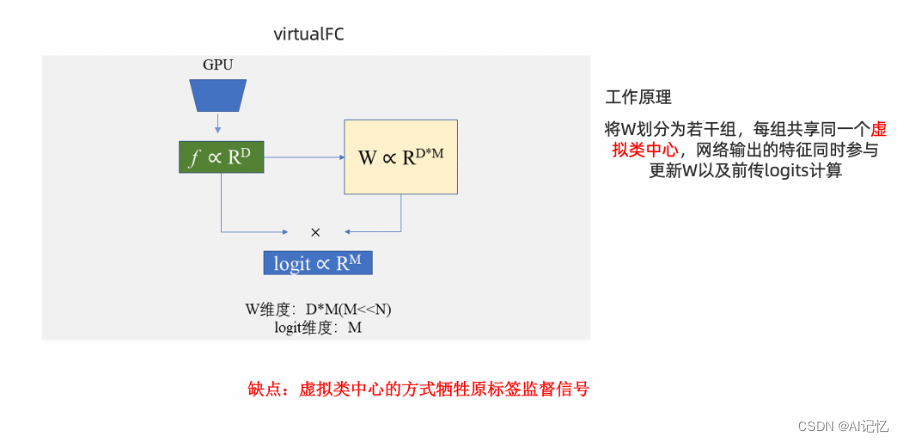
本论文方法:FFC框架
大规模分类采用FC训练时损失函数如下
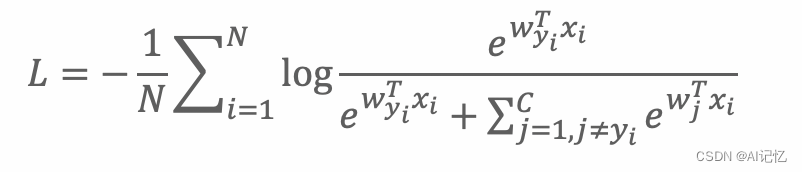
在每一次反传过程中,所有的类中心都会更新

但FC太大了,直观的思路是合理地选择一定比例的类中心,即如下Vj为1部分:
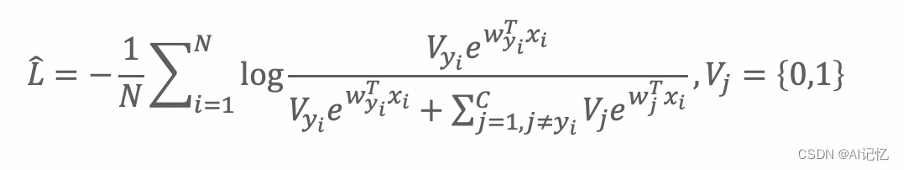
由上述动机,引出了如下初步的方案:
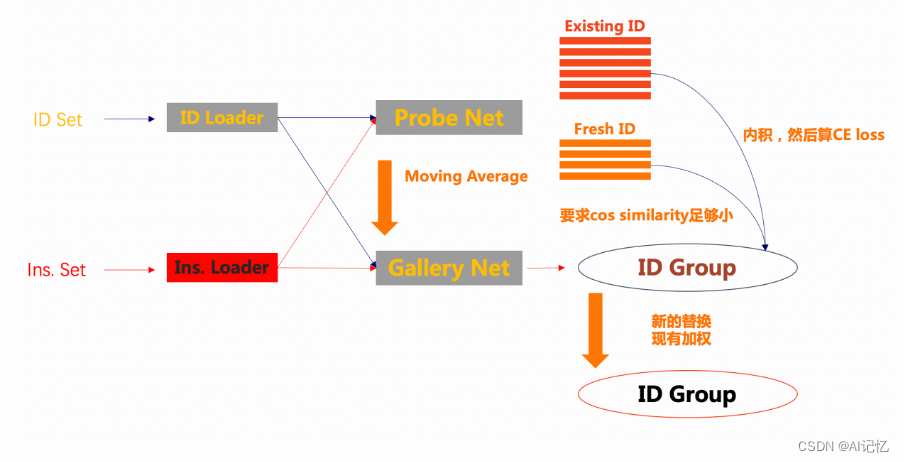
首先,为了解决长尾带来的影响,我们引入两个loaders,分别是基于id采样的id_loader和基于样本采样的instance_loader,有了这两个loader。在每个epoch当中,样本多的类和样本少的(few-shot)类能够有机会被训练到。
其次,在训练开始之前,先将一部分样本送入id group,这里假设放入10% id的样本进入group。这时候gallery用的是随机参数。
然后,训练开始时,batch样本挨个进入probe net。然后对于每个batch里面的样本就有两种情况:1.)group中存在此样本同样id的特征,2.)group中不存在同类样本的特征。对于这两种情况,我们分别称之为existing id和fresh id。对于existing的样本,拿特征和group里面的特征做内积,计算与标签的交叉熵损失函数,后回传。对于fresh的样本,跟group里面的样本来个最小化余弦相似度。
最后,对group里面特征更新,采取新类中心替换,现有类中心加权的原则。对于gallery net,采用moving average策略把probe里面的参数渐渐更新进去。
本论文方法:trick介绍
1.)引入的ID Group,其size是个可调参数,一般默认为3万。
2.)为达到稳定训练,参考moco类方法,引入moving average,相应收敛情况对别:
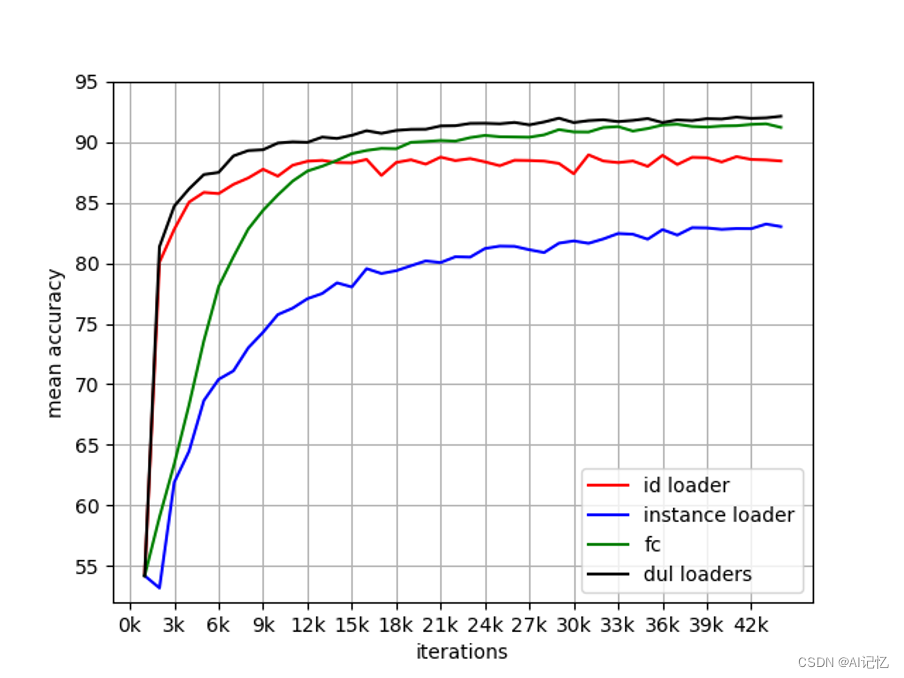
四、实验结果
1. 双Loader消融实验
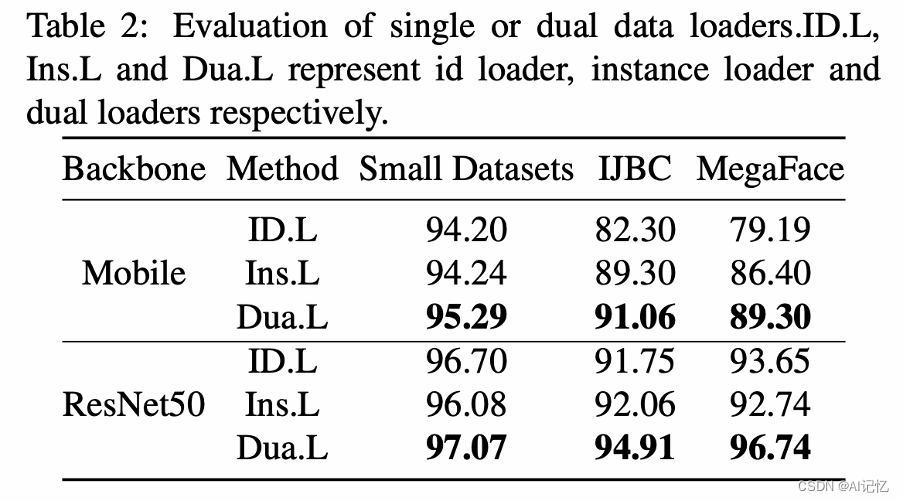
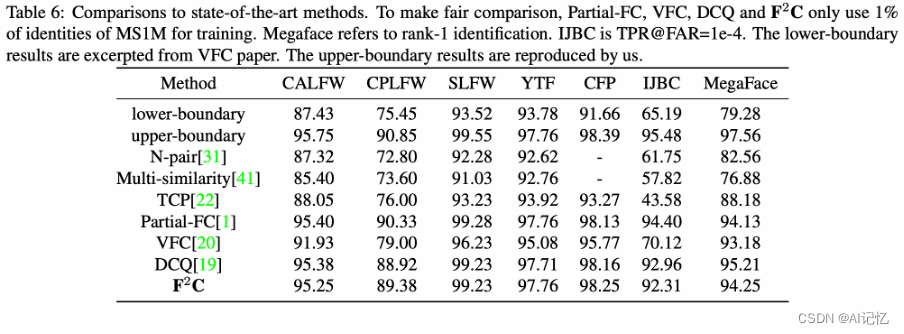
2. SOTA方法效果对比
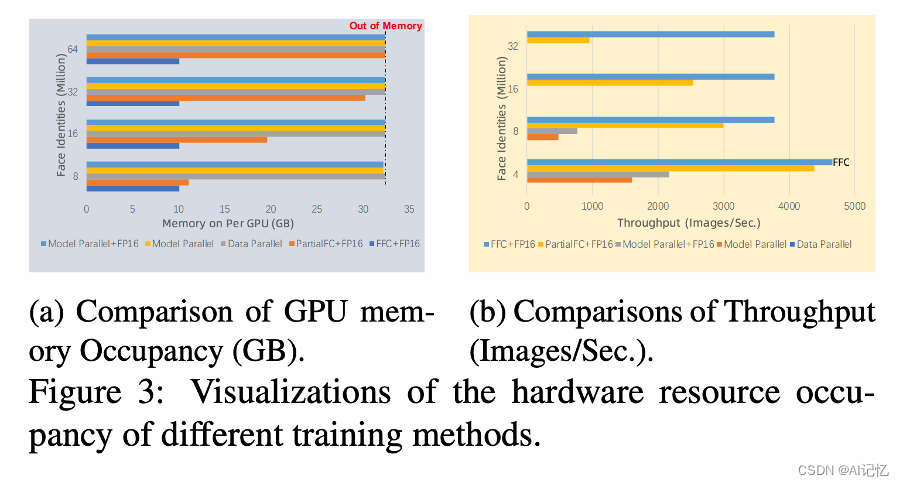
3. 显存与样本吞吐对比






![[附源码]JAVA毕业设计医院远程诊断系统(系统+LW)](https://img-blog.csdnimg.cn/1c7606d30add4c75acdbdcce0c386b5e.png)