目录
- CNN
- 代码
- 读取数据
- 搭建CNN
- 训练网络模型
- 数据增强
- 迁移学习
- 图像识别策略
- 数据读取
- 定义数据预处理操作
- 冻结resnet18的函数
- 把模型输出层改成自己的
- 设置哪些层需要训练
- 设置优化器和损失函数
- 训练
- 开始训练
- 再训练所有层
- 关机了,再开机,加载训练好的模型
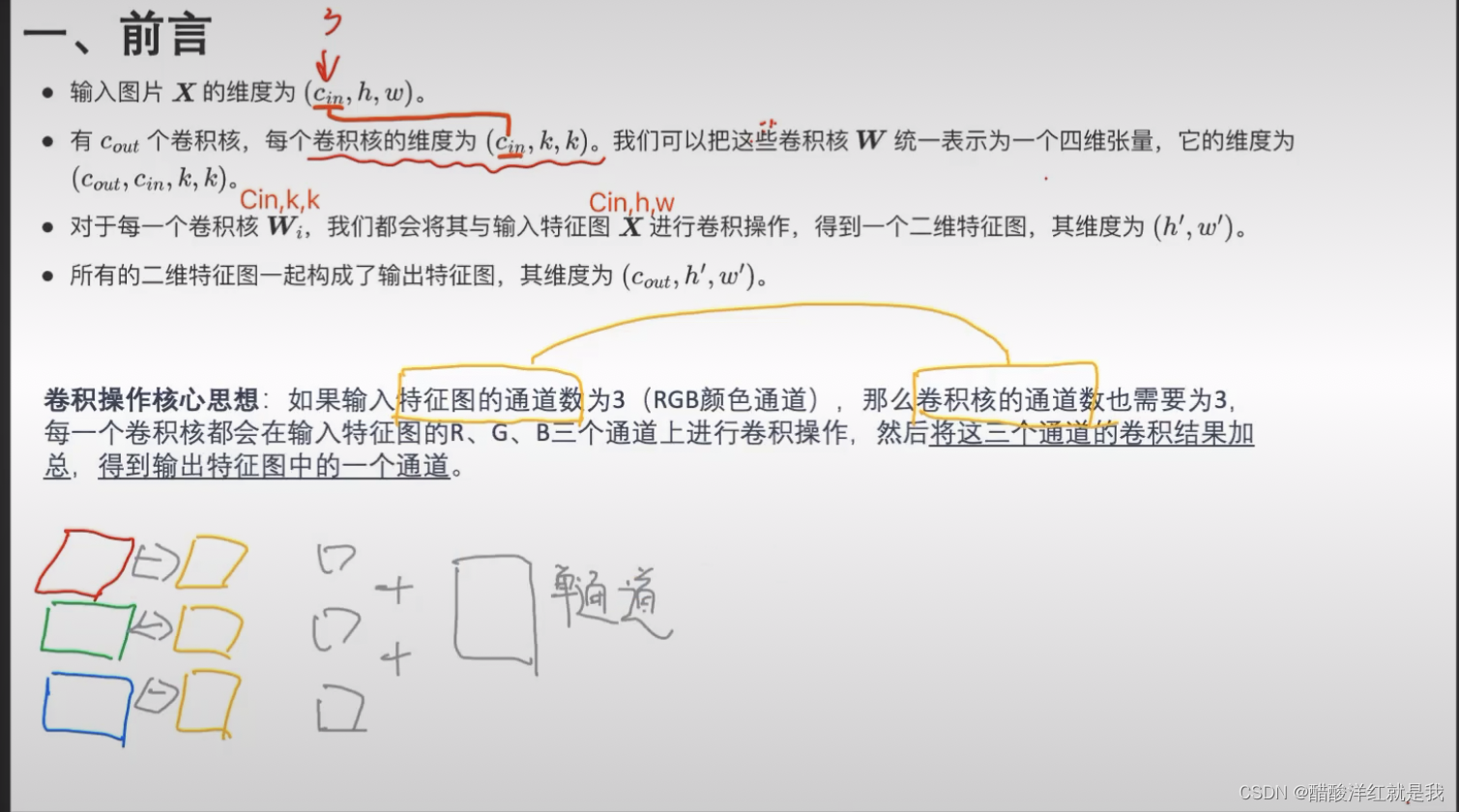
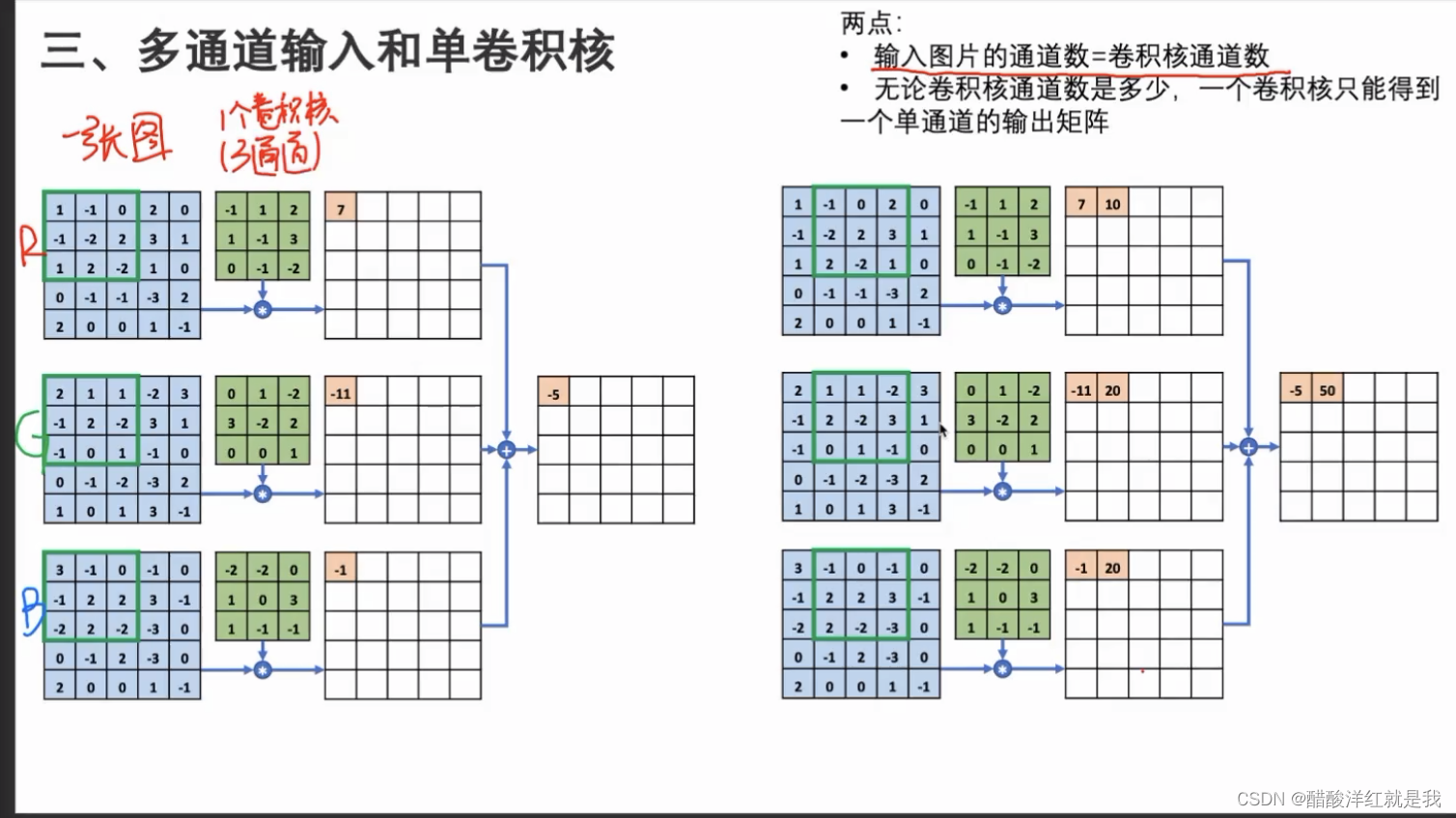
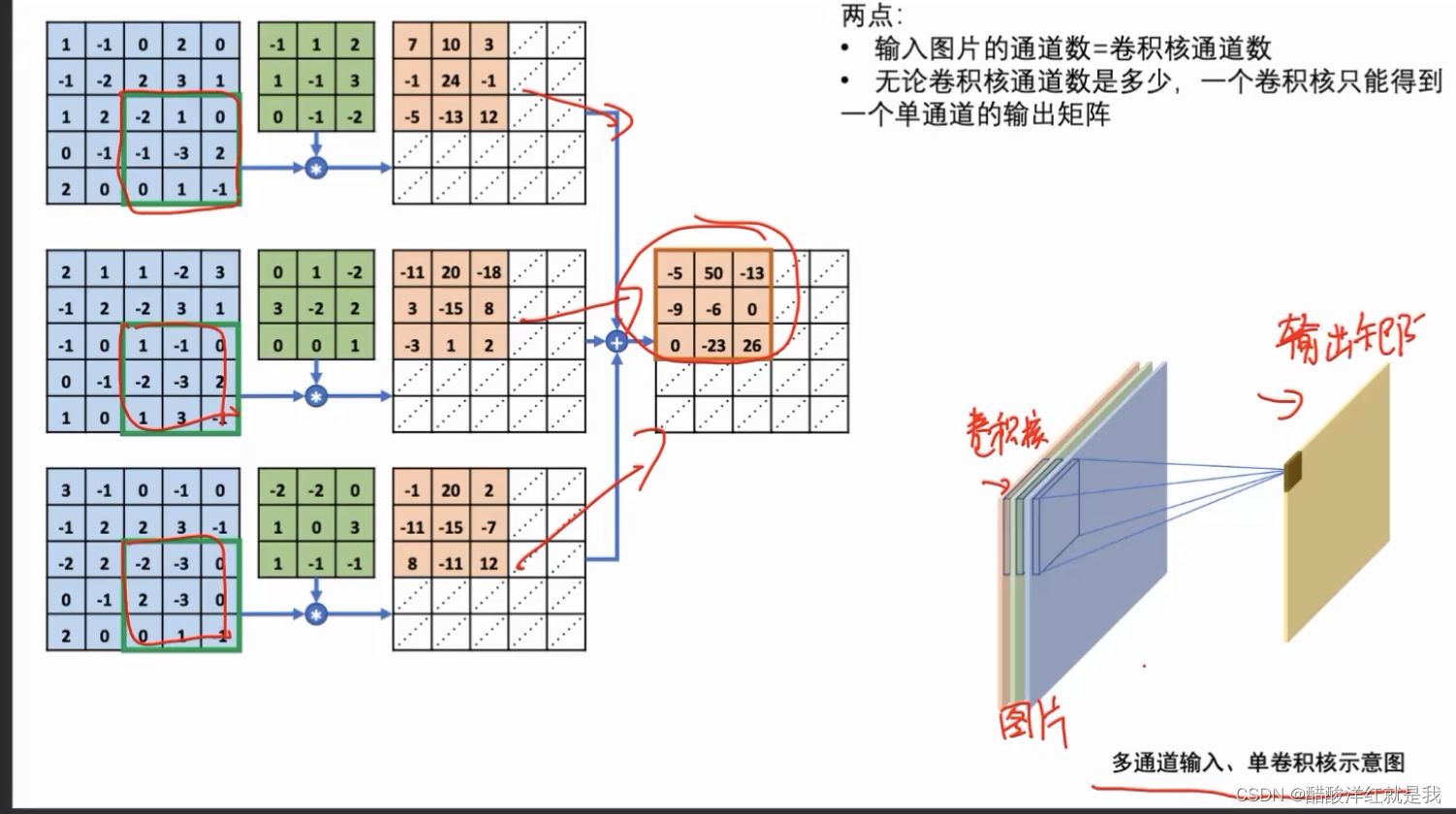
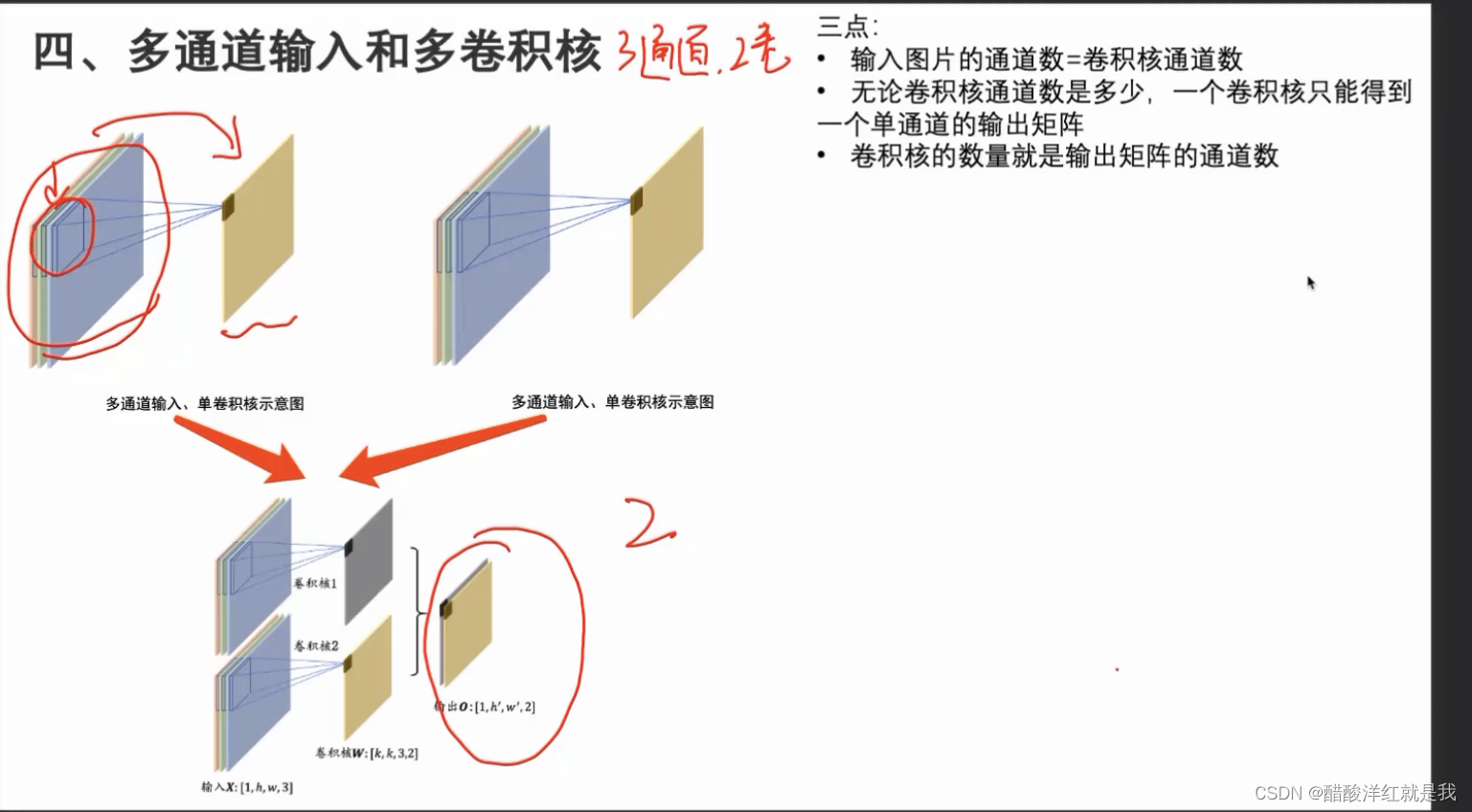
CNN
代码
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import datasets,transforms
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
读取数据
#定义超参数
input_size=28
num_class=10
num_epochs=3
batch_size=64
#训练集
train_dataset=datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset=datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
#构建batch数据
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True) #num_worker=4 使用4个子线程加载数据
test_loader=torch.utils.data.DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
train_data_iter=iter(train_loader)
#获取训练集的第一个批次数据(第一个快递包)
batch_x,batch_y=next(train_data_iter)
print(batch_x.shape,batch_y.shape)
test_data_iter=iter(test_loader)
batch_x_test,batch_y_test=next(test_data_iter)
print(batch_x_test.shape,batch_y_test.shape)

搭建CNN
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__() #batch_size,1,28,28
self.conv1=nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=16,kernel_size=5,stride=1,padding=2), #batch_size,16,28,28
nn.ReLU(),
nn.MaxPool2d(kernel_size=2), #batch_size,16,14,14
)
self.conv2=nn.Sequential(
nn.Conv2d(16,32,5,1,2), #batch_size,32,14,14
nn.ReLU(),
nn.Conv2d(32,32,5,1,2), #batch_size,32,14,14 #输入输出通道不变,让其在隐藏层里面更进一步提取特征
nn.ReLU(),
nn.MaxPool2d(2), #batch_size,32,7,7
)
self.conv3=nn.Sequential(
nn.Conv2d(32,64,5,1,2), #batch_size,64,7,7
nn.ReLU(),
)
#batch_size,64*7*7
self.out=nn.Linear(64*7*7,10)
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x)
x=nn.Flatten(self.conv3(x))
output=self.out(x)
return output
def accuracy(prediction,labels):
pred=torch.argmax(prediction.data,dim=1) #prediction.data中加data是为了防止数据里面单独数据可能会带来梯度信息
rights=pred.eq(labels.data,view_as(pred)).sum()
return rights,len(labels) #(batch_size,)/(batch_size,1)
训练网络模型
net=CNN()
criterion=nn.CrossEntropyLoss() #不需要在CNN中将logistic转换为概率,因为pytorch的交叉熵损失函数会自动进行
optimizer=optim.Adam(net.parameters(),lr=0.001)
for epoch in range(num_epochs):
train_rights=[]
for batch_idx,(data,target) in enumerate(train_loader):
net.train() #进入训练状态,也就是所有网络参数都处于可更新状态
output=net(data) #output只是logits得分
loss=criterion(output,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
right=accuracy(output,target)
train_rights.append(right)
if batch_idx %100 ==0:
net.eval() #进入评估模式,自动关闭求导机制和模型中的BN层drop out层
val_rights=[]
for (data,target) in test_loader:
output=net(data)
right=accuracy(output,target)
val_rights.append(right)
train_r=(sum([tup[0] for tup in train_rights]),sum([tup[1] for tup in train_rights]))
val_r=(sum([tup[0] for tup in val_rights]),sum([tup[1] for tup in val_rights]))
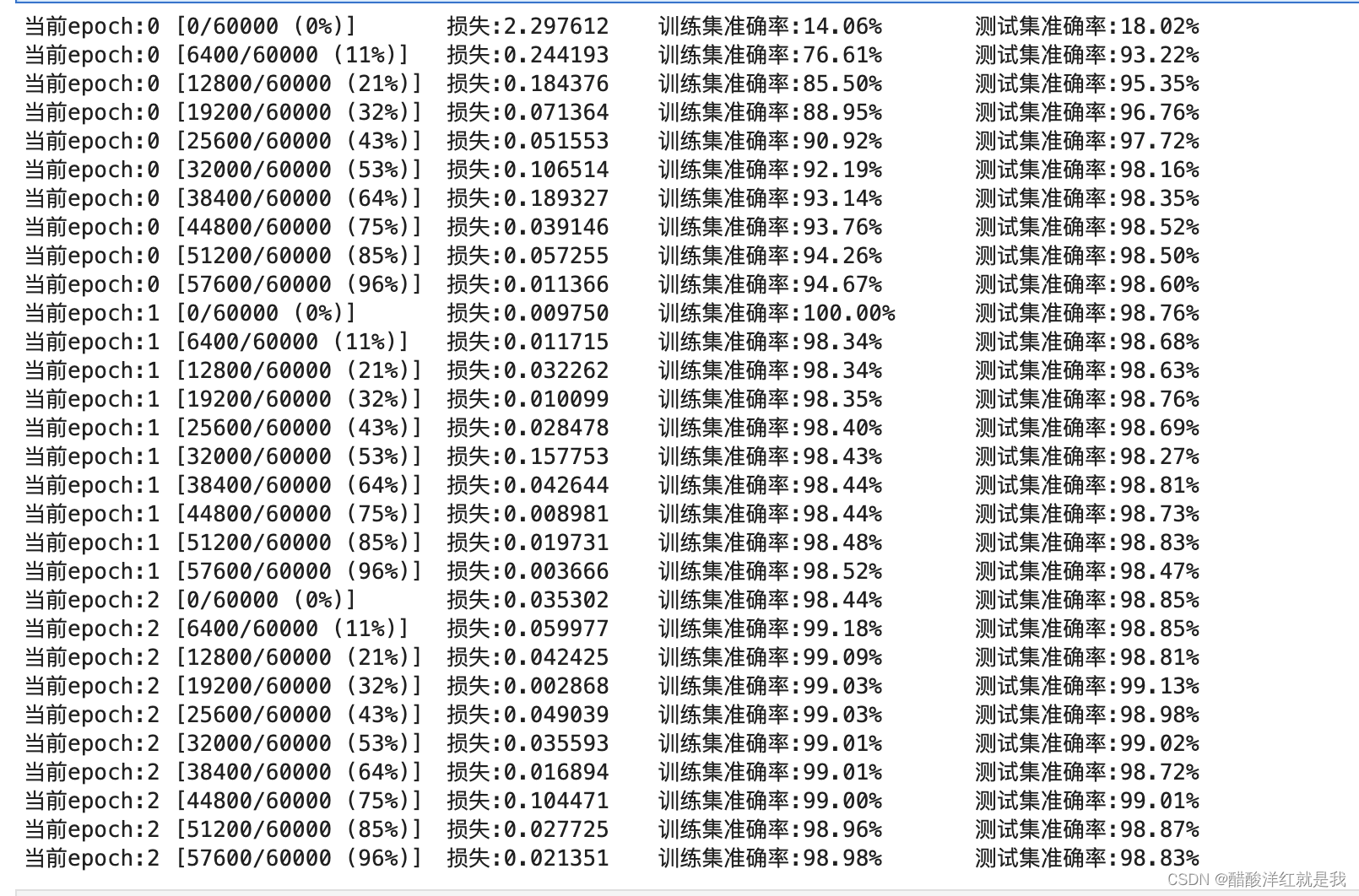
print('当前epoch:{} [{}/{} ({:.0f}%)]\t损失:{:.6f}\t训练集准确率:{:.2f}%\t测试集准确率:{:.2f}%'.format(epoch,
batch_idx*batch_size,
len(train_loader.dataset),
100.*batch_idx/len(train_loader),
loss.data,
100.*train_r[0].numpy()/train_r[1],
100.*val_r[0].numpy()/val_r[1]))
数据增强
比如数据不够,可以对数据进行旋转,翻转等操作来添加数据

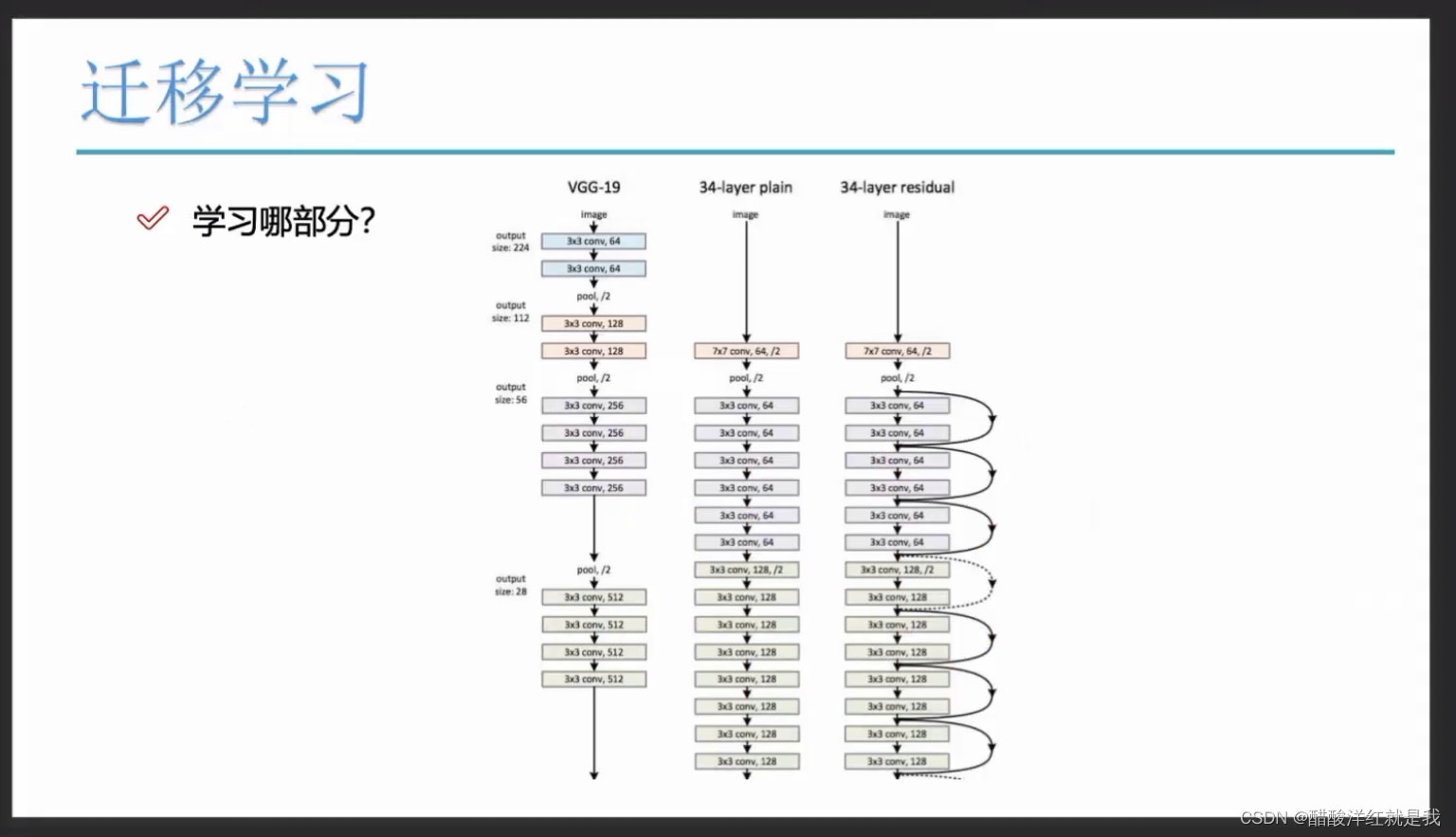
迁移学习
例如使用预训练模型
图像识别策略
输出为102
数据读取
data_dir = './汪学长的随堂资料/2/flower_data/'
train_dir = data_dir + '/train' # 训练数据的文件路径
valid_dir = data_dir + '/valid' # 验证数据的文件路径
定义数据预处理操作
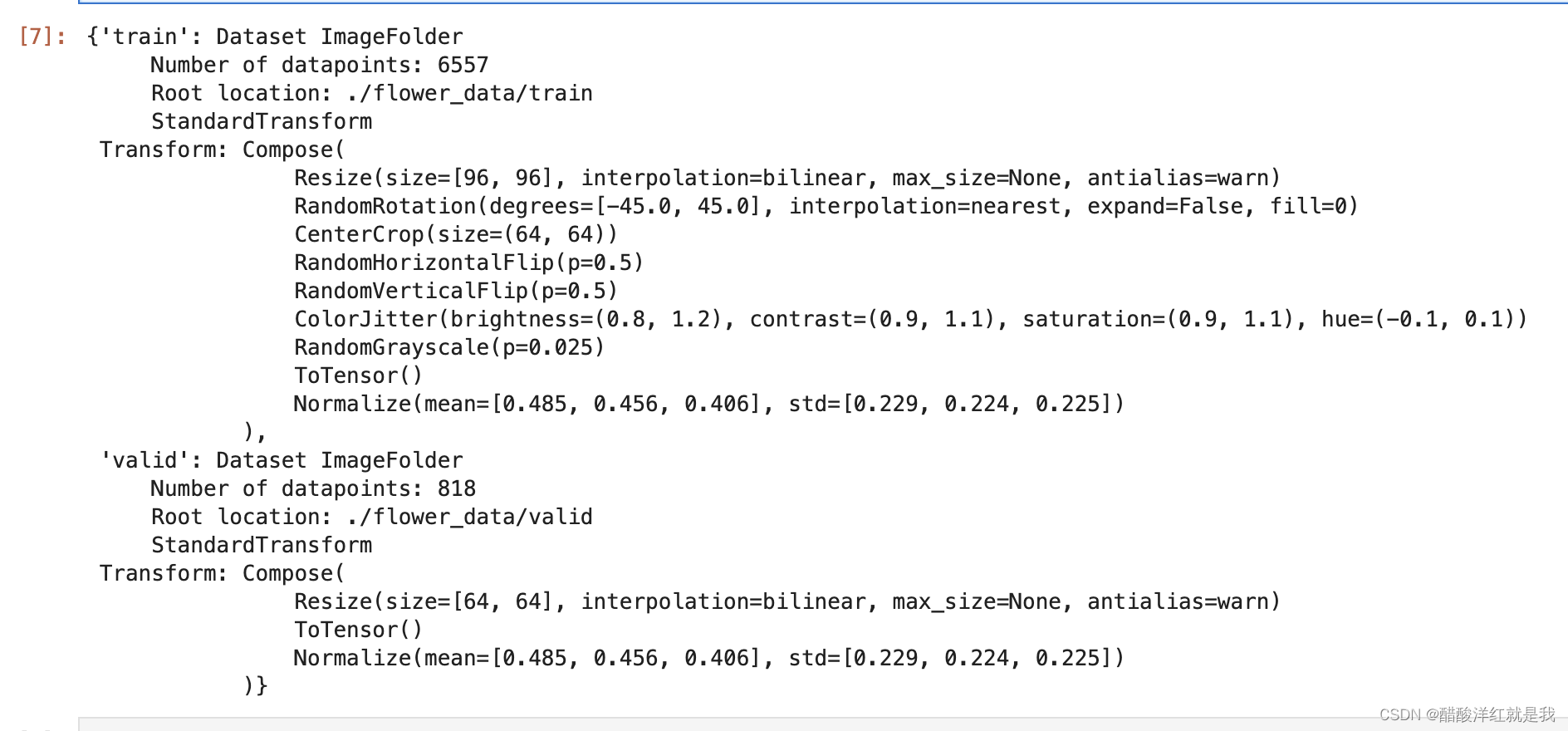
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([96, 96]),
transforms.RandomRotation(45), # 随机旋转, -45~45度之间
transforms.CenterCrop(64), #对中心进行裁剪,变成64*64
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1), # 亮度、对比度、饱和度、色调
transforms.RandomGrayscale(p=0.025), #彩色图变成灰度图
transforms.ToTensor(), # 0-255 ——> 0-1
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #这组均值和标准差是最适合图片进行使用的,因为是3通道所以有3组
]),
'valid':
transforms.Compose([
transforms.Resize([64, 64]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
image_datasets
dataloaders

dataset_sizes
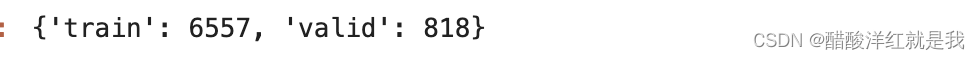
model_name = "resnet18" # resnet34, resnet50,
feature_extract = True #使用训练好的参数
冻结resnet18的函数
def set_parameter_requires_gard(model ,feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
model_ft = models.resnet18() #内置的resnet18
model_ft
改最后一层的,因为默认的是1000输出

把模型输出层改成自己的
def initialize_model(feature_extract, use_pretrained=True):
model_ft = models.resnet18(pretrained = use_pretrained)
set_parameter_requires_gard(model_ft, feature_extract)
model_ft.fc = nn.Linear(512, 102)
input_size = 64
return model_ft, input_size
设置哪些层需要训练
model_ft, input_size = initialize_model(feature_extract, use_pretrained=True)
device = torch.device("mps") # cuda/cpu
model_ft = model_ft.to(device)
filename = 'best.pt' # .pt .pth
params_to_update = model_ft.parameters()
if feature_extract:
params_to_update = []
for name, parm in model_ft.named_parameters():
if parm.requires_grad == True:
params_to_update.append(parm)
print(name)

model_ft

设置优化器和损失函数
optimizer_ft = optim.Adam(params_to_update, lr=1e-3)
# 定义学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=10, gamma=0.1)
criterion = nn.CrossEntropyLoss()
optimizer_ft.param_groups[0]
训练
def train_model(model, dataloaders, criterion, optimizer, num_epochs=50, filename="best.pt"):
# 初始化一些变量
since = time.time() # 记录初始时间
best_acc = 0 # 记录验证集上的最佳精度
model.to(device)
train_acc_history = []
val_acc_history = []
train_losses = []
valid_losses = []
LRS = [optimizer.param_groups[0]['lr']]
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch + 1, num_epochs))
print('-' * 10)
# 在每个epoch内,遍历训练和验证两个阶段
for phase in ['train', 'valid']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0 # 累积训练过程中的损失
running_corrects = 0 # 累积训练过程中的正确预测的样本数量
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
preds = torch.argmax(outputs, dim=1)
optimizer.zero_grad()
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)# 整个epoch的平均损失
epoch_acc = running_corrects.float() / len(dataloaders[phase].dataset) # 整个epoch的准确率
time_elapsed = time.time() - since
print('Time elapsed {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('{} Loss: {:.4f}; ACC: {:.4f}'.format(phase, epoch_loss, epoch_acc))
if phase == "valid" and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
state = {
'state_dict': model.state_dict(),
'best_acc': best_acc,
'optimizer': optimizer.state_dict()
}
torch.save(state, filename)
if phase == 'valid':
val_acc_history.append(epoch_acc)
valid_losses.append(epoch_loss)
if phase == 'train':
train_acc_history.append(epoch_acc)
train_losses.append(epoch_loss)
print('Optimizer learning rate : {:.7f}'.format(optimizer.param_groups[0]['lr']))
LRS.append(optimizer.param_groups[0]['lr'])
print()
scheduler.step() # 调用学习率调度器来进行学习率更新操作
# 已经全部训练完了
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:.4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model, val_acc_history, train_acc_history, valid_losses, train_losses ,LRS
开始训练
# def train_model(model, dataloaders, criterion, optimizer, num_epochs=50, filename="best.pt"):
model_ft, val_acc_history, train_acc_history, valid_losses, train_losses ,LRS = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=5)


再训练所有层
# 解冻
for param in model_ft.parameters():
parm.requires_grad = True
optimizer = optim.Adam(model_ft.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1) # 每7个epoch, 学习率衰减1/10
criterion = nn.CrossEntropyLoss()
# 加载之间训练好的权重参数
checkpoint = torch.load(filename)
best_acc = checkpoint['best_acc']
model_ft.load_state_dict(checkpoint['state_dict'])

model_ft, val_acc_history, train_acc_history, valid_losses, train_losses ,LRS = train_model(model_ft, dataloaders, criterion, optimizer_ft, num_epochs=3)

关机了,再开机,加载训练好的模型
model_ft, input_size = initialize_model(feature_extract, use_pretrained=True)
filename = 'best.pt'
# 加载模型
checkpoint = torch.load(filename)
model_ft.load_state_dict(checkpoint['state_dict'])